
- 1Linux上运行MySQL出现“ERROR 2002 (HY000): Can't connect to
- 202、MongoDB -- MongoDB 的安全配置(创建用户、设置用户权限、启动安全控制、操作数据库命令演示、mongodb 的帮助系统介绍)_mongodb 创建用户
- 3华为OD机试2024年最新题库(Python、JAVA、C++合集)_华为od机试题库_od题库
- 4简述ECC加密算法
- 5MTK平台Android13实现三方launcher为默认_android13 系统默认launcher
- 6年终前端安全防护规范总结
- 7微信小程序slot插槽的使用
- 8Python解压7z压缩文件
- 9QT窗体间传值总结之Signal与Slot_qt 两个窗体 slot signal
- 10第三方库介绍——cJSON库_c语言json库
HDFS简介_什么是hdfs
赞
踩
1、HDFS简介
HDFS(Hadoop Distributed File System)是Hadoop项目的核心子项目,是分布式计算中数据存储管理的基础,是基于流数据模式访问和处理超大文件的需求而开发的,可以运行于廉价的商用服务器上。它所具有的高容错、高可靠性、高可扩展性、高获得性、高吞吐率等特征为海量数据提供了不怕故障的存储,为超大数据集(Large Data Set)的应用处理带来了很多便利。
Hadoop整合了众多文件系统,在其中有一个综合性的文件系统抽象,它提供了文件系统实现的各类接口,HDFS只是这个抽象文件系统的一个实例。提供了一个高层的文件系统抽象类org.apache.hadoop.fs.FileSystem,这个抽象类展示了一个分布式文件系统,并有几个具体实现,如下表1-1所示。
表1-1 Hadoop的文件系统
| 文件系统 | URI方案 | Java实现 (org.apache.hadoop) | 定义 |
| Local | file | fs.LocalFileSystem | 支持有客户端校验和本地文件系统。带有校验和的本地系统文件在fs.RawLocalFileSystem中实现。 |
| HDFS | hdfs | hdfs.DistributionFileSystem | Hadoop的分布式文件系统。 |
| HFTP | hftp | hdfs.HftpFileSystem | 支持通过HTTP方式以只读的方式访问HDFS,distcp经常用在不同的HDFS集群间复制数据。 |
| HSFTP | hsftp | hdfs.HsftpFileSystem | 支持通过HTTPS方式以只读的方式访问HDFS。 |
| HAR | har | fs.HarFileSystem | 构建在Hadoop文件系统之上,对文件进行归档。Hadoop归档文件主要用来减少NameNode的内存使用。 |
| KFS | kfs | fs.kfs.KosmosFileSystem | Cloudstore(其前身是Kosmos文件系统)文件系统是类似于HDFS和Google的GFS文件系统,使用C++编写。 |
| FTP | ftp | fs.ftp.FtpFileSystem | 由FTP服务器支持的文件系统。 |
| S3(本地) | s3n | fs.s3native.NativeS3FileSystem | 基于Amazon S3的文件系统。 |
| S3(基于块) | s3 | fs.s3.NativeS3FileSystem | 基于Amazon S3的文件系统,以块格式存储解决了S3的5GB文件大小的限制。 |
Hadoop提供了许多文件系统的接口,用户可以使用URI方案选取合适的文件系统来实现交互。
2、HDFS基础概念
2.1 数据块(block)
-
HDFS(Hadoop Distributed File System)默认的最基本的存储单位是64M的数据块。
-
和普通文件系统相同的是,HDFS中的文件是被分成64M一块的数据块存储的。
-
不同于普通文件系统的是,HDFS中,如果一个文件小于一个数据块的大小,并不占用整个数据块存储空间。
2.2 NameNode和DataNode
HDFS体系结构中有两类节点,一类是NameNode,又叫"元数据节点";另一类是DataNode,又叫"数据节点"。这两类节点分别承担Master和Worker具体任务的执行节点。
1)元数据节点用来管理文件系统的命名空间
-
其将所有的文件和文件夹的元数据保存在一个文件系统树中。
-
这些信息也会在硬盘上保存成以下文件:命名空间镜像(namespace image)及修改日志(edit log)
-
其还保存了一个文件包括哪些数据块,分布在哪些数据节点上。然而这些信息并不存储在硬盘上,而是在系统启动的时候从数据节点收集而成的。
2)数据节点是文件系统中真正存储数据的地方。
-
客户端(client)或者元数据信息(namenode)可以向数据节点请求写入或者读出数据块。
-
其周期性的向元数据节点回报其存储的数据块信息。
3)从元数据节点(secondary namenode)
-
从元数据节点并不是元数据节点出现问题时候的备用节点,它和元数据节点负责不同的事情。
-
其主要功能就是周期性将元数据节点的命名空间镜像文件和修改日志合并,以防日志文件过大。这点在下面会相信叙述。
-
