
- 1io等待为什么引发cpu过高_一文搞懂,网络IO模型
- 2將IP地址改成自動獲取的詳細步驟
- 3python最简单的游戏代码,python最简单游戏代码_python20行贪吃蛇代码
- 4gitbook与Typora的使用_typora 与gitbook的高级用法
- 5扩散模型与生成模型详解_扩散生成模型
- 6如何使用git(同一账号)在多台电脑协同做工_git一个账号在两台电脑登录
- 7如何赚钱?聊聊程序员的副业与生意
- 8手机termux免root安装kali:一步到位+图形界面_termux安装kali-_termux手机版安装
- 9网络工程师——2024自学_网络工程师学习路线
- 10git设置查看清除账户信息_git清空store中的账号
MobileNet系列论文阅读笔记(MobileNetV1、MobileNetV2和MobileNetV3)_mobilenet网络论文
赞
踩
目录
引言
如下图,前向推理耗时分布,卷积层占用最大,并且batch-size越大,卷积层耗时最大,因此在网络轻量化的领域中一般都是优化卷积层为主。
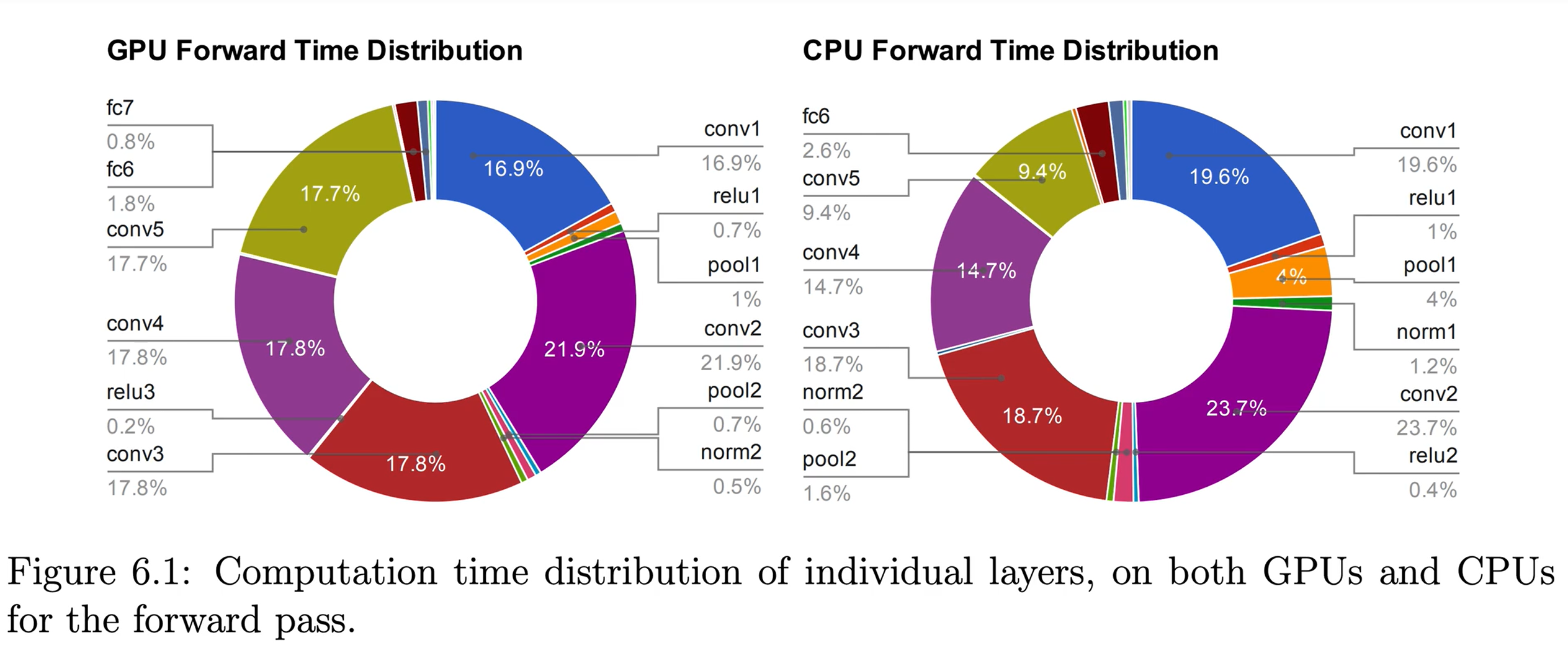
能耗:电费和芯片散热问题,芯片散热就会影响芯片性能。
轻量化网络很大程度上就是减少内存的读写。
减少内存读写方法:
1.减少参数量本身,减少权重本身,减少feature map就是中间层输出结果
2.使内存读写更加规则(结构化剪枝)

学习路线

MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications
论文链接:MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications
摘要
(1)提出了一个可在移动端应用的高效网络MobileNets,其使用深度可分类卷积使网络轻量化同时保证精度。
(2)设计了两个控制网络大小全局超参数,通过这两个超参数来进行速度 (时间延迟)和准确率的权衡,使用者可以根据设备的限制调整网络。
Prior Work – 先前工作
相关轻量化网络
Inception网络:使用深度可分离卷积减少前几层的计算量。
Flattened网络:利用完全的因式分解的卷积网络构建模型,显示出完全分解网络的潜力。
Factorized Networks :引入了类似的分解卷积以及拓扑连接的使用。
Xception网络:演示了如何按比例扩展深度可分离卷积核。
Squeezenet网络:使用一个bottleneck用于构建小型网络。
建立小型高效的神经网络两种方法
