
- 1传播行为、事务回滚、分布式事务(CAP理论和BASE理论)
- 2微信小程序发送模版消息推送_微信公众号若依
- 3vue router 整合引入_router在线引入
- 4microblaze+yt8511+freertos 1000M网调试记录_microblaze 千兆以太网
- 5时隔两年,盘点ECCV 2018影响力最大的20篇论文_eccv 2018 image inpainting for irregular holes usi
- 6如何在 Elasticsearch 中选择精确 kNN 搜索和近似 kNN 搜索_elasticsearch knn 和fassi hnsw
- 7进阶指南!深入理解Java注解_深入java注解
- 8大数据技术概述与入门_全球信息量总和 数据
- 9基于springboot+vue的在线学习系统的设计与实现_在线学习系统详细类设计
- 10Electron常见问题 10 - video标签如何控制视频音量大小_video 标签 音量键没法操作
推荐3款自动爬虫神器,再也不用手撸代码了_爬虫软件 最新
赞
踩
网络爬虫是一种常见的数据采集技术,你可以从网页、 APP上抓取任何想要的公开数据,当然需要在合法前提下。
爬虫使用场景也很多,比如:
- 搜索引擎机器人爬行网站,分析其内容,然后对其进行排名,比如百度、谷歌
- 价格比较网站,部署机器人自动获取联盟卖家网站上的价格和产品描述,比如什么值得买
- 市场研究公司,使用爬虫从论坛和社交媒体(例如,进行情感分析)提取数据。

与屏幕抓取不同,屏幕抓取只复制屏幕上显示的像素,网络爬虫提取的是底层的HTML代码,以及存储在数据库中的数据。一般使用抓包工具获取HTML,然后使用网页解析工具提取数据。
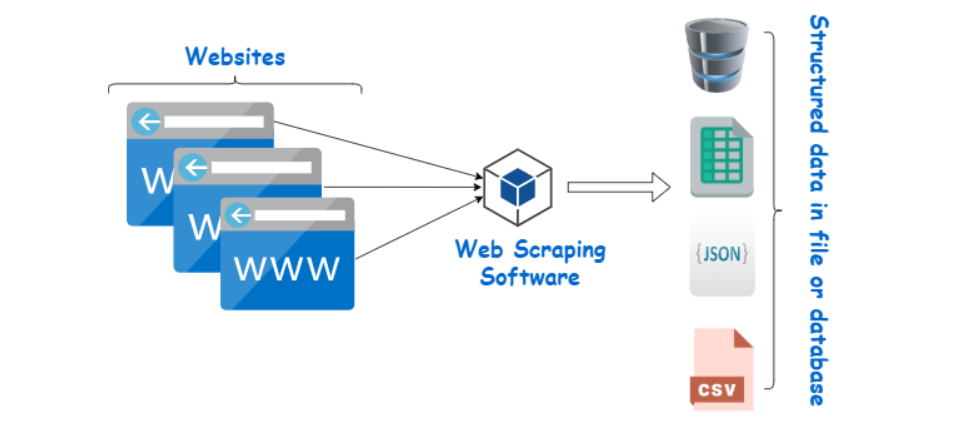
你可以使用Python编写爬虫代码实现数据采集,也可以使用自动化爬虫工具,这些工具对爬虫代码进行了封装,你只需要配置下参数,就可以自动进行爬虫。
这里推荐3款不错的自动化爬虫工具,八爪鱼、亮数据、Web Scraper
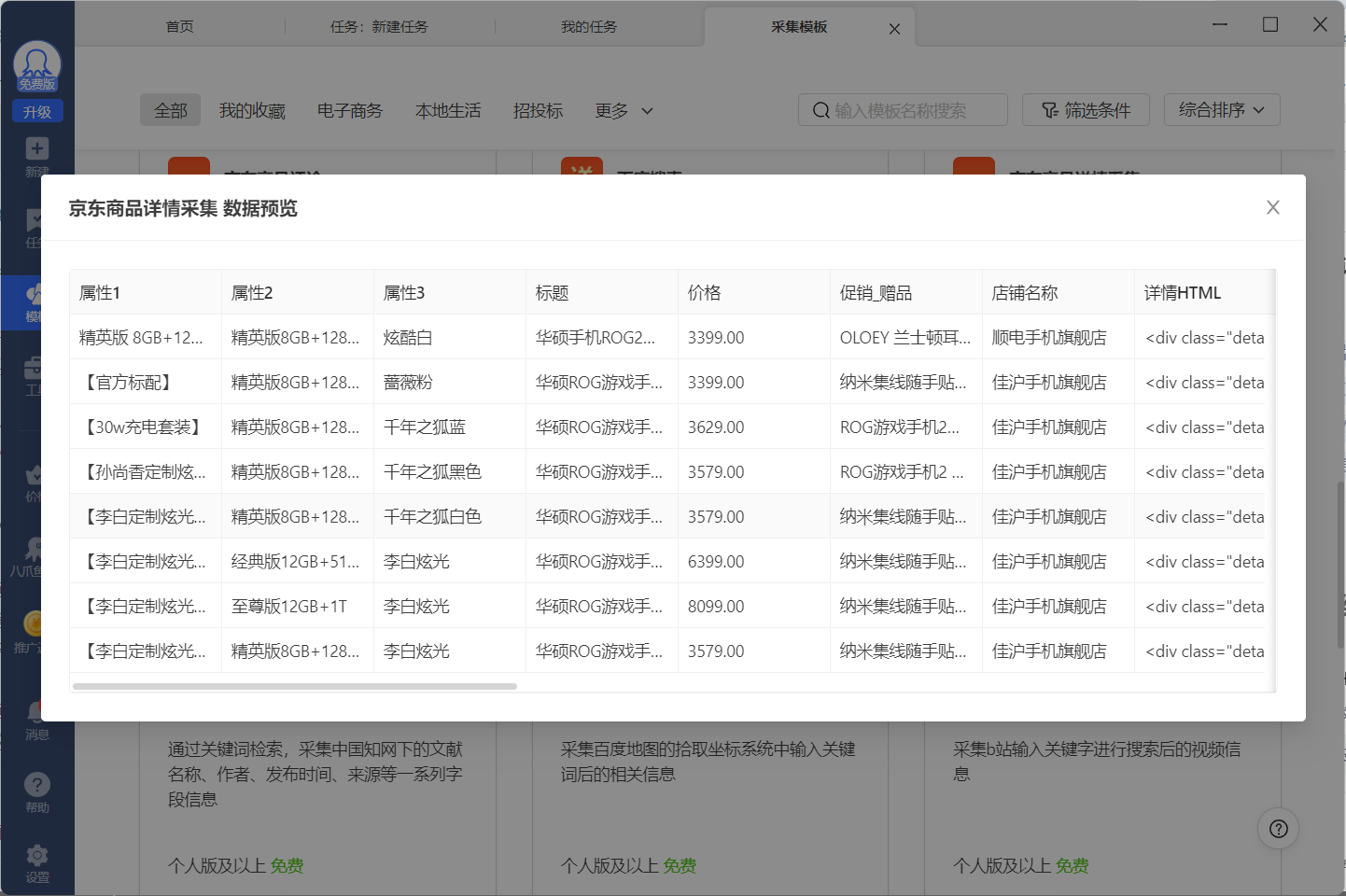
1. 八爪鱼爬虫
八爪鱼爬虫是一款功能强大的桌面端爬虫软件,主打可视化操作,即使是没有任何编程基础的用户也能轻松上手。
官网:https://affiliate.bazhuayu.com/hEvPKU
八爪鱼支持多种数据类型采集,包括文本、图片、表格等,并提供强大的自定义功能,能够满足不同用户需求。此外,八爪鱼爬虫支持将采集到的数据导出为多种格式,方便后续分析处理。

主要优势:
- 可视化界面:拖拽式操作,无需编写代码,即使是新手也能快速上手