合并过后的命名空间镜像文件也在从元数据节点保存了一份,以防元数据节点失败的时候,可以恢复。
2.3 元数据节点目录结构
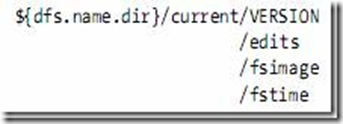
VERSION文件是java properties文件,保存了HDFS的版本号。
-
layoutVersion是一个负整数,保存了HDFS的持续化在硬盘上的数据结构的格式版本号。
-
namespaceID是文件系统的唯一标识符,是在文件系统初次格式化时生成的。
-
cTime此处为0
-
storageType表示此文件夹中保存的是元数据节点的数据结构。
namespaceID=1232737062
cTime=0
storageType=NAME_NODE
layoutVersion=-18
2.4 数据节点的目录结构
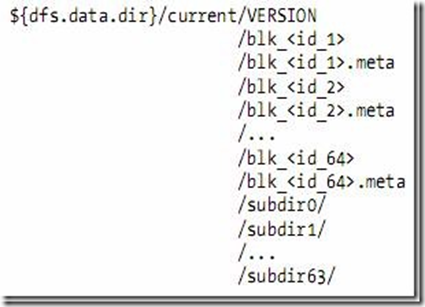
-
数据节点的VERSION文件格式如下:
namespaceID=1232737062
storageID=DS-1640411682-127.0.1.1-50010-1254997319480
cTime=0
storageType=DATA_NODE
layoutVersion=-18
-
blk_<id>保存的是HDFS的数据块,其中保存了具体的二进制数据。
-
blk_<id>.meta保存的是数据块的属性信息:版本信息,类型信息,和checksum
-
当一个目录中的数据块到达一定数量的时候,则创建子文件夹来保存数据块及数据块属性信息。
2.5 文件系统命名空间映像文件及修改日志
-
当文件系统客户端(client)进行写操作时,首先把它记录在修改日志中(edit log)
-
元数据节点在内存中保存了文件系统的元数据信息。在记录了修改日志后,元数据节点则修改内存中的数据结构。
-
每次的写操作成功之前,修改日志都会同步(sync)到文件系统。
-
fsimage文件,也即命名空间映像文件,是内存中的元数据在硬盘上的checkpoint,它是一种序列化的格式,并不能够在硬盘上直接修改。
-
同数据的机制相似,当元数据节点失败时,则最新checkpoint的元数据信息从fsimage加载到内存中,然后逐一重新执行修改日志中的操作。
-
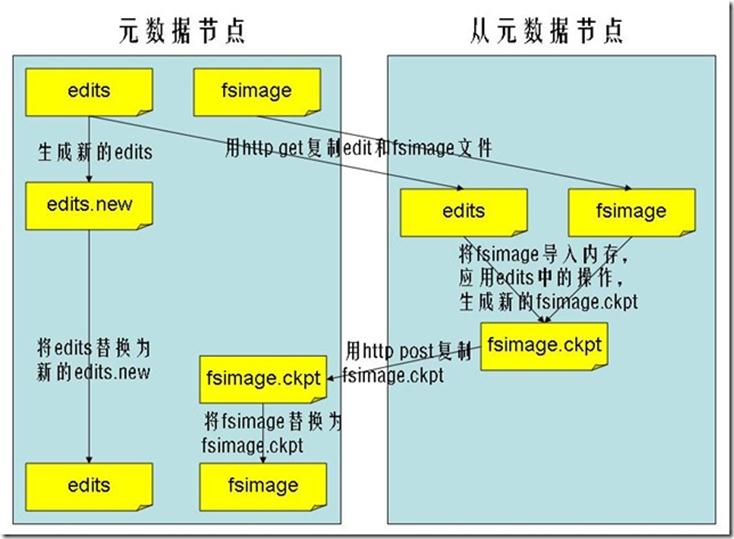
从元数据节点就是用来帮助元数据节点将内存中的元数据信息checkpoint到硬盘上的
-
checkpoint的过程如下:
-
从元数据节点通知元数据节点生成新的日志文件,以后的日志都写到新的日志文件中。
-
从元数据节点用http get从元数据节点获得fsimage文件及旧的日志文件。
-
从元数据节点将fsimage文件加载到内存中,并执行日志文件中的操作,然后生成新的fsimage文件。
-
从元数据节点奖新的fsimage文件用http post传回元数据节点
-
元数据节点可以将旧的fsimage文件及旧的日志文件,换为新的fsimage文件和新的日志文件(第一步生成的),然后更新fstime文件,写入此次checkpoint的时间。
-
这样元数据节点中的fsimage文件保存了最新的checkpoint的元数据信息,日志文件也重新开始,不会变的很大了。
-
3、HDFS体系结构
HDFS是一个主/从(Mater/Slave)体系结构,从最终用户的角度来看,它就像传统的文件系统一样,可以通过目录路径对文件执行CRUD(Create、Read、Update和Delete)操作。但由于分布式存储的性质,HDFS集群拥有一个NameNode和一些DataNode。NameNode管理文件系统的元数据,DataNode存储实际的数据。客户端通过同NameNode和DataNodes的交互访问文件系统。客户端联系NameNode以获取文件的元数据,而真正的文件I/O操作是直接和DataNode进行交互的。
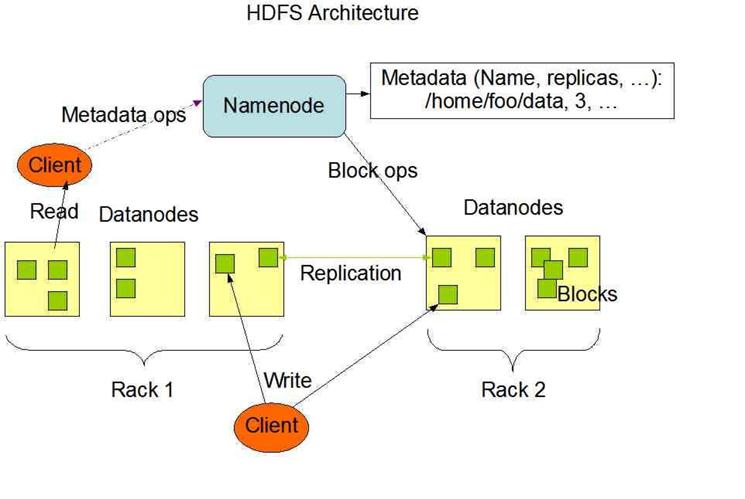
图3.1 HDFS总体结构示意图
1)NameNode、DataNode和Client
-
NameNode可以看作是分布式文件系统中的管理者,主要负责管理文件系统的命名空间、集群配置信息和存储块的复制等。NameNode会将文件系统的Meta-data存储在内存中,这些信息主要包括了文件信息、每一个文件对应的文件块的信息和每一个文件块在DataNode的信息等。
-
DataNode是文件存储的基本单元,它将Block存储在本地文件系统中,保存了Block的Meta-data,同时周期性地将所有存在的Block信息发送给NameNode。
-
Client就是需要获取分布式文件系统文件的应用程序。
2)文件写入
-
Client向NameNode发起文件写入的请求。
-
NameNode根据文件大小和文件块配置情况,返回给Client它所管理部分DataNode的信息。
-
Client将文件划分为多个Block,根据DataNode的地址信息,按顺序写入到每一个DataNode块中。
3)文件读取
-
Client向NameNode发起文件读取的请求。
-
NameNode返回文件存储的DataNode的信息。
-
Client读取文件信息。
HDFS典型的部署是在一个专门的机器上运行NameNode,集群中的其他机器各运行一个DataNode;也可以在运行NameNode的机器上同时运行DataNode,或者一台机器上运行多个DataNode。一个集群只有一个NameNode的设计大大简化了系统架构。