(1)压缩预训练模型:
①减小、分解或压缩预训练网络,例如量化压缩(product quantization)、哈希(hashing )、剪枝(pruning)、矢量编码( vector quantization)和霍夫曼编码(Huffman coding)等
②各种分解因子,用来加速预训练网络
(2)蒸馏:
使用大型网络指导小型网络
MobileNet Architecture— MobileNet结构
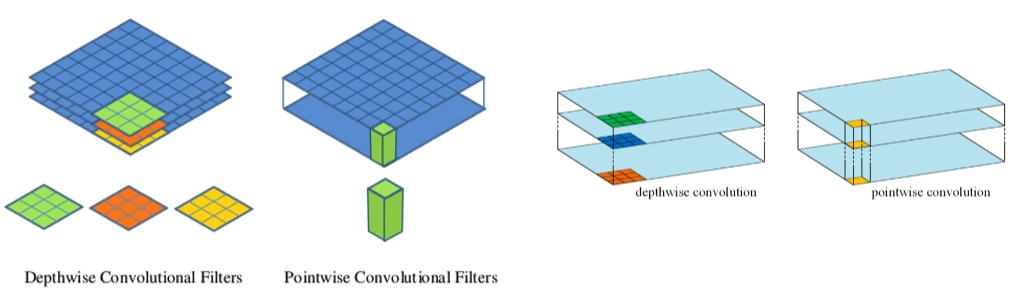
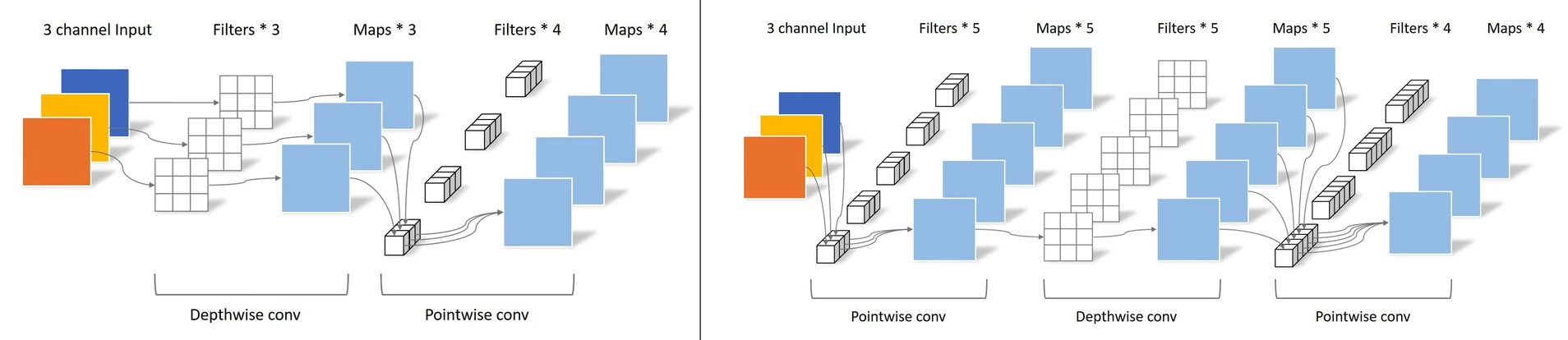
Depthwise Separable Convolution—深度可分离卷积
(1)标准卷积:
- 1.使用卷积核对图中的特征进行提取。
- 2.对提取的特征进行融合。
在标准卷积中这两步一般是同时进行的。
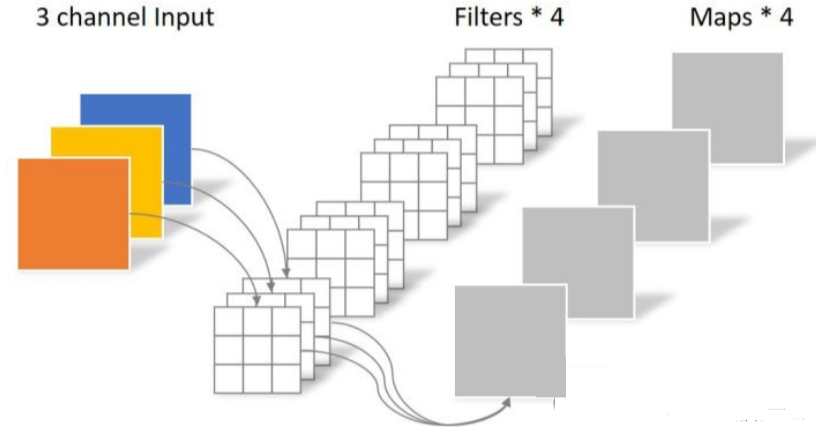
参数量
Wk × Hk × M × N
计算量
Wf × Hf × Wk × Hk × M × N
其中Wk、Hk为卷积核尺寸,Wf、Hf为特征图尺寸,****M*为输入通道数,*N****为输出通道数。
(2)深度卷积:
每个卷积核通道数都为1,然后每个卷积核各自处理一个通道,最后把结果进行concat得到结果。
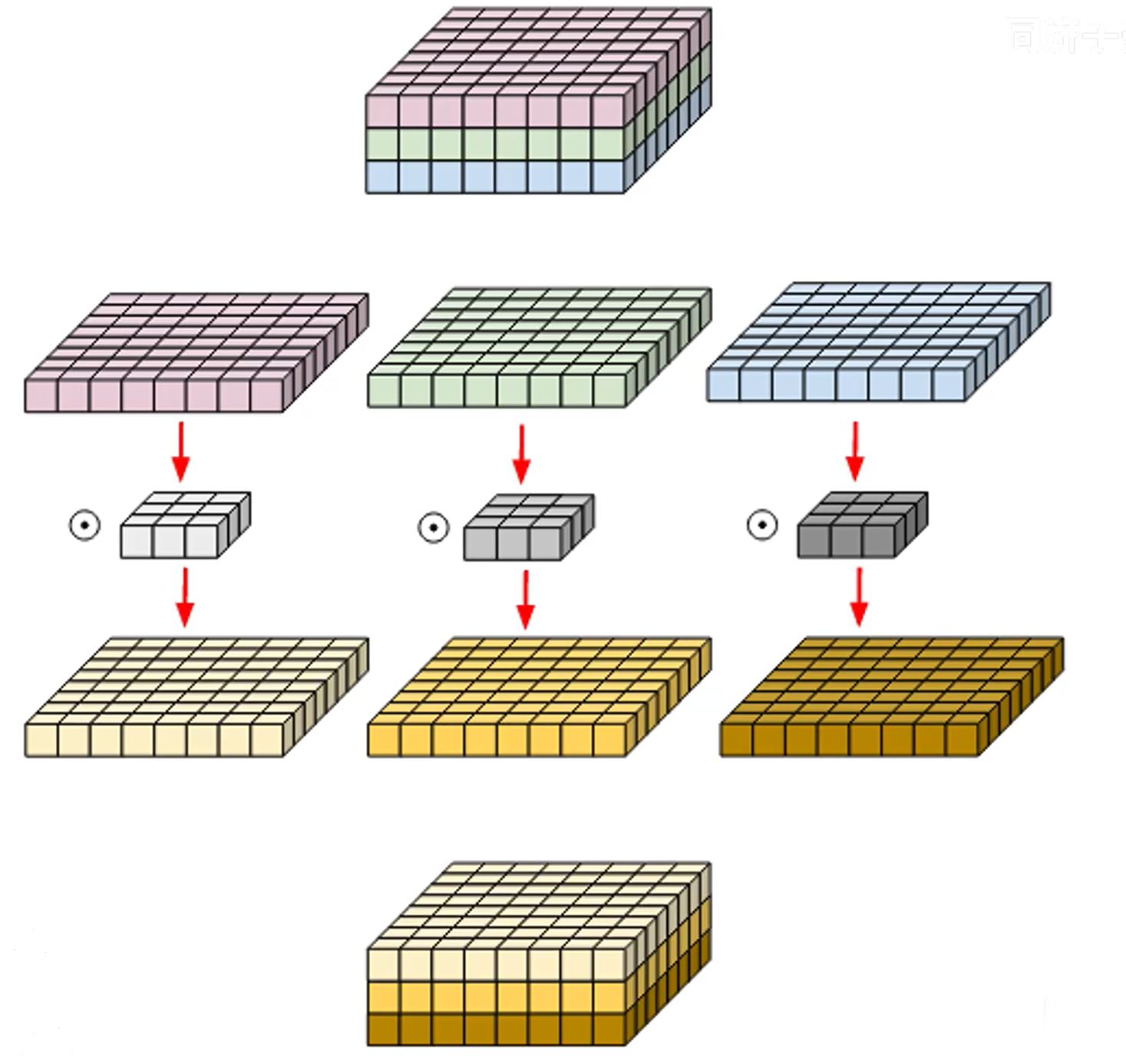
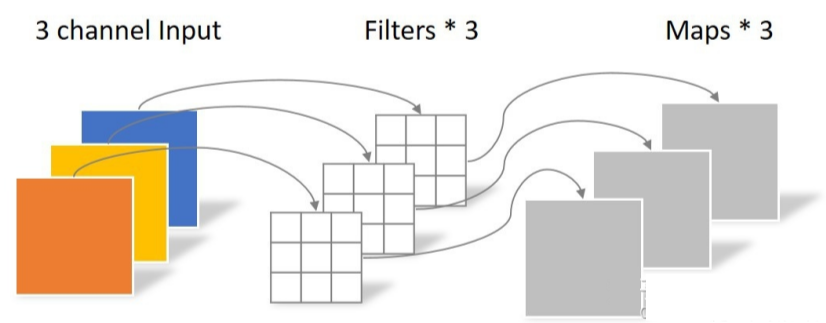
特点
- 卷积核channel=1
- 输入特征矩阵channel=卷积核个数=输出特征矩阵channel
参数量
Wk × Hk ×M
计算量
Wk × Hk × M × Wf × Hf
其中Wk、Hk为卷积核尺寸,Wf、Hf为特征图尺寸,M为输入通道数,输出通道数为1。
(3) pointwise convolution:逐点卷积
逐点卷积负责转换通道,是1x1卷积进行跨通道信息融合,可以大大减少参数量。
其实就是1x1的普通卷积。
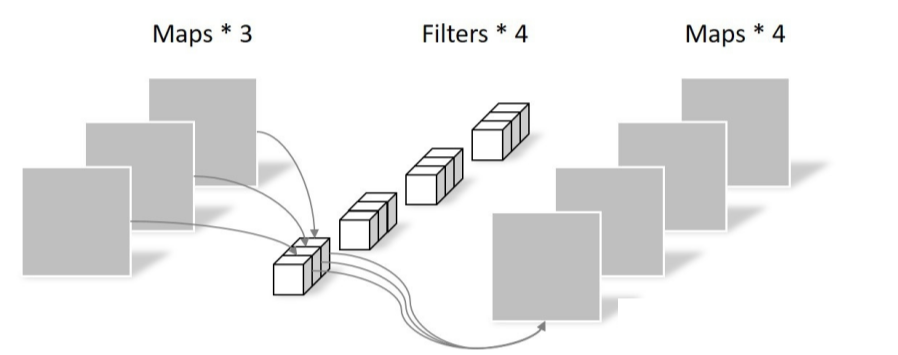
参数量
1 x 1 x M x N
计算量
1 x 1 x M x N x Wk x Hk
其中卷积核尺寸是1×1,Wk、Hk为特征图尺寸,M为输入通道数,N为输出通道数。
计算一次深度可分离卷积的总体计算量为:

它们减少计算量的比例(参数量比例同计算量)为:
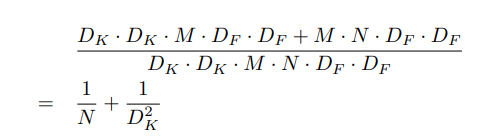
- 深度卷积其实就是g=M=N的分组卷积,但没有将g组concate起来,所以参数量为标准卷积的1/N
