
热门标签
热门文章
- 1【Flink-1.17-教程】-【二】Flink 集群搭建、Flink 部署、Flink 运行模式_flink1.17.0集群搭建
- 2Postman安装与入门简单教程_postman下载
- 3字节跳动,三轮面试,四个小时,灵魂拷问,结局我哭了但下次还敢!!!
- 4(2021,中文,双向生成,端到端,双向稀疏注意力)ERNIE-ViLG:双向视觉语言生成的统一生成预训练_ernie-vilg: unified generative pre-training forbid
- 5idea 远程调试sparck scala_scala怎么idea调试
- 6路径规划——图搜索算法(DFS、BFS、迪杰斯特拉、A*)_a*算法拓扑图
- 7Gitblit for Linux安装_gitblit-1.8.0.tar.gz
- 8NLP汉语分词
- 9第二证券股市知识:小白炒股是做长线好还是短线好?
- 10vue2 创建utils文件_vue2 utils
当前位置: article > 正文
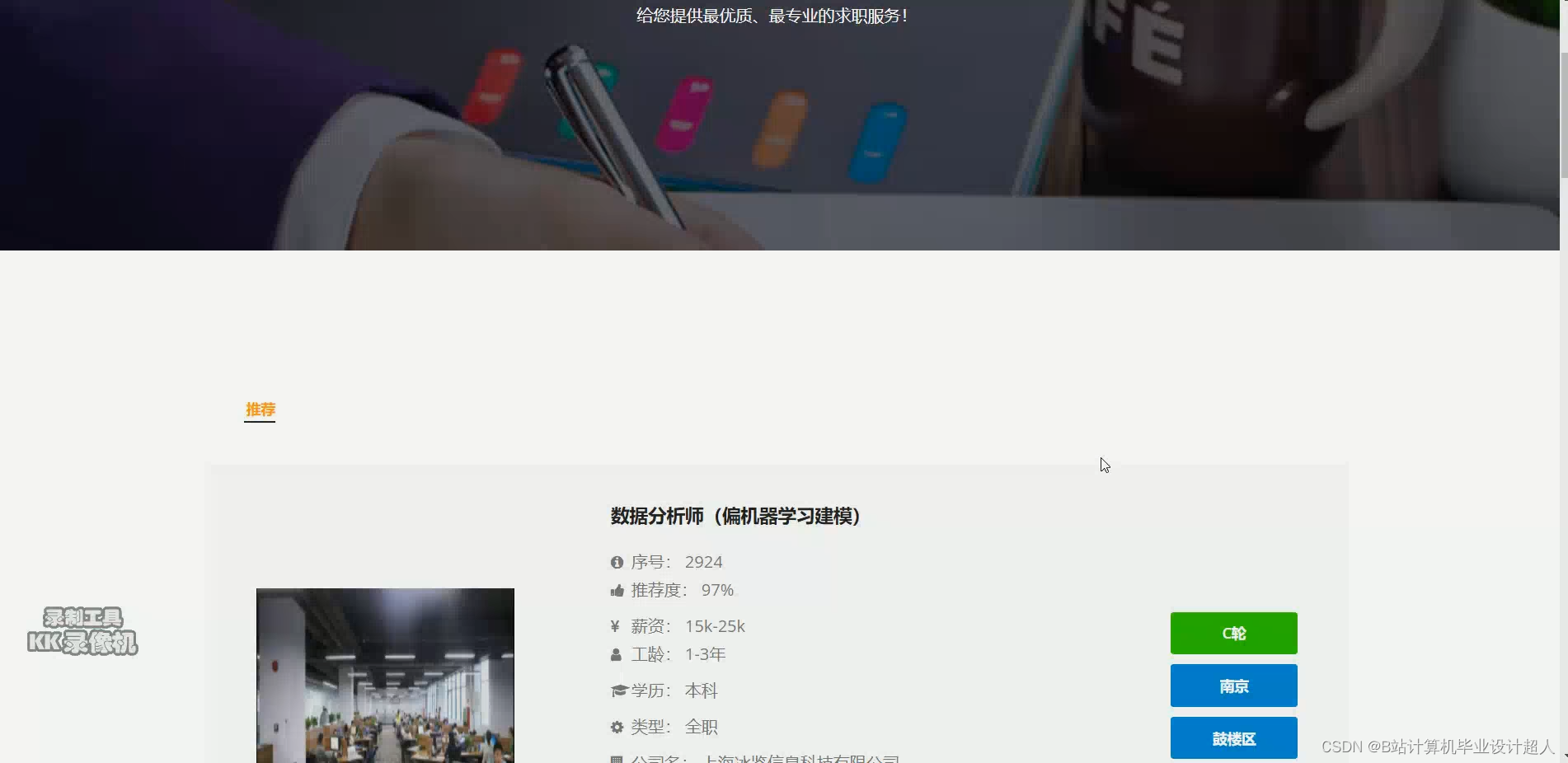
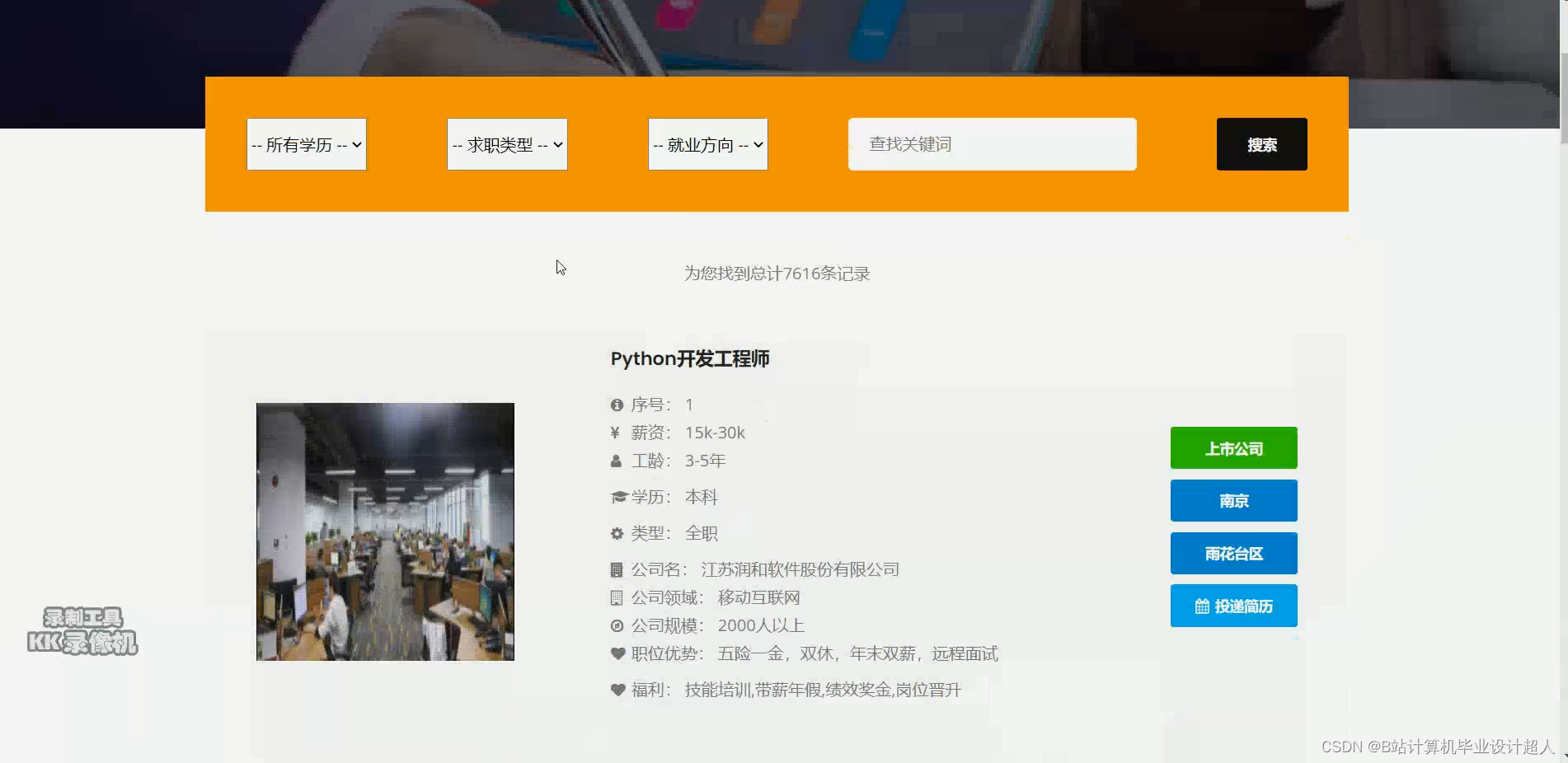
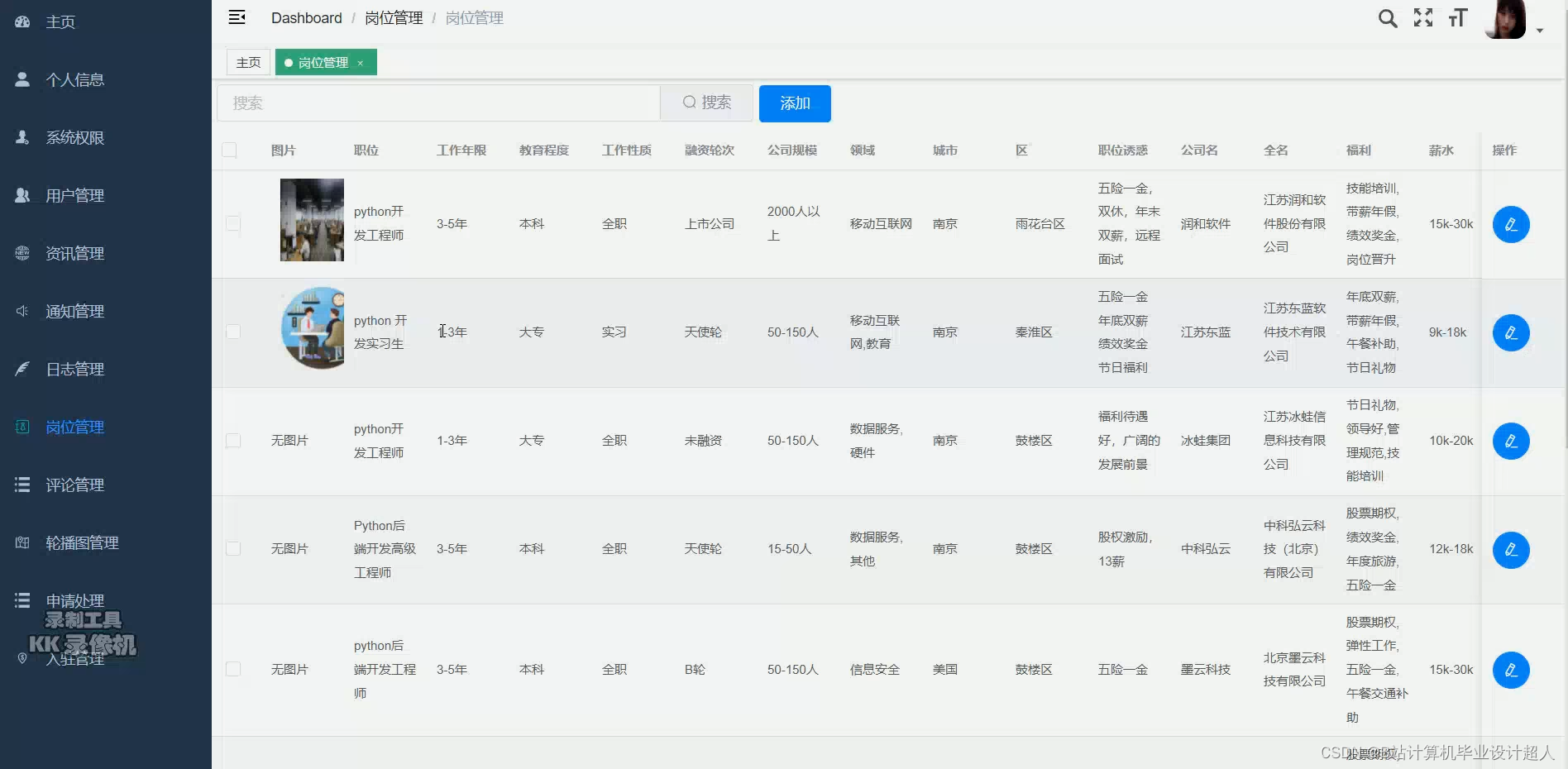