4、HDFS的优缺点
4.1 HDFS的优点
1)处理超大文件
这里的超大文件通常是指百MB、设置数百TB大小的文件。目前在实际应用中,HDFS已经能用来存储管理PB级的数据了。
2)流式的访问数据
HDFS的设计建立在更多地响应"一次写入、多次读写"任务的基础上。这意味着一个数据集一旦由数据源生成,就会被复制分发到不同的存储节点中,然后响应各种各样的数据分析任务请求。在多数情况下,分析任务都会涉及数据集中的大部分数据,也就是说,对HDFS来说,请求读取整个数据集要比读取一条记录更加高效。
3)运行于廉价的商用机器集群上
Hadoop设计对硬件需求比较低,只须运行在低廉的商用硬件集群上,而无需昂贵的高可用性机器上。廉价的商用机也就意味着大型集群中出现节点故障情况的概率非常高。这就要求设计HDFS时要充分考虑数据的可靠性,安全性及高可用性。
4.2 HDFS的缺点
1)不适合低延迟数据访问
如果要处理一些用户要求时间比较短的低延迟应用请求,则HDFS不适合。HDFS是为了处理大型数据集分析任务的,主要是为达到高的数据吞吐量而设计的,这就可能要求以高延迟作为代价。
改进策略:对于那些有低延时要求的应用程序,HBase是一个更好的选择。通过上层数据管理项目来尽可能地弥补这个不足。在性能上有了很大的提升,它的口号就是goes real time。使用缓存或多master设计可以降低client的数据请求压力,以减少延时。还有就是对HDFS系统内部的修改,这就得权衡大吞吐量与低延时了,HDFS不是万能的银弹。
2)无法高效存储大量小文件
因为Namenode把文件系统的元数据放置在内存中,所以文件系统所能容纳的文件数目是由Namenode的内存大小来决定。一般来说,每一个文件、文件夹和Block需要占据150字节左右的空间,所以,如果你有100万个文件,每一个占据一个Block,你就至少需要300MB内存。当前来说,数百万的文件还是可行的,当扩展到数十亿时,对于当前的硬件水平来说就没法实现了。还有一个问题就是,因为Map task的数量是由splits来决定的,所以用MR处理大量的小文件时,就会产生过多的Maptask,线程管理开销将会增加作业时间。举个例子,处理10000M的文件,若每个split为1M,那就会有10000个Maptasks,会有很大的线程开销;若每个split为100M,则只有100个Maptasks,每个Maptask将会有更多的事情做,而线程的管理开销也将减小很多。
改进策略:要想让HDFS能处理好小文件,有不少方法。
-
利用SequenceFile、MapFile、Har等方式归档小文件,这个方法的原理就是把小文件 归档起来管理,HBase就是基于此的。对于这种方法,如果想找回原来的小文件内容,那就必须得知道与归档文件的 映射关系。
-
横向扩展,一个Hadoop集群能管理的小文件有限,那就把几个Hadoop集群拖在一个虚拟服务器后面,形成一个大的Hadoop集群。google也是这么干过的。
-
多Master设计,这个作用显而易见了。正在研发中的GFS II也要改为分布式多Master设计,还支持Master的Failover,而且Block大小改为1M,有意要调优处理小文件啊。
-
附带个Alibaba DFS的设计,也是多Master设计,它把Metadata的映射存储和管理分开了,由多个Metadata存储节点和一个查询Master节点组成。
3)不支持多用户写入及任意修改文件
在HDFS的一个文件中只有一个写入者,而且写操作只能在文件末尾完成,即只能执行追加操作。目前HDFS还不支持多个用户对同一文件的写操作,以及在文件任意位置进行修改。
5、HDFS常用操作
先说一下"hadoop fs 和hadoop dfs的区别",看两本Hadoop书上各有用到,但效果一样,求证与网络发现下面一解释比较中肯。
粗略的讲,fs是个比较抽象的层面,在分布式环境中,fs就是dfs,但在本地环境中,fs是local file system,这个时候dfs就不能用。
5.1 文件操作
1)列出HDFS文件
此处为你展示如何通过"-ls"命令列出HDFS下的文件:
hadoop fs -ls
执行结果如图5-1-1所示。在这里需要注意:在HDFS中未带参数的"-ls"命名没有返回任何值,它默认返回HDFS的"home"目录下的内容。在HDFS中,没有当前目录这样一个概念,也没有cd这个命令。

图5-1-1 列出HDFS文件
2)列出HDFS目录下某个文档中的文件
此处为你展示如何通过"-ls 文件名"命令浏览HDFS下名为"input"的文档中文件:
hadoop fs –ls input
执行结果如图5-1-2所示。

图5-1-2 列出HDFS下名为input的文档下的文件
3)上传文件到HDFS
此处为你展示如何通过"-put 文件1 文件2"命令将"Master.Hadoop"机器下的"/home/hadoop"目录下的file文件上传到HDFS上并重命名为test:
hadoop fs –put ~/file test
执行结果如图5-1-3所示。在执行"-put"时只有两种可能,即是执行成功和执行失败。在上传文件时,文件首先复制到DataNode上。只有所有的DataNode都成功接收完数据,文件上传才是成功的。其他情况(如文件上传终端等)对HDFS来说都是做了无用功。
