
- 1二叉树--C语言实现数据结构_c语言写二叉树
- 2Python OS库使用详解_pycharm os
- 3二叉树的层序遍历 + 通过层序遍历实现二叉树的操作_按照层数遍历二叉树
- 4java面试题(上)_一年java面试
- 5GNN 2021(三) Boost then Convolve: Gradient Boosting Meets Graph Neural Networks,ICLR
- 6Linux NFS服务_nfs gid uid
- 7python数据分析——用jieba和词云做知乎的数据分析_mytext=''.join(jieba.cut(mytext))
- 8FAST_LIO_SAM 融入后端优化的FASTLIO SLAM 系统 前端:FAST_LIO2 后端:LIO_SAM_fast lio sam
- 9Python——列表(list)推导式_python列表推导式
- 10Opencv cuda版本编译
Registry dubbo的注册中心_dubbo注册中心
赞
踩
1. 架构说
注册中心。注册中心(Registry)在微服务架构中的作用举足轻重,有了它,服务提供者(Provider) 和消费者(Consumer) 就能感知彼此。从下面的 Dubbo 架构图中可知:
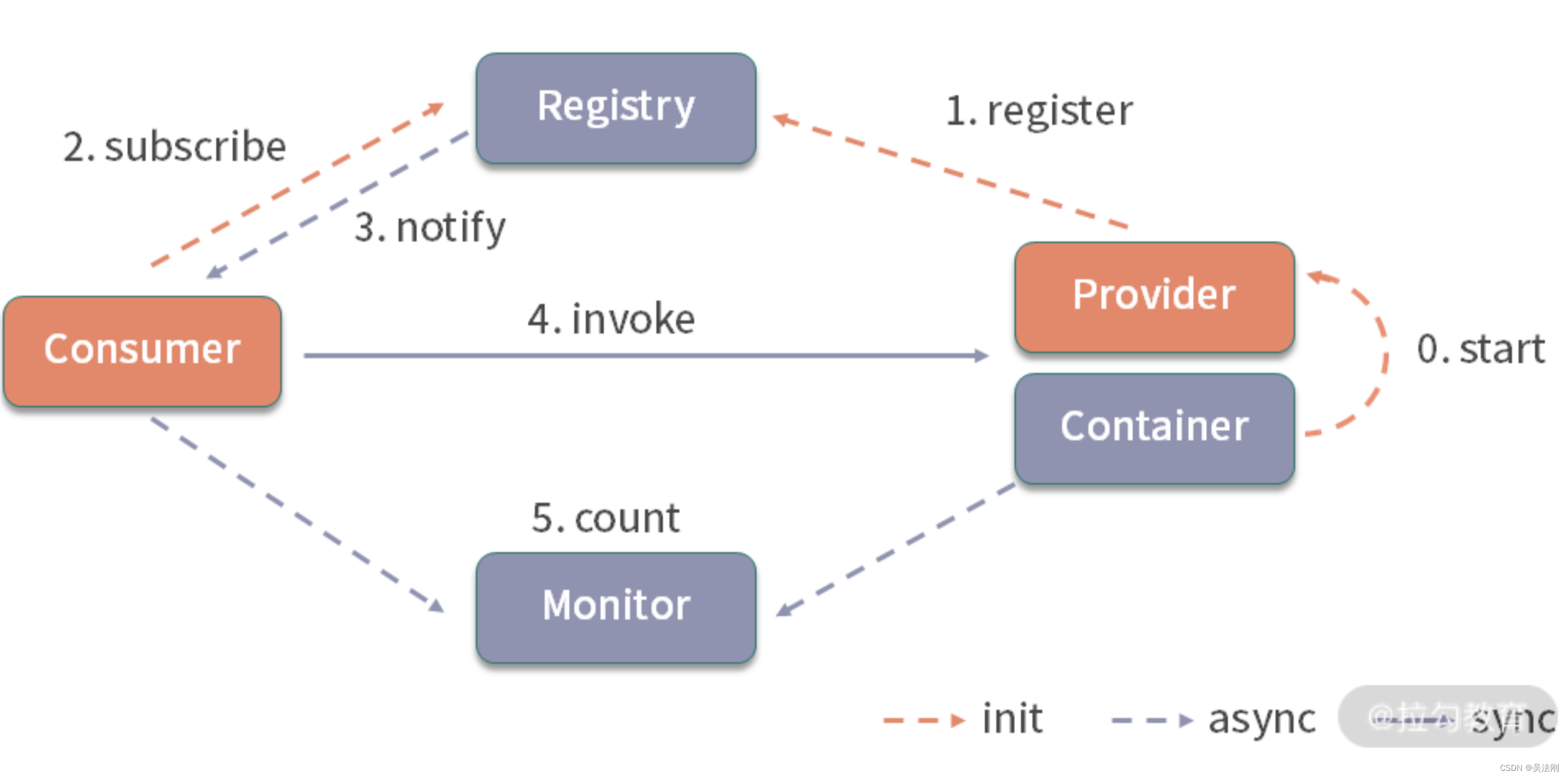
Dubbo 架构图
- Provider 从容器启动后的初始化阶段便会向注册中心完成注册操作;
- Consumer 启动初始化阶段会完成对所需 Provider 的订阅操作;
- 另外,在 Provider 发生变化时,需要通知监听的 Consumer。
Registry 只是 Consumer 和 Provider 感知彼此状态变化的一种便捷途径而已,它们彼此的实际通讯交互过程是直接进行的,对于 Registry 来说是透明无感的。Provider 状态发生变化了,会由 Registry 主动推送订阅了该 Provider 的所有 Consumer,这保证了 Consumer 感知 Provider 状态变化的及时性,也将和具体业务需求逻辑交互解耦,提升了系统的稳定性。
Dubbo 中存在很多概念,但有些理解起来就特别费劲,如本文的 Registry,翻译过来的意思是“注册中心”,但它其实是应用本地的注册中心客户端,真正的“注册中心”服务是其他独立部署的进程,或进程组成的集群,比如 ZooKeeper 集群。本地的 Registry 通过和 ZooKeeper 等进行实时的信息同步,维持这些内容的一致性,从而实现了注册中心这个特性。另外,就 Registry 而言,Consumer 和 Provider 只是个用户视角的概念,它们被抽象为了一条 URL 。
从本课时开始,我们就真正开始分析 Dubbo 源码了。首先看一下本课程第二部分内容在 Dubbo 架构中所处的位置(如下图红框所示),可以看到这部分内容在整个 Dubbo 体系中还是相对独立的,没有涉及 Protocol、Invoker 等 Dubbo 内部的概念。等介绍完这些概念之后,我们还会回看图中 Registry 红框之外的内容。
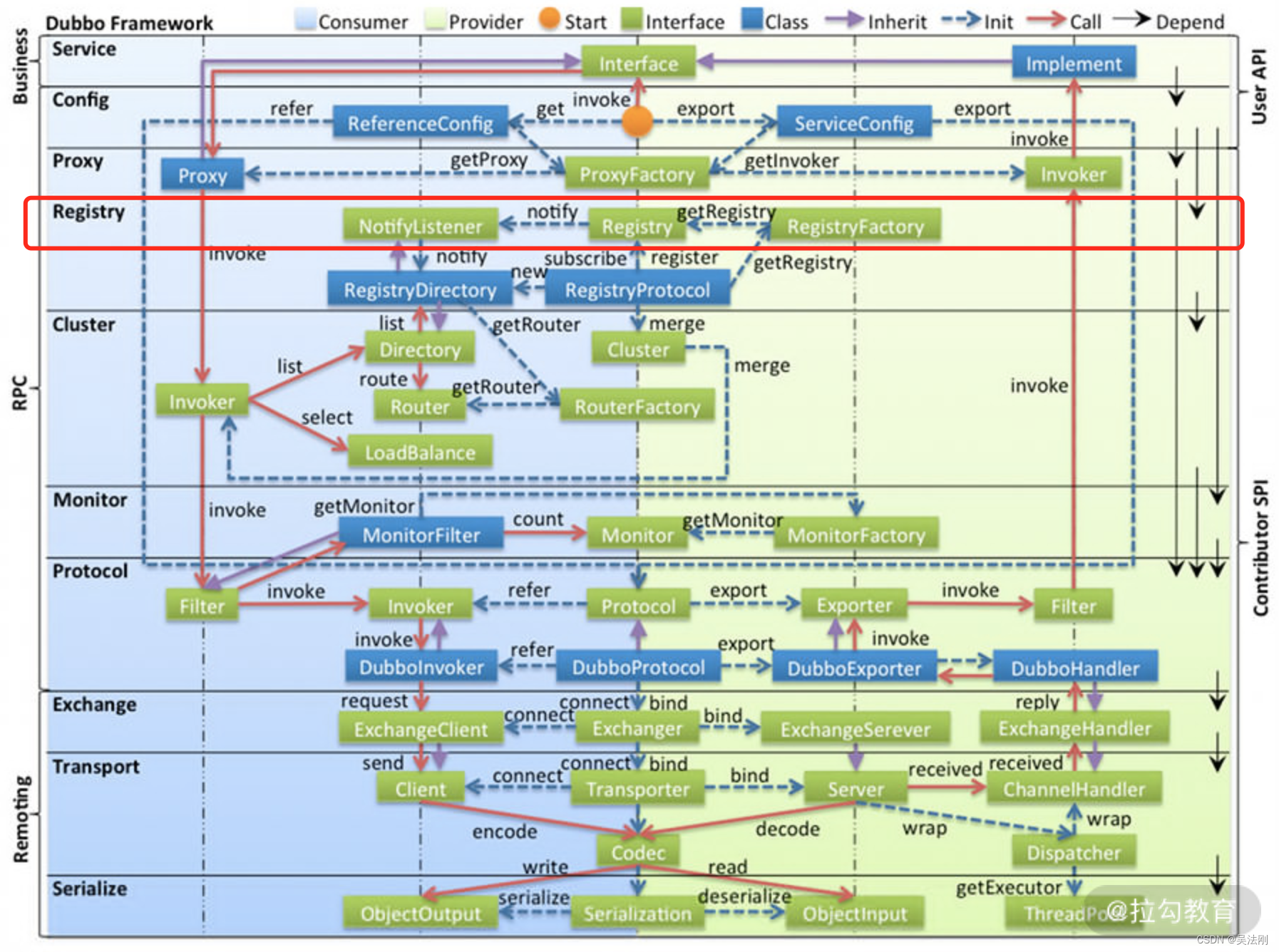
2. 源码结构截图
作为“注册中心”部分的第一课时,我们有必要介绍下 dubbo-registry-api 模块中的核心抽象接口,如下图所示:
3. 相关类的继承图
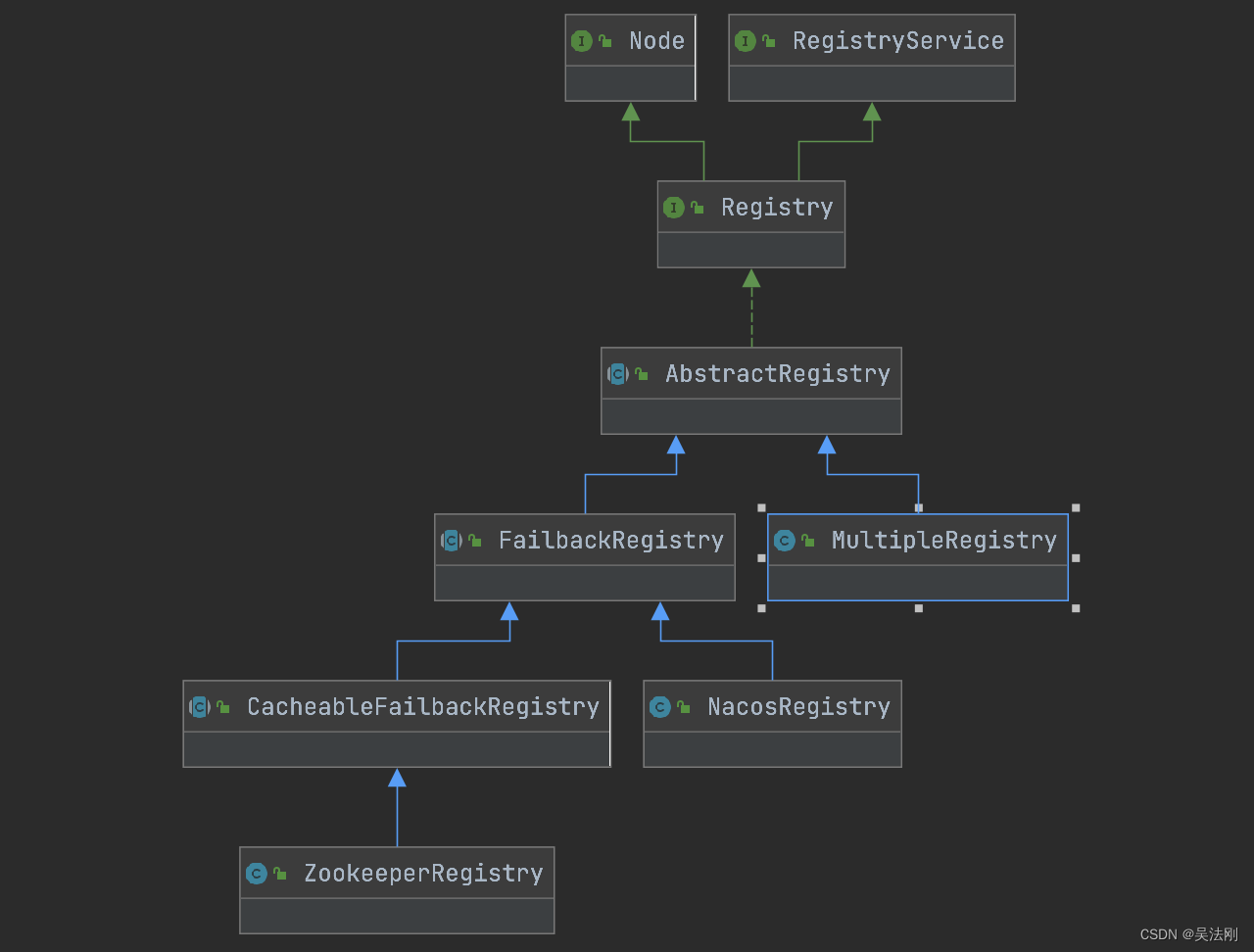
3.1 接口定义类
Node
在 Dubbo 中,一般使用 Node 这个接口来抽象节点的概念。Node不仅可以表示 Provider 和 Consumer 节点,还可以表示注册中心节点。Node 接口中定义了三个非常基础的方法(如下图所示):
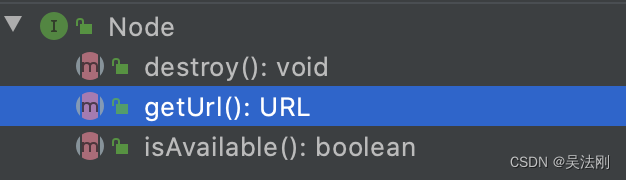
getUrl() 方法返回表示当前节点的 URL;
isAvailable() 检测当前节点是否可用;
destroy() 方法负责销毁当前节点并释放底层资源。
RegistryService
接口抽象了注册服务的基本行为,如下图所示:
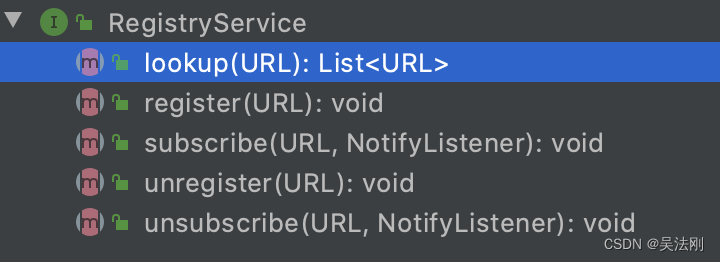
