
- 1Android进程间通讯——多进程共用SharedPreferences_android sharedpreferences多进程
- 2腾讯offer是什么样子_阿里员工求助:年包200+,拿到腾讯11级offer,跳不跳
- 3【Git】多个托管平台Git账户配置
- 4docker安装与配置docker镜像加速器_配置docker镜像家属器
- 5scanf设置精度、域宽易错点_若scanf域宽
- 6SprongBoot内置tomcat配置调优_springboot集成的tomcat配置优化
- 7JAVA数据库操作二(多个数据库操作+Spring data + jpa)_java实现同时修改两个数据库
- 800_Python—猜字游戏while-if基础版_#猜字游戏编写 #目的:掌握if分支(选择)结构、while循环结构的程序设计 #大部分源
- 9Midjourney的--seed 解释,并附有例子_midjourney seed
- 10密钥或者消息的CMAC计算_cmac_ctx_new
GAMES104里渲染等一些剩下的问题_hbao和ssao
赞
踩
Game104渲染的一些剩下的问题
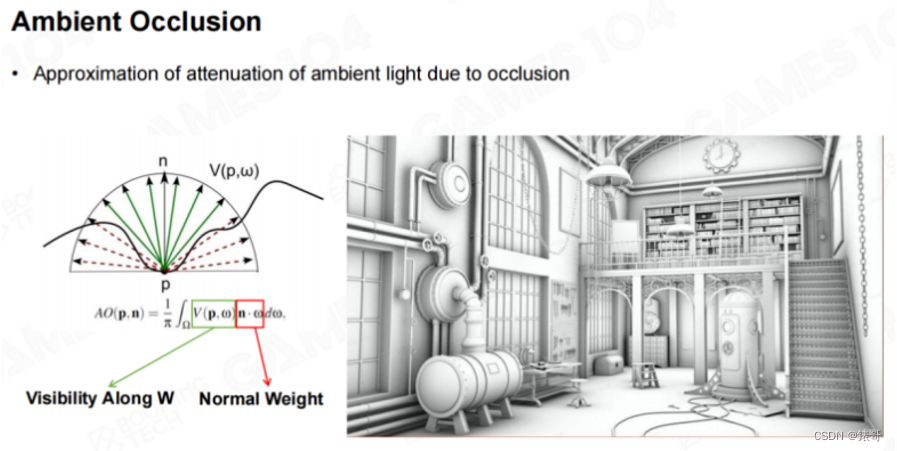
1. 如何理解渲染中的AO(环境光遮蔽)
环境光遮蔽
我们先从一个简单的效果开始—环境光遮蔽(Ambient Occlusion,以下简称AO)。大家可以看到,下图中的场景没有任何渲染效果,也没有任何着色效果,但场景呈现出了非常清晰的结构层次感,其中有很多的几何细节,而在光场中表现出了一定的明暗关系。这个明暗关系和传统的明暗关系不一样。比如图中的凹陷部分会显得比较黑,而突出部分就显得比较亮,这很符合人类生活中的实践。这种细节的光影变换满足kajiya的光照方程,但在渲染时很难实现这种效果。因为这种结构非常小,我们一般称之为中尺度结构(Meso Structure)。当天空光对其进行照明时,这种结构表面的几何细节会有相应的响应。

大家平时可能注意不到AO效果,但在现代游戏渲染中,AO效果是很明显的,下图中的场景中应用了PBR材质,呈现出了强烈的光照,但这张图中缺少了AO效果。如果我们打开了AO效果,场景就会呈现出更强烈的立体感,因为人类大脑对这种光影的明暗变化非常明暗,并且可以根据光影的明暗变化构建出3D视觉感知。


大家一致以为3D视觉是基于双目视觉,然而,双目视觉只是空间立体感知(perception)很重要的一个基础。因为即使只有一张平面图,人类也可以在大脑中构建出一副具有立体感的画面,这是通过光影变化来实现的。而在光影变化中,AO是一个非常重要的视觉元素。很早以前,大家就意识到了AO的重要性。比如前面课程中介绍的渲染方程,对于表面上的每个点,在它的可见正半球面上,只有部分能够看到天光,而有些部分会被其周围的几何结构遮挡住,因此就产生了AO效果。
回忆一下之前介绍过的Cook-Torrance材质模型,其中有一项是G项(即Geometry,几何项),G项处理的就是几何结构的自遮挡。AO和也类似于几何自遮挡。如果将相机拉的足够远,AO所表现出的数学方程和BRDF十分接近。因此AO的尺度是相对的,取决于相机的远近。
最初,对于AO效果的实现十分简单粗暴。比如在Zbrush中雕刻高精度模型时,会雕刻出很多细节,如下图所示。图中呈现出了人脸和眼角处的皱纹。当将高精度模型转换为游戏中使用的低精度模型时,就会将这些细节烘焙到法线上。但法线体现出的只是一种明暗变化,而无法体现出几何的变化。在渲染时,也无法根据法线来实现几何上的变化,因此,在现代的很多建模软件中,都提供了AO烘焙功能。如下图中的右图所示。

如果在渲染过程中使用了AO贴图,就会呈现出上图中间的效果,和左图中的效果完全不同,明暗对比更加明显。这种预计算的AO在十几年前就应经在游戏行业中应用,而且效果非常好。
即使后面又出现了实时计算AO的方法,但这个方法还是不能被取代掉。因为AO计算都是基于几何结构的,没有几何结构,实时方法也无法计算出来。
因此上述方法多用于角色的表达,在制作角色时,通常会生成一张AO贴图。
这种方法也是使用了之前提到过的空间换时间的思想。预先计算好AO的信息,在程序运行时,只需要直接进行采样。但这种方法只能表达单个物体。当对整个场景进行AO处理时,上述方法就无法胜任了。比如地板上有一张桌子和一把椅子,桌子和椅子的位置一直在变化,这时我们就无法预先烘焙好它们的AO效果。
SSAO(屏幕空间环境光遮蔽)
这里我们介绍一个最基础的方法,叫屏幕空间环境光遮蔽(SSAO,Screen-Space Ambient Occlusion)。该方法的思路十分简单,当我们使用相机渲染场景时,除了可以生成场景的颜色信息,还可以生成场景中物体的深度信息。如果将每个像素点的深度信息连在一起,就可以得到一个高度场(Heightfield)。有了高度场信息之后,我们就可以估算每个区域的自遮挡关系。
算法的实现并不难,首先从人眼(相机)射出去一根光线,就是说我从这个眼睛射出去一根光线,这条光线会和物体相交,我们可以得到交点的坐标(x,y,z)。给定一个半径,在这个半径范围内的球形区域中随机撒若干个采样点。然后再利用相机投射计算出这些采样点的深度,如果一个采样点的深度比Z-buffer中的深度更近,说明该采样点位于可以看得见光的地方。如果采样点的深度比Z-buffer中的深度更远,则说明该采样点被当前绘制中的某个几何体遮挡了。
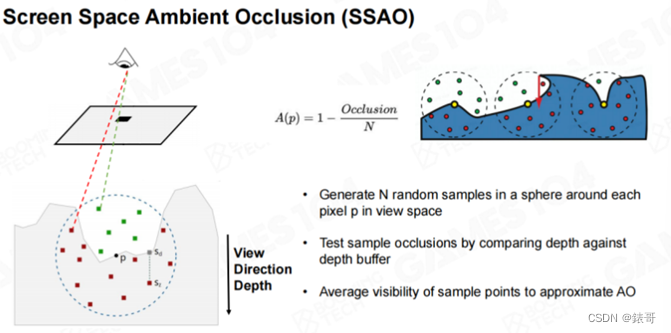
这里一个很重要的思想就是屏幕空间(Screen-Space)在游戏中,我们对整个世界有一个完整的几何表达,但在实际计算过程中,如果我们真的对上万个物体和上百万的面片进行各种各样的几何运算,效率是非常低的。后来人们发现,可以利用屏幕空间中的深度信息来简化运算,因为屏幕空间深度信息是对世界的一个局部采样的几何信息,利用这个局部采样的几何信息,我们就可以实现很多算法。今天我们介绍的屏幕空间环境光遮蔽就是利用了这个原理。
后面我们会提到的屏幕空间阴影贴图、屏幕空间反射、屏幕空间全局光照,都来源于这个思想。对于SSAO来说,比如我们随机撒了60个采样点,如果有32个点可见,我们就可以知道,着色点周围大约有一半的空间被挡住了,所以光强只能有原来的一半。这样我们就可以给出一个简单的方程,对于N个采样点来说,如果有O个被遮挡了,那么该点的光强就是1-O/N。
。
这就是Screen-Space最古老的一个方程,思想也很简单,但我认为这个方程是错误的。首先,对于一个着色点来说,着色点的受光面并不是一个完整的球,而是一个半球面。当对着色点周围的整个球面进行采样时,按照概率分布,将会有一半的采样点分布在下半球面,而下半球面本来就没有AO效果。如果按照这个方程进行计算,算出来的光强就是正常的1/2,因此这个方程用的非常少。大家都意识到这个方程有问题,然而遗憾的是,提出这个方程的原始论文就是这么写的。当然在实际应用中,我们可以将被遮挡的点的数量乘以1/2。重要的是,大家需要理解的是屏幕空间这个想法,即从人眼射向平面中像素点的光线,可以对一个立体空间进行采样,这个思想是非常重要的。
SSAO+
现在大家已经意识到,这样进行采样是多余的,因为我们只需要对半球面进行采样。基于这个思想,我们引入另外一个方法。如果我们知道着色点的法线朝向,沿着法线方向,我们只需要对半球面进行采样。因此就产生了一个改进算法,一般称为SSAO+,这样就可以减少一半的采样点,并且能够解决前面我们提到的问题。所以最早期的SSAO算法运行时会让整个画面变暗,现在我们知道这是因为整个算法存在着一定的问题。

下图中就是有SSAO和没有SSAO效果的对比,有SSAO效果的图像的立体感会好过没有SSAO效果的图像。这个方法也存在一定的问题,比如图中路灯背面的地面上也出现了很强的AO效果,这个AO效果是错误的。因为地面距离路灯柱已经很远了,路灯柱不应该对地面产生强烈的AO效果。但在屏幕空间中没有办法区分这一点,所以会产生失真(Artifact)。当然大家也在不断对这个算法进行改进。


