
- 1Python sorted与lambda表达式结合的用法_sorted lamda
- 2双人贪吃蛇@botzone数据格式_botzone数据怎么用
- 3基于python下django框架 实现校园网站系统详细设计_基于django个设
- 4【无服务器数据库】如何创建一个非常便宜的无服务器数据库_谷歌 firebase与阿里
- 5Spark 数据读取保存_spark saveastextfile
- 6懂点人情世故,让你少吃亏。
- 7iOS 如何使用TestFlight进行测试_testfilght we require for you help
- 8mediasoup源码分析(三)channel创建及信令交互_channel request 信令
- 9【安卓】Android API 指南之数据存储(Data Storage)之存储选项(Storage Options)
- 10ROS入门21讲---常用可视化工具的使用及课程总结_ros可视化工具心得
[转]出租车轨迹处理(一):预处理+DBSCAN聚类+gmplot可视化_出租车轨迹聚类结果的可视化
赞
踩
1、认识数据
我要处理的是2015年成都市的出租车数据
数据格式及示例为:
出租车ID,纬度,经度,载客状态(1表示载客,0表示无客),时间点
1, 30.4996330000,103.9771760000,1,2014/08/03 06:01:22
1, 30.4936580000,104.0036220000,1,2014/08/03 06:02:22
2, 30.6319760000,104.0384040000,0,2014/08/03 06:01:13
2, 30.6318830000,104.0366790000,1,2014/08/03 06:02:53
- import pandas as pd
- import numpy as np
- import datatime
- f=open('D:\动态人口分布实验\交通赛数据_下\\20140816_train.txt')
- data=pd.read_csv(f,names=['ID','lat','lon','passager','time'])
2、对数据进行简单预处理
由于我的兴趣只在于出租车的载客位置与卸客位置,于是需要做一个简单的预处理,把载客状态变更(0变1、1变0)的行提取出来。
于是一个简单的做法就是把每一行的“载客状态”,减去上一行或者下一行。所以需要对这一列数据整体进行一个向上或向下平移,生成一个新列,然后做一个两列相减。
然后,要删除掉对后续数据分析无意义的列,减少数据量。
最后,使用pandas强大的索引功能,只选取载客状态变更的数据,进行后续计算。
- data['passager_1']=data['passager'].shift(1)
- data['change']=data['passager']-data['passager_1']
- data=data.drop(['passager_1'],axis=1) #axis=0 为删掉某行; axis=1位删掉某列
- data=data.loc[(data['change']==1) |(data['change']==-1)]
3、时间数据的处理
这部分看似简单,但由于基础太差,真心是踩了不少坑。
首先是,要把代表时间的那一列,转换为pandas的datetime类型。
其次,把这一列设置为索引。
- data['time']=pd.to_datetime(data['time'])
- data=data.set_index('time')
- print(data['2014-08-16 09:00:00':'2014-08-16 10:00:00'])
其次为了观察数据的空间分布,保存了一下文件:
data.to_csv('D:\深度学习估算人口\data.csv')
CSV文件可以导入Arcgis中看一下分布。
但是还是想学习一下如何用Python进行可视化。
学习了这两篇博文
1、使用Python加载谷歌地图并可视化
https://blog.csdn.net/qq_38684480/article/details/851237772、 Inferring home and work locations using GPS trajectories and DBSCAN
https://yidatao.github.io/2016-12-23/geolife-dbscan/
于是尝试着实现可视化:
- import gmplot
- data=data.sort_index() #突然发现数据本身的排序并非是严格按照时间,于是还要先进行一个排序
- gmap=gmplot.GoogleMapPlotter(data.lat[0],data.lon[0],11)
- data1=data.loc[data['ID']==1]
- gmap.plot(data1.lat,data1.lon)
- gmap.draw('user001_map.html')
4、位置数据的处理
这次数据好的地方在于位置数据都是用经纬度显示,但是有时轨迹数据的位置信息是用Geohash后编码数据表示,因此还需要进行解码。
如之前处理的MOBIKE数据,数据如下: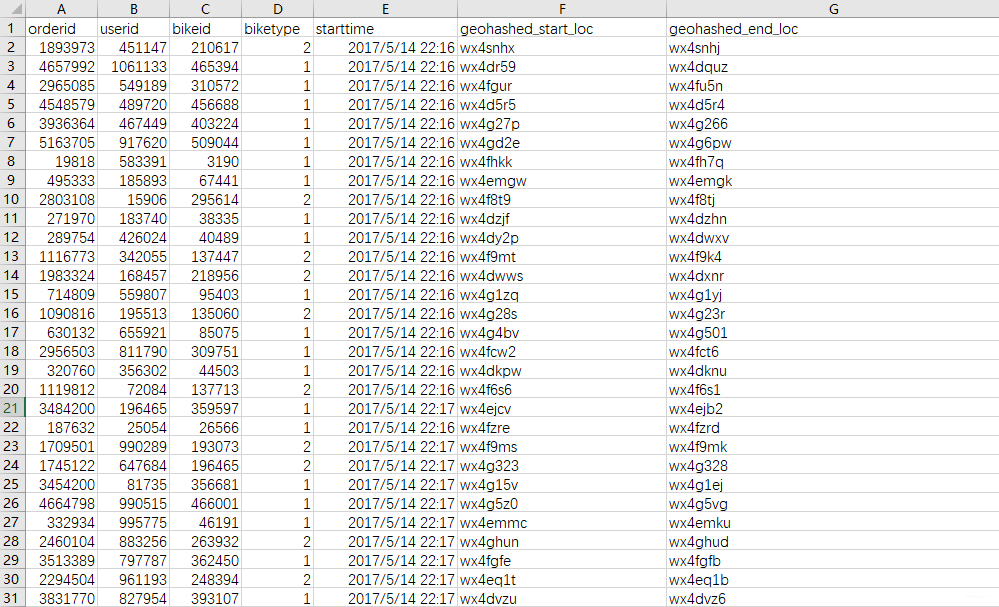
