
- 1MacOS + Android Studio 通过 WIFI 无线真机调试_android studio wifi
- 2Python程序后台运行的五种方式_python 后台运行
- 3VSCode msys2/git wrapper.bat Source control无法识别git仓库the folder currently open doesn‘t have a git rep_vscode sourcecontrol
- 4E: Package
has no installation candidate_e: package 'python-matplotlib' has no installation - 5如何查看sqlserver日志的方法
- 6“人机共驾”时代,百度Apollo如何走好汽车智能化之路?_百度智能车解决方案
- 7图文并茂——从Kubernetes的诞生背景到什么是Kubernetes, 带你深度解析Kubernetes
- 8三种命名规则之-----骆驼命名法_camel命名法
- 9基于Xilinx XCVU3P的PCIe Gen3x16+FMC-HPC x1+100G QSFP28国产替代板高性能开发平台(可选复旦微JFM9RFVU3P)
- 10常见八大排序(C语言实现)及动图演示_给序号排序c语言
【白话Flink基础理论】Flink运行时(Runtime)架构(三)并行度&Task&SubTask&Slot&Flink中的并行剖析_flink并行计算
赞
踩
——wirte by 橙心橙意橙续缘,
前言
白话系列
————————————————————————————
也就是我在写作时完全不考虑写作方面的约束,完全把自己学到的东西、以及理由和所思考的东西等等都用大白话诉说出来,这样能够让信息最大化的从自己脑子里输出并且输入到有需要的同学的脑中。PS:较为专业的地方还是会用专业口语诉说,大家放心!
白话Flink系列
————————————————————————————
主要是记录本人(国内某985研究生)在Flink基础理论阶段学习的一些所学,更重要的是一些所思所想,所参考的视频资料或者博客以及文献资料均在文末放出.由于研究生期间的课题组和研究方向与Flink接轨较多,而且Flink的学习对于想进入大厂的同学们来说也是非常的赞,所以该系列文章会随着本人学习的深入来不断修改和完善,希望大家也可以多批评指正或者提出宝贵建议。
说在前面
————————————————————
在Runtime架构的前两节,我们已经简单地对Runtime层的架构、组件以及其中涉及到的任务调度和资源管理部分进行了学习,但是我们在其中涉及到一些过程确一直一知半解,比如
- JobManager要将每个Task调度到TaskManager的Slot上进行执行,那么每个Slot里执行的是什么呢?
- 1个Job的Task是怎么划分的呢?我们又听过SubTask这又是什么呢?
- Flink作为一个分布式系统,它的并行性是如何体现的呢?
我们学完Runtime这一块的前两节,虽然对Rntime层的大致思想有了了解,但是却又不清楚的3个很重要的问题,这3个问题基本就能把Runtime层最底层的任务调度和资源管理给解释地明明白白,理解了本节内容,对Runtime层的理解才算真正是拨开云雾见光明。
概念介绍
以下概念是Flink官方给出并且结合自身理解给出的,比较全面。
算子operator:逻辑图Logical Graph(也即数据流图Dataflow Graph)的节点。运算符执行特定操作,该操作通常由函数执行。Source和Sink是用于数据引入和数据出口的特殊运算符。包括以下两种模式。one-to-one(forwarding): 即两种算子间所产生的的元素的个数和顺序皆相同,不涉及数据重分区,比如map flatMap fliter等算子Redistributing:(1)算子的操作会引起数据的重分区,或者(2)人为在算子执行完后进行重分区。KeyBy:该算子会产生基于hashCode的重分区- 重分区操作。
broadcast:广播rebalance:轮询,也就是上游算子所产生的数据会依次发送给下游算子shuffle:彻底的随机打乱重分区
并行度算子的并行度:每个算子均有属于自己的并行度,每个并行度会产生一个在ExecutGraph中对应的结点。job的并行度:该Job所有算子中的最大并行度,与所用Slot的数量一一对应。
算子链operator chain:由两个或多个连续的算子组成,之间没有任何重新分区。同一算子链中的算子将记录直接转发给对方,而无需通过序列化或 Flink 的网络堆栈。
所以Flink底层来看算子链其实就是1个新的用户自定义算子。这块不细讲了,需要可以看参考资料6
任务Task:数据流图(dataflow graph)的结点。Task是基本工作单元,由 Flink 的运行时Runtime执行。Task只封装一个算子operator或算子链operator chain的并行实例。子任务SubTask:subtask是负责处理数据流分区的任务。术语"子任务"强调同一算子operator或算子链operator chain有多个并行任务。
注意Task和subTask在加粗部分的
区别。也就是说Task是在逻辑层面的表示,而subTask是真正在Slot里执行的涉及数据分区的物理层面的表示;换种说法,也是1个Task至少包含1个并行执行的subtask。
插槽Slot:Flink 中计算资源进行隔离的单元,一个 Slot 中可以运行多个 subTask(插槽共享),但是这些 subTask 必须是来自同一个 application 的不同阶段的 subTask。
问题1:Task和SubTask是如何划分的?