register() 方法和 unregister() 方法分别表示注册和取消注册一个 URL。
subscribe() 方法和 unsubscribe() 方法分别表示订阅和取消订阅一个 URL。订阅成功之后,当订阅的数据发生变化时,注册中心会主动通知第二个参数指定的 NotifyListener 对象,NotifyListener 接口中定义的 notify() 方法就是用来接收该通知的。
lookup() 方法能够查询符合条件的注册数据,它与 subscribe() 方法有一定的区别,subscribe() 方法采用的是 push 模式,lookup() 方法采用的是 pull 模式。
Registry
Registry 接口继承了 RegistryService 接口和 Node 接口,如下图所示,它表示的就是一个拥有注册中心能力的节点,其中的 reExportRegister() 和 reExportUnregister() 方法都是委托给 RegistryService 中的相应方法。
public interface Registry extends Node, RegistryService {
default int getDelay() {
return getUrl().getParameter(REGISTRY_DELAY_NOTIFICATION_KEY, DEFAULT_DELAY_NOTIFICATION_TIME);
}
default boolean isServiceDiscovery() {
return false;
}
default void reExportRegister(URL url) {
register(url);
}
default void reExportUnregister(URL url) {
unregister(url);
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
3.2 抽象层 AbstractRegistry 本地缓存
AbstractRegistry 本地缓存:降低 ZooKeeper 压力的一个常用手段
AbstractRegistry 实现了 Registry 接口,虽然 AbstractRegistry 本身在内存中实现了注册数据的读写功能,也没有什么抽象方法,但它依然被标记成了抽象类,从前面的Registry 继承关系图中可以看出,Registry 接口的所有实现类都继承了 AbstractRegistry。
为了减轻注册中心组件的压力,AbstractRegistry 会把当前节点订阅的 URL 信息缓存到本地的 Properties 文件中,其核心字段如下:
- registryUrl(URL类型)。 该 URL 包含了创建该 Registry 对象的全部配置信息,是 AbstractRegistryFactory 修改后的产物。
- properties(Properties 类型)、file(File 类型)。 本地的 Properties 文件缓存,properties 是加载到内存的 Properties 对象,file 是磁盘上对应的文件,两者的数据是同步的。在 AbstractRegistry 初始化时,会根据 registryUrl 中的 file.cache 参数值决定是否开启文件缓存。如果开启文件缓存功能,就会立即将 file 文件中的 KV 缓存加载到 properties 字段中。当 properties 中的注册数据发生变化时,会写入本地的 file 文件进行同步。properties 是一个 KV 结构,其中 Key 是当前节点作为 Consumer 的一个 URL,Value 是对应的 Provider 列表,包含了所有 Category(例如,providers、routes、configurators 等) 下的 URL。properties 中有一个特殊的 Key 值为 registies,对应的 Value 是注册中心列表,其他记录的都是 Provider 列表。
- syncSaveFile(boolean 类型)。 是否同步保存文件的配置,对应的是 registryUrl 中的 save.file 参数。