- 逐点卷积其实就是g组卷积用con1×1拼接起来,所以参数量是标准卷积的1/Dk^2
深度可分离卷积完整结构,mobilenet就是由多个这种结构堆叠而成的。

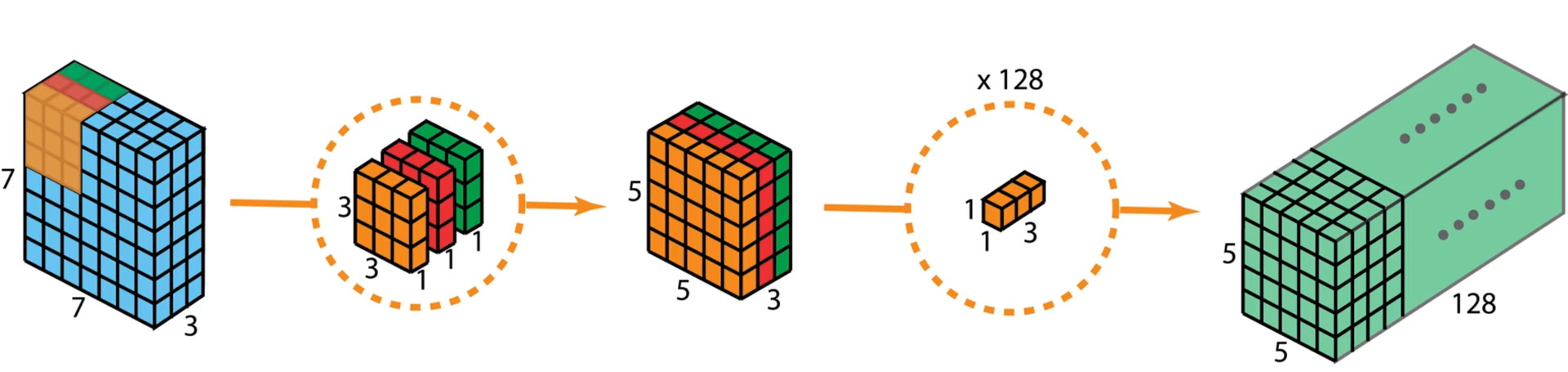
通过下图可以直观的对比深度卷积和逐点卷积
Network Structure – 网络结构
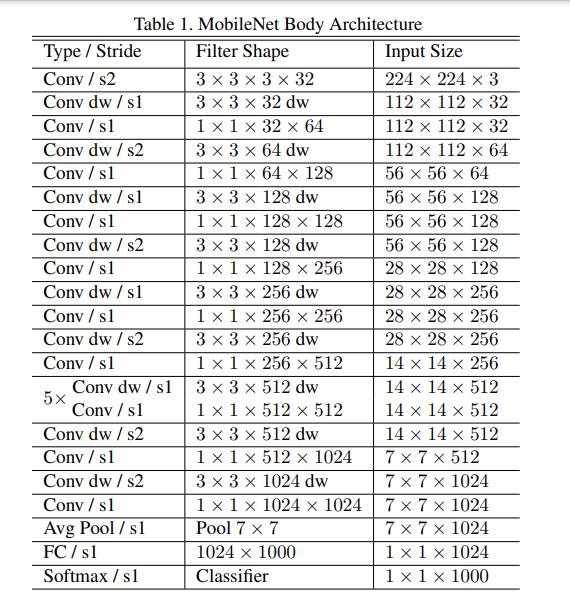
整个结构就是由标准卷积和深度可分离卷积堆叠而成。

整体网络结构
整个MobileNetV1网络除了平均池化层和softmax输出层外,共28层。
第1层为标准卷积,接下来26层为核心层结构(深度可分离卷积层),最后是平均池化层,全连接层加softmax层输出。
除全连接层不使用激活函数,而使用softmax进行分类之外,其他所有层都使用BN和ReLU。
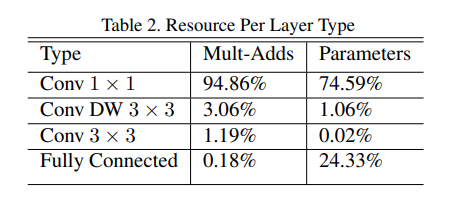
计算性能分析
从计算量占比可以看出1×1卷积占比十分重,那么计算核心就是加速1×1卷积。
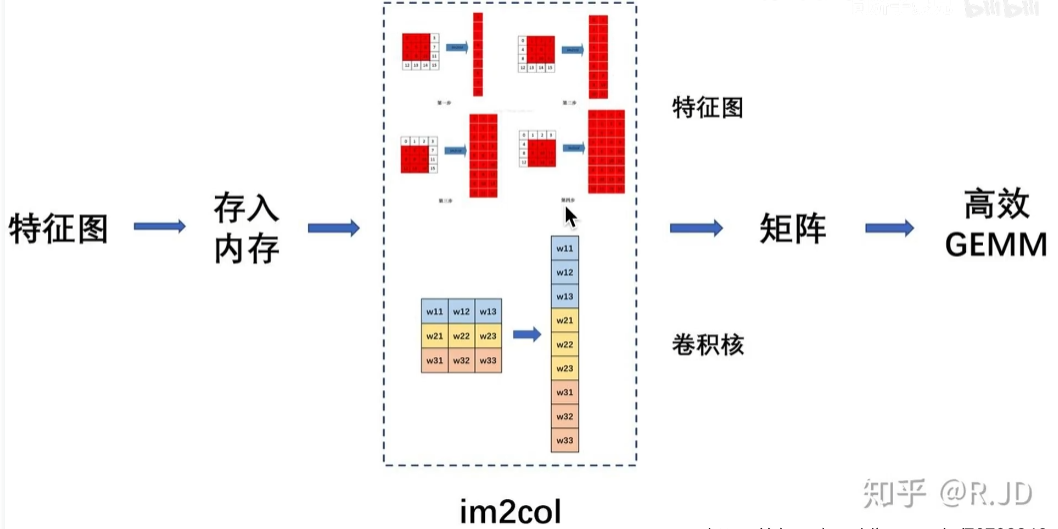
一般情况下,卷积运算可以通过im2col把卷积运算转为矩阵运算,矩阵乘法的运算是研究的十分透彻的,加速效果十分显著。从下图可以看出要先把卷积核转为矩阵才能进行计算,而1 × 1的卷积本身就是一个矩阵,因此效率比一般的卷积核更加快。
- 1x1卷积核是一个比较密集的矩阵,所以在卷积计算时速度较快
- 1x1卷积可以直接通过GEMM (general matrix multiply)进行加速,其他类型的卷积在使用GEMM之前需要先经过Im2col
注意事项: 由于小网络不易过拟合,MobileNet较少使用正则化和数据增强技术(如没有使用side heads或者label smoothing)。
总结
(1)提出了一种基于深度可分离卷积构建了轻量级网络— MobileNet,并设置宽度乘子和分辨率乘子以调整网络大小达到在不同设备上适配的 目的。
(2)通过实验其在大幅度降低MAdds和参数量时,没有出现精度显著下降。
(3)在实验部分展示了MobileNet在分类、检测、人脸识别等各种图像任务上的效果,并且将MobileNets与其他先进的模型进行对比,凸显了 MobileNets良好的尺寸和性能。
使用深度可分离卷积,在保证各类视觉任务准确度不变的条件下,将计算量、参数量压缩30倍。引入网络宽度和输入图像分辨率超参数,进一步控制网络尺寸。
MobileNetV2: Inverted Residuals and Linear Bottlenecks
