
- 1Python第三方库怎样离线安装到本地,详细教程来了_python离线安装第三方库
- 2EchoMimic—语音驱动图像
- 3docker上部署mysql
- 4Hadoop-yarn-未授权访问漏洞_hadoop未授权访问
- 5java jdbc oracle rac_Tomcat JDBC 连接池配置(Oracle RAC)
- 62024最新国内外低代码平台大全_开源低代码平台
- 7【产品经理修炼之道】- 浅谈企业数字化建模蓝图
- 8python脚本 数据库压力测试_python-网站压力测试脚本
- 9Ubuntu20.04:Fatal to connect to github.com port 443:拒绝连接_ubuntu20.04 failed to connect to hub.fastgit.xyz p
- 10机器学习——K-近邻算法实例实战_k近邻算法经典案例
通义千问Qwen-7B、14B安装试用微调笔记_qwen 7b 14b
赞
踩
1、前言
成为程序员以后,ChatGpt几乎成了不可或缺的工具,慢慢的从面相对象编程成了面相AI编程。自从4.0试体验后,一直想找一个开源可用的大模型自己搭建学习一下。感受一下科技的魅力。
2、通义千问72B试用体验
modelscope提供了多个模型的试用
除了通义72B,还体验了llama3 70b和yi 34b。
72B的数量级在桌面级的电脑上已经很难带起来了,所以还是决定找个算力服务器解决一下
3、搭建服务器试用
首先推荐的就是modelscope试用的里面,无需充值,即可体验36小时GPU服务器(没打广告)
我用的是autodl的服务器,autodl,刚开始学习可以按需买,几小时的,不用的时候关机即可
- 购物服务器

不一定非要这个,我这边试用的是14B和7B的模型,这个显存带宽是够用的!
不同的显存要求在modelscope模型下面介绍都有!
- 安装python和git环境
这步省略,网上太多了!直接百度即可,记得python版本尽量3.10以上,好用不懵逼
- 下载通义代码
https://github.com/QwenLM/Qwen
这是git官方地址
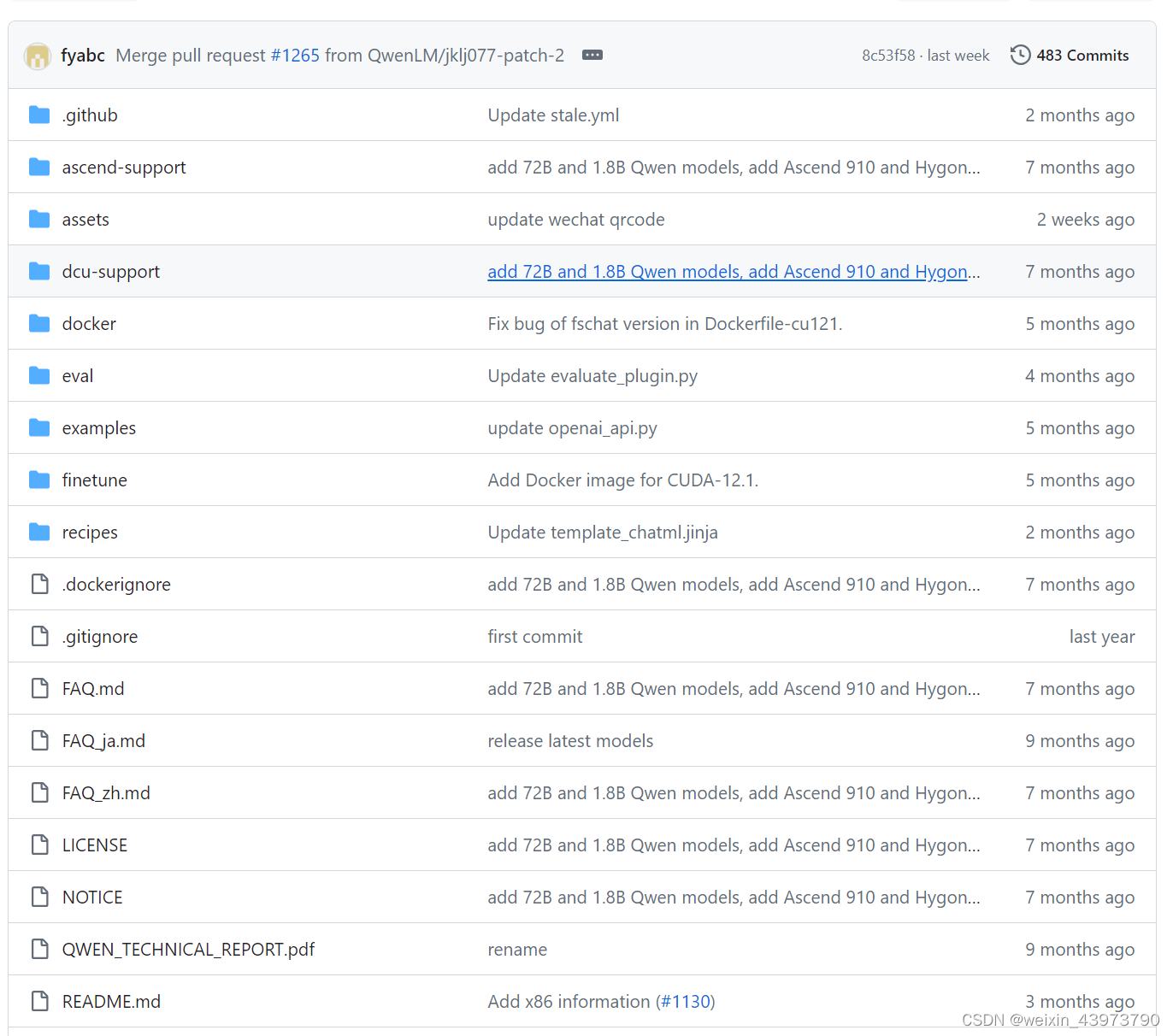