- registryCacheExecutor(ExecutorService 类型)。 这是一个单线程的线程池,在一个 Provider 的注册数据发生变化的时候,会将该 Provider 的全量数据同步到 properties 字段和缓存文件中,如果 syncSaveFile 配置为 false,就由该线程池异步完成文件写入。
lastCacheChanged(AtomicLong 类型)。 注册数据的版本号,每次写入 file 文件时,都是全覆盖写入,而不是修改文件,所以需要版本控制,防止旧数据覆盖新数据。 - registered(Set 类型)。 这个比较简单,它是注册的 URL 集合。
- subscribed(ConcurrentMap<URL, Set> 类型)。 表示订阅 URL 的监听器集合,其中 Key 是被监听的 URL, Value 是相应的监听器集合。
- notified(ConcurrentMap<URL, Map<String, List>>类型)。 该集合第一层 Key 是当前节点作为 Consumer 的一个 URL,表示的是该节点的某个 Consumer 角色(一个节点可以同时消费多个 Provider 节点);Value 是一个 Map 集合,该 Map 集合的 Key 是 Provider URL 的分类(Category),例如 providers、routes、configurators 等,Value 就是相应分类下的 URL 集合。
介绍完 AbstractRegistry 的核心字段之后,我们接下来就再看看 AbstractRegistry 依赖这些字段都提供了哪些公共能力。
3.2.1 本地缓存
作为一个 RPC 框架,Dubbo 在微服务架构中解决了各个服务间协作的难题;作为 Provider 和 Consumer 的底层依赖,它会与服务一起打包部署。dubbo-registry 也仅仅是其中一个依赖包,负责完成与 ZooKeeper、etcd、Consul 等服务发现组件的交互。
当 Provider 端暴露的 URL 发生变化时,ZooKeeper 等服务发现组件会通知 Consumer 端的 Registry 组件,Registry 组件会调用 notify() 方法,被通知的 Consumer 能匹配到所有 Provider 的 URL 列表并写入 properties 集合中。
下面我们来看 notify() 方法的核心实现:
/**
* Notify changes from the provider side.
*
* @param url consumer side url
* @param listener listener
* @param urls provider latest urls
* // 注意入参,第一个URL参数表示的是Consumer,
* 第二个NotifyListener是第一个参数对应的监听器,
* 第三个参数是Provider端暴露的URL的全量数据
*/
protected void notify(URL url, NotifyListener listener, List<URL> urls) {
// keep every provider's category.
Map<String, List<URL>> result = new HashMap<>();
for (URL u : urls) {
// 需要Consumer URL与Provider URL匹配,具体匹配规则后面详述
if (UrlUtils.isMatch(url, u)) {
// 根据Provider URL中的category参数进行分类
//category 有:providers、consumers、configurators、routers
String category = u.getCategory(DEFAULT_CATEGORY);
List<URL> categoryList = result.computeIfAbsent(category, k -> new ArrayList<>());
categoryList.add(u);
}
}
if (result.size() == 0) {
return;