论文链接:MobileNetV2: Inverted Residuals and Linear Bottlenecks
摘要
(1)本文介绍了一种新框架:SSDLite,描述了如何通过SSDLite将这些移动模型应用于对象检测
(2)本文还演示了如何通过简化形式的DeepLabv3(称之为mobile DeepLabv3)构建移动端的语义分割模型
主要贡献:
Inverted Residuals :倒残差结构
Linear Bottlenecks:结构的最后一层采用线性层
该模块将低维压缩表示作为输入,首先将其扩展到高维,并使用轻型深度卷积进行过滤。特征随后通过线性卷积投影回低维表示。
该模块的优点
(1)该模块可以在任何现代框架中高性能实现。
(2)适合于移动设计。减少了许多嵌入式硬件设计中对主内存访问的需求,提供了少量非常快速的软件控制高速缓存。
MobileNet V1的不足:
1.没有使用残差结构
2.深度可分离卷积中有大量卷积核为0,即有很多卷积核没有参与实际计算。
原因:
卷积核权重数量和通道数量太少
v2的作者发现是ReLU激活函数的问题,认为 ReLU这个激活函数,在低维空间运算中会损失很多信息,而在高维空间中会保留较多有用信息 。
Linear Bottlenecks—线性瓶颈层
ReLU与维度的关系

从图中直观来看,ReLU会对维度较低的张量造成较大的信息损耗。
维度越低,损失信息越多。(如2和3已经没有螺旋的样子了)
维度越高,损失信息越少。(当原始输入维度数增加到15以后再加ReLU,基本不会丢失太多的信息,接近输入)
原文中提到:
需要的感兴趣流行(manifold of interest)应该位于较高维激活空间的低维子空间中:
1.如果感兴趣的流形在ReLU转换后保持非零体积,则其对应于线性转换。
2.只有当输入流形位于输入空间的低维子空间时,ReLU才能保留有关输入流形的完整信息。
这两个深刻见解为我们提供了优化现有神经架构的经验提示:假设感兴趣流形是低维的,我们可以通过将线性瓶颈层插入到卷积模块中来捕获这一点。实验证据表明,使用线性层是至关重要的,因为它可以防止非线性破坏太多的信息。
两个性质
(1)如果"manifold of interest"都为非零值,则经过ReLU相当于只做了一个线性变换,没有信息丢失。
(2)维度足够多时,ReLU能够保留"manifold of interest"的完整信息(把升维和降维一个看作正向一个看作逆向的操作,我们的目的是把线性变换后经过激活的结果进行还原,然而肯定有梯度消失导致信息丢失,那么我们进行升维后,可以得到更多的有效结果,假设输入的10个值为我们想要还原的答案,我们仅仅还原出10个值是很难正确的,那么我们就还原100个值,这100个值里面就很有可能包含的输入的10个值,也就是得到了输入的信息)