- 数据类型丰富:支持文本、图片、表格、HTML等多种数据类型采集
- 自定义功能强:支持自定义采集规则、数据处理逻辑等,满足个性化需求
- 数据导出方便:支持CSV、Excel、JSON等多种数据格式导出
使用方法:
- 下载并安装八爪鱼爬虫软件
- 打开要采集数据的目标网页
- 使用鼠标选中要采集的数据区域
- 在软件界面设置采集规则,包括数据类型、保存路径等
- 点击“开始采集”按钮,即可获取数据
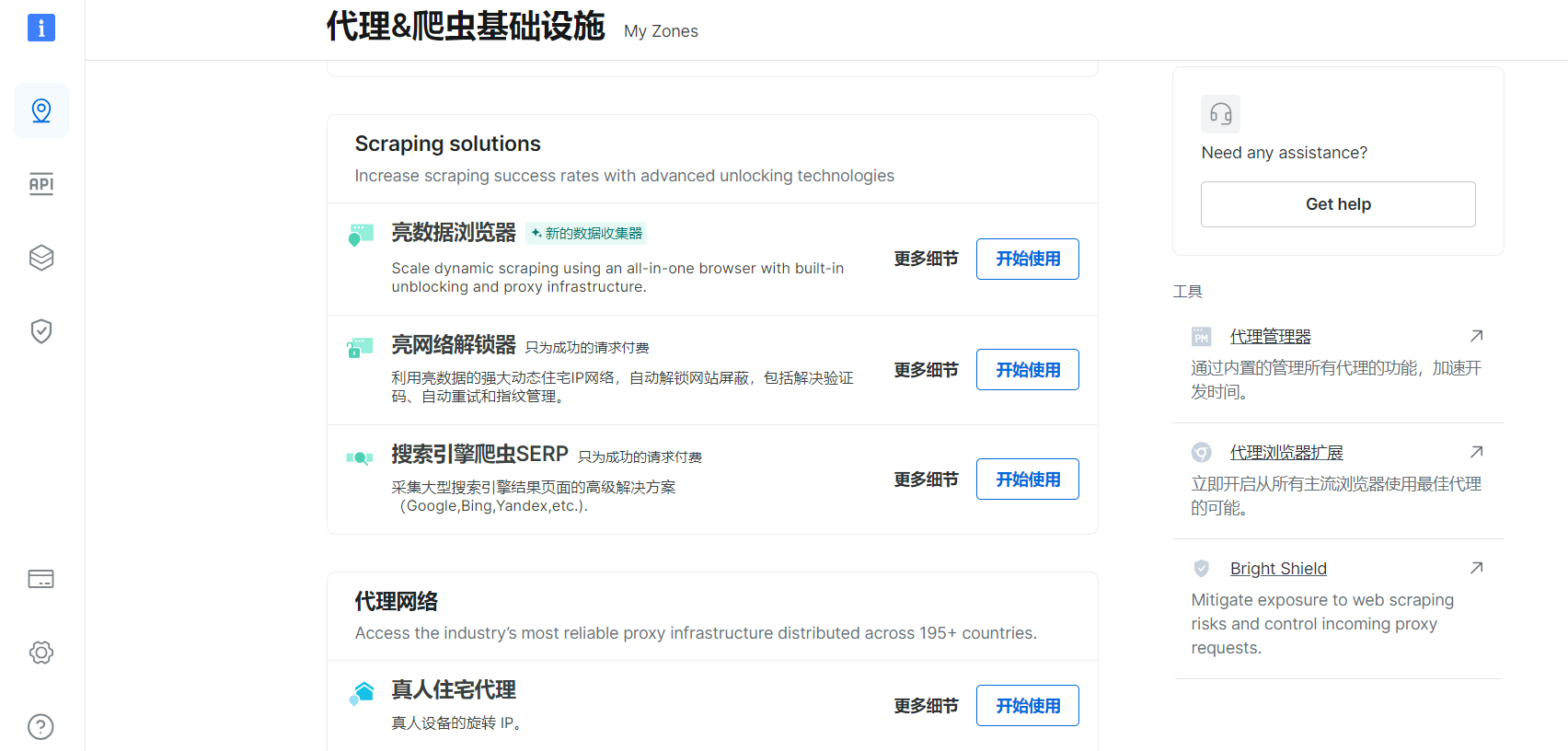
2、亮数据爬虫
亮数据平台提供了强大的数据采集工具,比如Web Scraper IDE、亮数据浏览器、SERP API等,能够自动化地从网站上抓取所需数据,无需分析目标平台的接口,直接使用亮数据提供的方案即可安全稳定地获取数据。
网站:https://get.brightdata.com/weijun
亮数据浏览器支持对多个网页进行批量数据抓取,适用于需要JavaScript渲染的页面或需要进行网页交互的场景。

另外,亮数据浏览器内置了自动网站解锁功能,能够应对各种反爬虫机制,确保数据的顺利抓取。它能兼容多种自动化工具,如Puppeteer、Playwright和Selenium等,用户可以根据需求选择合适的工具进行数据抓取。
主要优势:
- 平台化操作:无需搭建服务器,可直接在平台上创建、管理爬虫任务
