
热门标签
热门文章
- 1外包公司值不值得去?_现在外包值得做吗
- 2【已解决】ModuleNotFoundError: No module named ‘torch._six‘_modulenotfounderror: no module named 'torch
- 3大数据工程师简历_成为大数据工程师所需的技能
- 4半球展开图_棱锥的展开图.ppt
- 5ECMAScript 与 JavaScript的联系 以及为什么会有浏览器兼容的问题?_ecmascript 兼容性
- 6推荐项目:CLIP-ONNX - 加速CLIP推理速度的神器!
- 7MyBatis——MyBatis实现多表查询_mybatis多表查询
- 8老徐WEB:最简单详细的轮播图原理和制作过程(一)_最简单的网页轮播图
- 9LoRA中值得注意的微调细节_lora微调
- 10Python 实战之淘宝手机销售分析(数据清洗、可视化、数据建模、文本分析)_数据可视化手机价位图的代码
当前位置: article > 正文
3D目标检测经典模型比较_3d目标检测算法排行
作者:代码探险家 | 2024-07-12 20:03:41
赞
踩
3d目标检测算法排行
研一不知道干啥,下面罗列了最近看的一些3D目标检测模型,其中都当作笔记记录在了主页博客里,不过记得不规范的就设置为私密了。现在比较一下相当于复习了,下面简单列了他们的主要思路。(有错误理解欢迎指出)
首先是基于LSS范式的:
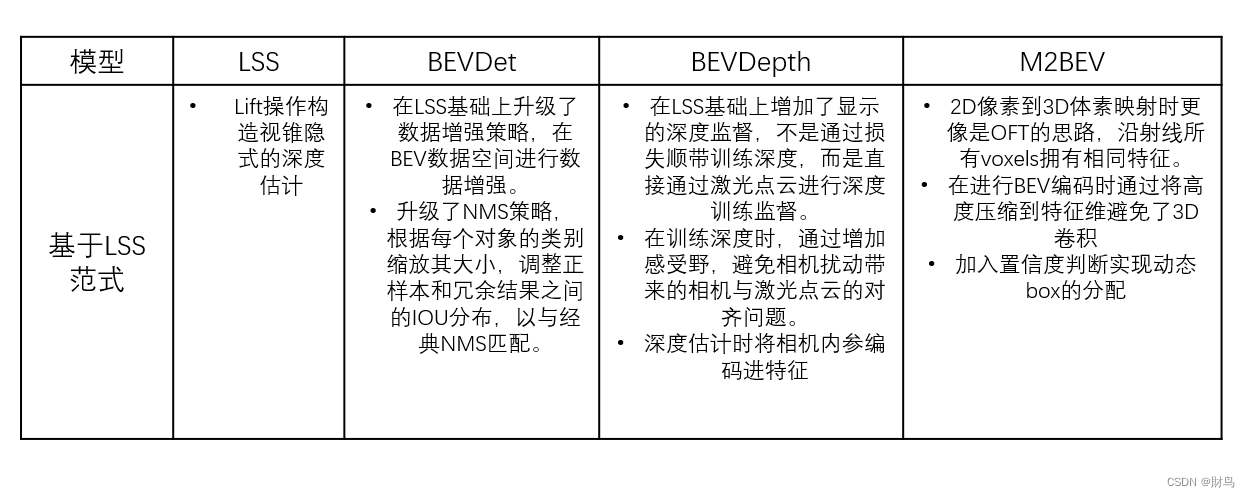
然后是基于transformer的:

然后是基于双目立体视觉的:
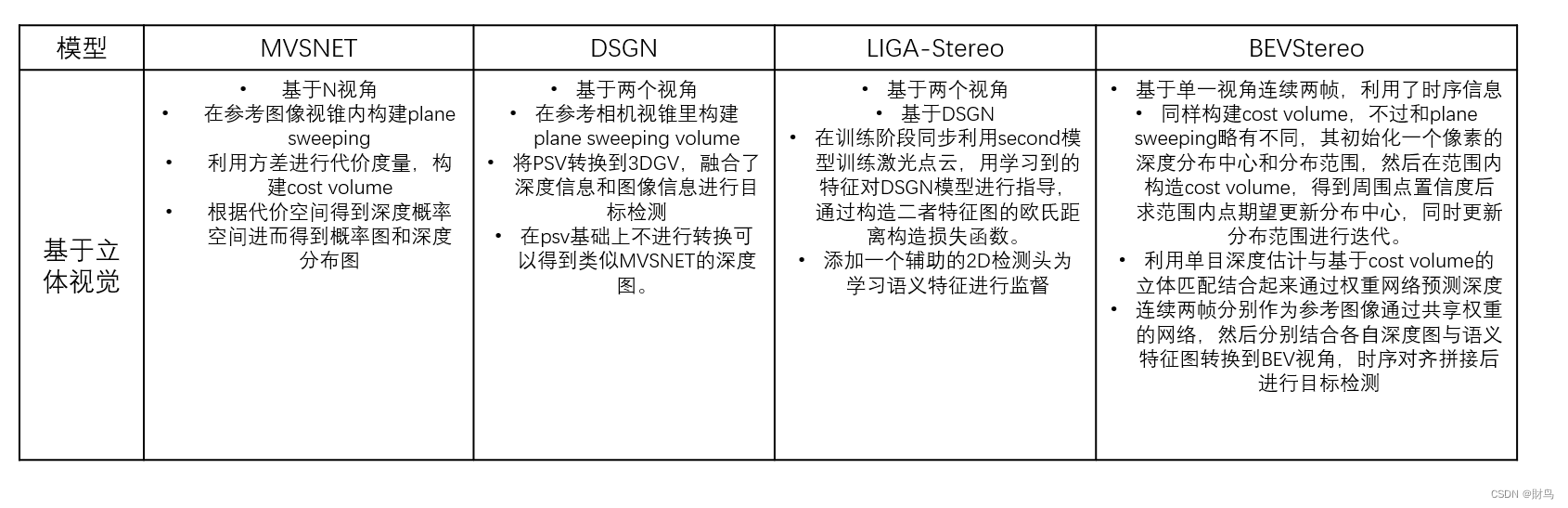
看了这些模型后的感受:
刚看基于transfromer的算法时,感觉未来的大方向就是类似于detr那种,感觉好简洁,摆脱了锚框和NMS,感觉网络可以放开干了,可是后面在detr的改进还是又加入了anchor的思想,希望基于注意力机制的模型可以多摆脱一些之前卷积网络的惯式,query在融合各种信息感觉更加自由,优雅。还有感觉双目立体视觉算法沿用了之前三维重建的很多思路,不过也差不多就是一回事,只是现在用于自动驾驶而已。还有就是看了nuscenes排行上排名前几的模型,感觉想上分就得加时序,对于视觉模型深度是最关键的点,得分高的模型不仅是多机位构造空间多视角,还要引入时序构造时序上的立体,还有就是bevdepth那种显示深度估计也起到不错的效果,不管显示隐式,我觉得在训练视觉模型时能用激光点云数据做监督才是本质。
只看论文不动手,感觉自己还是废物一个啊!
如果有研一做相同方向的可以私信我,一起学习,自己一个人学太自闭了
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/代码探险家/article/detail/815751
推荐阅读
相关标签