解决方法
论文针对这个问题在Bottleneck末尾使用Linear Bottleneck(即不使用ReLU激活,做了线性变换)来代替原本的非线性激活变换。具体到v2网络中就是将最后的Point-Wise卷积的ReLU6都换成线性函数。
实验证据表明,使用线性层至关重要,因为它可以防止非线性破坏太多的信息。
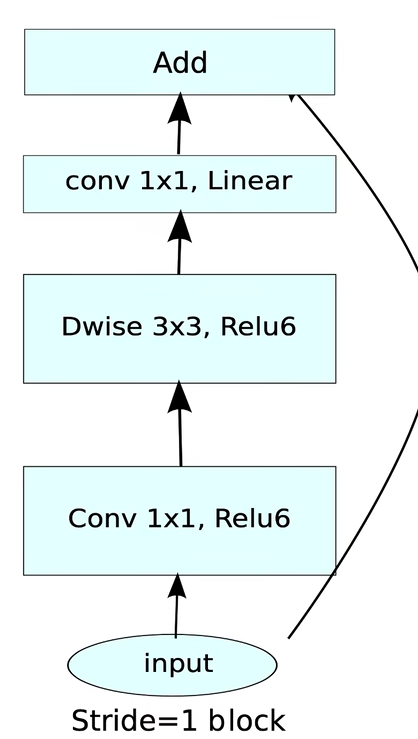
Inverted residuals—反向残差
在resnet中是先降维再升维(减少参数计算量),而在本文中是先升维再降维(提高网络的特征提取能力)。
MobileNetV2中首先在DW深度卷积之前使用PW卷积进行升维(升维倍数为t,t=6),再在一个更高维的空间中进行卷积操作来提取特征,最后再压缩数据,让网络变小。

举个例子:我们的压缩文件,首先要解压(内存变大,相当于升维),再解压后再对文件进行处理(特征提取),最后再进行压缩(减小网络参数)。
MobileNetV1和MobileNetV2对比如下图:
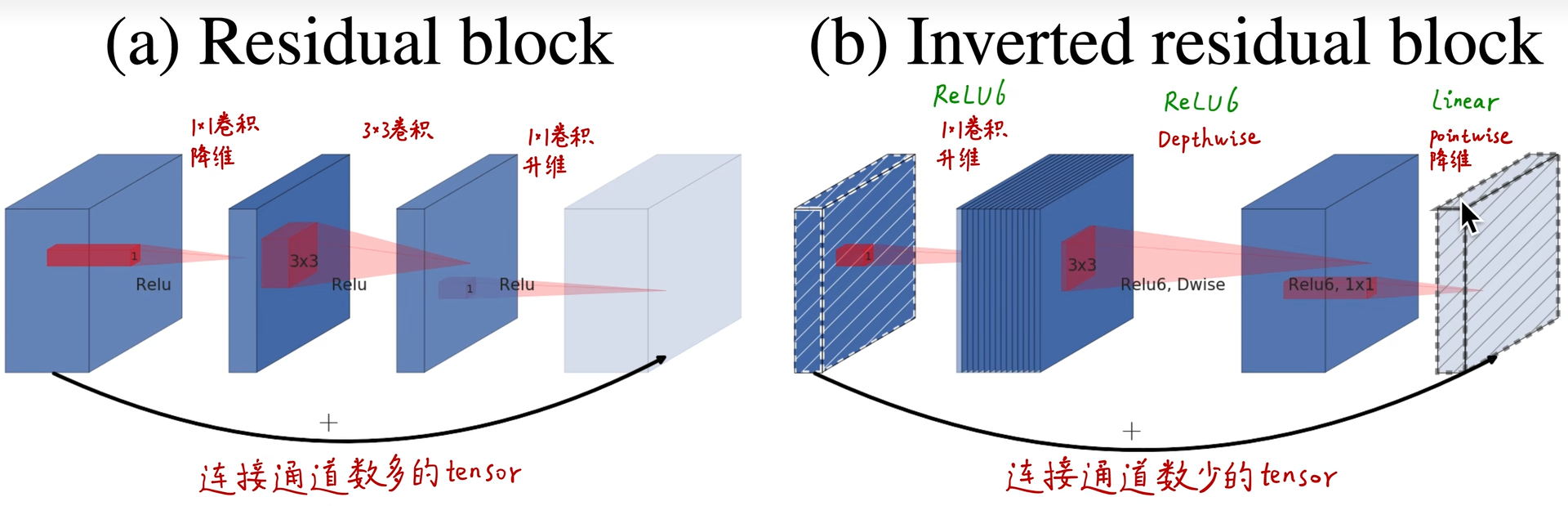
ResNet和MobileNetV2对比:
(a)为residual block模块,短路连接线之间通道数是少的,呈“两边多,中间小”。
(b)则是为了尽量使ReLU6能够更好与深度可分离卷积兼容,所以在短路连接线之间的通道数是最多的,而两边的通道则比中间小。呈“两边少,中间多”。所以作者称其为Inverted residual block。
Model Architecture—模型架构
网络架构
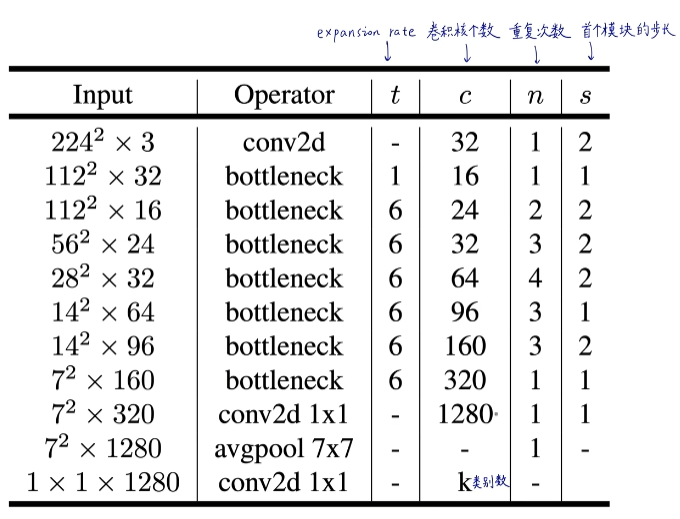
t: 扩展因子(即升维倍数),一般与输入的通道数相乘;
c: 输出通道数;
n: 该层重复次数(比如重复4次,那么这4个相同操作的输出通道都是64);
s: 步幅,注意,shortcut只在s=1时才使用;
卷积核大小均为3 * 3;
本文使用ReLU6作为非线性激活函数,训练过程使用dropout和batch normalization。
除了第一层,在整个网络中使用恒定的扩展因子t;
较小的网络用较小的扩展因子t表现更好,较大的网络使用较大的扩展因子时表现更好。
总结
构建先升维后降维,在降维时使用线性激活函数(防止非线性破坏太多的信息),带残差的Inverted bottleck模块,防止ReLU信息丢失。 在图像分类、目标检测、语义分割等任务上实现了网络轻量化、速度和准确度的权衡。