Job对Task的划分,也即算子链的形成,需要Task中的每一个算子符合以下条件。
- 上下游算子的并行度一致
- 下游节点的入度为1
- 上下游节点都在同一个 slot group 中
- 下游节点的 chain 策略为 ALWAYS(可以与上下游链接,map、flatmap、filter等默认是ALWAYS)
- 上游节点的 chain 策略为 ALWAYS 或 HEAD(只能与下游链接,不能与上游链接,Source默认是HEAD)
- 两个节点间数据分区方式是 forward
- 用户没有禁用 chain(代码中是否配置disableChain())
Operator Chains 是一个有用的优化,它减少了线程到线程的切换和缓冲的开销,并在降低延迟的同时提高了总体吞吐量。
针对内存密集型、CPU密集型,使用
startNewChins()、disableChaining()方法,可以将当前算子单独放到一个 Task 中,使其独享当前Task的所有资源,以此来提升计算效率。

上图并行数据流,一共有
3个 Task,5个 subTask。每个subTask对应1个线程。
正如我们在上面算子部分所介绍的,流可以按照一对一模式或重新分配模式在两个 Operator 算子之间传输数据:
- 1
-
一对一的流:(例如上图中的 Source 和 map() 算子之间的流)它们都保留各自元素的分区和排序。即:map() 算子的 subtask[1] 将会与产生相同元素顺序的Source() 算子的 subtask[1] 关联,进行数据传输。
-
重新分配的流:(例如上图的 map()和 keyBy()/window()之间以及 keyBy ()/window()和Sink之间)重新分配流会改变流的分区。每个算子subTask都将数据发送到不同的目标subTask,具体 subTask 取决于所选算子使用的转换方法。例如: keyBy() 通过 Hash 散列重新分区;broadcast()广播;或者 rebalance() (随机重新分区)。
问题2:Task和Slot是怎样被调度到一起的?
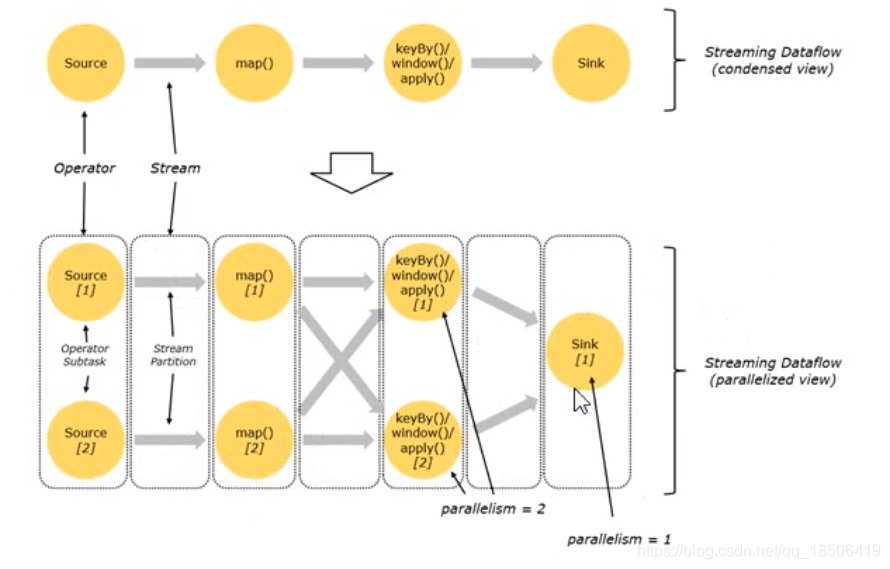

不考虑slot share或者人为强制将这些子任务划分不同共享组的情况
再来回顾一下这张图,根据刚刚讲述的知识,由于Source算子和map算子属于one-to-one模式,所以合并成了1个Task,又由于其并行度皆为2,所以对应这有2个subtask;这样图中其实是有3个task,5个subtask大家都清楚了,所以如果对于每个subtask都分配1个slot进行计算,那么具体的分配就如上图所示。
但是Flink中确不是这样做的,为什么?