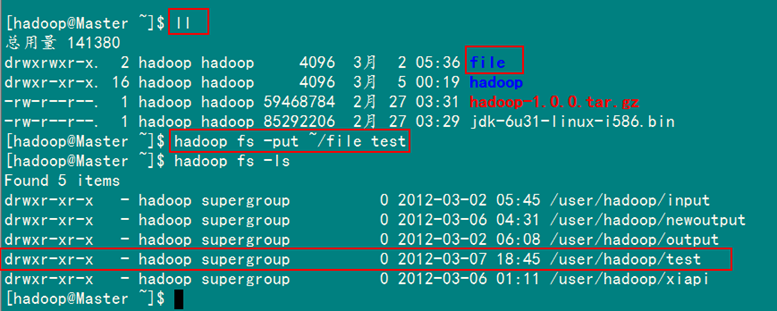
图5-1-3 成功上传file到HDFS
4)将HDFS中文件复制到本地系统中
此处为你展示如何通过"-get 文件1 文件2"命令将HDFS中的"output"文件复制到本地系统并命名为"getout"。
hadoop fs –get output getout
执行结果如图5-1-4所示。

图5-1-4 成功将HDFS中output文件复制到本地系统
备注:与"-put"命令一样,"-get"操作既可以操作文件,也可以操作目录。
5)删除HDFS下的文档
此处为你展示如何通过"-rmr 文件"命令删除HDFS下名为"newoutput"的文档:
hadoop fs –rmr newoutput
执行结果如图5-1-5所示。
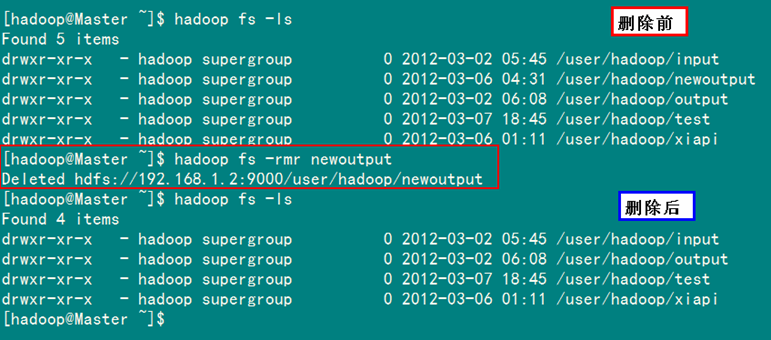
图5-1-5 成功删除HDFS下的newoutput文档
6)查看HDFS下某个文件
此处为你展示如何通过"-cat 文件"命令查看HDFS下input文件中内容:
hadoop fs -cat input/*
执行结果如图5-1-6所示。
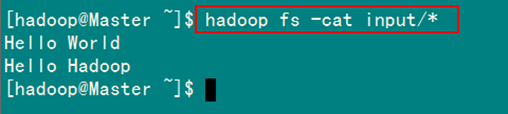
图5-1-6 HDFS下input文件的内容
"hadoop fs"的命令远不止这些,本小节介绍的命令已可以在HDFS上完成大多数常规操作。对于其他操作,可以通过"-help commandName"命令所列出的清单来进一步学习与探索。
5.2 管理与更新
1)报告HDFS的基本统计情况
此处为你展示通过"-report"命令如何查看HDFS的基本统计信息:
hadoop dfsadmin -report
执行结果如图5-2-1所示。
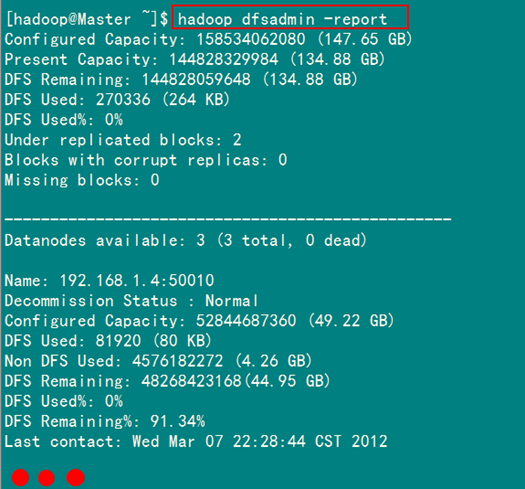
图5-2-1 HDFS基本统计信息
2)退出安全模式
NameNode在启动时会自动进入安全模式。安全模式是NameNode的一种状态,在这个阶段,文件系统不允许有任何修改。安全模式的目的是在系统启动时检查各个DataNode上数据块的有效性,同时根据策略对数据块进行必要的复制或删除,当数据块最小百分比数满足的最小副本数条件时,会自动退出安全模式。
系统显示"Name node is in safe mode",说明系统正处于安全模式,这时只需要等待17秒即可,也可以通过下面的命令退出安全模式:
hadoop dfsadmin –safemode enter
成功退出安全模式结果如图5-2-2所示。

图5-2-2 成功退出安全模式
3)进入安全模式
在必要情况下,可以通过以下命令把HDFS置于安全模式:
hadoop dfsadmin –safemode enter
执行结果如图5-2-3所示。

图5-2-3 进入HDFS安全模式
4)添加节点
可扩展性是HDFS的一个重要特性,向HDFS集群中添加节点是很容易实现的。添加一个新的DataNode节点,首先在新加节点上安装好Hadoop,要和NameNode使用相同的配置(可以直接从NameNode复制),修改"/usr/hadoop/conf/master"文件,加入NameNode主机名。然后在NameNode节点上修改"/usr/hadoop/conf/slaves"文件,加入新节点主机名,再建立到新加点无密码的SSH连接,运行启动命令:
start-all.sh
5)负载均衡
HDFS的数据在各个DataNode中的分布肯能很不均匀,尤其是在DataNode节点出现故障或新增DataNode节点时。新增数据块时NameNode对DataNode节点的选择策略也有可能导致数据块分布的不均匀。用户可以使用命令重新平衡DataNode上的数据块的分布:
start-balancer.sh
执行命令前,DataNode节点上数据分布情况如图5-2-4所示。
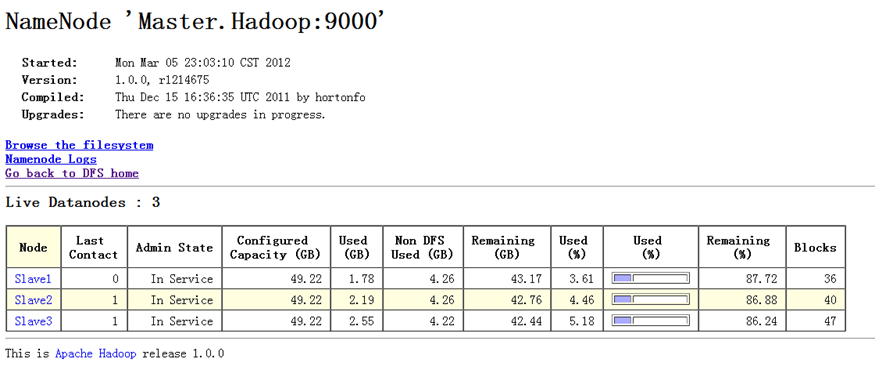
负载均衡完毕后,DataNode节点上数据的分布情况如图5-2-5所示。
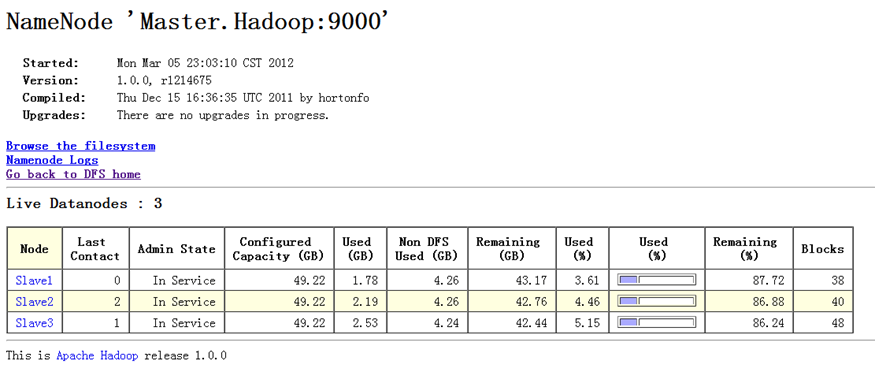
执行负载均衡命令如图5-2-6所示。

6、HDFS API详解
Hadoop中关于文件操作类基本上全部是在"org.apache.hadoop.fs"包中,这些API能够支持的操作包含:打开文件,读写文件,删除文件等。
Hadoop类库中最终面向用户提供的接口类是FileSystem,该类是个抽象类,只能通过来类的get方法得到具体类。get方法存在几个重载版本,常用的是这个:
static FileSystem get(Configuration conf);
该类封装了几乎所有的文件操作,例如mkdir,delete等。综上基本上可以得出操作文件的程序库框架:
operator()
{
得到Configuration对象
得到FileSystem对象
进行文件操作
}
6.1 上传本地文件
通过"FileSystem.copyFromLocalFile(Path src,Patch dst)"可将本地文件上传到HDFS的制定位置上,其中src和dst均为文件的完整路径。具体事例如下:
package com.hebut.file;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileStatus;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
publicclass CopyFile {
public staticvoid main(String[] args)throws Exception {
Configuration conf=new Configuration();
FileSystem hdfs=FileSystem.get(conf);
//本地文件
Path src =new Path("D:\\HebutWinOS");
//HDFS为止
Path dst =new Path("/");
hdfs.copyFromLocalFile(src, dst);
System.out.println("Upload to"+conf.get("fs.default.name"));
FileStatus files[]=hdfs.listStatus(dst);
for(FileStatus file:files){
System.out.println(file.getPath());
}
}
}
运行结果可以通过控制台、项目浏览器和SecureCRT查看,如图6-1-1、图6-1-2、图6-1-3所示。
1)控制台结果

图6-1-1 运行结果(1)
2)项目浏览器
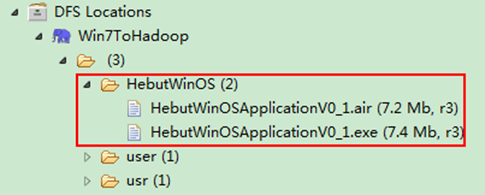
图6-1-2 运行结果(2)
3)SecureCRT结果
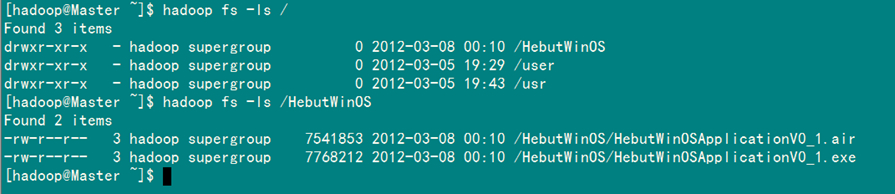
图6-1-3 运行结果(3)
6.2 创建HDFS文件
通过"FileSystem.create(Path f)"可在HDFS上创建文件,其中f为文件的完整路径。具体实现如下:
package com.hebut.file;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FSDataOutputStream;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
publicclass CreateFile {
public staticvoid main(String[] args)throws Exception {
Configuration conf=new Configuration();
FileSystem hdfs=FileSystem.get(conf);
byte[] buff="hello hadoop world!\n".getBytes();
Path dfs=new Path("/test");
FSDataOutputStream outputStream=hdfs.create(dfs);
outputStream.write(buff,0,buff.length);
}
}
运行结果如图6-2-1和图6-2-2所示。
1)项目浏览器
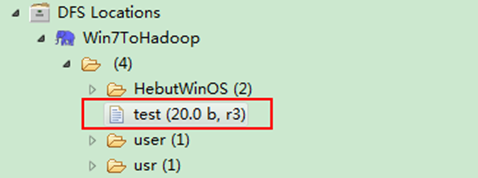
图6-2-1 运行结果(1)
2)SecureCRT结果
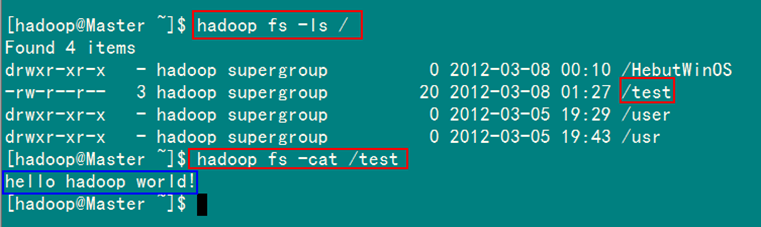
图6-2-2 运行结果(2)
6.3 创建HDFS目录
通过"FileSystem.mkdirs(Path f)"可在HDFS上创建文件夹,其中f为文件夹的完整路径。具体实现如下:
package com.hebut.dir;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
publicclass CreateDir {
public staticvoid main(String[] args)throws Exception{
Configuration conf=new Configuration();
FileSystem hdfs=FileSystem.get(conf);
Path dfs=new Path("/TestDir");
hdfs.mkdirs(dfs);
}
}
运行结果如图6-3-1和图6-3-2所示。
1)项目浏览器
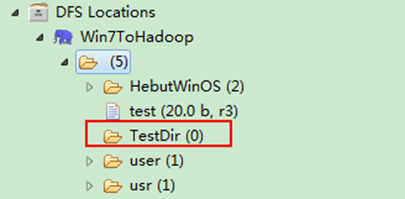
图6-3-1 运行结果(1)
2)SecureCRT结果
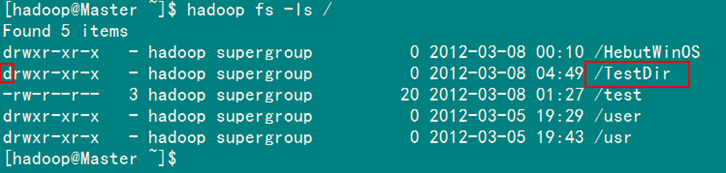
图6-3-2 运行结果(2)
6.4 重命名HDFS文件
通过"FileSystem.rename(Path src,Path dst)"可为指定的HDFS文件重命名,其中src和dst均为文件的完整路径。具体实现如下:
package com.hebut.file;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
publicclass Rename{
public staticvoid main(String[] args)throws Exception {
Configuration conf=new Configuration();
FileSystem hdfs=FileSystem.get(conf);