}
Map<String, List<URL>> categoryNotified = notified.computeIfAbsent(url, u -> new ConcurrentHashMap<>());
for (Map.Entry<String, List<URL>> entry : result.entrySet()) {
String category = entry.getKey();
List<URL> categoryList = entry.getValue();
categoryNotified.put(category, categoryList);
// 调用NotifyListener
listener.notify(categoryList);
// We will update our cache file after each notification.
// When our Registry has a subscribed failure due to network jitter, we can return at least the existing cache URL.
if (localCacheEnabled) {
// 更新properties集合以及底层的文件缓存
saveProperties(url);
}
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
在 saveProperties() 方法中会取出 Consumer 订阅的各个分类的 URL 连接起来(中间以空格分隔),然后以 Consumer 的 ServiceKey 为键值写到 properties 中,同时 lastCacheChanged 版本号会自增。完成 properties 字段的更新之后,会根据 syncSaveFile 字段值来决定是在当前线程同步更新 file 文件,还是向 registryCacheExecutor 线程池提交任务,异步完成 file 文件的同步。本地缓存文件的具体路径是:
/.dubbo/dubbo-registry-[当前应用名]-[当前Registry所在的IP地址].cache
这里首先关注第一个细节:UrlUtils.isMatch() 方法。该方法会完成 Consumer URL 与 Provider URL 的匹配,依次匹配的部分如下所示:
- 匹配 Consumer 和 Provider 的接口(优先取 interface 参数,其次再取 path)。双方接口相同或者其中一方为“*”,则匹配成功,执行下一步。
- 匹配 Consumer 和 Provider 的 category。
- 检测 Consumer URL 和 Provider URL 中的 enable 参数是否符合条件。
- 检测 Consumer 和 Provider 端的 group、version 以及 classifier 是否符合条件。
第二个细节是:URL.getServiceKey() 方法。该方法返回的 ServiceKey 是 properties 集合以及相应缓存文件中的 Key。ServiceKey 的格式如下:
[group]/{interface(或path)}[:version]
AbstractRegistry 的核心是本地文件缓存的功能。 在 AbstractRegistry 的构造方法中,会调用 loadProperties() 方法将上面写入的本地缓存文件,加载到 properties 对象中。
在网络抖动等原因而导致订阅失败时,Consumer 端的 Registry 就可以调用 getCacheUrls() 方法获取本地缓存,从而得到最近注册的 Provider URL。可见,AbstractRegistry 通过本地缓存提供了一种容错机制,保证了服务的可靠性。
3.2.2. 注册/订阅
AbstractRegistry 实现了 Registry 接口,它实现的 registry() 方法会将当前节点要注册的 URL 缓存到 registered 集合,而 unregistry() 方法会从 registered 集合删除指定的 URL,例如当前节点下线的时候。