HBAO
下面我们介绍另外一个算法——HBAO,HBAO已经部分解决了前面的问题。我们需要得到一个着色点在球面空间上的可见性,假设我们从这个点出发,沿各个方向转动,寻找到一个光线能够越过该着色点的最高的相邻几何点,我们称之为仰角(Pitch Angle)。想象一下,我们位于一个山谷中,向外射出一束光线,那么这束光的仰角要多大才能够越过最高的山脊,这就是我们需要寻找的点。如果在山谷的周围一圈都找到了这个点,就可以得到下图中右上图所示的高低起伏的覆盖图。如果能够得知着色点周围的半球形空间的仰角的采样信息,我们就能够估算出有多大面积的球面被遮挡了。我们可以理解为一种离散积分。
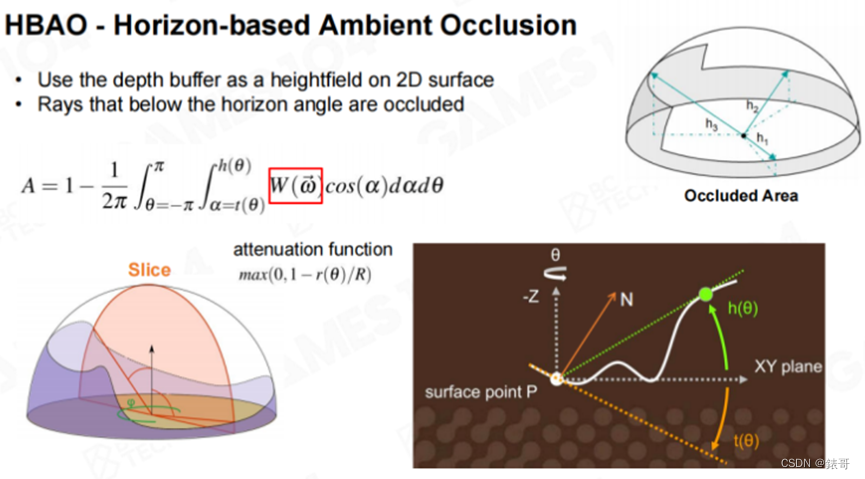
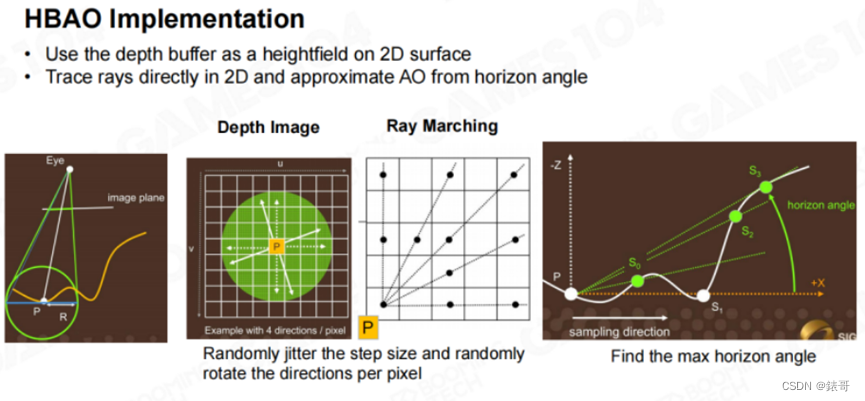
HBAO方法中还引入了一个Hack,即一个衰减函数。当山距离着色点过远时,则认为山体对于该着色点的AO没有什么影响,这样就可以处理SSAO算法中出现的失真现象。HBAO算法的实现涉及到很多细节,我们不进行详细展开。具体来说,算法还是使用了Ray Marching方法,以一定的步长向前测试。同时将深度缓冲作为高度场,并直接在2D空间中追踪光线,以水平角(Horizon Angle)来估算AO。
在进行光线步进时,每向前步进一步,都会稍微抖动(jitter)一下。这是因为如果光线每次行进的方向都相同,采样率就会很低,会出现一些很明显的走样。大家如果学过信号和系统就会知道,当一个信号采样率特别低,而且采样的滤波器非常规整的话,所采样出来的信号本身就带有很明显的Pattern(编者注:这里的Pattern可以理解为模式、样式或者图案,意为一种规整的表现)。因此算法中加入了一个Trick。最终,在像素着色器中,会一步步沿着深度缓冲区步进,寻找最大的仰角。这样寻找一圈,就可以得到遮挡信息。这就是HBAO算法的核心思想。因此,HBAO算法本质上是基于半球面积分的一个想法。
GTAO(Ground Truth-based Ambient Occlusion)
HBAO算法的结果比SSAO算法的结果要好很多,而且**能够解决SSAO算法中出现的失真问题,**但也存在一个问题。前面的课程中曾经提到过,**我们可以认为天空是一个球体。对于球体来说,从天顶射下来的光线和从水平方向射来的光线,贡献值是不一样的。**我们在介绍漫反射模型时曾经提到过lambertian模型,lambertian模型中有一个很重要的因子cosine,当光线越靠近天顶时,如果光线和天顶之间的夹角是θ,那么cosθ就接近于0。光线的irradiance接近于100%被表面吸收。而散射是向四面八方的均匀散射,因此无论从哪个角度观察,所看到的的都是100%的散射强度。但同样亮度的光如果以45度角入射,那么散射出来的光就是cos45度,大约是0.7左右。
而HBAO和SSAO算法在计算过程中都没有考虑这个因素,所以计算出来的值都是不正确的。现在大家使用的最多的方式是GTAO(Ground Truth-based Ambient Occlusion),该算法号称计算结果接近离线算法计算出来的结果。该算法的论文中所给出的Demo也和使用蒙特卡洛积分所计算出来的结果几乎一样,因为算法也考虑了表面法线的影响。这样一来,当光从四面八方入射时,倾斜的光线的权重会被降低,而靠近天顶的光线的贡献会很大。
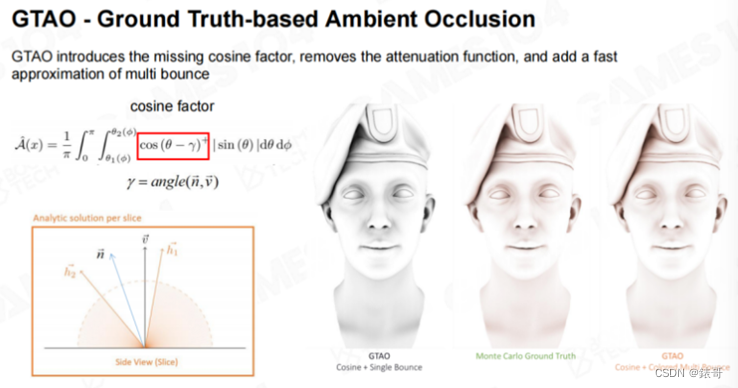
GTAO还有一个值得一提的地方,如果能够计算出来AO值,那么就能够猜测光线射入之后,在黑暗处来回反弹的亮度,我们称为**Multi Scattering.**因为AO只是计算了遮挡,和真实的物理效果不一样。假设人位于山谷的谷底最黑的地方,而由于山谷两侧的反光,谷底并没有那么黑,这才是真实的物理效果。而且谷底的颜色和山谷周边的颜色相关。比如山谷是绿色或者红色,那么在谷底看到的AO也是有颜色的。这需要进行很多积分才能得到这样的结果,但这是GTAO中一个非常好的想法。
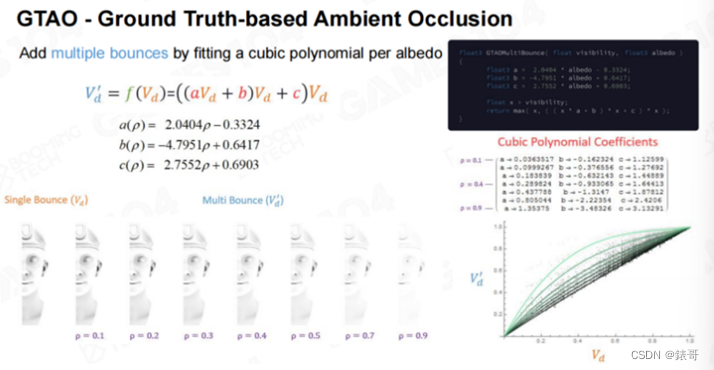
GTAO方法根据不同的AO值,对数值进行了大量的分析,并得出了一个结论—AO值实际上和Multi Scattering有一定的关联度。这个关联度不是线性的,但符合某条曲线。于是作者给出了一个三阶多项式的方程,使用这个方程,就能够根据AO值估算出光线来回反弹的最终结果。
该方法和我们上节课中介绍大气散射的方法有异曲同工之妙。上节课中,我们也是计算出了单次散射,然后就能够估算出多次散射的结果。虽然原论文没有给出理论证明,但我个人觉得这种方法在数学上是有基础的。
回忆一下,我们在计算BRDF模型时,也不知道微表面上的细节结构,但我们使用了一个统一的量,叫做粗糙度(roughness),就表达了微表面的集合不平整度。而这里的AO值,就有点像小区域内的粗糙度,可以表示出某点周围对该点的遮挡性。类似于BRDF中的G项,假设表面的分布符合一个统计学分布,如果使用统计学的方法进行计算,这其中肯定是有一个关联度的。但这个关联度可能是个积分值,也可能是个更复杂的方程。而再复杂的方程,在某些情况下,我们都可以用一个多项式来进行拟合,这在数学上也是成立的。因此,GTAO方法的这个发现,是有数学基础的。同学们如果有兴趣,可以进行深入的研究。
对于GTAO方法自身来说,并不需要花费这么长时间进行介绍。但这个思想特别值得借鉴。从最开始的SSAO,大家想到了利用屏幕空间的方法,不用对整个世界进行几何上的运算。而对于HBAO,我们可以认为这是一个过渡性的方法。而到了GTAO方法,则是从数学上彻底将这个问题解决了。作者同时还观察到了一个很重要的性质,并给出了一个拟合方程。这样一来,AO的效果就从一个简单的黑白分明的效果变成了彩色的有色相的效果。
实时光线追踪的Ambient Occlusion。实时光线追踪的数学基础核心就是现代GPU能够快速进行光线投射(Ray-Casting)的计算,并给出是否命中物体的结果。对于屏幕上的每个像素,我们可以发射出射线,然后就可以得到周围有没有遮挡的结果。
当然,如果希望结果正确,我们需要为屏幕上的每个像素点在它的半球面发射出很多条光线,但即使现代的GPU也没有这样的算力。真实的做法是在每一帧对于每个像素,只向外发射1-2条射线,但会在时序上对数据进行收集,这样就能够完成球面上的采样。
2. 如何实现真实的雾效
雾效
下面我们介绍雾效。在游戏中,最开始使用的雾效的原理非常简单,叫做Depth Fog。简单来说,从人眼看出去,随着距离的增加,场景的透明度开始逐渐下降。
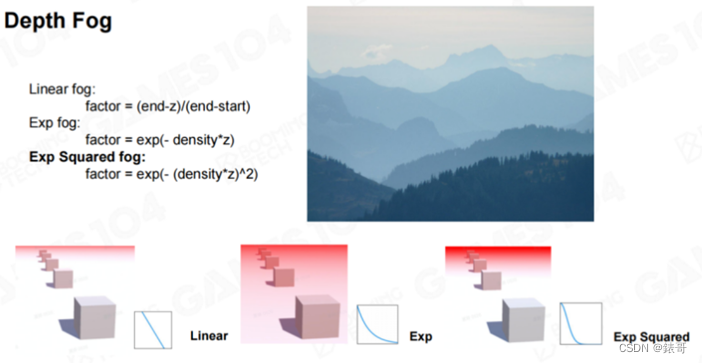
实现雾效最简单的方法就是线性方法,首先,设置一个起始点,在该点之前的空间中没有雾效,而随着距离的增加,雾效会逐渐加重,到了一定远处,雾效就会达到一个最大值。在使用过程中,人们发现,指数型雾效效果较好,而在实际应用中,一般会使用二阶指数型雾效。这个过程中的数学原理很简单。大家打开任何一个商用引擎,选择雾效,缺省的雾效模式就是这种指数雾效。如果打开Unity的话,我们可以发现,Unity中提供了三种雾效模式分别是Linear Fog,ExponentialFog,以及Exponential Squared Fog。这几种雾效对于世界的表达力比较有限。
在真实世界中,雾是有高度的,因为雾实际上是一种气溶胶,很多时候会沉淀在靠近地面的地方。大家如果去爬山,有时候就会发现,在山顶是没有雾的,而山脚下会有雾。如果我们想在游戏中营造一种很恐怖的场景,比如有一个大裂谷,裂谷中有很多有毒的生物,我们站在裂谷上面向下看。这时我们可以使用Height Fog。在计算机图形学中,Height Fog假设雾效会有一个最大值,当高度低于某高度时,下面所有的雾都是最大的雾效值。而当高度高于这个最大值时,我们认为雾效的强度会以指数方式递减。