通过git clone https://github.com/QwenLM/Qwen.git即可下载
- 安装指定依赖
cd QwenLm
pip install requirements.txt
pip install requirements_web_demo.txt
安装完指定的依赖
transformers>=4.32.0,<4.38.0
accelerate
tiktoken
einops
transformers_stream_generator==0.0.4
scipy
- 下载指定模型
Qwen-14B-Chat
git clone https://www.modelscope.cn/qwen/Qwen-14B-Chat.git
- 尝试运行
通义里面带了通过gradio交互的一个界面
我们只需要修改web_demo.py文件
先讲DEFAULT_CKPT_PATH = 'Qwen-14B-Chat’路径指定到模型的位置
即可通过
python web_demo.py
看到这个访问地址就是启动成功了,首次可能会比较慢

- 量化
前一步如果你用的也是4090的卡,可能会启动成功,但是只要一问问题就error
这里可以通过量化,减少显存带宽,也会降低相应的精度
官网提供了一系列量化的方式
from transformers import BitsAndBytesConfig
quantization_config = BitsAndBytesConfig(
load_in_4bit =True,
bnb_4bit_quant_type='nf4',
bnb_4bit_compute_dtype=torch.bfloat16
)
- 1
- 2
- 3
- 4
- 5
- 6
找到下面加载模型的地方,加上quantization_config=quantization_config,这行
model = AutoModelForCausalLM.from_pretrained(
args.checkpoint_path,
device_map=device_map,
trust_remote_code=True,
resume_download=True,
quantization_config=quantization_config,
