
热门标签
热门文章
- 1MySQL MVCC
- 2深度学习笔记: Sigmoid激活函数_sigmoid函数
- 3leetcode 224:基本计算器_给你个字符串表达式s,请使用一种您熟悉的语言(c java, python)实现一个基本计算器
- 4第一章 Web应用基础_在web应用软件的基本结构中,客户端的基础是
- 5Docker安装jenkins,并且创建maven任务_docker下jenkins配置maven
- 6万字长文!用文本挖掘深度剖析54万首诗歌
- 7C语言[编程入门]链表之报数问题(环链表)_链表 报数问题
- 8Python中的时间序列分析与预测技术_python时间序列相关性什么指标最好
- 9springboot中 druid数据源密码加密_passwordcallbackclassname
- 10QNX在车机系统的应用_车机qnx
当前位置: article > 正文
Python爬虫入门教程!手把手教会你爬取网页数据_python爬取网页数据_python编程爬取
作者:代码探险家 | 2024-07-18 11:14:59
赞
踩
python编程爬取
from bs4 import BeautifulSoup # 导入 BeautifulSoup 的方法
# 可以传入一段字符串,或者传入一个文件句柄。一般都会先用 requests 库获取网页内容,然后使用 soup 解析。
soup = BeautifulSoup(html_doc,'html.parser') # 这里一定要指定解析器,可以使用默认的 html,也可以使用 lxml。
print(soup.prettify()) # 按照标准的缩进格式输出获取的 soup 内容。
- 1
- 2
- 3
- 4
- 5
BeautifulSoup 的一些简单用法
print(soup.title) # 获取文档的 title
print(soup.title.name) # 获取 title 的 name 属性
print(soup.title.string) # 获取 title 的内容
print(soup.p) # 获取文档中第一个 p 节点
print(soup.p['class']) # 获取第一个 p 节点的 class 内容
print(soup.find_all('a')) # 获取文档中所有的 a 节点,返回一个 list
print(soup.find_all('span', attrs={'style': "color:#ff0000"})) # 获取文档中所有的 span 且 style 符合规则的节点,返回一个 list
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
具体的用法和效果,我会在后面的实战中详细说明。
XPath 定位
XPath 是 XML 的路径语言,是通过元素和属性进行导航定位的。几种常用的表达式
表达式含义node选择 node 节点的所有子节点/从根节点选取//选取所有当前节点.当前节点…父节点@属性选取text()当前路径下的文本内容
一些简单的例子
xpath('node') # 选取 node 节点的所有子节点
xpath('/div') # 从根节点上选取 div 元素
xpath('//div') # 选取所有 div 元素
xpath('./div') # 选取当前节点下的 div 元素
xpath('//@id') # 选取所有 id 属性的节点
- 1
- 2
- 3
- 4
- 5
- 6
当然,XPath 非常强大,但是语法也相对复杂,不过我们可以通过 Chrome 的开发者工具来快速定位到元素的 xpath,如下图
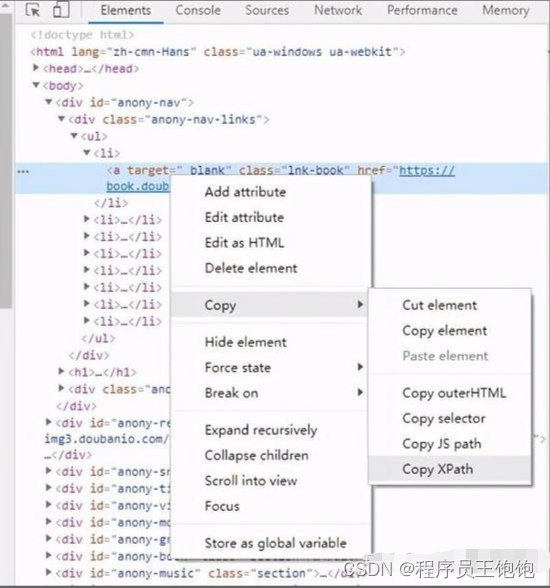
得到的 xpath 为
//*[@id="anony-nav"]/div[1]/ul/li[1]/a
- 1
- 2
在实际的使用过程中,到底使用 BeautifulSoup 还是 XPath,完全取决于个人喜好,哪个用起来更加熟练方便,就使用哪个。
爬虫实战:爬取豆瓣海报
我们可以从豆瓣影人页,进入都影人对应的影人图片页面,比如以刘涛为例子,她的影人图片页面地址为
- [https://movie.douban.com/celebrity/1011562/photos/]
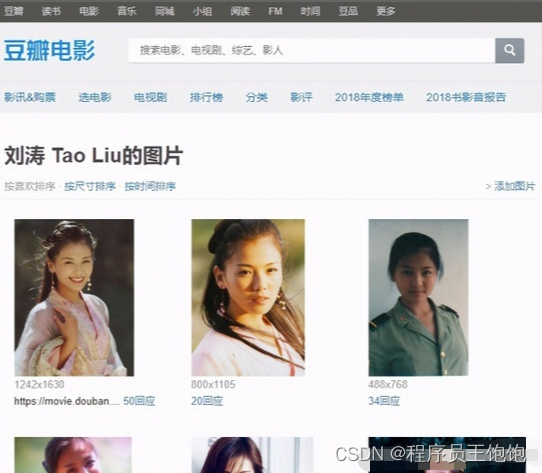
下面我们就来分析下这个网页
目标网站页面分析
注意:网络上的网站页面构成总是会变化的,所以这里你需要学会分析的方法,以此类推到其他网站。正所谓授人以鱼不如授人以渔,就是这个原因。
Chrome 开发者工具
Chrome 开发者工具(按 F12 打开),是分析网页的绝佳利器,一定要好好使用。
我们在任意一张图片上右击鼠标,选择“检查”,可以看到同样打开了“开发者工具”,而且自动定位到了该图片所在的位置
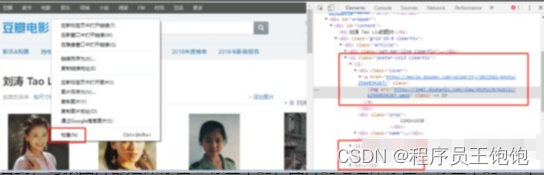
可以清晰的看到,每张图片都是保存在 li 标签中的,图片的地址保存在 li 标签中的 img 中。
知道了这些规律后,我们就可以通过 BeautifulSoup 或者 XPath 来解析 HTML 页面,从而获取其中的图片地址。
代码编写
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/代码探险家/article/detail/845315
推荐阅读

相关标签