Path frpaht=new Path("/test"); //旧的文件名
Path topath=new Path("/test1"); //新的文件名
boolean isRename=hdfs.rename(frpaht, topath);
String result=isRename?"成功":"失败";
System.out.println("文件重命名结果为:"+result);
}
}
运行结果如图6-4-1和图6-4-2所示。
1)项目浏览器
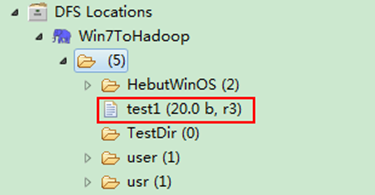
图6-4-1 运行结果(1)
2)SecureCRT结果
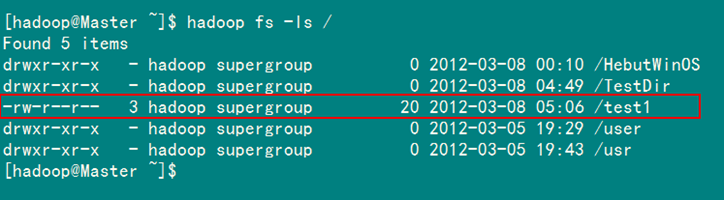
图6-4-2 运行结果(2)
6.5 删除HDFS上的文件
通过"FileSystem.delete(Path f,Boolean recursive)"可删除指定的HDFS文件,其中f为需要删除文件的完整路径,recuresive用来确定是否进行递归删除。具体实现如下:
package com.hebut.file;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
publicclass DeleteFile {
public staticvoid main(String[] args)throws Exception {
Configuration conf=new Configuration();
FileSystem hdfs=FileSystem.get(conf);
Path delef=new Path("/test1");
boolean isDeleted=hdfs.delete(delef,false);
//递归删除
//boolean isDeleted=hdfs.delete(delef,true);
System.out.println("Delete?"+isDeleted);
}
}
运行结果如图6-5-1和图6-5-2所示。
1)控制台结果

图6-5-1 运行结果(1)
2)项目浏览器
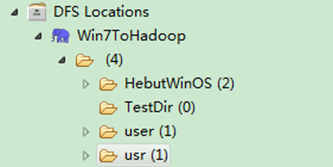
图6-5-2 运行结果(2)
6.6 删除HDFS上的目录
同删除文件代码一样,只是换成删除目录路径即可,如果目录下有文件,要进行递归删除。
6.7 查看某个HDFS文件是否存在
通过"FileSystem.exists(Path f)"可查看指定HDFS文件是否存在,其中f为文件的完整路径。具体实现如下:
package com.hebut.file;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
publicclass CheckFile {
public staticvoid main(String[] args)throws Exception {
Configuration conf=new Configuration();
FileSystem hdfs=FileSystem.get(conf);
Path findf=new Path("/test1");
boolean isExists=hdfs.exists(findf);
System.out.println("Exist?"+isExists);
}
}
运行结果如图6-7-1和图6-7-2所示。
1)控制台结果

图6-7-1 运行结果(1)
2)项目浏览器
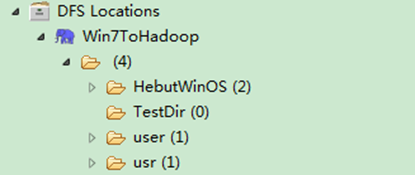
图6-7-2 运行结果(2)
6.8 查看HDFS文件的最后修改时间
通过"FileSystem.getModificationTime()"可查看指定HDFS文件的修改时间。具体实现如下:
package com.hebut.file;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileStatus;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
publicclass GetLTime {
public staticvoid main(String[] args)throws Exception {
Configuration conf=new Configuration();
FileSystem hdfs=FileSystem.get(conf);
Path fpath =new Path("/user/hadoop/test/file1.txt");
FileStatus fileStatus=hdfs.getFileStatus(fpath);
long modiTime=fileStatus.getModificationTime();
System.out.println("file1.txt的修改时间是"+modiTime);
}
}
运行结果如图6-8-1所示。
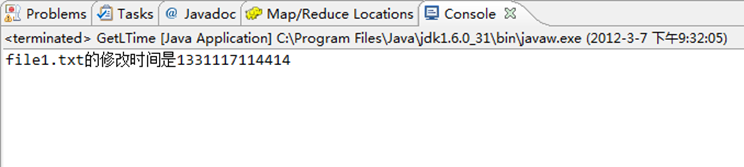
图6-8-1 控制台结果
6.9 读取HDFS某个目录下的所有文件
通过"FileStatus.getPath()"可查看指定HDFS中某个目录下所有文件。具体实现如下:
package com.hebut.file;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileStatus;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
publicclass ListAllFile {
public staticvoid main(String[] args)throws Exception {
Configuration conf=newConfiguration();
FileSystem hdfs=FileSystem.get(conf);
Path listf =new Path("/user/hadoop/test");
FileStatus stats[]=hdfs.listStatus(listf);
for(int i = 0; i < stats.length; ++i)
{
System.out.println(stats[i].getPath().toString());
}
hdfs.close();
}
}
运行结果如图6-9-1和图6-9-2所示。
1)控制台结果

图6-9-1 运行结果(1)
2)项目浏览器
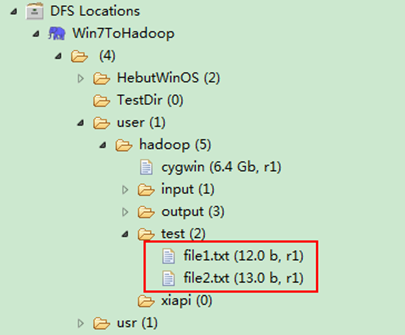
图6-9-2 运行结果(2)
6.10 查找某个文件在HDFS集群的位置
通过"FileSystem.getFileBlockLocation(FileStatus file,long start,long len)"可查找指定文件在HDFS集群上的位置,其中file为文件的完整路径,start和len来标识查找文件的路径。具体实现如下:
package com.hebut.file;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.BlockLocation;
import org.apache.hadoop.fs.FileStatus;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
publicclass FileLoc {
public staticvoid main(String[] args)throws Exception {
Configuration conf=new Configuration();
FileSystem hdfs=FileSystem.get(conf);
Path fpath=new Path("/user/hadoop/cygwin");
FileStatus filestatus = hdfs.getFileStatus(fpath);
BlockLocation[] blkLocations = hdfs.getFileBlockLocations(filestatus, 0, filestatus.getLen());
int blockLen = blkLocations.length;
for(int i=0;i<blockLen;i++){
String[] hosts = blkLocations[i].getHosts();
System.out.println("block_"+i+"_location:"+hosts[0]);
}
}
}
运行结果如图6-10-1和6.10.2所示。
1)控制台结果
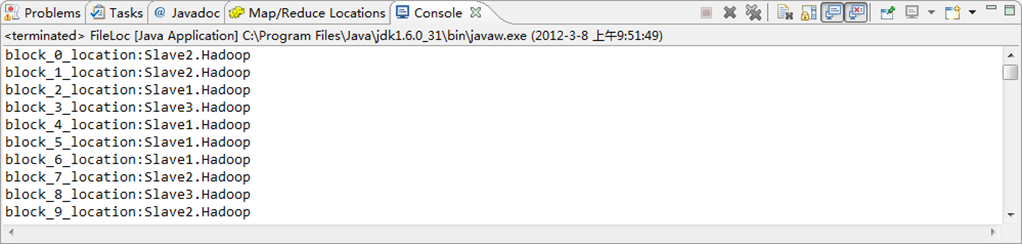
图6-10-1 运行结果(1)
2)项目浏览器
图6-10-2 运行结果(2)
6.11 获取HDFS集群上所有节点名称信息
通过"DatanodeInfo.getHostName()"可获取HDFS集群上的所有节点名称。具体实现如下:
package com.hebut.file;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.hdfs.DistributedFileSystem;
import org.apache.hadoop.hdfs.protocol.DatanodeInfo;
publicclass GetList {
public staticvoid main(String[] args)throws Exception {
Configuration conf=new Configuration();
FileSystem fs=FileSystem.get(conf);
DistributedFileSystem hdfs = (DistributedFileSystem)fs;
DatanodeInfo[] dataNodeStats = hdfs.getDataNodeStats();
for(int i=0;i<dataNodeStats.length;i++){
System.out.println("DataNode_"+i+"_Name:"+dataNodeStats[i].getHostName());
}
}
}
运行结果如图6-11-1所示。
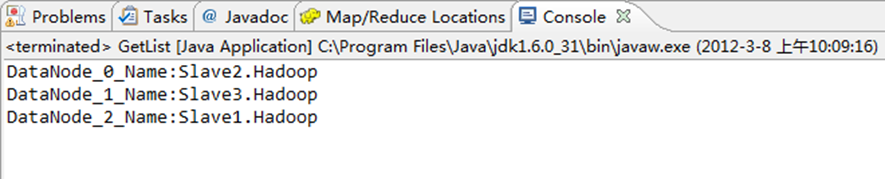
图6-11-1 控制台结果
7、HDFS的读写数据流
7.1 文件的读取剖析
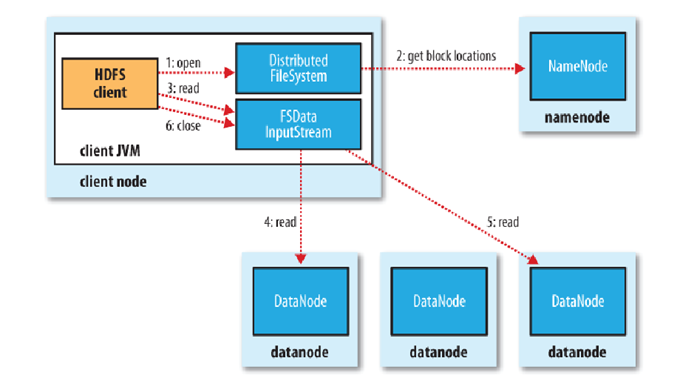
文件读取的过程如下:
1)解释一
-
客户端(client)用FileSystem的open()函数打开文件。
-
DistributedFileSystem用RPC调用元数据节点,得到文件的数据块信息。
-
对于每一个数据块,元数据节点返回保存数据块的数据节点的地址。
-
DistributedFileSystem返回FSDataInputStream给客户端,用来读取数据。
-
客户端调用stream的read()函数开始读取数据。
-
DFSInputStream连接保存此文件第一个数据块的最近的数据节点。
-
Data从数据节点读到客户端(client)。
-
当此数据块读取完毕时,DFSInputStream关闭和此数据节点的连接,然后连接此文件下一个数据块的最近的数据节点。
-
当客户端读取完毕数据的时候,调用FSDataInputStream的close函数。
-
在读取数据的过程中,如果客户端在与数据节点通信出现错误,则尝试连接包含此数据块的下一个数据节点。
-
失败的数据节点将被记录,以后不再连接。
2)解释二
-
使用HDFS提供的客户端开发库,向远程的Namenode发起RPC请求;
-
Namenode会视情况返回文件的部分或者全部block列表,对于每个block,Namenode都会返回有该block拷贝的datanode地址;
-
客户端开发库会选取离客户端最接近的datanode来读取block;
-
读取完当前block的数据后,关闭与当前的datanode连接,并为读取下一个block寻找最佳的datanode;
-
当读完列表的block后,且文件读取还没有结束,客户端开发库会继续向Namenode获取下一批的block列表。
-
读取完一个block都会进行checksum验证,如果读取datanode时出现错误,客户端会通知Namenode,然后再从下一个拥有该block拷贝的datanode继续读。
7.2 文件的写入剖析

写入文件的过程比读取较为复杂:
1)解释一
-
客户端调用create()来创建文件
-
DistributedFileSystem用RPC调用元数据节点,在文件系统的命名空间中创建一个新的文件。
-
元数据节点首先确定文件原来不存在,并且客户端有创建文件的权限,然后创建新文件。
-
DistributedFileSystem返回DFSOutputStream,客户端用于写数据。
-
客户端开始写入数据,DFSOutputStream将数据分成块,写入data queue。
-
Data queue由Data Streamer读取,并通知 元数据节点分配 数据节点,用来存储数据块(每块默认复制3块)。分配的数据节点放在一个pipeline里。
-
Data Streamer将数据块写入pipeline中的第一个数据节点。第一个数据节点将数据块发送给第二个数据节点。第二个数据节点将数据发送给第三个数据节点。
-
DFSOutputStream为发出去的数据块保存了ack queue,等待pipeline中的数据节点告知数据已经写入成功。
-
如果数据节点在写入的过程中失败:
-
关闭pipeline,将ack queue中的数据块放入data queue的开始。
-
当前的数据块在已经写入的数据节点中被元数据节点赋予新的标示,则错误节点重启后能够察觉其数据块是过时的,会被删除。
-
失败的数据节点从pipeline中移除,另外的数据块则写入pipeline中的另外两个数据节点。
-
元数据节点则被通知此数据块是复制块数不足,将来会再创建第三份备份。
-
-
当客户端结束写入数据,则调用stream的close函数。此操作将所有的数据块写入pipeline中的数据节点,并等待ack queue返回成功。 最后通知元数据节点写入完毕。
2)解释二
-
使用HDFS提供的客户端开发库,向远程的Namenode发起RPC请求;
-
Namenode会检查要创建的文件是否已经存在,创建者是否有权限进行操作,成功则会为文件创建一个记录,否则会让客户端抛出异常;
-
当客户端开始写入文件的时候,开发库会将文件切分成多个packets,并在内部以"data queue"的形式管理这些packets,并向Namenode申请新的blocks,获取用来存储replicas的合适的datanodes列表,列表的大小根据在Namenode中对replication的设置而定。
-
开始以pipeline(管道)的形式将packet写入所有的replicas中。开发库把packet以流的方式写入第一个datanode,该datanode把该packet存储之后,再将其传递给在此pipeline中的下一个datanode,直到最后一个datanode,这种写数据的方式呈流水线的形式。
-
最后一个datanode成功存储之后会返回一个ack packet,在pipeline里传递至客户端,在客户端的开发库内部维护着"ack queue",成功收到datanode返回的ack packet后会从"ack queue"移除相应的packet。
-
如果传输过程中,有某个datanode出现了故障,那么当前的pipeline会被关闭,出现故障的datanode会从当前的pipeline中移除,剩余的block会继续剩下的datanode中继续以pipeline的形式传输,同时Namenode会分配一个新的datanode,保持replicas设定的数量。

