
热门标签
热门文章
- 1更新微信小程序史上巨巨巨巨细步骤 我奶看了都学会了_小程序更新
- 2一个简单的答题程序_答题小程序游戏流程图
- 32024年网络安全最全火爆国内外的大模型究竟是什么?有哪些大模型学习和参赛的网站?_大模型特点行业数据库
- 4Ubuntu 20.04(双系统)+ 机器人开发环境搭建 速通教程,长期更新_双系统里安装robotware stdio
- 5多语言模型(Multilingual Models)用于推理(Inference)
- 6【AIGC调研系列】Qwen2与llama3对比的优势_qwen2 llama3
- 7玩转Eclipse — 快捷键设置及汇总_eclipse复制快捷键在哪里设置
- 8vue-cli3.0配置不同的网址(根据不同的环境进行网址切换)_vue3怎么切换接口地址用的是env还是env.dev
- 9MacOS安装Homebrew教程_homebrew 安装时候需要 sudo 吗
- 10Springboot-Zookeeper(curator)实现分布式锁、分布式ID等_springboot curator
当前位置: article > 正文
Transformer模型原理细节解析
作者:代码探险家 | 2024-07-05 02:02:40
赞
踩
Transformer模型原理细节解析
基本原理:
Transformer 的核心概念是 自注意力机制(Self-Attention Mechanism),它允许模型在处理每个输入时“关注”输入序列的不同部分。这种机制让模型能够理解每个单词或符号与其他单词或符号之间的关系,而不是逐个地线性处理输入。
Transformer 主要由两个部分组成:
编码器(Encoder):将输入序列转换为一个隐表示(向量表示)。
解码器(Decoder):从隐表示生成输出序列。
编码器 和 解码器 都由多个 层(layers) 组成,每层都包括一个 自注意力机制 和一个 前馈神经网络(Feed-Forward Neural Network, FFN)。
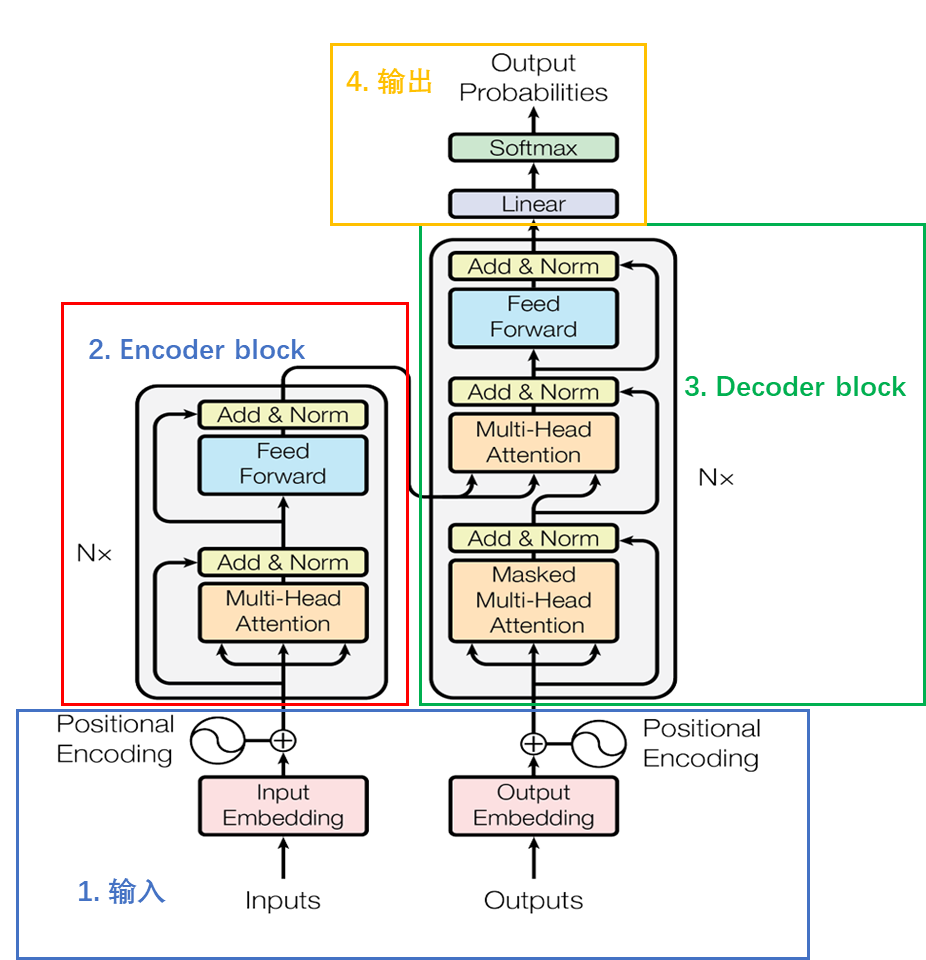
整体组成:
Encoder block由6个encoder堆叠而成,一个Encoder由两个子层组成,即Multi-Head Attention和全连接神经网络Feed Forward Network,每个子层都采用了残差连接的结构,后面接一个layer_norm层。
Decoder block由6个decoder堆叠而成,一个Decoder包含两个 Multi-Head Attention 层。第一个 Multi-Head Attention 层采用了 Masked 操作。第二个 Multi-Head Attention 层的K, V
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/代码探险家/article/detail/788867
推荐阅读
相关标签