当一个人站在某个特定的高度,该高度比雾的高度高一点。我们观察雾中的一个物体,这时看到的雾的强度会是多少?这个问题并不简单,因为这并不是简单地对某点处的雾效数值进行计算。假设该点正好位于Height Fog的最高点,那么高点到观察点的雾效浓度会越来越低。所以这不是一个简单的均匀效果。我们在介绍天空和大气效果时提到过,遇到这种情况,只能使用Ray Marching一步步进行积分。这个算法在很早以前就被提出来了,但如果需要达到正确的效果,就需要在像素着色器中进行积分,而那个年代的硬件算力无法达到算法的要求。
人们对该算法进行了简化,认为雾的强度直接和雾的透明度线性相关,这样就可以沿路径只对浓度进行积分,计算出一个浓度值,用这个浓度值来估算雾的透明度。如果计算过程中的函数都是自然对数的函数,那么在对其积分求导时,就可以求出解析解。所以在真实计算时,我们只需要将解析解代入即可。实际上,当人眼位于雾的高面以下,或者高面以上,物体位于雾的高面以下,或者高面以上,雾效还是会有少许区别。包括雾中的内散射给物体叠加的颜色值,也是一个积分值。我们不对此进行展开。
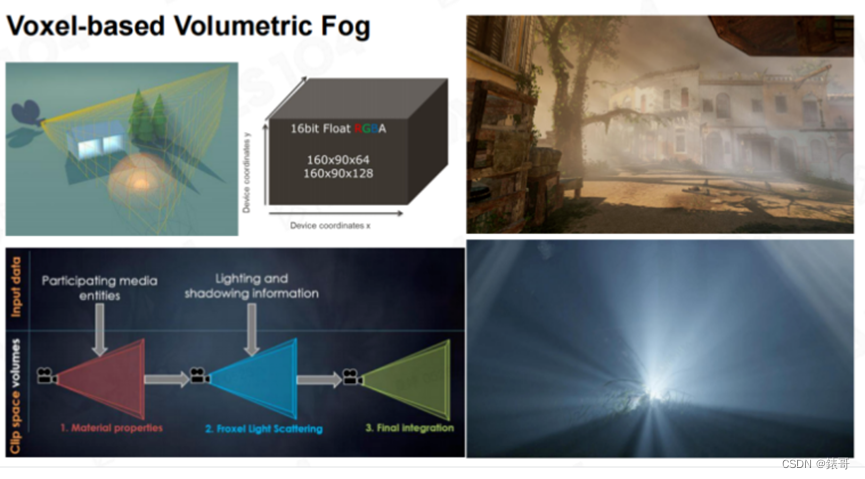
在十年前的3A游戏中,Depth Fog和Height Fog基本上已经够用。对于现代游戏引擎来说,希望大家关注一个前沿方向——基于体素的雾效,即雾也开始具有体量感。当一道光射出来时,我们能够看到一道道的光柱,这个效果看上去非常酷。很遗憾,我们刚刚介绍的Depth Fog和Height Fog无法实现这种效果。
要想实现这种效果,我们需要对整个相机空间进行体素化。请注意,这里的体素化和我们前面介绍过的均匀体素化不大一样。对空间进行均匀体素化,需要分别在XYZ方向上对空间进行均匀划分。想象一下,如果对空间进行均匀划分,从人眼处看过去,在近处会存在精度不足的问题,而在远处又会存在精度过剩的问题,于是人们想到了以视锥体的近平面和远平面对视锥体进行切分的方法。在下图左上角的黄色切分图中,我们会发现,在距离人眼近的地方,空间被切分得非常密,而距离人眼较远的地方则会被切分得非常稀疏。然后在这种规则而不均匀的网格中进行各种Ray Marching、In-Scattering、Multi-Scattering计算,具体的计算方法和第6讲中介绍的计算云层和大气的方法大同小异。如果大家对体素化的雾效感兴趣,只需要将第6讲中介绍的计算大气的方法看明白,就会知道如何计算体素化的雾效。
在工程实践中,我们一般会构建一个3D纹理来存储所有的中间计算结果,如下图中第一行的中间图片所示。3D纹理的宽度是160,高度是90,而深度可能是64,也可能是128。纹理的宽度和高度不是大家在处理纹理时很熟悉的2的n次幂,而是16:9的比例。这和屏幕的分辨率有关,这是为了使该纹理尽量保证对屏幕上的像素块的采样是一致的。大家如果自己进行实践,就会知道,这个纹理的分辨率不能随意设置。
抗锯齿
接下来我们介绍一个大家不太注意的内容——反走样。在开发游戏引擎时,有些内容大家可能注意不到,但又非常有用,必须要做。反走样就是在渲染时令人特别头疼,但又需要解决的问题。
我们在使用计算机进行绘制时,不管算法多高级,最后都是一个像素一个像素地将整个世界绘制出来。每一个像素可以理解成对连续世界的一个采样。因为真实世界信号频率(信号密度)是无限高的。当我们使用一个个像素来表达真实世界时,采样率是远远不够的。多年以前,数码相机的精度并不高,我们看到那时的照片,会发现人脸上有很多色块,也就是马赛克。而现在的数码相机分辨率越来越高,照片上的马赛克也就越来越小了。
走样(Aliasing)本质上是因为屏幕的分辨率是有限的,而需要表达的屏幕后面的几何世界的频率是非常高而导致的。我个人总结,引起走样的原因有三个。
第一个是由几何导致的,比如几何形状的一条边,只要不是严格的横平竖直的话,这条边在屏幕上一个像素一个像素覆盖过去,就一定会产生锯齿状(zigzag)的效果。字体就是这样的一种情况。
第二个是由物体表面的细节引起的。当我们对物体表面的纹理进行采样,从不同角度观察时,物体表面的纹理就会产生各种各样的失真,比如下图中的中图展示出来的摩尔纹。纹理采样产生的走样可以通过Mipmap来解决。还有一类走样大家平时可能注意不到,这就是场景中的高频信号。所谓的高频信号就是变化幅度可能很小,但是变化速度非常快。比如物体反射的高光,当旋转物体或者改变视角观察物体时,物体上的高光流动非常迅速。稍微转动一个小角度,物体上的高光一瞬间就会发生变化。高光也是游戏画面出现走样的一个很重要的源泉。

所有这些走样都会让整个游戏画面变得非常难看。对于一个现代游戏来说,如果我们关闭/打开反走样(Anti-Aliasing)设置,你会觉得是两个游戏,而关掉反走样设置之后,你会觉得整个画面都在闪烁。
大家如果玩过游戏就会知道,游戏的图形设置中会有AA相关选项的设置,一般会有4倍AA或者更大的AA。去除走样的功能称为反走样(Anti-Aliasing),反走样的核心思想都很简单,都是一个思想。我们知道屏幕上的每个像素的采样是不充分的,我们可以多采样几个像素,一般叫做“Sub-Sampling”或者“Sub-Pixel”。这样生成的颜色值就会有变化,我们可以对这些变化值进行平均,平均之后,就会产生很多过渡区域,这时的边界就没有那么生硬,过渡区域的像素看起来会显得很光滑。
以下图中的字体为例,计算机中显示的所有字体都是TrueType字体,TrueType字体是矢量字体,而矢量字体可以无限放大。但在放大时,如果我们仔细观察,就会发现字体的边缘会有锯齿。图中左边的字母A没有经过反走样处理,而现代计算机在渲染字体时,都会打开反走样选项,这样字体的边界就不再是一个明确的0-1变化。虽然看起来像是0-1变化,但实际上计算机进行了很多次超采样,所以我们会看到字体边缘的半透明区域。如果大家眯起眼睛仔细观察字体边缘,就会发现右边的字母A看上去线条更加平滑。这就是反走样的核心思想和效果。
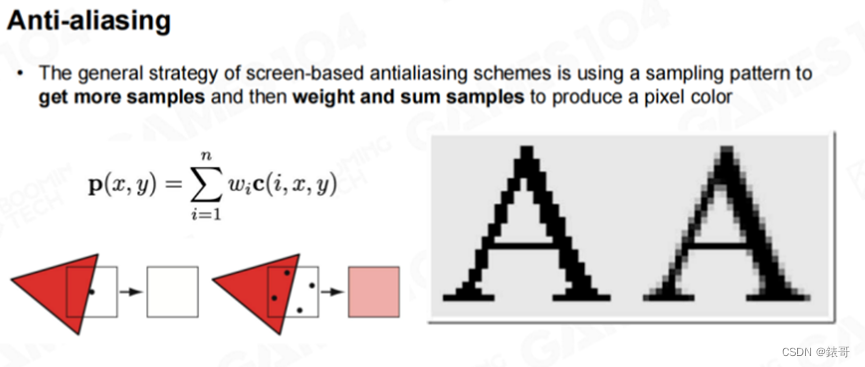
SSAA
在渲染中,我们一般会采用两种方法进行反走样。第一个方法叫做超采样(Super-Sampling)。假设我们现在需要绘制一幅1024768分辨率的图像,我们可以将分辨率加倍,绘制一幅20481536分辨率的图像,这就是4倍超采样。然后再将这个4倍大小的图像做一个下采样(Down-Sampling),甚至可以更高级一点,做一个滤波(Gaussian Filter),这样得到左图右边的结果。这个方法一定是有效的,但代价是无论Z-Buffer还是Framebuffer,包括像素着色器的渲染量,都是原来的4倍。如果显卡足够好,就可以采用这种方法进行反走样,但现代的游戏引擎中已经很少采用这种方法。
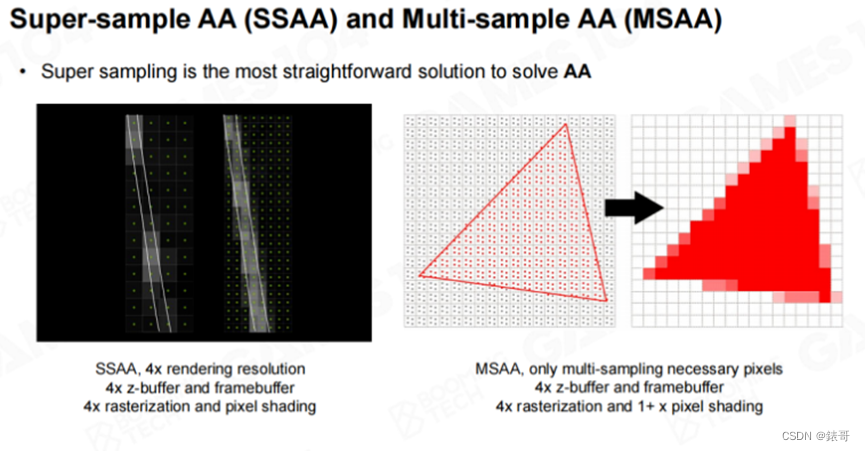
我们可以观察到一件非常有意思的事情,走样产生锯齿最多的位置是在几何体的边缘。以三角形为例,如果想对它进行超采样,我们会发现,三角形中间的大部分的点其实不需要进行超采样。因为这些点都位于三角形内部,使用中间的点的颜色大致代表即可。而真正会出现问题的地方位于三角形的边界处,三角形可能部分覆盖了一个像素,但是又没有完全覆盖,而其他部分属于另外一个三角形。
MSAA
人们后续又发明了一种叫做“Multi-Sampling Anti-Aliasing”的方法,简称MSAA。MSAA方法的思想非常简单,虽然仍然会对空间进行4倍采样,但在进行着色时,会考虑这4个子像素(Sub Pixel,或者Sub Sample)对同一个几何体的覆盖率。在实际计算中,会反过来进行,即考虑三角形对这4个采样点的覆盖率。如果三角形对这4个采样点的覆盖率是100%,则只着色一次即可。如果这4个采样点不止有一个三角形的贡献,则都需要进行着色,然后根据每个三角形占据的采样点的比例计算该点的平均值。比如有4个子采样点,两个三角形各占一半,那么权重就是一个三角形占据一半,以此类推。
现代硬件很早就已经支持这种方法,打开显卡的MSAA功能,这些所有的计算都会由硬件完成。但这个算法的代价仍然是正常渲染的4倍,算法需要4倍大小的Z-Buffer,4倍的光栅化计算,Framebuffer也需要4倍大小。只是在最终进行像素着色时,会跳过很多不需要的渲染。
MSAA方法非常好,但也存在自身的问题。在现代游戏中,几何体的密度非常高,后续我们会介绍Nanite技术,Nanite技术着重解决的就是场景中所能看到的三角形数量会超过屏幕上的像素数量的问题。对于这么密集的三角形分布,MSAA方法就会彻底失效。总之,SSAA和MSAA是上个时代的反走样技术,很简单,也很实用,但也有点过时。
时至今日,反走样算法也出现了很多变种,我们着重介绍两种方法。在工业界,这两种方法非常实用,而且代表了两种非常巧妙的思路。
FXAA
第一个方法叫做FXAA(Fast Approximate Anti-Aliasing)。从它的名字就可以得知,这是一个快速估算的反走样算法。这个方法摒弃了使用多倍采样的思路,而只对原始图像进行操作,以达到反走样的目的。
FXAA算法的目的很明确,由于需要进行反走样的像素都位于边界处,比如高光快速变化的地方,或者三角形的边界处,这些位置都会发生颜色的跳变,因此FXAA聚焦于对这些颜色发生跳变的地方进行处理。在计算机视觉中,有一个很重要的领域叫做边缘检测(Edge-Detection),会将图片中的很多边提取出来。FXAA方法会将计算机生成的每一帧画面中的边提取出来,然后在这些边缘处,采用一些很巧妙的插值方法,进行反走样处理。该方法首先使用了一个非常简单的十字形滤波,对于每个像素点,以及该点的上下左右四个点,计算出亮度的最大值和最小值,然后得到最大亮度和最小量度之间的差值。当差值大于某个阈值,则认为该点就是一个边界。实现该算法需要将整个图片转换到亮度空间,这可以通过下图中的公式进行转换。