subscribe() 方法会将当前节点作为 Consumer 的 URL 以及相关的 NotifyListener 记录到 subscribed 集合,unsubscribe() 方法会将当前节点的 URL 以及关联的 NotifyListener 从 subscribed 集合删除。
这四个方法都是简单的集合操作,这里我们就不再展示具体代码了。
单看 AbstractRegistry 的实现,上述四个基础的注册、订阅方法都是内存操作,但是 Java 有继承和多态的特性,AbstractRegistry 的子类会覆盖上述四个基础的注册、订阅方法进行增强。
3.2.3. 恢复/销毁
AbstractRegistry 中还有另外两个需要关注的方法:recover() 方法和destroy() 方法。
在 Provider 因为网络问题与注册中心断开连接之后,会进行重连,重新连接成功之后,会调用 recover() 方法将 registered 集合中的全部 URL 重新走一遍 register() 方法,恢复注册数据。同样,recover() 方法也会将 subscribed 集合中的 URL 重新走一遍 subscribe() 方法,恢复订阅监听器。recover() 方法的具体实现比较简单,这里就不再展示,你若感兴趣的话,可以参考源码进行学习。
在当前节点下线的时候,会调用 Node.destroy() 方法释放底层资源。AbstractRegistry 实现的 destroy() 方法会调用 unregister() 方法和 unsubscribe() 方法将当前节点注册的 URL 以及订阅的监听全部清理掉,其中不会清理非动态注册的 URL(即 dynamic 参数明确指定为 false)。AbstractRegistry 中 destroy() 方法的实现比较简单,这里我们也不再展示,如果你感兴趣话,同样可以参考源码进行学习。
3.3 FailbackRegistry 网络重试
具体的实现一般继承这个类进行
重试机制是网络操作的基本保证
在真实的微服务系统中, ZooKeeper、etcd 等服务发现组件一般会独立部署成一个集群,业务服务通过网络连接这些服务发现节点,完成注册和订阅操作。但即使是机房内部的稳定网络,也无法保证两个节点之间的请求一定成功,因此 Dubbo 这类 RPC 框架在稳定性和容错性方面,就受到了比较大的挑战。为了保证服务的可靠性,重试机制就变得必不可少了。
所谓的 “重试机制”就是在请求失败时,客户端重新发起一个一模一样的请求,尝试调用相同或不同的服务端,完成相应的业务操作。能够使用重试机制的业务接口得是“幂等”的,也就是无论请求发送多少次,得到的结果都是一样的,例如查询操作。
3.3.1 核心设计
在上一课时中,我们介绍了 AbstractRegistry 中的 register()/unregister()、subscribe()/unsubscribe() 以及 notify() 等核心操作,详细分析了通过本地缓存实现的容错功能。其实,这几个核心方法同样也是重试机制的关注点。
dubbo-registry 将重试机制的相关实现放到了 AbstractRegistry 的子类—— FailbackRegistry 中。如下图所示,接入 ZooKeeper、etcd 等开源服务发现组件的 Registry 实现,都继承FailbackRegistry,也就都拥有了失败重试的能力。
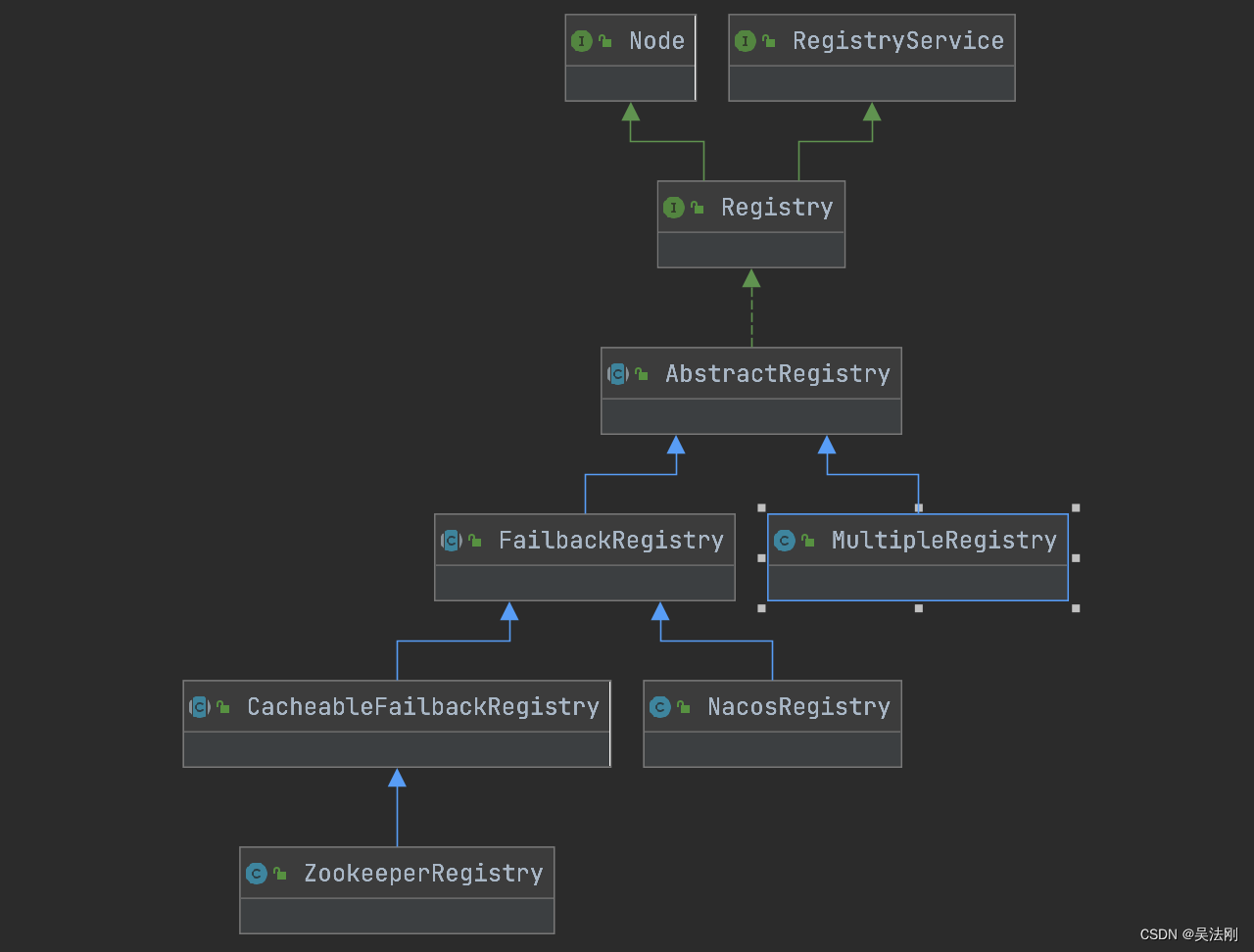
FailbackRegistry 设计核心是:覆盖了 AbstractRegistry 中 register()/unregister()、subscribe()/unsubscribe() 以及 notify() 这五个核心方法,结合前面介绍的时间轮,实现失败重试的能力;真正与服务发现组件的交互能力则是放到了 doRegister()/doUnregister()、doSubscribe()/doUnsubscribe() 以及 doNotify() 这五个抽象方法中,由具体子类实现。这是典型的模板方法模式的应用。
3.3.2 核心字段介绍
分析一个实现类的第一步就是了解其核心字段,那 FailbackRegistry 的核心字段有哪些呢?
