
- 1在Unity中使用Vuforia识别自定义图片、物体_vuforia物体识别
- 2NLP - pytorch 实现 word2vec(简单版)_torch word2vec
- 3【python】python绘制相关性热力图_python相关性热力图
- 4助力工业产品质检,基于YOLOv5全系列参数模型【n/s/m/l/x】开发构建智能PCB电路板质检分析系统_yolo工业质检
- 5云中 GPU的AI训练,显卡分配_如何为模型训练显卡算力分配
- 6人脸识别——使用谷歌Firebase-ML Kit实现_mlkit 人脸对比
- 7BeeWare,一个如雷贯耳的python库
- 8虚拟机双硬盘安装ubuntu固态+机械_虚拟机如何用机械盘储存固态硬盘运行
- 9JAVA常用框架及漏洞_常见框架漏洞
- 10【LLM】快速了解Dify 0.6.10的核心功能:知识库检索、Agent创建和工作流编排(二)_dify知识检索
JAVA学习-hash算法_java hash
赞
踩
Hash
Hash,一般翻译做“散列”,也有直接音译为“哈希”的,就是把任意长度的输入,通过散列算法,变换成固定长度的输出,该输出就是散列值。根据散列值作为地址存放数据,这种转换是一种压缩映射,简单的说就是一种将任意长度的消息压缩到某一固定长度的消息摘要的函数。查找关键字数据(如K)的时候,若结构中存在和关键字相等的记录,则必定在f(K)的存储位置上。由此,不需比较便可直接取得所查记录。我们称这个对应关系f为散列函数(Hash function),按这个事件建立的表为散列表。
综上所述,根据散列函数f(key)和处理冲突的方法将一组关键字映象到一个有限的连续的地址集(区间)上,并以关键字在地址集中的“象” 作为记录在表中的存储位置,这种表便称为散列表,这一映象过程称为散列造表或散列,所得的存储位置称散列地址。
Hash冲突
对不同的关键字可能得到同一散列地址,即key1≠key2,而f(key1)=f(key2),这种现象称hash冲突。即:key1通过f(key1)得到散列地址去存储key1,同理,key2发现自己对应的散列地址已经被key1占据了。
解决办法(总共有四种):
1.开放寻址法
所谓的开放定址法就是一旦发生了冲突,就去寻找下一个空的散列地址,只要散列表足够大,空的散列地址总能找到,并将记录存入 。
开放寻址法:Hi=(H(key) + di) MOD m,i=1,2,…,k(k<=m-1),其中H(key)为散列函数,m为散列表长,di为增量序列,可有下列三种取法:
1). di=1,2,3,…,m-1,称线性探测再散列;
2). di=1^2,(-1)^2,2^2,(-2)^2,(3)^2,…,±(k)^2,(k<=m/2)称二次探测再散列;
3). di=伪随机数序列,称伪随机探测再散列。
用开放定址法解决冲突的做法是:当冲突发生时,使用某种探测技术(线性探测法、二次探测法(解决线性探测的堆积问题)、随机探测法(和二次探测原理一致,不一样的是:二次探测以定值跳跃,而随机探测的散列地址跳跃长度是不定值))在散列表中形成一个探测序列。沿此序列逐个单元地查找,直到找到给定的关键字,或者碰到一个开放的地址(即该地址单元为空)为止插入即可。
比如说,我们的关键字集合为{12,67,56,16,25,37,22,29,15,47,48,34},表长为12。 我们用散列函数f(key) = key mod l2
当计算前S个数{12,67,56,16,25}时,都是没有冲突的散列地址,直接存入:

计算key = 37时,发现f(37) = 1,此时就与25所在的位置冲突。
于是我们应用上面的公式f(37) = (f(37)+1) mod 12 = 2。于是将37存入下标为2的位置:

2.再哈希
再哈希法又叫双哈希法,有多个不同的Hash函数,当发生冲突时,使用第二个,第三个,….,等哈希函数去计算地址,直到无冲突。虽然不易发生聚集,但是增加了计算时间。
3.链地址法(Java hashmap就是这么做的)
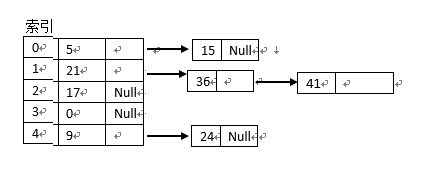
链地址法的基本思想是:每个哈希表节点都有一个next指针,多个哈希表节点可以用next指针构成一个单向链表,将所有关键字为同义词的结点链接在同一个单链表中,如:
设有 m = 5 , H(K) = K mod 5 ,关键字值序例 5 , 21 , 17 , 9 , 15 , 36 , 41 , 24 ,按外链地址法所建立的哈希表如下图所示:
4.建立一个公共溢出区
这种方法的基本思想是:将哈希表分为基本表和溢出表两部分,凡是和基本表发生冲突的元素,一律填入溢出表。