使用这个公式,就可以将一张彩色照片变成一张具有艺术感的黑白照片,然后再为每个像素比较一下上下左右相邻像素的色差,如果这些像素的综合色差超过了某个阈值,那么久认为这个像素位于边界处,可能需要对对该像素进行反走样。
以下图为例,下图取了一幅图像中很小的一个区域,我们对左图中浅绿色方框中的点进行处理。首先需要确认横向和纵向的变化哪个更大,因为如果需要进行反走样,就需要和差别最大的像素进行混合。方法中应用了一个简单的卷积算法,首先沿纵向进行卷积,计算出一个绝对值,然后沿横向卷积,计算出一个绝对值,从而得到一个3×3的矩阵。然后对中心点应用这个矩阵。这样就可以得到横向和纵向的一个相关数值。图中横向的数值比纵向的数值大,再对横向的左右两点进行比较,此时右侧点和中心点的差距大于左侧点和中心点的差距。于是我们得到了一个叫做“offset”的朝向。即如果需要进行反走样混合,则应该和右侧点进行混合,因为中心点和右侧点的差别最大,大概率会在这个地方出现问题。
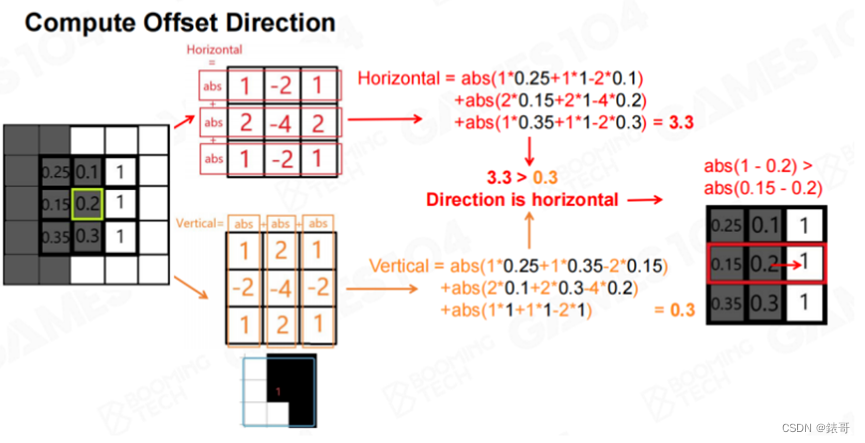

然后计算出当前像素和右侧像素之间的对比亮度和平均亮度,之后沿两个垂直的方向进行搜索,并分别计算每两个像素点的平均亮度,直到满足一定的条件,如下图最后的条件所示。这时就相当于找到了两个端点,比较该点到左侧和右侧的长度,以确定哪一侧的权重更大。
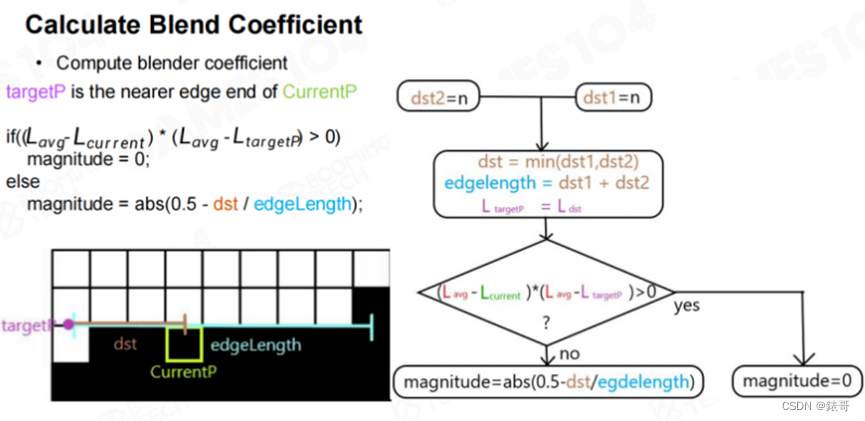
算法的基本原理类似于相似三角形的原理,只是在该算法中应用在矩形上。这样在渲染每个点时,就可以知道采样时采样点的位置应该上移还是下移。因为在为每个点着色时,实际上取的是一个插值,即可以取一点周围相邻点的颜色。这里也利用了显卡的纹理采样机制,前面的课程中曾经介绍过,纹理采样的核心就是双线性插值。相当于只要我们将采样坐标上移零点几像素,就可以得到相邻像素的颜色。

算法的巧妙之处在于,每个点都独立计算和寻找自己的Edge,但当所有点都计算完成之后,就会出现下图中右侧的结果。算法基本上只用到了初中数学的相关知识,只是一些简单的加减和比较,没有任何多余的绘制操作,就可以得出一个可接受的结果。
在下图的示例中,标记黄色和蓝色线条的图代表所找到的offset方向,接下来的几张图表示需要要进行计算的方向,后续的图片则表示根据所找到的边,需要取哪边的数值。最后的结果如右图所示。

FXAA是一个非常实用的算法,现代显卡中基本都直接集成了这个方法,效果也非常好,速度也很快。对于商业级游戏来说,很多时候大家也在使用FXAA方法。这就是不用进行额外计算,而只对数据进行观察和处理,就可以进行反走样的一种流派。
TAA
第二种流派就是TAA(Temporal Anti-Aliasing),他的核心思想就是利用前一帧的数据进行计算。在现代引擎的很多算法种,都会利用时序上的数据进行计算,即在计算当前帧时,会利用前一帧的数据。这里引入一个“运动向量(Motion Vector)”的概念,即当前图像中的每个点,在上一帧的位置,和当前帧的位置所构成的向量。有了运动向量之后,就可以和上一帧的数据进行混合。TAA的聪明之处在于,不需要进行更多的采样,而只在时间轴上寻找数据,也可以进行反走样的运算。
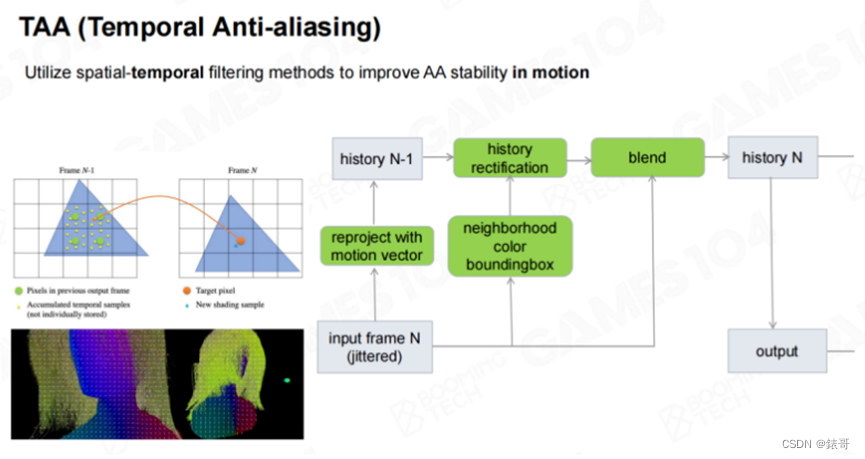
下图中是TAA的效果展示。图中有一个角色站在一座桥上,这个角色在不断移动。对于静态物体来说,当相机静止不动时,它的运动向量几乎是黑色的(表示没有移动)。而天上的云和地面上的角色都在移动,它们的运动向量就是有值的。由于运动向量具有方向性,我们对其XY方向进行了RGB编码,在计算之前的混合权重。这里的混合权重指的是当前帧和过去一帧的置信度。当然在计算时,还会有一个hack,比如对于高速运动的物体,会更加相信当前帧的数据,而不会过渡相信过去一帧的数据。而如果物体是基本静止的,那么两帧的权重就差不多。所以对于运动的物体来说,当前帧的权重会略高一点。

TAA也是现代游戏引擎中非常主流的一种反走样算法。下图中展示的是实战中的结果,来自于NVidia制作的一个demo。

大家可以关注视频中的高光和几何细节。当TAA关闭时,这些位置会有很多抖动,特别是吧台上的高光。而当TAA打开时,场景中每个像素的位置会和TAA关闭时有少许错位。这是因为相机一直在移动,而TAA需要利用过去一帧的图像进行混合,因此会产生一点点偏移。这是我个人认为TAA的一个问题,而且TAA做不好的时候会出现一些残影,这也是由于时序比较而出现的问题。
总结一下:FXAA和TAA是当前比较主流的反走样算法。
3. 为什么说“后处理”是3A大作的美颜相机
后处理
后处理是渲染的一个相当重要的部分。我个人认为,对于所谓的3A大作来说,后处理就是个巨大的美颜相机。如果将这些作品的后处理功能关闭,无论使用了什么高端渲染技术,看起来也就那么回事。而一旦给画面加上后处理功能(加上滤镜)之后,才能够呈现出大片感。爱好摄影的同学很容易理解这一点。后处理功能相对于游戏引擎渲染来说,就是一个大滤镜。后处理的好处有很多,今天我们简单介绍几个常用的后处理功能。