- retryTimer(HashedWheelTimer 类型):用于定时执行失败重试操作的时间轮。
- retryPeriod(int 类型):重试操作的时间间隔。
- failedRegistered(ConcurrentMap<URL, FailedRegisteredTask>类型):注册失败的 URL 集合,其中 Key 是注册失败的 URL,Value 是对应的重试任务。
- failedUnregistered(ConcurrentMap<URL, FailedUnregisteredTask>类型):取消注册失败的 URL 集合,其中 Key 是取消注册失败的 URL,Value 是对应的重试任务。
- failedSubscribed(ConcurrentMap<Holder, FailedSubscribedTask>类型):订阅失败 URL 集合,其中 Key 是订阅失败的 URL + Listener 集合,Value 是相应的重试任务。
- failedUnsubscribed(ConcurrentMap<URL, Set>类型):取消订阅失败的 URL 集合,其中 Key 是取消订阅失败的 URL + Listener 集合,Value 是相应的重试任务。
- failedNotified(ConcurrentMap<Holder, FailedNotifiedTask>类型):通知失败的 URL 集合,其中 Key 是通知失败的 URL + Listener 集合,Value 是相应的重试任务。
在 FailbackRegistry 的构造方法中,首先会调用父类 AbstractRegistry 的构造方法完成本地缓存相关的初始化操作,然后从传入的 URL 参数中获取重试操作的时间间隔(即retry.period 参数)来初始化 retryPeriod 字段,最后初始化 retryTimer时间轮。整个代码比较简单,这里就不展示了。
3.3.3 核心方法实现分析
FailbackRegistry 对 register()/unregister() 方法和 subscribe()/unsubscribe() 方法的具体实现非常类似,所以这里我们就只介绍其中register() 方法的具体实现流程。
- 根据 registryUrl 中 accepts 参数指定的匹配模式,决定是否接受当前要注册的 Provider URL。
- 调用父类 AbstractRegistry 的 register() 方法,将 Provider URL 写入 registered 集合中。
- 调用 removeFailedRegistered() 方法和 removeFailedUnregistered() 方法,将该 Provider URL 从 failedRegistered 集合和 failedUnregistered 集合中删除,并停止相关的重试任务。
- 调用 doRegister() 方法,与服务发现组件进行交互。该方法由子类实现,每个子类只负责接入一个特定的服务发现组件。
- 在 doRegister() 方法出现异常的时候,会根据 URL 参数以及异常的类型,进行分类处理:待注册 URL 的 check 参数为 true(默认值为 true);待注册的 URL 不是 consumer 协议;registryUrl 的 check 参数也为 true(默认值为 true)。若满足这三个条件或者抛出的异常为 SkipFailbackWrapperException,则直接抛出异常。否则,就会创建重试任务并添加到 failedRegistered 集合中。
明确 register() 方法的核心流程之后,我们再来看 register() 方法的具体代码实现:
@Override
public void register(URL url) {
//参数指定的匹配模式,决定是否接受当前要注册的 Provider URL
if (!acceptable(url)) {
logger.info("URL " + url + " will not be registered to Registry. Registry " + this.getUrl() + " does not accept service of this protocol type.");
return;
}
// 完成本地文件缓存的初始化
super.register(url);
// 清理failedRegistered集合和failedUnregistered集合,并取消相关任务
removeFailedRegistered(url);
removeFailedUnregistered(url);
try {
// Sending a registration request to the server side
// 与服务发现组件进行交互,具体由子类实现
doRegister(url);
} catch (Exception e) {
Throwable t = e;
// If the startup detection is opened, the Exception is thrown directly.
// 检测check参数,决定是否直接抛出异常
boolean check = getUrl().getParameter(Constants.CHECK_KEY, true)
&& url.getParameter(Constants.CHECK_KEY, true)
&& (url.getPort() != 0);
boolean skipFailback = t instanceof SkipFailbackWrapperException;
if (check || skipFailback) {
if (skipFailback) {
t = t.getCause();
}
throw new IllegalStateException("Failed to register " + url + " to registry " + getUrl().getAddress() + ", cause: " + t.getMessage(), t);
} else {
logger.error(INTERNAL_ERROR, "unknown error in registry module", "", "Failed to register " + url + ", waiting for retry, cause: " + t.getMessage(), t);
}
// Record a failed registration request to a failed list, retry regularly
// 如果不抛出异常,则创建失败重试的任务,并添加到failedRegistered集合中
addFailedRegistered(url);
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
从以上代码可以看出,当 Provider 向 Registry 注册 URL 的时候,如果注册失败,且未设置 check 属性,则创建一个定时任务,添加到时间轮中。
下面我们再来看看创建并添加这个重试任务的相关方法——addFailedRegistered() 方法,具体实现如下:
private void addFailedRegistered(URL url) {
FailedRegisteredTask oldOne = failedRegistered.get(url);
if (oldOne != null) { // 已经存在重试任务,则无须创建,直接返回
return;
}
FailedRegisteredTask newTask = new FailedRegisteredTask(url, this);
oldOne = failedRegistered.putIfAbsent(url, newTask);
if (oldOne == null) {
// never has a retry task. then start a new task for retry.