很明显,对于不同的subtask,它们对于数据的处理速度,以及所处理数据的密集程度都是不同的,比如上面的source和map算子组成的subtask,很明显map算子要对来自数据源的每一个数据进行操作,操作密集程度很高;而后续的keyby,windows算子都是分组操作,一次处理一组数据,操作密集程度就没有那么高。
所以,如果按照上图这样为slot分配task,由于Flink的流式操作的特性,只会造成不同的slot内处理速度较快的子任务等待较慢的子任务,这样就会有大量时刻Slot中的资源是闲置且被占用的,这样就造成了资源利用的严重不足。
Flink通过提供Slot共享来解决了这一问题
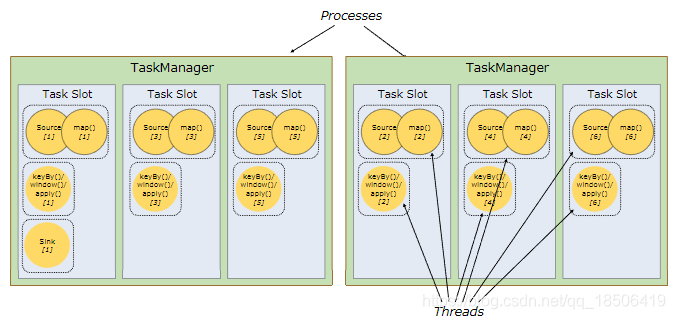
加入了slot share后的情况
什么样的子任务能够共享1个slot呢?
- 同一个application,也即同一个job中,多个 不同task的 subTask,可以运行在同一个 slot 资源槽中。
- 同一个 task 中的多个的 subTask,不能运行在一个 slot 资源槽中,他们可以分散到其他的资源槽中。
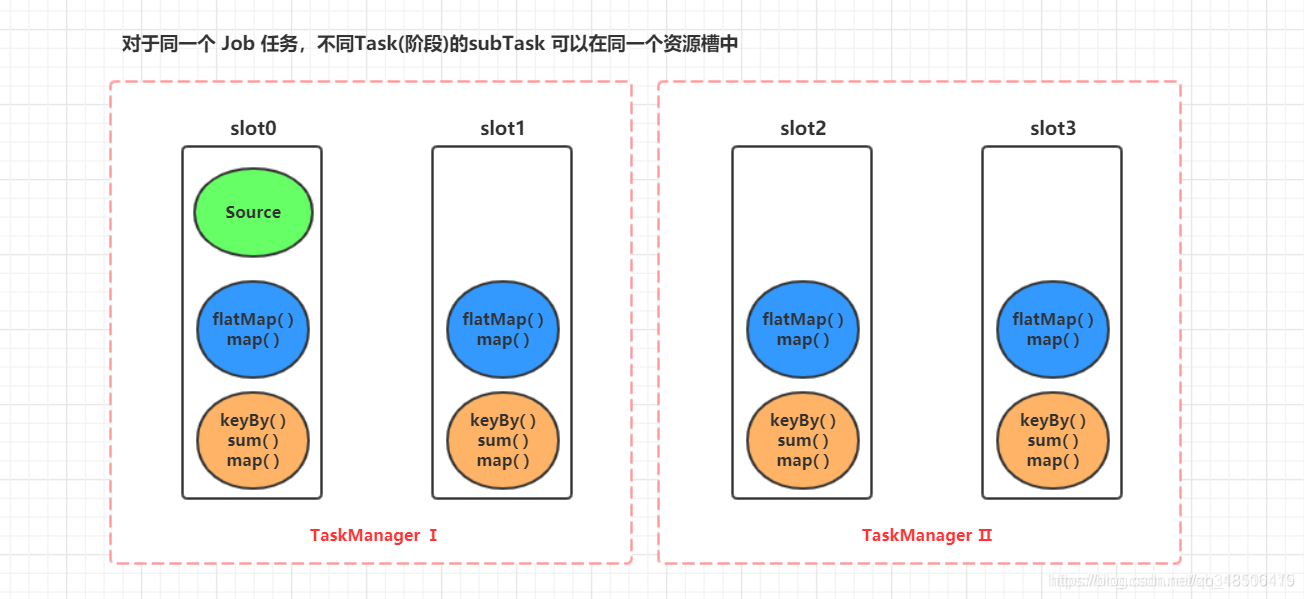
这样的话,在每个Slot内,因为拥有来自不同task的subtask,那么这些subtask之间自上而下刚好组成了类似于在Flink Client根据我们代码生成的数据流图中的东西,1条完整或者部分作业的流式执行管道。
好处
- 可以充分利用Slot中的资源
- 如果不进行重分区的话,还免于了部分数据传输。
- 如果其他的Slot或者TM出现错误挂掉了,那么还能很大程度上保证其他Slot能够继续完成整个的工作,仅仅是并行度降低而已。
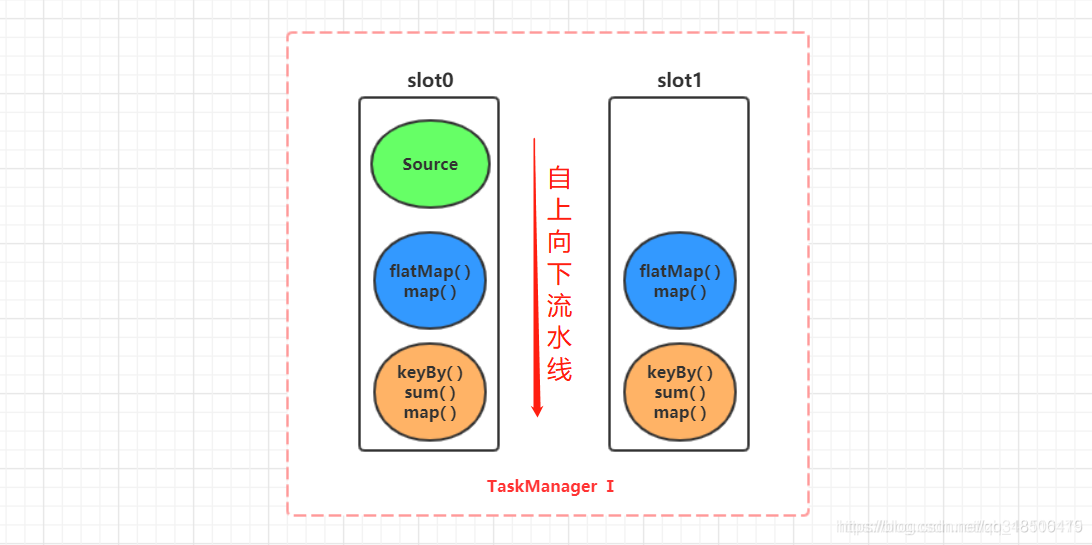
问题3:Flink中的并行性是如何体现的?