后处理的第一个目的是为了使画面物理上正确,可以使游戏画面正确地被曝光。大家想象一下相机拍照的原理,在真实世界中,光强的明暗变化幅度是很大的,比如太阳光的光强可能是烛光的几亿倍。但如果需要将这两种光拍摄到一张照片上,就需要进行正确的曝光,才能产生想要的效果。还有一些光晕的效果,这些也都是物理上真实的需要。还有就是一些风格化的表达,这其中最著名的就是“Color Grading”的效果。
我认为这三种效果是后处理中最常用的:第一个是Blooming(即泛光),第二个是Tone Mapping(即曝光),第三个是Color Grading(即调色)。即先给画面加上光晕,然后再将画面的曝光效果调正确,最后再给整个画面调色,这样一幅美丽的画面就产生了。
Blooming在游戏中是很常见的一种表现,游戏中的很多霓虹灯、强光源,都使用了Blooming效果。在渲染领域,大家也会进行讨论,为什么人眼观察强光时,强光周围会产生一些光晕。

人们对于这种现象有很多种解释。第一种解释认为人眼和相机一样,相机有个光圈,而任何凸透镜的成像并不是完美的小孔成像,它并不能完美的聚焦到一个焦平面上,所以会发散,并产生艾里斑(Airy Disk)。
另一种解释认为人眼的晶状体中有很多半透明材质(即上节课中介绍Participating Media,参与介质)。而这些参与介质和气溶胶一样,会产生米氏散射。即光线照射过来之后,会沿着光的传播方向产生一个有极向的散射。当光线照射过来时,人眼中的很多小液珠就会产生一些散射,而这些散射会在视网膜上形成光晕的效果。

不管原理如何,这种效果是能够真实观察到的,包括有些照片也能产生bloom效果。
Blooming效果的实现非常简单,首先渲染出光照信息,然后再将亮度信息提取出来。使用前面介绍的亮度提取算法,将RGB三个颜色分别赋予不同的权重,绿色权重最高,红色次之,蓝色权重最低,计算出每个点的亮度。当某点的亮度超过某个阈值时,我们就认为这个地方很亮。这个阈值是一个“Magic Number”,一般会大于1,但在现代游戏渲染中我们认为它也不一定正确。因为在现在游戏渲染中,有时候会使用HDR渲染,光强的变化幅度会非常大,所以有时候选择光场的平均亮度会更好。

这时我们就可以得到所有亮度值超过阈值的区域,请记住,这里我们取的是这些区域的颜色,而不仅仅是强度。然后我们进行一个Hack,对这些区域进行模糊处理。我们可以使用高斯模糊对这些区域进行处理,高斯方程还有一个很巧妙的特性,比如下图中的5×5的高斯模糊,实际上可以通过两次5个像素的卷积,就可以实现25个卷积。
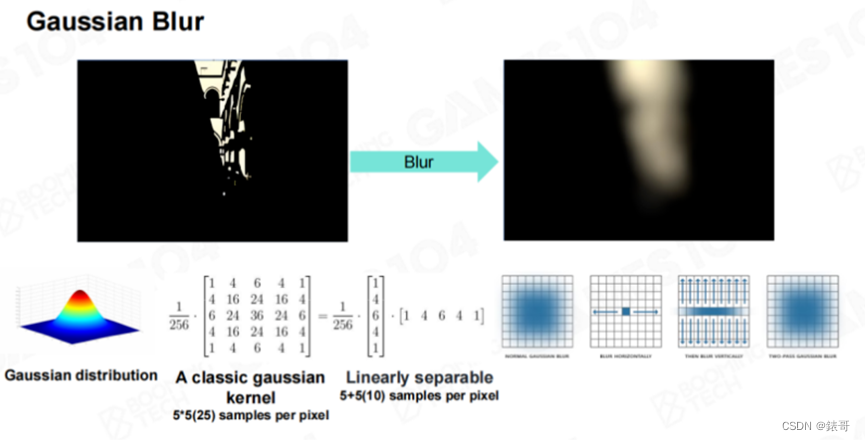
这个方法可以这样理解:对于每个点,第一个pass会将其上下两个相邻像素合并到一起形成一个结果,第二个pass时,每个点都是上一个pass的结果,再将其左右合并到一起,这样做的数学结果就相当于将每个点周边25个像素全部取了一遍的结果。
假设高斯卷积的卷积核很大,比如有9个像素大小,原来需要卷积81个数值,这里只需要卷积19个数值。这样的计算量会小很多。因此对图像加上高斯模糊,就可以得到Bloom的区域,但这样Bloom出来的区域其实不够大。如果真的需要形成这种朦胧的效果,可能要对几十个像素大小的区域进行卷积处理。
即便使用这种快速方法,每个像素点都需要进行上百次卷积,这样的计算量也无法接受。这时我们可以使用一个非常经典的方法,即使用一个Pyramid(金字塔)方法,对图像不断地进行降采样,在降采样的最低一级使用一个Kernel进行模糊,再将模糊的效果一级级放大回来,这样就可以形成很大的光晕。具体做法就是在最低级对像素点进行高斯模糊,然后将其放大,再和原来的图相加。需要注意的是,这里的相加会有个权重,具体的权重值每个引擎都不相同,由每个引擎自己设定,甚至可以开放给艺术家进行设置。然后在每一层相加时,再进行一次模糊,将图像放大,再和上一级进行加权合并,并再次放大,最后就可以得到一个很大的光晕效果。
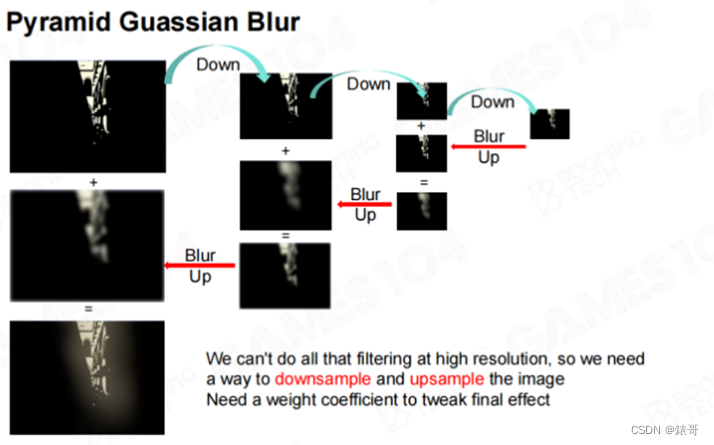
这种方法的计算量远小于在最高精度的图像上进行一个大的放大的计算量。这种思想在渲染中非常常见,我们在后面的很多运算中都会提到“Half Resolution”,或者使用Mip的方法,一层层从低向上算,这些都是降低计算复杂度的方法。
得到经过模糊的Bloom效果图之后,再将其叠加到原始图像上,就可以得到一个非常漂亮的Bloom效果。

Bloom是一种非常简单,也非常重要的效果,在现代游戏中,如果将Bloom效果关闭,场景的艺术感就会差很多,如下图所示。

另外一种后处理效果叫做“Tone Mapping”。大家可能会有这样一个经验,如果大家去过教堂或者大礼堂,窗户在白天会非常亮,而且在室内,窗户可以看得很清楚,里面的物体也可以看得很清楚。但如果这时候掏出手机来拍照,拍出来的照片大概率要么是室内的物体很清楚,窗户会过度曝光,要么就是窗户很清楚,室内看起来特别黑。
这是因为真实世界的光照范围非常之大,相机的曝光如果没有经过仔细调整,拍摄出来的照片要么就是过亮,要么就是过暗。在渲染中,这可以通过Tone Mapping来解决。现代大型游戏基本上都会使用HDR渲染,对于阳光能够直射到的地方,亮度会非常高,而在阴影中时,亮度会非常低。如果不使用曝光曲线,将这么大范围的光照数据映射到LDR或者SDR的范围内的话,实际上看到的图像就会如下图中左图所示,天空会过度曝光,下面的环境也看不清楚,而且会出现色偏。色偏是因为颜色亮度很高时,会使用截断操作(clamp),即超过1就会将颜色数据截断,这样就会使HDR颜色产生色偏,我们需要通过Tone Mapping来进行正确曝光。