- 数据源丰富:支持网页、API、数据库等多种数据源
- 模板化服务:提供丰富的爬虫模板,快速创建爬虫任务
使用方法:
- 注册亮数据爬虫账号
- 创建爬虫任务,选择数据源
- 选择爬虫模板或编写爬虫代码
- 设置任务参数,包括采集规则、数据存储等
- 点击“启动任务”按钮,即可获取数据
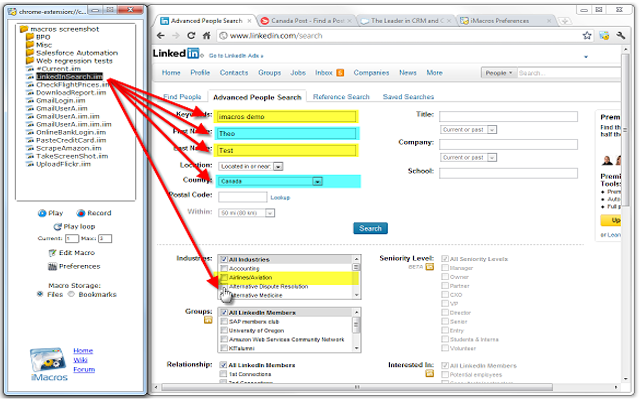
3、Web Scraper
Web Scraper是一款轻便易用的浏览器扩展插件,用户无需安装额外的软件,即可在Chrome浏览器中进行爬虫。插件支持多种数据类型采集,并可将采集到的数据导出为多种格式。


主要优势:
- 使用方便:直接在浏览器中安装扩展插件即可使用,无需安装额外软件
- 操作简单:可通过鼠标选中要采集的数据,无需编写代码
- 数据格式丰富:支持CSV、JSON、XML等多种数据格式导出
使用方法:
- 安装Web Scraper扩展插件
- 打开要采集数据的目标网页
- 点击扩展插件图标,选择“开始采集”
- 使用鼠标选中要采集的数据区域
- 点击“导出数据”按钮,即可获取数据
无论是需要简单快速的数据采集,还是复杂的定制化服务,八爪鱼爬虫、亮数据爬虫和Web Scraper都能满足采集需求。
选择合适的工具,让数据采集变得更加轻松和高效。记得在使用这些工具时,一定要遵守相关网站的爬虫政策和法律法规。