可以看出位置两列并非是经纬度。于是需要进行解码。还有一个小知识点是关于数据的切片:pd.iloc
- import numpy as np
- import pandas as pd
- import Geohash as geohash
-
- # 获取出发地的经纬度
- def get_eloc_latlon(result):
- eloc_latlon = result['geohashed_end_loc'].apply(lambda x: geohash.decode_exactly(x)[:2])
- result['eloc_lat'] = eloc_latlon.apply(lambda x: float(x[0]))
- result['eloc_lon'] = eloc_latlon.apply(lambda x: float(x[1]))
- return result
- def get_sloc_latlon(result):
- sloc_latlon = result['geohashed_start_loc'].apply(lambda x: geohash.decode_exactly(x)[:2])
- result['sloc_lat'] = sloc_latlon.apply(lambda x: float(x[0]))
- result['sloc_lon'] = sloc_latlon.apply(lambda x: float(x[1]))
- return result
-
- data=pd.DataFrame(pd.read_csv('H:\python program\Mobike-master\\train.csv'))
-
- X = np.array(data[['geohashed_start_loc', 'geohashed_end_loc']])
- #print(X[:10,:])
- X=get_eloc_latlon(data)
- X=get_sloc_latlon(data)
- X.to_csv('H:\python program\Mobike-master\\train_lonlat.csv')
- Y=pd.read_csv('H:\python program\Mobike-master\\train_lonlat.csv')
- YY=Y.iloc[0:10]
- print(YY.info())
- YY.to_csv('H:\python program\Mobike-master\\train_lonlat10.csv')
-

5、DBSCAN聚类分析
- 聚类
- # 也许是由于数据量太大,导致聚类失败,故只选择10辆出租车的数据进行尝试
- data1=data.loc[data['ID']<10]
- from sklearn.cluster import DBSCAN
- from sklearn import metrics
-
- # represent GPS points as (lat, lon)
- coords = data1.as_matrix(columns=['lat', 'lon'])
-
- # earth's radius in km
- kms_per_radian = 6371.0088
- # define epsilon as 0.5 kilometers, converted to radians for use by haversine
- epsilon = 0.5 / kms_per_radian
-
- # eps is the max distance that points can be from each other to be considered in a cluster
- # min_samples is the minimum cluster size (everything else is classified as noise)
- db = DBSCAN(eps=epsilon, min_samples=100, algorithm='ball_tree', metric='haversine').fit(np.radians(coords))
- cluster_labels = db.labels_
- # get the number of clusters (ignore noisy samples which are given the label -1)
- num_clusters = len(set(cluster_labels) - set([-1]))
-
- print ('Clustered ' + str(len(data1)) + ' points to ' + str(num_clusters) + ' clusters')
-
- # turn the clusters in to a pandas series
- clusters = pd.Series([coords[cluster_labels == n] for n in range(num_clusters)])
- clusters
-
-
结果是聚成了4类
- Clustered 6304 points to 4 clusters
- 0 [[30.694546000000003, 104.064254], [30.694587,...