通过使用一条“Filmic Curve”对其进行曝光之后,上图中的图片就会变得很清晰,也没有出现色偏。这里的算法非常简单,即通过一条曲线,将一个0-40或者0-50的值,映射回0-1的区间,这样的映射在二维空间上就是一条曲线。实现Tone Mapping有很多种方法,但随着行业这么多年的发展,最经典的曲线也就只有几种。
这里我们介绍一下Filmic曲线,Filmic曲线可以让游戏产生电影般的画质感。如果我没有记错,这条曲线应该是“Naughty Dog”工作室自己提出来的,而整个行业都在大规模应用。Filmic曲线对于任何一个计算出来的像素点的光强,当重新对其进行映射时,会将其变成一张纹理,并进行采样。在实现过程中,Filmic曲线使用了一个多项式拟合出了一条曲线,下图中就是Filmic曲线的Shader代码,大家可以仔细研究一下。
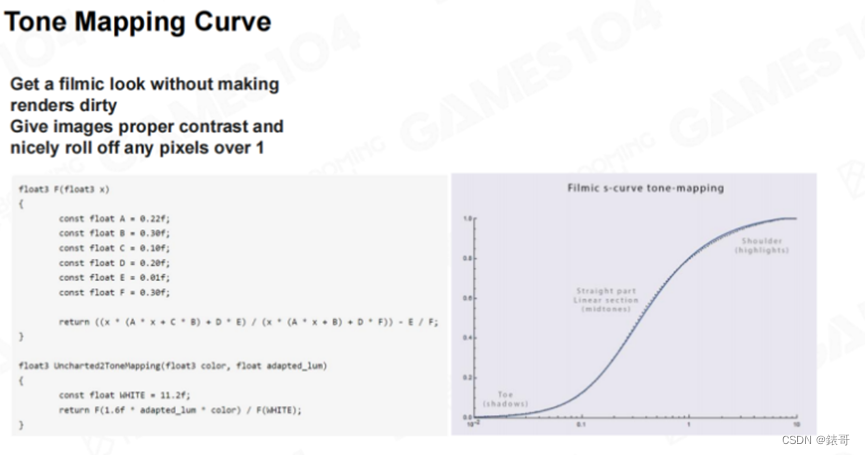
这和前面介绍AO时,从一个简单的AO数值就可以估计并推算出Multi-Scattering的数值是一个道理。有时候讲不清楚为什么这种机制可以工作,但就是可以工作,而且效果非常好。
大家可能认为Filmic曲线是游戏行业的巅峰水平了,然而在现代游戏行业,大家都在慢慢转向ACES(Academy Color Encoding System)。这是由美国电影艺术和科学学会的人士提出的(即颁发奥斯卡奖的机构),并且解决了在不同设备上播放的适配问题。
不同的显示器有不同的色彩显示范围,比如大家在购买显示器时,至少会有两种选择,一种是HDR显示器,一种是非HDR显示器。而人眼对色彩的感知都是相对的,不同的显示器对于同一种颜色的映射,最后还是需要不同的曲线进行映射。比如同样一个绿色,显示在一个周围都是白光的电脑屏幕上,以及对比显示在周围都是黑色的电影院幕布上,如果希望用户能够感知到一样的绿色,是需要进行调整的。
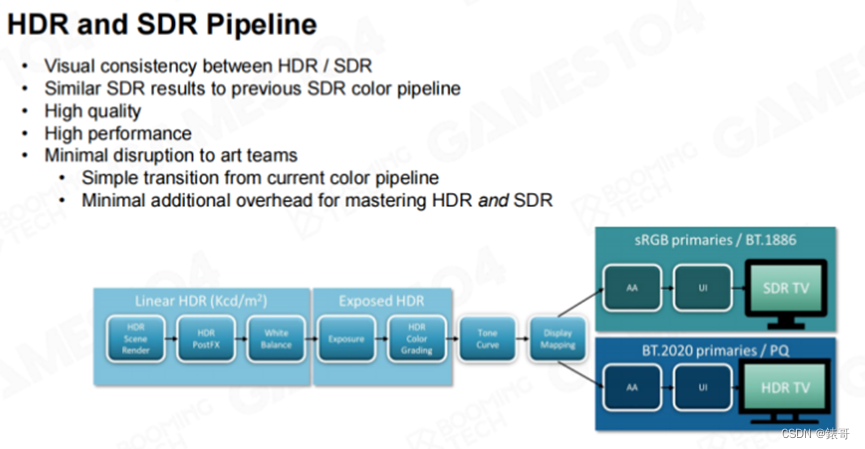
而使用ACES的Tone Mapping曲线,在转换完毕之后,后面再经过一道工序,就能够无差别地适应到各种显示终端。我觉得这其中包含了大量专业的视觉艺术家的工作成果。在工业界中,越来越多的人开始使用ACES模型。
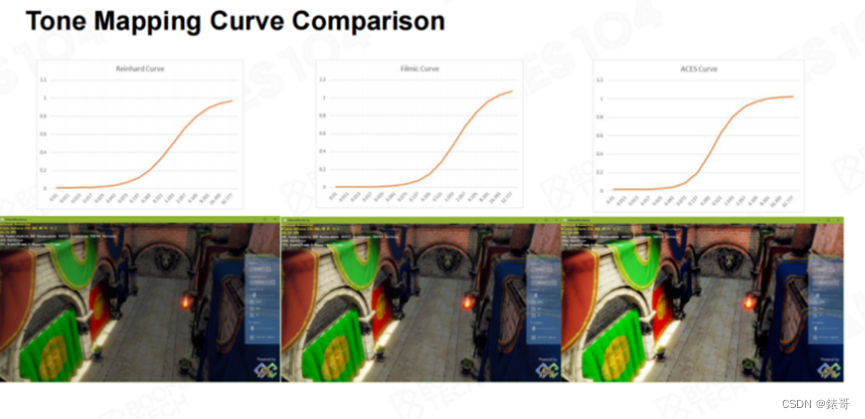
下面的图引用自知乎作者“叛逆者(龚敏敏)”,大家可以看到对于同一个场景使用不同的Tone Mapping曲线曝光后的效果。我个人觉得,使用ACES曲线曝光的效果最好,亮部看起来足够量,色彩足够饱满,而暗部又很清晰,整个画面显得非常明暗有致。而人眼天然会对这种高对比度的画面感兴趣。这也是在目前的游戏行业中,大家越来越多地转向ACES曲线的原因。
以上就是关于Tone Mapping的介绍。这一部分非常重要,因为现在大家在开发游戏引擎时,太阳光的亮度基本上都是HDR模式了。渲染出来的场景效果好不好,Tone Mapping非常重要。
下面要介绍的内容则是一个彻头彻尾的“美颜相机”。大家看下面的图,左图和右图是同一张照片,但进行调色之后,感觉会截然不同。右边的图片像是一张老照片,会产生一种年代感。这就是Color Grading,现代游戏中一个非常重要的处理步骤。Color Grading的实现十分简单,却可以在现代游戏中表达情绪和环境的基调。比如在打Boss时,这个Boss十分难打,而玩家的情绪十分低落时,这时大家会发现,整个游戏画面的颜色会偷偷发生变化,这就是Color Grading在起作用。

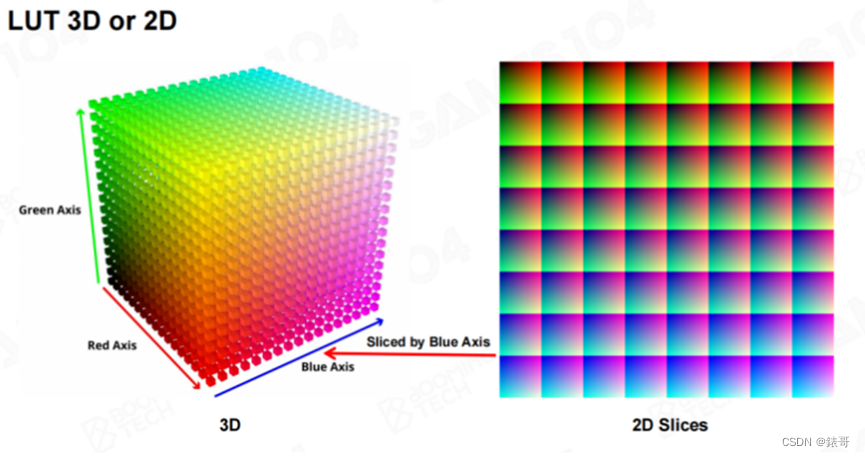
Color Grading的另一个称呼是LUT(Looking-up Table),它本质上是从原始颜色到开发者想调整到的色相空间的一个映射。这个映射一般用一个表格来表示。在现实世界中,所有颜色都由RGB组成,这可以表示成一张3D纹理。而Color Grading的功能就是将任何一种输入的颜色变化成另外一种颜色。早期的很多硬件不支持3D纹理,但我们可以将3D纹理拍平成一个二维的纹理,存放到Shader中。

在实现Color Grading的过程中,我们并不需要256×256×256这么大的纹理。在工业界,大家发现使用16×16×16或者32×32×32大小的纹理就已经足够。这是因为颜色是连续的,对于中间的颜色进行插值即可。比如我们使用32×32×32大小的纹理,而我们需要显示数值为69的颜色,69介于64和72之间,在64和72的颜色值之间插一个值,这个值基本上就够用了。这就是为什么所有的Color Grading的LUT都不会做的十分密集的原因。Color Grading非常简单,也非常实用,程序员在写完算法功能之后,就可以交由艺术家自由发挥。
在Photoshop中,艺术家可以先制作一张原始图(一般是游戏截图),然后在原始图上叠加一个图层,预先调出各种想要的效果。然后使用Photoshop的插件,导出Color Grading的LUT,同时还可以选择导出2D或者3D LUT。引擎中使用这个导出的LUT进行Color Grading的后处理,就可以在游戏中产生一模一样的效果。有一些专门制作Color Grading LUT的软件,艺术家们甚至都不需要自己P图,直接在软件中设置各种参数,就能够实现颜色的各种变化。
在我自己的工程实践中,我认为Color Grading是艺术家们特别喜欢的功能,而且是开发现代游戏引擎所必备的功能,同时也是游戏渲染中性价比最高的一个功能,对于游戏画面有着质的提升。下图的原始图片看着很一般,但叠加了Color Grading处理之后,就会让玩家感觉到压抑。总之,Color Grading是后处理中非常重要的一个部分。

4. 现代渲染管线及其发展方向详解
渲染管线
前向渲染
渲染所有一切东西,都是在解卡基亚老爷子的渲染方程
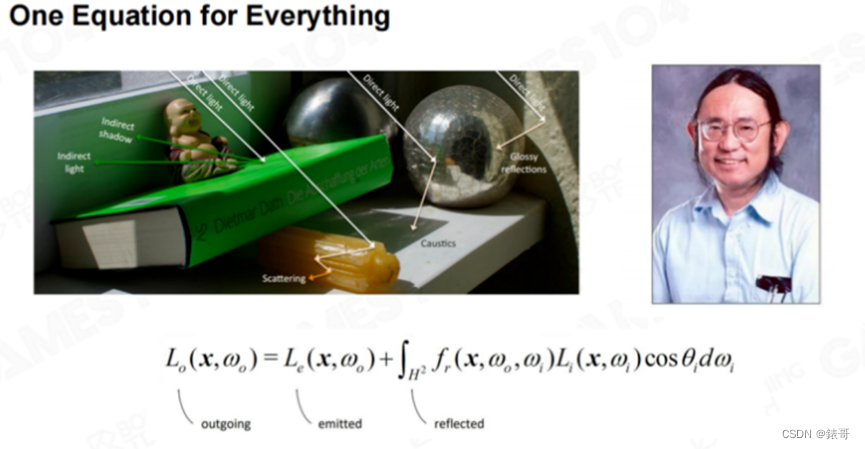
在第一节课中,我们曾经介绍过,世界时使用网格、材质和着色器来构建和绘制的,然后通过裁剪将不必要的物体裁减掉,这样就可以绘制出整个画面。从第二节课开始,内容逐渐深入,我们介绍了渲染方程中最难的点,包括阴影、全局光照、光和材质的变化,又引入了最难的材质系统。后来由PBR材质一统天下,这样我们基本上完成了材质的统一。第三节课我们介绍了世界中难以表达的元素——地形、复杂的天空和云,介绍了一系列非常复杂的积分算法。我们能够近似模拟渲染方程中提到的需求,同时能够将游戏世界做得非常大,非常开放,而又具有无数的细节。
今天的课程介绍了一些零散的细节元素。比如AO,有了AO之后,游戏世界才会让人看起来感觉凹凸有致。然后是雾效,雾效会让整个游戏世界显得更有层次感。同时由于游戏世界中的元素太多,屏幕分辨率又不够,所以需要进行反走样,让画面看起来更平滑。最后还需要进行一些后处理,给游戏画面“美颜”。所以需要将Blooming效果表达出来,并对画面进行正确的曝光,不要让画面看起来具有色偏。最后再应用一个“魔法科技”——Color Grading,将整个游戏画面调整成需要的色相效果。
有了这些知识之后,我们是否就已经知道游戏画面是如何绘制出来的呢?这里面还有一个很重要的内容——Render Pipeline,Render Pipeline最简单的解释就是绘制顺序。之前介绍的众多算法,必须有一套规则来确定算法执行的先后顺序,这样才能保证绘制是有序的。
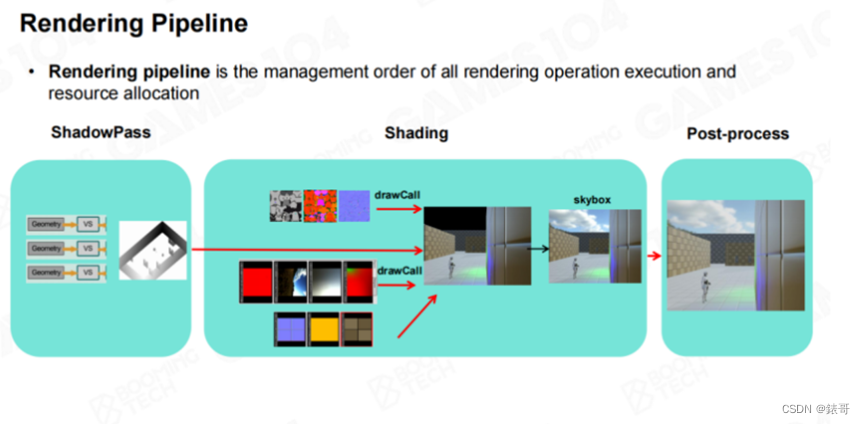
这就是我们在第一节课中所讲的,游戏引擎中的渲染和纯粹的图形学渲染,最本质的区别是游戏引擎没有办法抽象出一个简单干净的算法。实际上,在一帧游戏画面的生成过程中,会有几十种到上百种算法同时在运行。如果希望这些算法的最终效果不出问题,就需要有一个管线进行管理,让这些算法有序运行。最简单的管线如下:先计算阴影贴图,然后依次处理物体的光照,对其进行着色,每个光源计算一次,最后再将计算结果输入后处理,进行曝光、Color Grading等处理,就能够得到想要的结果。
这是最简单的一种排列,而且确实可以工作,很多商业级游戏使用的就是这种管线。这种管线我们一般称为Forward Rendering(编者注:一般也翻译成前向渲染),即为每个网格,将其对应的所有灯光依次渲染一遍。以本门课程开发的辅助引擎Piccolo为例,就是对于每个物体,将每个灯光依次渲染一遍。(编者注:请参考B站GAMES104课程视频第7讲1:20:41秒处的动画演示)

