
热门标签
热门文章
- 1数学建模 因子分析_因子载荷矩阵
- 2http报文在网络中是明文传输的,所以不安全。HTtp必然来临
- 3命令行操作Hive_进入hive命令模式的命令是
- 4vue怎么给一个元素绑定多个点击事件_vue中button能@多个吗
- 5解决错误:pip is configured with locations that require TLS/SSL,the ssl module in Python is not available_pip is configure with location
- 6/opt/hbase/conf 中不能启动hbase_[分享]新一代多系统启动U盘解决方案(Ventoy 绿色版)...
- 7HDMI ——CEC 协议详解以及待机唤醒 实现_hdmi cec
- 8linux网卡驱动和tcp,TCP/IP协议在Linux2.4上的实现 之 网卡驱动篇
- 9「力扣」第 416 题:“分割等和子集”_力扣416c语言
- 10软件测试最新“年薪50万”骗局来了,让我们来康康你们是如何上当受骗的_一台电脑半年收入几十万骗局
当前位置: article > 正文
布隆滤波器(Bloom Filter)_bloom滤波器
作者:代码探险家 | 2024-06-27 16:45:42
赞
踩
bloom滤波器
试想一个场景, 做推荐业务时, 我们需要避免在某个时间区间内给用户推荐重复的item, 于是我们会记录给某用户推荐过的item set. 当我们要给他推荐一个新item时, 得先去历史推荐的item set里面查询, 如果发现推荐过了, 就不再重复推荐.
抽象来讲, 我们就是想查询某个item是否在一个set中. 传统数据结构需要维护一个很占空间的set, 这在很多场景下不够space-efficient. Bloom filter可以节省很多的空间来实现一个近似的查询.
Bloom filter的功能
Bloom filter有两个操作: ADD 和 TEST
- ADD
向set中添加一个item(eg. 某String id). - TEST
查询一个目标item是否在set中.
若返回False, 则此item 一定不在set中. 若返回True, 则此item 可能在set中. 即有一定的false positive几率. 这就是节省空间牺牲准确度的地方.
Bloom filter的实现
- 我们用m-bit的空间来存储这个set.
- 我们需要准备k个不同的hash function. 每个function都要将item映射到m-bit中的一个位置上. 映射得是uniform random distribution(不能有冥冥注定的碰撞). k会远小于m. 如何根据sizeof(data_set)选择合适的k值及m值, 后面讲.
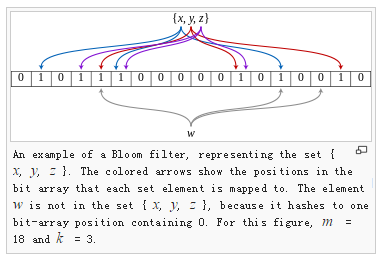
- ADD item的时候, 用k个hash function计算出这个item对应的k个bit位. 将这k个bit位都置为1. 如图, (来源Wikipedia: Bloom filter)
- TEST item的时候, 用k个hash function计算出这个item对应的k个bit位. 若这k个bit位都为1, 那么认为item在set中(有false几率); 若这k个bit中有0, 那么肯定item不在set中, 因为add的时候都会置1.
Bloom filter的分析
- False positive的可容忍性. 例如推荐场景, false positive就意味着, 我们没给用户推送过某doc, 但是误以为给他推送过而不再推送. 用户会因此miss掉这篇doc. 这种低概率false positive用户是感受不到的, 对于业务效果影响也不大, 于是完全是可容忍的. Bloom filter适用于这类场景.
- 无DEL功能. 一个普通的Bloom filter是不具有DEL item的功能的. 如果DEL item动作定义为将k个hash得来的bit位都置0, 那么就会引入false negative, 这会改变Bloom filter的适用场景.
- 相比于其它数据结构, 比如Map(rbtree, hash table etc.), DATrie, 都具有巨大的空间优势(估算, 单机的内存), 同时也有难以超越的速度优势(ADD, TEST都是O(k)复杂度).
Bloom filter的模型搭建
- 假设我们使用m-bit的空间, k个hash function, 预计set中有n个item, 那么false positive概率为
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/代码探险家/article/detail/763074
推荐阅读
相关标签