- 1 [[30.642768, 104.041161], [30.642794, 104.0410...
- 2 [[30.571728999999998, 103.964786], [30.5734200...
- 3 [[30.649578, 104.062095], [30.6518, 104.063633...
- dtype: object
2)
- from shapely.geometry import MultiPoint
- from geopy.distance import great_circle
- def get_centermost_point(cluster):
- centroid = (MultiPoint(cluster).centroid.x, MultiPoint(cluster).centroid.y)
- centermost_point = min(cluster, key=lambda point: great_circle(point, centroid).m)
- return tuple(centermost_point)
-
- # get the centroid point for each cluster
- centermost_points = clusters.map(get_centermost_point)
- lats, lons = zip(*centermost_points)
- rep_points = pd.DataFrame({'lon':lons, 'lat':lats})
-
3) 可视化
- import matplotlib.pyplot as plt # 注意,是matplotlib.pyplot,不然没有plt.subplots模块
- fig, ax = plt.subplots(figsize=[10, 6])
- rs_scatter = ax.scatter(rep_points['lon'][0], rep_points['lat'][0], c='#99cc99', edgecolor='None', alpha=0.7, s=450)
- ax.scatter(rep_points['lon'][1], rep_points['lat'][1], c='#99cc99', edgecolor='None', alpha=0.7, s=250)
- ax.scatter(rep_points['lon'][2], rep_points['lat'][2], c='#99cc99', edgecolor='None', alpha=0.7, s=250)
- ax.scatter(rep_points['lon'][3], rep_points['lat'][3], c='#99cc99', edgecolor='None', alpha=0.7, s=150)
- df_scatter = ax.scatter(data1['lon'], data1['lat'], c='k', alpha=0.9, s=3)
- ax.set_title('Full GPS trace vs. DBSCAN clusters')
- ax.set_xlabel('Longitude')
- ax.set_ylabel('Latitude')
- ax.legend([df_scatter, rs_scatter], ['GPS points', 'Cluster centers'], loc='upper right')
-
- labels = ['cluster{0}'.format(i) for i in range(1, num_clusters+1)]