).eval()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
就能重新启动了,如果还是启动失败,可以尝试换个更小的模型尝试,7B
4、体验回答
打开服务器的端口映射,阿里云,华为云对应的安全组打开,就可以通过ip+端口的方式访问了
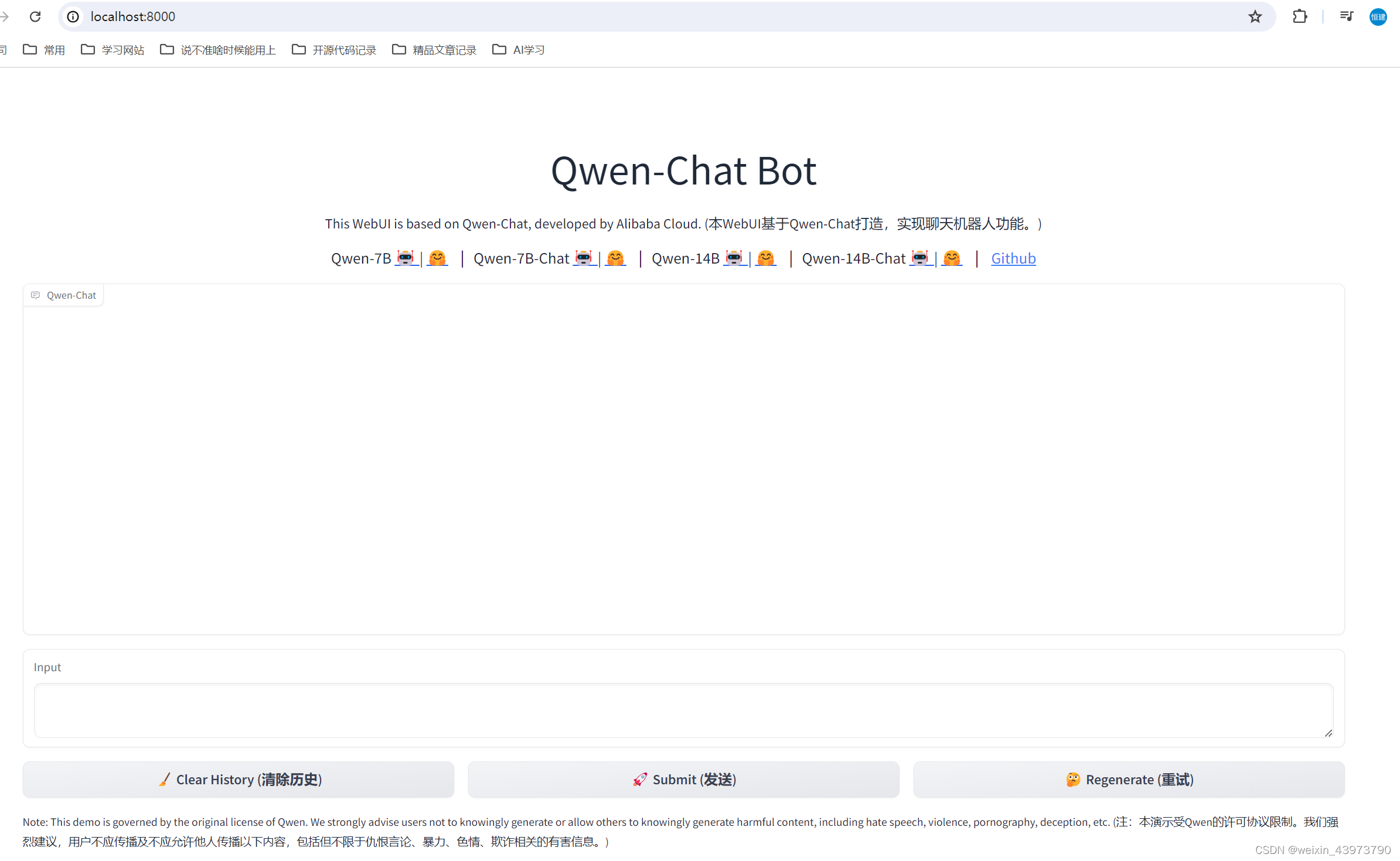
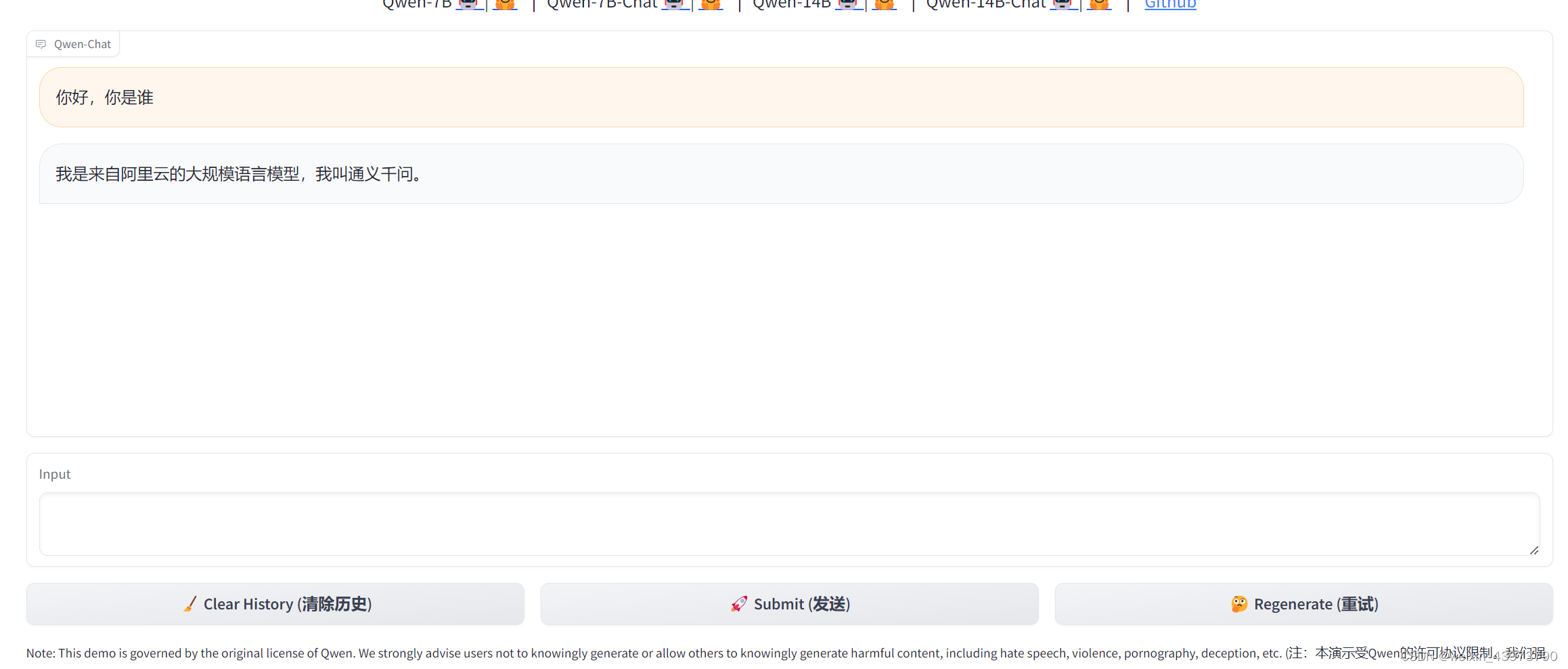
可以正常回复,之后也尝试问了一些其他的,回答上还是有点生硬,72B的回复就更流畅了
5、尝试微调
https://github.com/hiyouga/LLaMA-Factory/blob/main/README_zh.md
有一个可视化的微调模型
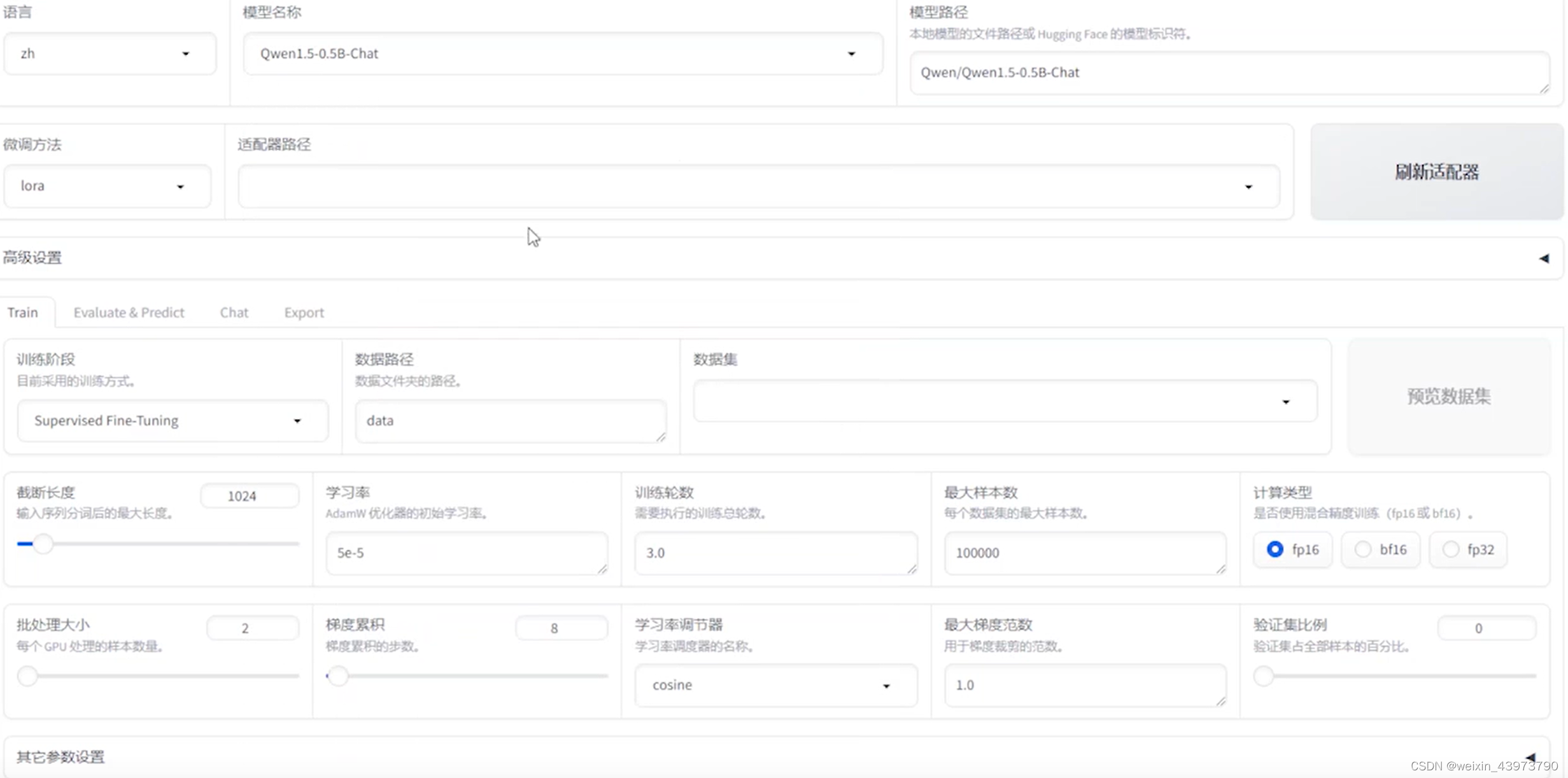
这里有自带的一些数量集,也可以通过huggingface还有modelscope下载使用,我这里最终的目的是把数据的数据转换成数据库方便投喂,所以这个插件能用就暂时没有更深入的了解了,下一期会说数据库转换的办法。
总结
科技改变生活,不可过度依赖