前向渲染中有一个小细节,即天空盒会在最后绘制。这是因为天空盒距离相机最远,其次是由于透明度排序的问题。游戏场景中会存在一些半透明物体,对于Forward Rendering来说,半透明物体的绘制不能和不透明物体的绘制混合在一起,而必须最后绘制。在绘制半透明物体时,还需要进行排序(Transparency Sorting)。因为当在屏幕上叠加半透明效果时,需要和屏幕上已有不透明物体的深度进行比较,如果不透明物体位于半透明物体之前,则不需要绘制这个半透明物体,这可以利用Z-Buffer来实现。如果半透明物体位于不透明物体之前,则半透明物体需要混合不透明物体的颜色,因此必须在不透明物体绘制完毕之后,再绘制半透明物体。
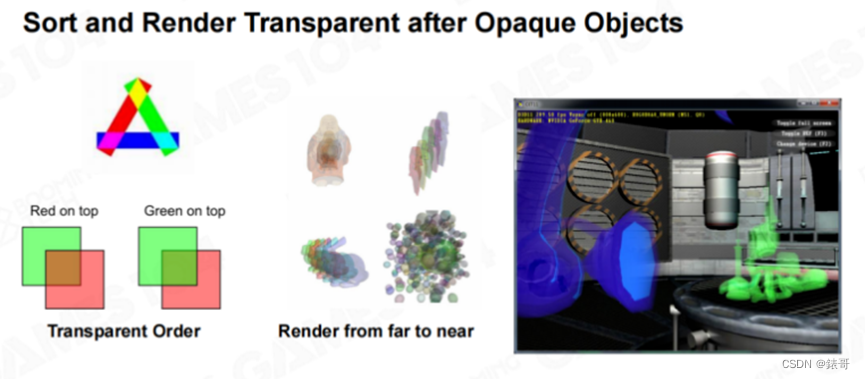
如果场景中同时存在多个半透明物体,则需要使用透明度排序(Transparent Sorting)算法对半透明物体排序,将所有半透明物体按照与相机的距离由远及近进行绘制。想象一下,当两个玻璃前后重叠时,我们需要将后面的颜色先绘制出来,然后再将前面玻璃的颜色混合上去,才能够得到正确的效果。这里有一个示例,黄绿红三种玻璃,以不同的顺序重叠在一起,所产生的结果是不一样的。
在现代游戏引擎中,透明度排序是一个非常难的问题,会产生很多Bug。很早以前,就有人提出了透明度排序问题,并给出了相应的算法,但该算法并不完美。比如上图中的三个透明物体相互覆盖在一起,无论以何种顺序渲染,结果都是不对的。
在游戏引擎中,一般会使用物体的中心点对半透明物体排序,而游戏中的半透明物体非常多。举个例子,在游戏场景中扔下一颗手雷,手雷爆炸时会生成很多烟,这些烟就是一个个的粒子。这些粒子都是半透明的,需要进行排序,这个问题就困扰了引擎开发者很多年。后续在介绍粒子系统时,我们会详细阐述对粒子进行排序时所遇到的各种困难。
大家只需要记住,对于Forward Rendering来说,一定要将半透明物体放在不透明物体之后绘制,然后对半透明物体依次进行排序。这样的管线基本上能够胜任早期游戏的绘制。
对于早期使用Forward Rendering的游戏来说,比如《Just Cause(2006)》和《Heavy Rain(2010)》,游戏画面的表现都很不错。但在十几年前,大家逐渐认识到Forward Rendering存在的一些问题,因此现在主流的渲染管线并不是Forward Rendering。这其中有一个很核心的问题。在现代游戏中,为了画面表现,灯光往往非常丰富,并且十分复杂。比如屋顶的吊灯、扔出去的照明弹、地上的火把等等。Forward Rendering在处理多个灯光时效率十分低下。

延迟渲染
这时大家提出了延迟渲染技术(Deferred Shading,也称为Deferred Rendering)。延迟渲染的思想非常简单,先将所有的物体渲染一遍,计算材质的Albedo、Specular、Roughness、Depth等信息,并存储在缓冲区(Buffer)中。但不进行光照计算,而是将光照计算放到后续的步骤中进行。
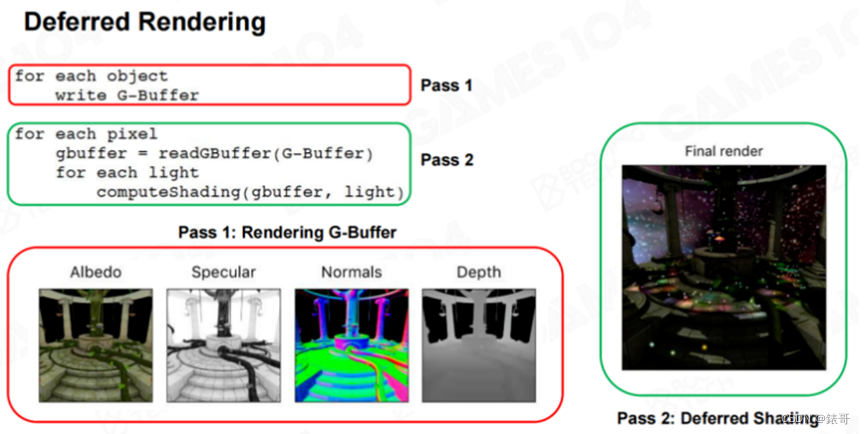
这个缓冲区一般叫做“G-Buffer”。有了G-Buffer中存储的信息,在将灯光应用到屏幕上时,就可以只进行光照计算,这样所有顶点和像素都不会产生Overdraw,因为最后的着色运算只会计算一次像素的颜色(编者注:在实际应用中,延迟着色并不能完全避免overdraw,因为还有半透明物体的绘制)。在过去几年,延迟着色是游戏引擎最常用的一种绘制方式(编者注:这是对于主机游戏和PC游戏而言,而对于移动游戏来说,受限于移动设备的带宽和耗电限制,延迟着色的应用并不多)。
这种绘制方式的潜在优势是会使材质越来越统一。在PBR绘制方式流行之前,人们已经开始逐渐将材质数据全部保存到当前帧的G-Buffer中,这样后面的光照计算会高度一致。
延迟渲染的另外一个优势在于,它对于灯光的处理十分方便,能够同时计算很多光源的光照效果。比如我们以前实现的“Screen-Space Light”,需要在屏幕上添加很多小型点光源。在使用了延迟渲染之后,只需要在点光源所覆盖的圆形区域中,将光的效果叠加上去。我们以前还实现过下图中所示的“Screen-Space Light”效果,为了表达夜晚的街道场景,我们需要绘制很多小型光点,延迟渲染能够轻易实现这种效果。

延迟渲染易于调试,很多问题很容易发现,但也存在一定问题。对于延迟渲染来说,G-Buffer占用的空间十分之大,在硬件上,读写G-Buffer中的数据效率也十分低下。
TBDR
在移动端,一般会使用“Tile-Based Rendering”方式进行渲染,因为移动设备对于发热特别敏感,而移动设备最容易发热的部位就是存储芯片。主板上的DRAM速度相对较慢,对DRAM进行读写会消耗很多电量,但On-Chip的SRAM频率很高,但容量较小。因此人们设计了一种结构,在驱动程序层面,将画面切成一个个的小分块(Tile),每个分块只渲染位于该分块中的几何体。每个分块渲染完毕之后,将分块中的内容送入Front-Buffer中,生成最终的结果,而不用分配一个巨大的G-Buffer。
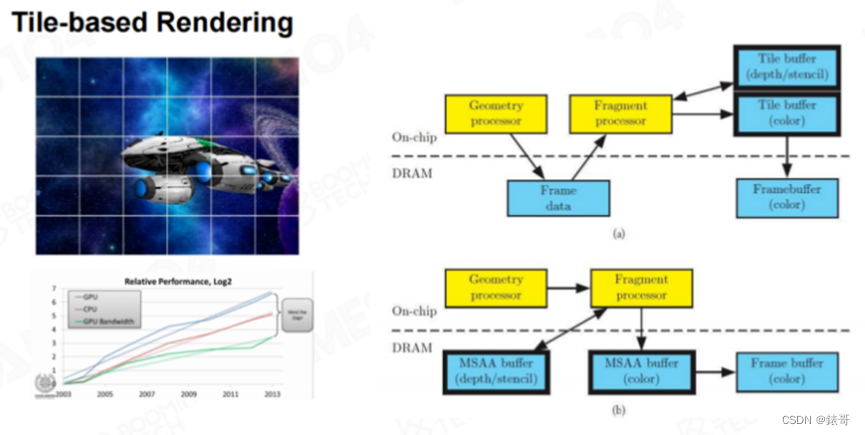
时至今日,越来越多的游戏开始使用延迟渲染,而手机游戏的主流渲染管线仍然是Forward Rendering,也是因为这个原因。
人们发现,将游戏画面拆分成一个个的小型分块,可以有效减少Framebuffer的读写压力。这样带来的一个额外的好处就是,灯光也可以被裁剪,并分配到一个个的小分块中。换言之,对于屏幕上的每个小分块,只需要进行一个简单的View Frustum处理,都可以得到照亮该分块的灯光信息。这个灯光信息称为灯光列表(Light List)。
受上述思想的启发,我们在渲染世界时,可以先生成一个叫做“Early-z”或者“Pre-z”的Z-Buffer。对于每个分块,我们可以具体得知分块中最近和最远的深度。如下图中右图所示,摩托车的背面不会被着色,而前面的部分会形成一个个的小型区域。
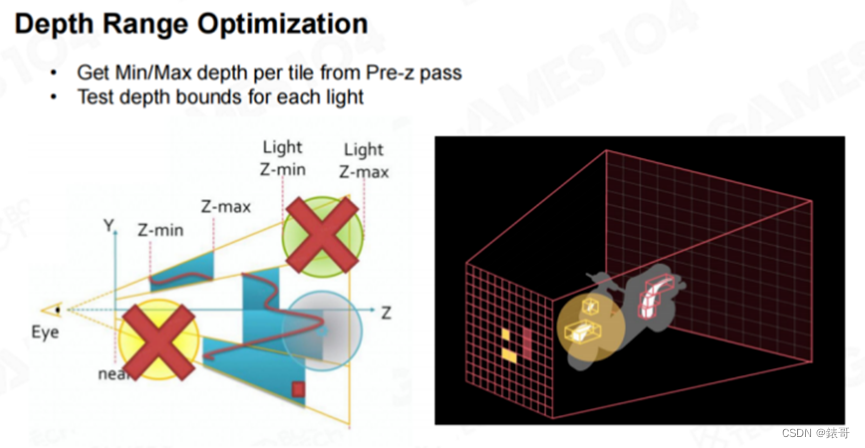
假设有一个点光源,点光源在引擎中一般表示为球体。通过上述计算,我们就可以得知哪些分块会受到该点光源的影响,而哪些分块不会被影响。一般来说,相机视锥体的大部分空间都不会被该点光源覆盖,这就是空间划分所带来的巨大优势。Tile-Based Rendering或Tile-Based Deferred Rendering是很多现代游戏的主流绘制方案,因为它们对于光照的处理十分高效。在五年前,很多大作都已经采用了这种架构,在这些作品中,对于光影的处理十分出色。