MnasNet
本章仅作简要介绍,目的是为MobileNetV3的学习打下基础。
本文创新:
1.多目标优化函数:兼顾的速度(直接用手机推理时间进行衡量)与精度
2.分层的NAS搜索空间:一共有7个block,每个block自身内部的结构是一样的,不同block之间是不同的,便于设计网络深层和浅层的模型结构。
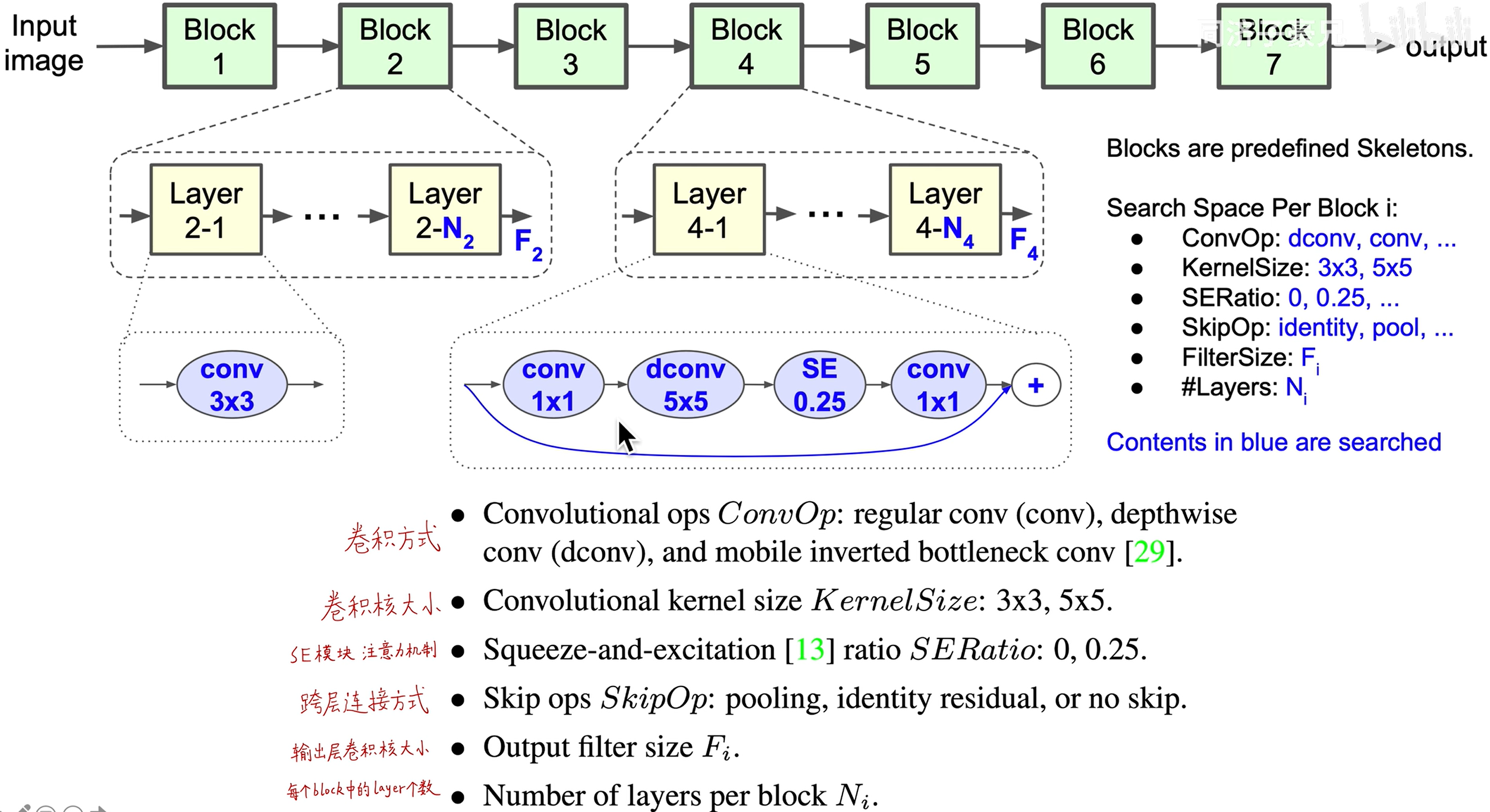
通过强化学习的方法在一个庞大的搜索空间进行搜索,搜索参数:卷积尺寸,处理方式,层数,即插即用的注意力机制等
以往的NAS搜索出一个结构然后不断堆叠,本文中通过分层分解的方式,使得搜索出来的网络具备多样性。
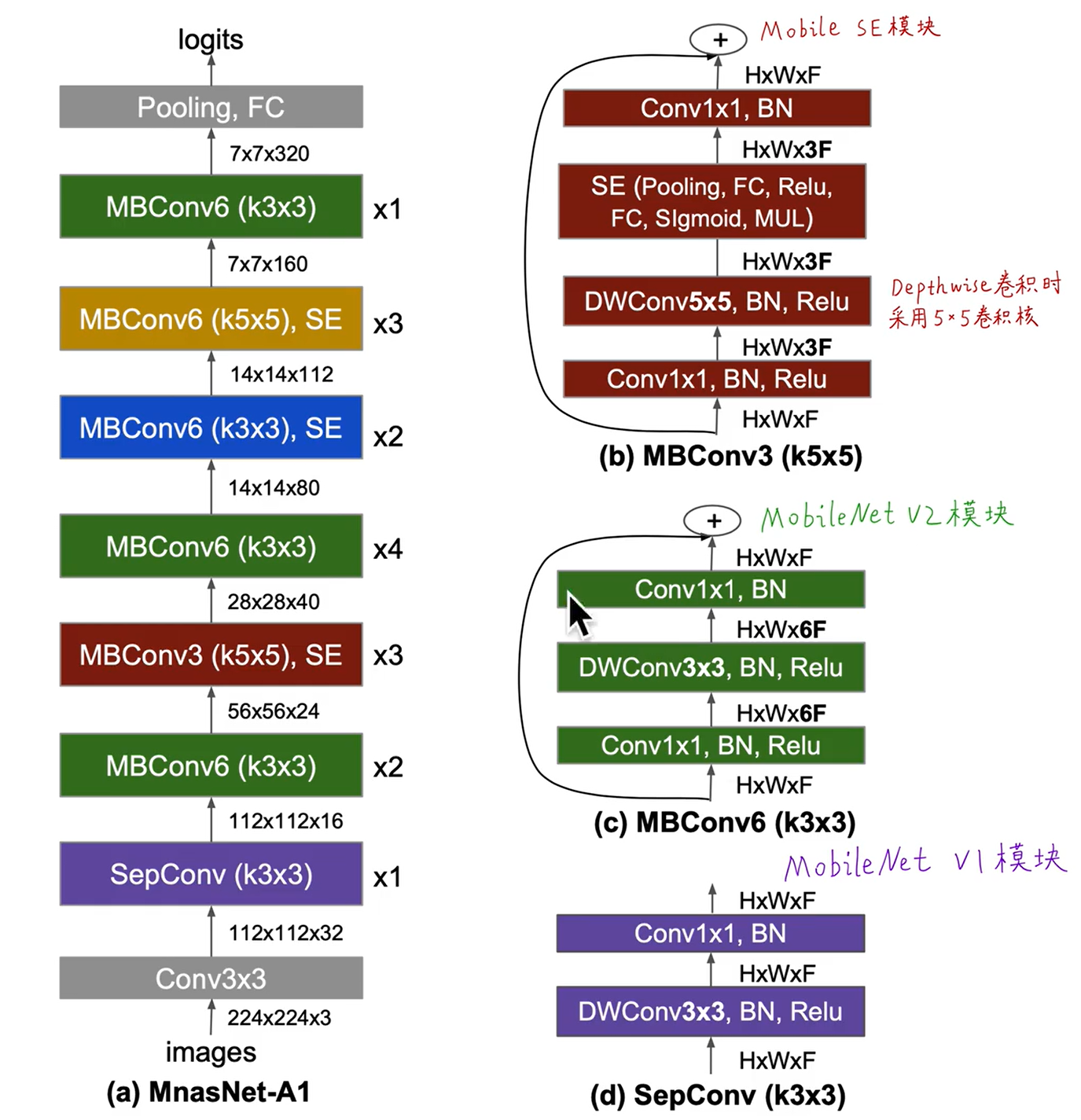
Searching for MobileNetV3
论文链接:Searching for MobileNetV3
摘要
(1)MobileNet V3通过结合NetAdapt算法辅助的硬件NAS和新颖的架构来优化到移动端的CPU上
(2)本文创建了两个新的MobileNet模型,应用于对象检测和语义分割的任务
MobileNetV3-Large
MobileNetV3-Small
(3)分割任务中提出了一种高效的轻量级空间金字塔池化策略Lite Reduced ASPP
相关工作
轻量化网络之前的相关工作
MobileNetV1: 深度可分离卷积+1×1卷积
MobileNetV2: 线性瓶颈+反向残差
MnasNet: 建立在 MobileNetV2 结构上,将基于SE的注意力模块引入到bottleneck结构中
MnasNet创新:
使用多目标优化的目标函数,兼顾速度和精度,其中速度用真实手机推断时间衡量。
提出分层的神经网络架构搜索空间,将卷积神经网络分解为若干block,分别搜索各自的基本模块,保证层结构多样性。
本文的方法
(1)上述三种结构相结合构建块来实现更高效的模型
(2)引入了改进的swish作为非线性函数
(3)将Sigmoid替换为hard Sigmoid
MobileNetV3对比MobileNetV2,从下图可以看出就是加入了SE模块(黄色框部分),其实在MnasNet就已经加入是SE模块,所以MobileNetV3网络就是一个大融合。

下图是黄色框内的示意图,和常规的SE模块几乎一致,需要注意的就是FC2的激活函数将Sigmoid替换为hard Sigmoid。

网络搜索
两个模型
重用了相同的MnasNet-A1模型作为初始的移动端Large模型,之后采用了NetAdapt和基于此的其它优化。