- for label, x, y in zip(labels, rep_points['lon'], rep_points['lat']):
- plt.annotate(
- label,
- xy = (x, y), xytext = (-25, -30),
- textcoords = 'offset points', ha = 'right', va = 'bottom',
- bbox = dict(boxstyle = 'round,pad=0.5', fc = 'white', alpha = 0.5),
- arrowprops = dict(arrowstyle = '->', connectionstyle = 'arc3,rad=0'))
-
- plt.show()
可视化结果如下: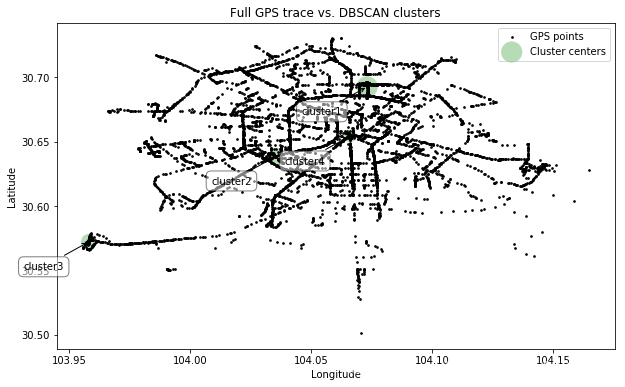
之后生成热力图:
使用了gmplot库,生成一个网页,从浏览器打开即可。
- import gmplot
- gmap = gmplot.GoogleMapPlotter(rep_points['lat'][0], rep_points['lon'][0], 11)
- #gmap.plot(data1.lat, data1.lon)
- gmap.heatmap(rep_points['lat'][:4], rep_points['lon'][:4], radius=20)
- gmap.draw("user_work_home.html")
6、一些其他统计分析
1)按小时统计成都市一天内的上客人数、卸客人数
其中,花费我较多时间的是找到 resample 函数,这真的是一个很有用的功能,具体可以查询《使用python进行数据分析》一书。别的博客还有用时间数据groupby的,可惜我没有实验成功,不知道是否可行。
- #首先还是要分别提取出上客数据、卸客数据
- PUP=data.loc[data['change']==1]
- DOP=data.loc[data['change']==-1]
- # 上客人数的可视化
- PUP=PUP.resample('H').sum()
- M=PUP['change'].plot(title='passagers')
- fig=M.get_figure()
- fig.set_size_inches(20,9)
- # 由于卸客人数数据的change是-1,所以增添一个新列,取【change】的绝对值,然后再汇总、显示
- DOP['num']=abs(DOP['change'])
- DOP=DOP.resample('H').sum()
- N=DOP['num'].plot(title='passagers')
- fig=N.get_figure()
- fig.set_size_inches(20,9)
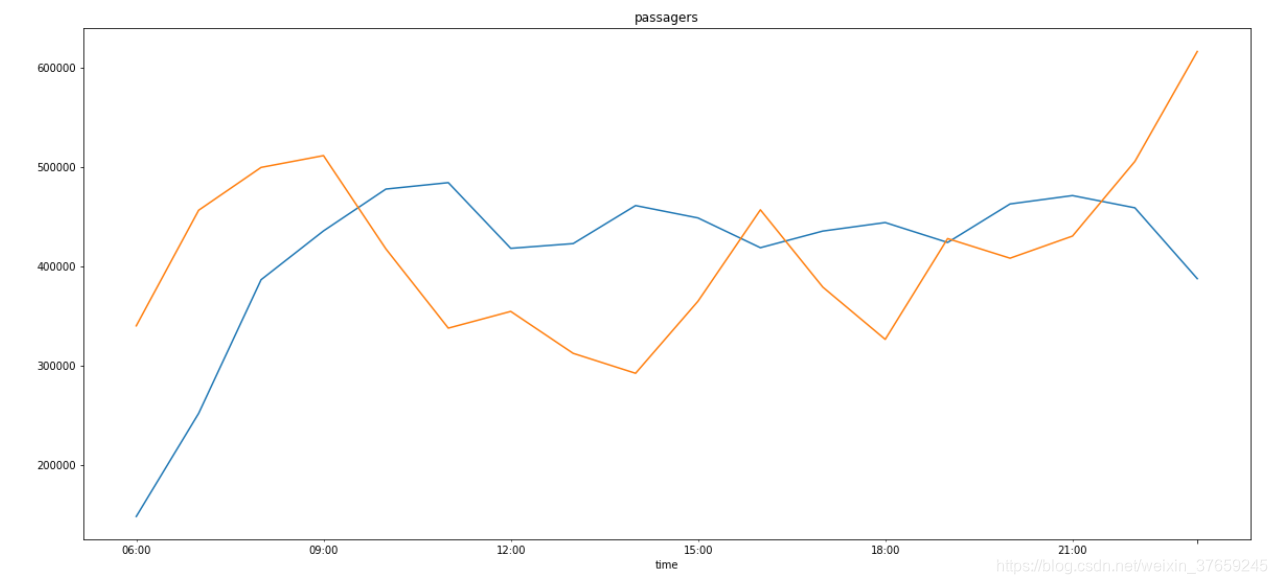
2) 统计一下不同时间段的“净流量”:上客人数—卸客人数
- FLOW['flow']=PUP['change']-DOP['num']
- FF=FLOW['flow'].plot(title='passagers')
- fig=N.get_figure()
- fig.set_size_inches(20,9)
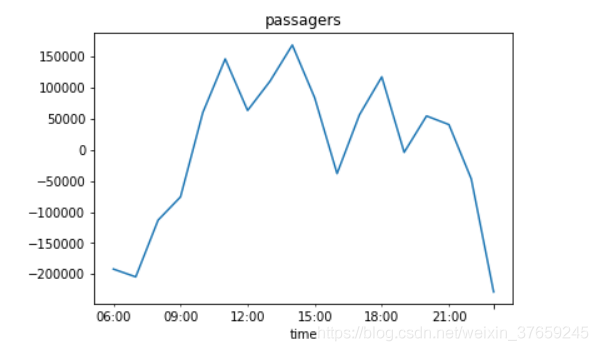
---------------------
作者:菜鸡的自我拯救
来源:CSDN
原文:https://blog.csdn.net/weixin_37659245/article/details/89306413