Forward+
在Forward Rendering中按照分块方式进行绘制就叫做Forward+。Forward+对于移动端特别友好,即使在一些PC游戏中,也有人使用这种方法进行绘制。

在前面的方法中,我们在对世界进行划分时,只根据Z方向进行了划分,并分别计算出了 Zmin和 Zmax。我们还可以直接对空间划分,将空间划分成一个个的类似于四棱锥的体柱,我们称为“Cluster”。基于Cluster的渲染称为“Cluster-based Rendering”,这种渲染方式对于光源的处理更为高效。比如下图中的示例,图中有上千个光源,这些光源都可以高效地进行实时渲染。大家想象一下,如果我们使用古老的Forward Rendering技术,对于这种场景是无能为力的。
Cluster-Based Rendering
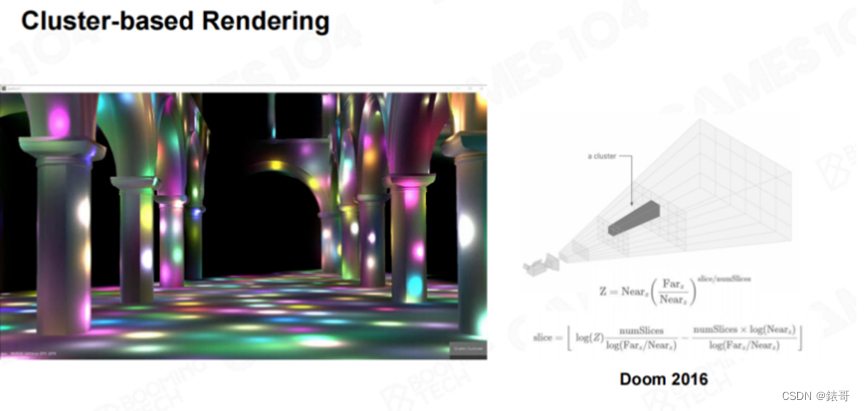
Cluster-based Rendering也在逐渐成为很多游戏引擎的标配,这种方法并没有什么特殊的技术,只是不用再计算 Zmin和 Zmax,而是逐Cluster地计算光照。
最后我们介绍一项正在蓬勃发展的新型渲染管线技术——“Visibility Buffer”。前面我们介绍的渲染管线,大部分都属于延迟渲染技术。延迟渲染本质上是将所有材质信息写入一个巨大的G-Buffer中,包括深度、法线朝向、颜色、粗糙度等。随着现代硬件的发展,大家逐渐意识到,可以将几何信息和材质信息剥离开来,然后在一个Framebuffer中写入像素所属的几何体的图元ID。比如之前课程中介绍的Meshlet ID,以及三角形ID,同时写入该点所属三角形的重心坐标(Biocentric Coordinate),这样就可以从三角形的三个顶点中提取该点的数据。
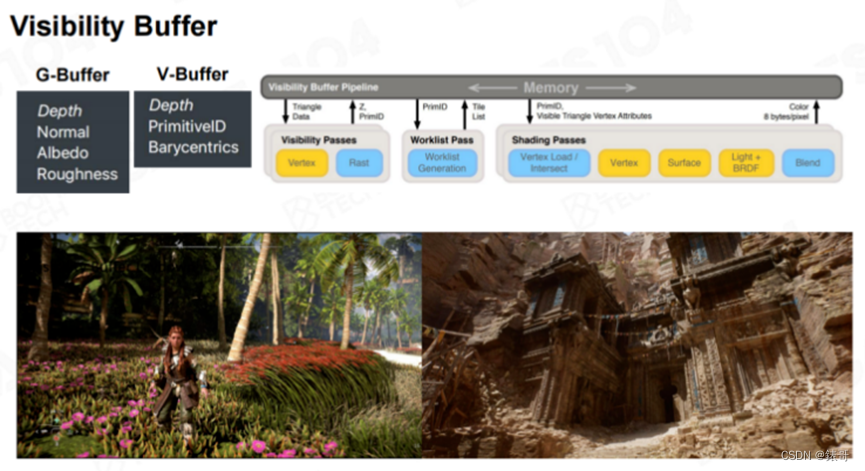
有了图元ID和重心坐标,就可以反向查找到该点所属的物体、三角形所使用的材质、法线等数据。使用一个Visibility Buffer,就可以保存该点全部的几何信息。有了这些信息之后,后续就可以对该点直接进行着色。在过去,我们一直认为材质渲染是比较复杂的,而几何处理相对简单。但在现代引擎中,比如虚幻5的Nanite技术演示中,以及《地平线》系列的最新一部作品中的植被渲染,几何体的密度非常之高,有时候会超过像素密度。
使用传统的写G-Buffer方法,会产生大量的Overdraw,还要进行大量的纹理滤波运算。而使用Visibility Buffer,只需要写入几何信息即可。Visibility Buffer也逐渐成为现代渲染管线的一个非常重要的发展方向。
同时,Geometry Shader和Mesh Shader技术也越来越成熟。大家发现,如果使用传统的渲染管线,将顶点索引缓冲区传入,再使用光栅器进行光栅化,然后再进行像素着色,这样的效率并不高。而自己用GPU直接编写Shader代码,将三角形光栅化的运行效率比硬件光栅化要高。
此外,在着色时,传统的管线需要不断查询G-Buffer中的数据,特别是纹理采样,而纹理采样的效率很低。有了Visibility Buffer,在取到对应的信息之后,就可以直接查询VB(Vertex Buffer)和IB(Index Buffer),这样做的效率非常高。
Visibility Buffer是现代渲染管线的一个很重要的前沿发展方向。我们可以预测,在未来的三到五年,会有越来越多的管线引入这个机制。但就现在而言,Visibility Buffer不像延迟渲染的设定一样是一种主管线,而是对现有管线的一种增强。随着技术的成熟,Visibility Buffer在未来可能会成为一个主管线。同学们可以关注这个方向。
如果大家真正理解了延迟渲染,理解了G-Buffer,可以再反过来理解一下这些概念。在延迟渲染中,我们在G-Buffer中存储的是材质的全部属性。而在Visibility Buffer中,我们存储的是几何属性,通过几何属性,也可以反向找到材质。Visibility Buffer还有一个好处是,它剔除了所有无用的材质信息,只保留了需要用到的材质,它支持的材质类型也更加复杂,更加丰富。如果使用G-Buffer,一般会假设材质是一致的。这是个很有趣的一个方向,大家可以关注。
5.如何理解Frame Graph的作用
Frame Graph
我们今天只介绍一个概念——“Render Graph”,也叫做Frame Graph。
如果大家对虚幻引擎或者Unity有所了解,就会知道SRP的概念,SRP是“Scriptable Rendering Pipeline”的缩写,即可编程渲染管线。SRP将管线中的运算视为一个个独立的模块,开发者可以通过脚本或者图形工具,将管线中所用到的计算和资源依赖用DAG图(有向无环图,Directed Acyclic Graph)表达出来,然后由系统自动检查这些资源之间的依赖关系,自动优化这些资源和资源间可重用的部分。比如系统发现有个缓冲区不会在后续计算过程中用到,就会将这个缓冲区释放掉,然后在另外一个计算中再重用这个缓冲区。这个操作叫做“Aliasing”,这样可以减少开发出错的可能性。
大家在开发任何一个大型系统时,在项目的初始阶段,模块较少,相互协作会比较简单。而到了项目中后期,整个团队人员都开始协作时,大部分的时间就不是在考虑如何实现具体的算法,而是如何协调每个模块,让模块之间和开发人员之间不会发生冲突。
下图是《战地4》的Frame Graph,大家可以藉此了解到渲染管线的复杂性。如果没有Frame Graph对此进行管理,开发过程中会很容易出错,而且出现问题之后很难调试,有时候甚至会导致操作系统崩溃。
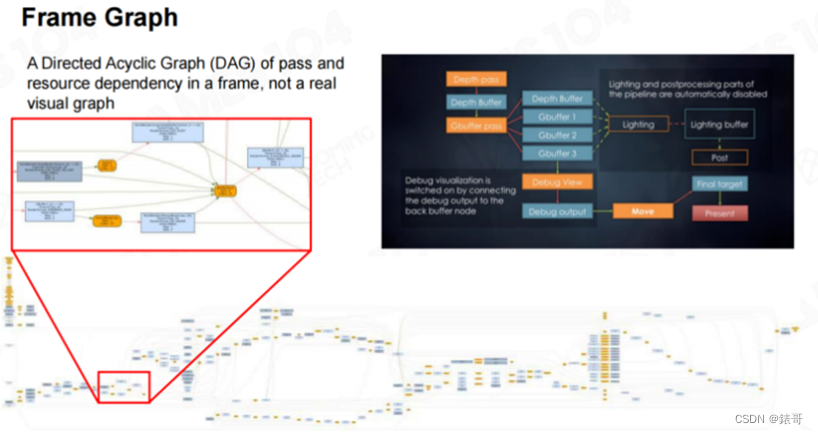
Frame Graph是未来一个非常重要的发展方向。以Unity为例,Unity有两套管线,一个叫URP,一个叫做HDRP。URP是一个更加简单通用的渲染管线,而HDRP则是一个添加了很多高端效果、高画质的渲染管线。这两个管线底层都是用SRP来定义的。
坦率来说,Render Graph还不是很成熟,大家还都在探索。比如接口如何封装,哪些接口需要开放给上层的图形程序员,Technical Artist能否使用这些接口等问题。这其中依然存在很多挑战,但这种思想值得大家借鉴。
当一个系统足够复杂,以至于连渲染本身也变得足够复杂的时候,我们定义了一个图形化的语言,将渲染本身的前后关系和依赖关系表达出来。这样才能够使复杂的3A级游戏开发被有序地管理起来。
V-Sync与G-Sync
最后,我们介绍一下如何将图像传送到显示设备上。首先需要了解的概念是“V-Sync”。
大家可能会发现,当关闭游戏中的V-Sync选项之后,游戏画面有时会出现上下两面错开的情况,这种现象的学名叫做“Screen Tearing”(画面撕裂)。出现这种情况的原因是,游戏引擎渲染每一帧画面的时间是不固定的,比如有时场景复杂,有时场景简单。游戏引擎渲染每帧画面的时间不同,就会导致游戏帧率不固定,而显示器的刷新频率是一致的。如果这时刚好错过显示器的刷新时间,则需要等待显示器下一次刷新的到来,这时就会出现画面撕裂。
V-Sync是一种预防画面撕裂的机制,游戏引擎必须完成Framebuffer的写操作,然后等到显示器下一次刷新,再将整帧画面刷新到显示器上,而不能在Framebuffer还没有写完成的时候进行刷新。
我们再介绍一个现在很流行的概念——“Variable Refresh Rate”。简单来说,Variable Refresh Rate使显示器的刷新率动态可调,游戏按照什么帧率渲染,显示器就按照什么刷新率进行刷新,这样就不会出现画面撕裂的问题。而且对于V-Sync来说,由于总是需要等待显示器刷新,就有可能出现画面刷新忽快忽慢的问题。专业的游戏玩家很容易注意到这个问题。当然,现在的显示器的刷新率也越来越高,因此这种问题也不大容易出现。
这就是开发游戏引擎的最后一步——将渲染画面呈现到显示设备上。