不足
上述方法对小型移动端模型不是最优的,小模型的精度会随着时延变化得更剧烈。
本文改进的方法
使用w = − 0.15代替原文的w = − 0.07
从头开始一个新的架构搜索,以找到初始的 seed 模型,然后应用 NetAdapt 和其他优化来获得最终的 MobileNetV3-Small模型。
NetAdapt
NetAdapt: 一种新的网络压缩算法。
NetAdapt的网络优化以自动的方式进行,它使用一个预训练好的模型在固定计算资源的手机平台上进行压缩试验,逐渐降低预训练网络的资源消耗,直接采集压缩之后的性能表现(作为feedback,得到一系列满足资源限制、同时最大化精度的简化网络。)
本文NetAdapt处理流程
(1)从平台感知 NAS 发现的种子网络体系结构开始
(2)对于每一个步骤:
1.提出一套新的提议proposal, 每个提议都表示对体系结构的修改,与前一步相比,该体系结构至少可以减少延迟
2.对于每一个提议,使用前一个步骤的预先训练的模型,并填充新提出的架构,适当地截断和随机初始化缺失的权重。对于 T 步的每个建议进行微调,以获得 对精度的粗略估计
3.根据某种标准选择最佳提议proposal
(3)重复前面的步骤,直到达到目标延迟。
原文提到的两个建议
(1)减小扩展层的尺寸;
(2)保持残差连接,减小瓶颈的尺寸。
网络改进
重新设计耗时层结构
origin last stage 是耗时比较长的,一个重要原因是在最后一层使用了1×1卷积进行特征空间维度扩展(如下图红框内)。
将该层移动到平均池化层之外。最终,维度扩展是在1×1而非7×7的分辨率上进行。
本文改进的方法
(1)精简last stage,将该层移动到平均池化层之外。最终,维度扩展是在1×1而非7×7的分辨率上进行。
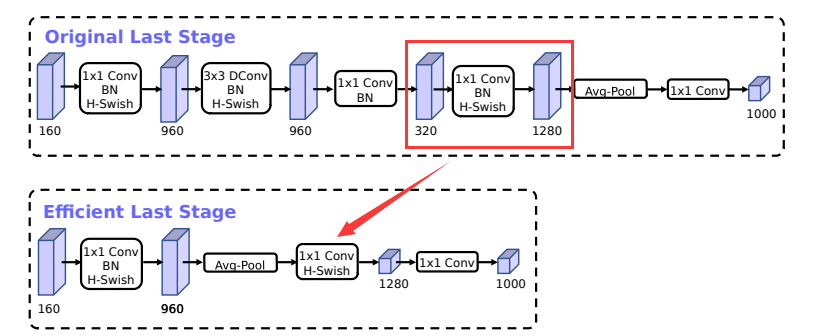
(2)将第一个卷积层的卷积核的个数从32个减少到 16 个(精度几乎不变,没有影响)
(3)使用hard swish非线性激活函数
重新设计激活函数
hard sigmoid

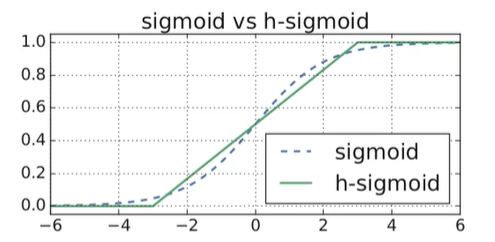
hard swish
swish是Google提出的一种非线性激活函数,在一些深层网络中优于ReLU,如在40层以上的全连接层的效果要明显优于其他激活函数。
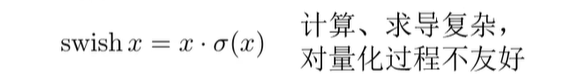
Swish 具备无上界有下界、平滑、非单调的特性,但由于sigmoid在硬件设备上无法实现,为此将sigmoid替换为相近的基于ReLU6的计算,即h-swish。