其实以前我在学习的过程对Flink是如何实现并行计算存在1个误区,就是我认为Flink的并行是由于存在多个TM,也就是多个slave节点实现的,看起来好像没问题啊,主从结构嘛,1个master多个slave,但仔细想想好像又有问题,那我1个master+1个salve就不行并行计算了?
所以对于Flink并行性的体现我总结了以下几点:
- 最外层来看,多个TaskManager从节点是并行执行。
- 对于每一个TM,其内部又包含多个Slot,每个Slot分别处理多个子任务,所以Slot之间又是并行的。
- 对于每一个Slot,其中包含着来自先后执行的不同task的subtask,而每个subtask又分别由1个线程来执行,所以每个Slot中也是多线程运行的。
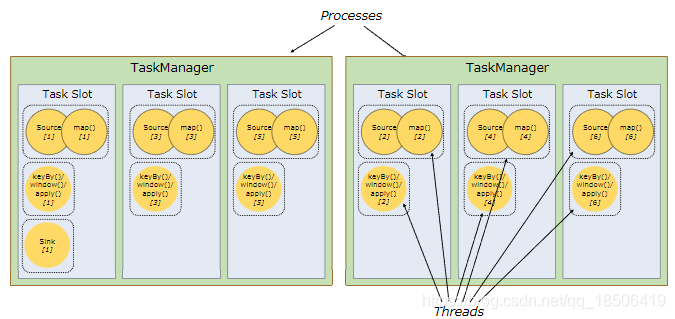
这张图很好的显示了TM与Slot与Subtask之间的关系。(
2个TM,6个Slot,13个subtask,即13个threads)
以上3点,角度不同但都互相包容,从而实现了Flink中的并行执行,也就是说我们可能在学校里学习过的《并行程序设计》中讲的主-从结构是宏观概念上的,当然没有错,但是Flink基于这个结构,底层呢还有属于自己的东西,比如Slot的划分等等来具体进行任务执行的并行。
总结
通过本节的梳理和汇总,相信大家已经对Flink中每个Job的具体task执行过程有了深刻的了解,不在像前2节一样,一看就懂,一深入就懵了。通过梳理Runtime层的这些细节,使得我们将作业执行的整体流程串了起来,脑子中也能够比较条理地梳理出具体的流程了,在进行后面的一些复杂操作时也不至于混乱。
在这篇博客里使用到了许多参考资料中其他作者的很好的图片来辅助理解,十分感谢!。而且本章节只是对理论层面的讲解,有很多实战性的操作以及验证,大家可以具体看B站的教程或者是下面其他作者的博文。
参考资料
《Flink 之 Dataflow、Task、subTask、Operator Chains、Slot 介绍》