大数据毕业设计hadoop+spark+hive招聘推荐系统 招聘分析可视化大屏 职位推荐系统 就业推荐系统 招聘爬虫 招聘大数据 计算机毕业设计 机器学习 深度学习 人工智能_spark招聘就业类大屏
作者:代码探险家 | 2024-06-29 03:21:56
赞
踩
spark招聘就业类大屏
内容:
爬取拉勾网不同类型的招聘信息数据(java、python、大数据、运维、测试等等)作为数据分析的基础数据集;
搭建Linux数据分析环境,配置hadoop+hive离线数据分析生态圈;
将数据仓库的理论知识应用于实践,进行数据仓库建模;
完成数据清洗、数据分析等数仓流程;
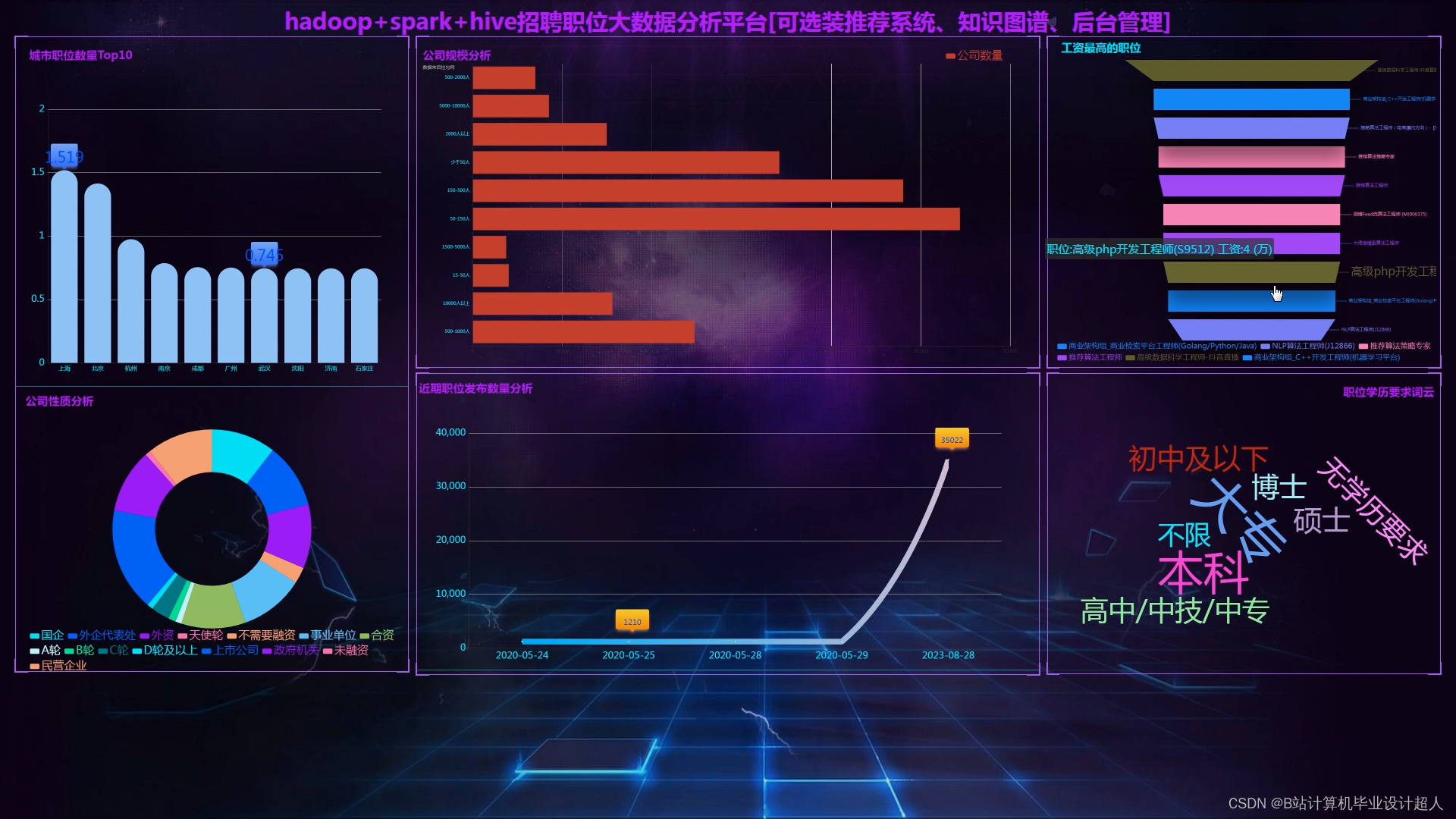
研究FineReport报表技术,进行可视化实现;
拟解决的问题:
拉勾网人机验证反爬问题,数据获取不全面;
数据量较大数仓、MySQL数据库查询缓慢问题;
Hadoop/Hive计算数据倾斜问题、JVM内存计算溢出问题;
可视化指标精度问题;
研究方法
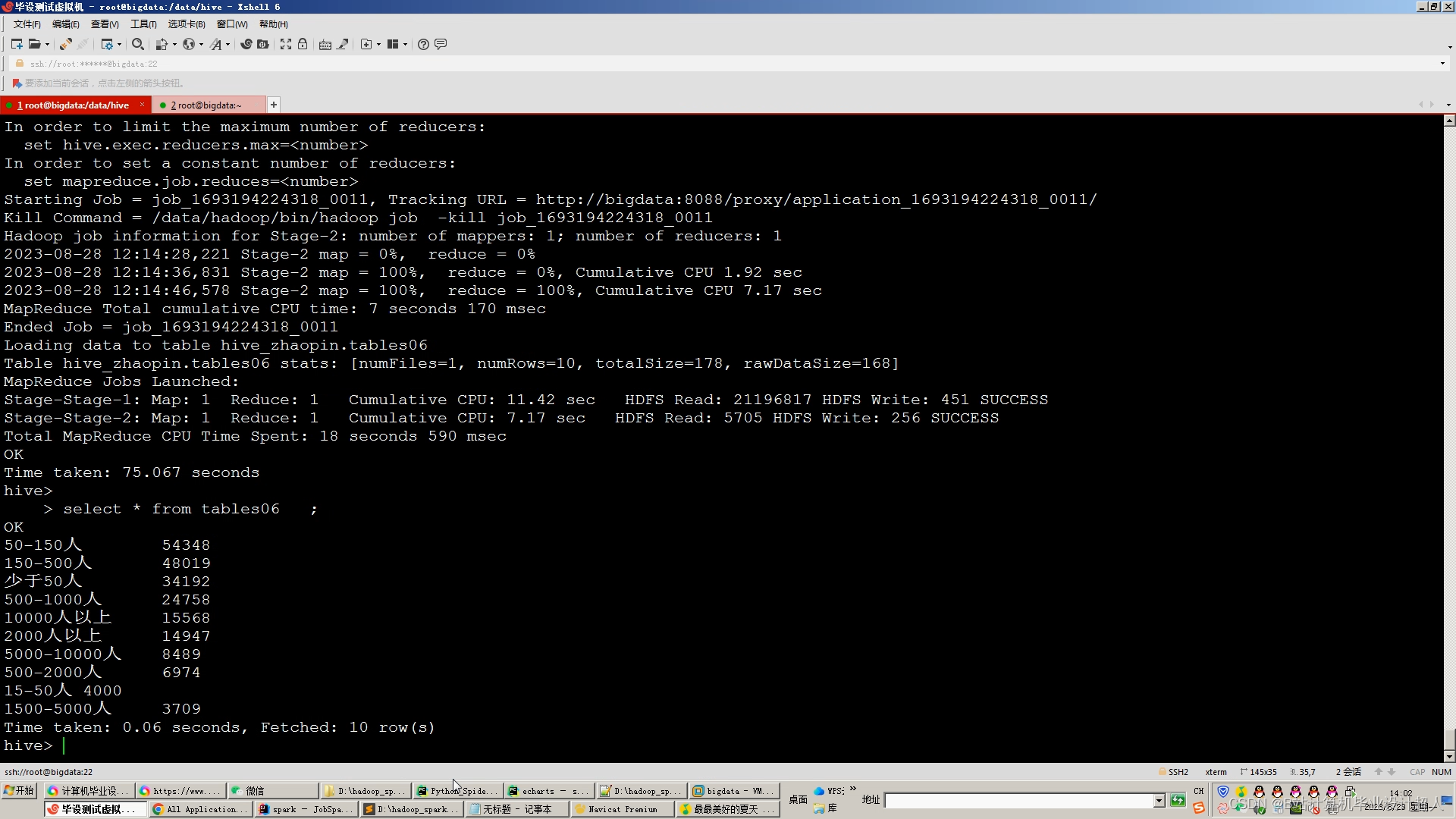
项目整体数通过浏览器开发者模式对拉勾网进行浏览器请求分析,将请求cookie取出,放到requests框架开发的爬虫代码中采集拉勾网数据,将爬取到的数据存入MySQL;
通过sqoop工具将MySQL数据导入到大数据Hadoop平台;
使用Hive并采用数据仓库建设方法对相关指标进行数据分析,将分析出来的结果再次通过sqoop导出到MySQL供给可视化查询使用;
最终通过帆软大屏的方式对结果数据进行展示。
通过调度工具azkaban将整个项目流程串通,一键启动项目即可完成整个数据分析过程。
同时为了方便查hive数据,还采用了目前主流的数据查询工具hue;
————————————————

声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/代码探险家/article/detail/768121
推荐阅读
相关标签