h-swish计算速度比swish更快(但比ReLU慢),更易于量化,精度上没有差异。
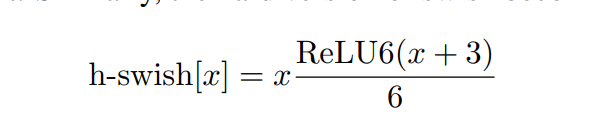
而且实验发现h-swish激活在深层次网络中更有效,为此前层网络依旧使用的ReLU。
网络结构
关键说明:
-
operator:表示的是操作,对于第一个卷积层conv2d
NBN: 最后两个卷积的operator提示NBN,表示这两个卷积不使用BN结构,最后两个卷积相当于全连接的作用
最后的conv2d 1x1: 相当于全连接层的作用。
-
exp size 代表的是第一个升维的卷积,我们要将维度升到多少,exp size多少,我们就用第一层1x1卷积升到多少维
-
bneck: 对应的是下图中左侧的结构
第一个bneck(下图蓝框内)虽然exp size是16,但是实际代码中并未进行升维,也就是这个bneck没有第一层conv。

总结
本文的MobileNetV3,它首先引入MobileNetV1的深度可分离卷积,然后引入MobileNetV2的具有线性瓶颈的倒残差结构,后来使用了网络搜索算法,并引入了SE模块以及H-Swish激活函数等,可谓集大成者。
MobileNet V3 = MobileNet v2 + SE结构 + hard-swish activation + 网络结构头尾微调。
MobileNetV1、MobileNetV2和MobileNetV3对比
| MobileNetV1 | MobileNetV2 | MobileNetV3 |
|---|---|---|
| 1.标准卷积改为深度可分离卷积,降低计算量; 2. ReLU改为ReLU6; 3.引入Width Multiplier(α)和Resolution Multiplier(ρ),调节模型的宽度(卷积核个数)和图像分辨率; | 1.采用线性瓶颈层:将深度可分离卷积中的1×1卷积后的ReLU替换成线性激活函数; 2.采用反向残差结构: 引入了Expansion layer,在进行深度分离卷积之前首先使用1×1卷积进行升维; 引入Shortcut结构,在升维的1×1卷积之前与深度可分离卷积中的1×1卷积之后进行shortcut连接; | 1.采用增加了SE机制的Bottleneck模块结构; 2.使用了一种新的激活函数h-swish(x)替代MobileNetV2中的ReLU6激活函数; 3.网络结构搜索中,结合两种技术:资源受限的NAS(platform-aware NAS)与NetAdapt; 4.修改了MobileNetV2网络端部最后阶段; |
上表引自路人贾’ω’。