// 如果是新建的重试任务,则提交到时间轮中,等待retryPeriod毫秒后执行
retryTimer.newTimeout(newTask, retryPeriod, TimeUnit.MILLISECONDS);
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
3.3.4 重试任务
FailbackRegistry.addFailedRegistered() 方法中创建的 FailedRegisteredTask 任务以及其他的重试任务,都继承了 AbstractRetryTask 抽象类,如下图所示:

在 AbstractRetryTask 中维护了当前任务关联的 URL、当前重试的次数等信息,在其 run() 方法中,会根据重试 URL 中指定的重试次数(retry.times 参数,默认值为 3)、任务是否被取消以及时间轮的状态,决定此次任务的 doRetry() 方法是否正常执行。
public void run(Timeout timeout) throws Exception {
if (timeout.isCancelled() || timeout.timer().isStop() || isCancel()) {
// other thread cancel this timeout or stop the timer.
return;
}
if (times > retryTimes) {
// 1-13 - failed to execute the retrying task.
logger.warn(
REGISTRY_EXECUTE_RETRYING_TASK, "registry center offline", "Check the registry server.",
"Final failed to execute task " + taskName + ", url: " + url + ", retry " + retryTimes + " times.");
return;
}
if (logger.isInfoEnabled()) {
logger.info(taskName + " : " + url);
}
try {
doRetry(url, registry, timeout);
} catch (Throwable t) { // Ignore all the exceptions and wait for the next retry
// 1-13 - failed to execute the retrying task.
logger.warn(REGISTRY_EXECUTE_RETRYING_TASK, "registry center offline", "Check the registry server.",
"Failed to execute task " + taskName + ", url: " + url + ", waiting for again, cause:" + t.getMessage(), t);
// reput this task when catch exception.
reput(timeout, retryPeriod);
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
如果任务的 doRetry() 方法执行出现异常,AbstractRetryTask 会通过 reput() 方法将当前任务重新放入时间轮中,并递增当前任务的执行次数。
protected void reput(Timeout timeout, long tick) {
if (timeout == null) {
throw new IllegalArgumentException();
}
Timer timer = timeout.timer();
if (timer.isStop() || timeout.isCancelled() || isCancel()) {
return;
}
times++;
timer.newTimeout(timeout.task(), tick, TimeUnit.MILLISECONDS);
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
AbstractRetryTask 将 doRetry() 方法作为抽象方法,留给子类实现具体的重试逻辑,这也是模板方法的使用。
在子类 FailedRegisteredTask 的 doRetry() 方法实现中,会再次执行关联 Registry 的 doRegister() 方法,完成与服务发现组件交互。如果注册成功,则会调用 removeFailedRegisteredTask() 方法将当前关联的 URL 以及当前重试任务从 failedRegistered 集合中删除。如果注册失败,则会抛出异常,执行上文介绍的 reput ()方法重试。
另外,在 register() 方法入口处,会主动调用 removeFailedRegistered() 方法和 removeFailedUnregistered() 方法来清理指定 URL 关联的定时任务:
3.3.5 其他核心方法
unregister() 方法以及 unsubscribe() 方法的实现方式与 register() 方法类似,只是调用的 do*() 抽象方法、依赖的 AbstractRetryTask 有所不同而已,这里就不再展开细讲。
你还记得上一课时我们介绍的 AbstractRegistry 通过本地文件缓存实现的容错机制吗?FailbackRegistry.subscribe() 方法在处理异常的时候,会先获取缓存的订阅数据并调用 notify() 方法,如果没有缓存相应的订阅数据,才会检查 check 参数决定是否抛出异常。
通过上一课时对 AbstractRegistry.notify() 方法的介绍,我们知道其核心逻辑之一就是回调 NotifyListener。下面我们就来看一下 FailbackRegistry 对 notify() 方法的覆盖:
protected void notify(URL url, NotifyListener listener,
List<URL> urls) {
... // 检查url和listener不为空(略)
try {
// FailbackRegistry.doNotify()方法实际上就是调用父类
// AbstractRegistry.notify()方法,没有其他逻辑
doNotify(url, listener, urls);
} catch (Exception t) {
// doNotify()方法出现异常,则会添加一个定时任务
addFailedNotified(url, listener, urls);
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
addFailedNotified() 方法会创建相应的 FailedNotifiedTask 任务,添加到 failedNotified 集合中,同时也会添加到时间轮中等待执行。如果已存在相应的 FailedNotifiedTask 重试任务,则会更新任务需要处理的 URL 集合。
在 FailedNotifiedTask 中维护了一个 URL 集合,用来记录当前任务一次运行需要通知的 URL,每执行完一次任务,就会清空该集合,具体实现如下:
protected void doRetry(URL url, FailbackRegistry registry,
Timeout timeout) {
// 如果urls集合为空,则会通知所有Listener,该任务也就啥都不做了
if (CollectionUtils.isNotEmpty(urls)) {
listener.notify(urls);
urls.clear();
}
reput(timeout, retryPeriod); // 将任务重新添加到时间轮中等待执行
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
从上面的代码可以看出,FailedNotifiedTask 重试任务一旦被添加,就会一直运行下去,但真的是这样吗?在 FailbackRegistry 的 subscribe()、unsubscribe() 方法中,可以看到 removeFailedNotified() 方法的调用,这里就是清理 FailedNotifiedTask 任务的地方。我们以 FailbackRegistry.subscribe() 方法为例进行介绍:
public void subscribe(URL url, NotifyListener listener) {
super.subscribe(url, listener);
removeFailedSubscribed(url, listener); // 关注这个方法
try {
doSubscribe(url, listener);
} catch (Exception e) {
addFailedSubscribed(url, listener);
}
}
// removeFailedSubscribed()方法中会清理FailedSubscribedTask、FailedUnsubscribedTask、FailedNotifiedTask三类定时任务
private void removeFailedSubscribed(URL url, NotifyListener listener) {
Holder h = new Holder(url, listener); // 清理FailedSubscribedTask
FailedSubscribedTask f = failedSubscribed.remove(h);
if (f != null) {
f.cancel();
}
removeFailedUnsubscribed(url, listener);// 清理FailedUnsubscribedTask
removeFailedNotified(url, listener); // 清理FailedNotifiedTask
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
介绍完 FailbackRegistry 中最核心的注册/订阅实现之后,我们再来关注其实现的恢复功能,也就是 recover() 方法。该方法会直接通过 FailedRegisteredTask 任务处理 registered 集合中的全部 URL,通过 FailedSubscribedTask 任务处理 subscribed 集合中的 URL 以及关联的 NotifyListener。
FailbackRegistry 在生命周期结束时,会调用自身的 destroy() 方法,其中除了调用父类的 destroy() 方法之外,还会调用时间轮(即 retryTimer 字段)的 stop() 方法,释放时间轮相关的资源。
3.4 ZookeeperRegistry 具体的实现
ZooKeeper 注册中心实现,官方推荐注册中心实践
ZooKeeper 是为分布式应用所设计的高可用且一致性的开源协调服务。它是一个树型的目录服务,支持变更推送,非常适合应用在生产环境中。
在 ZookeeperRegistry 的构造方法中,会通过 ZookeeperTransporter 创建 ZookeeperClient 实例并连接到 Zookeeper 集群,同时还会添加一个连接状态的监听器。在该监听器中主要关RECONNECTED 状态和 NEW_SESSION_CREATED 状态,在当前 Dubbo 节点与 Zookeeper 的连接恢复或是 Session 恢复的时候,会重新进行注册/订阅,防止数据丢失。这段代码比较简单,我们就不展开分析了。
doRegister() 方法和 doUnregister() 方法的实现都是通过 ZookeeperClient 找到合适的路径,然后创建(或删除)相应的 ZNode 节点。这里唯一需要注意的是,doRegister() 方法注册 Provider URL 的时候,会根据 dynamic 参数决定创建临时 ZNode 节点还是持久 ZNode 节点(默认创建临时 ZNode 节点),这样当 Provider 端与 Zookeeper 会话关闭时,可以快速将变更推送到 Consumer 端。
这里注意一下 toUrlPath() 这个方法得到的路径,是由下图中展示的方法拼装而成的,其中每个方法对应本课时开始展示的 Zookeeper 节点层级图中的一层。

doSubscribe() 方法的核心是通过 ZookeeperClient 在指定的 path 上添加 ChildListener 监听器,当订阅的节点发现变化的时候,会通过 ChildListener 监听器触发 notify() 方法,在 notify() 方法中会触发传入的 NotifyListener 监听器。
从 doSubscribe() 方法的代码结构可看出,doSubscribe() 方法的逻辑分为了两个大的分支。
一个分支是处理:订阅 URL 中明确指定了 Service 层接口的订阅请求。该分支会从 URL 拿到 Consumer 关注的 category 节点集合,然后在每个 category 节点上添加 ChildListener 监听器。下面是 Demo 示例中 Consumer 订阅的三个 path,图中展示了构造 path 各个部分的相关方法:
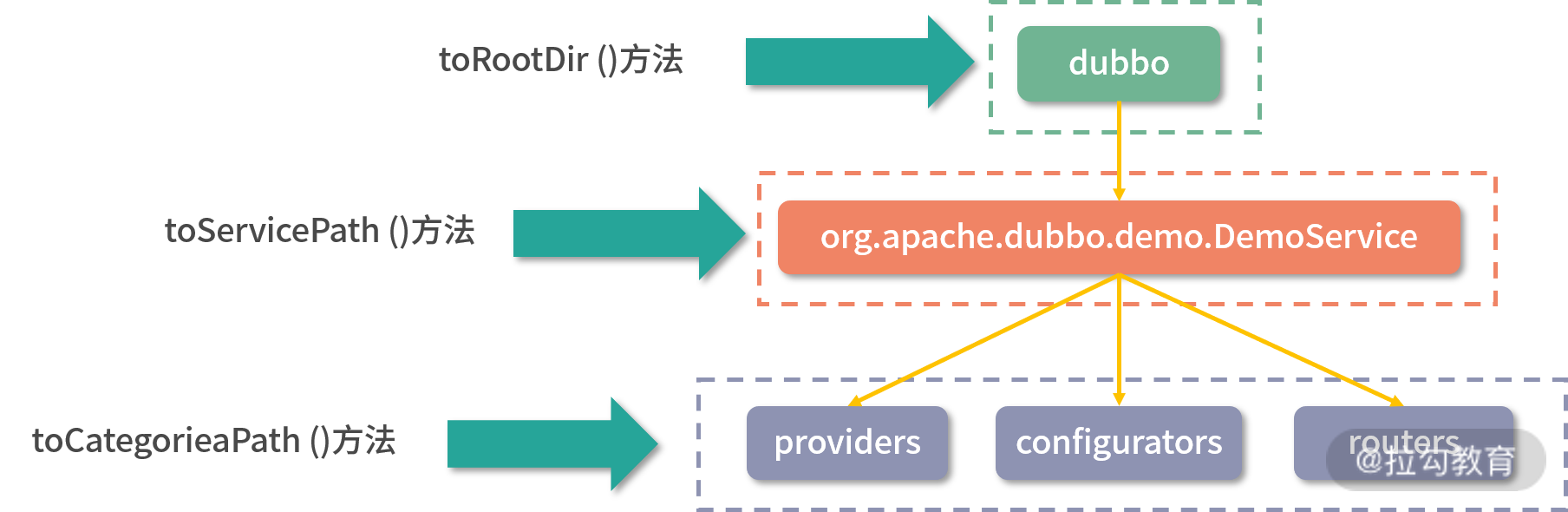
下面是这个分支的核心源码分析:
List<URL> urls = new ArrayList<>();
for (String path : toCategoriesPath(url)) { // 要订阅的所有path
// 订阅URL对应的Listener集合
ConcurrentMap<NotifyListener, ChildListener> listeners =
zkListeners.computeIfAbsent(url,
k -> new ConcurrentHashMap<>());
// 一个NotifyListener关联一个ChildListener,这个ChildListener会回调
// ZookeeperRegistry.notify()方法,其中会回调当前NotifyListener
ChildListener zkListener = listeners.computeIfAbsent(listener,
k -> (parentPath, currentChilds) ->
ZookeeperRegistry.this.notify(url, k,
toUrlsWithEmpty(url, parentPath, currentChilds)));
// 尝试创建持久节点,主要是为了确保当前path在Zookeeper上存在
zkClient.create(path, false);
// 这一个ChildListener会添加到多个path上
List<String> children = zkClient.addChildListener(path,
zkListener);
if (children != null) {
// 如果没有Provider注册,toUrlsWithEmpty()方法会返回empty协议的URL
urls.addAll(toUrlsWithEmpty(url, path, children));
}
}
// 初次订阅的时候,会主动调用一次notify()方法,通知NotifyListener处理当前已有的
// URL等注册数据
notify(url, listener, urls);
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
doSubscribe() 方法的另一个分支是处理:监听所有 Service 层节点的订阅请求,例如,Monitor 就会发出这种订阅请求,因为它需要监控所有 Service 节点的变化。这个分支的处理逻辑是在根节点上添加一个 ChildListener 监听器,当有 Service 层的节点出现的时候,会触发这个 ChildListener,其中会重新触发 doSubscribe() 方法执行上一个分支的逻辑(即前面分析的针对确定的 Service 层接口订阅分支)。
下面是针对这个分支核心代码的分析:
String root = toRootPath(); // 获取根节点
// 获取NotifyListener对应的ChildListener
ConcurrentMap<NotifyListener, ChildListener> listeners =
zkListeners.computeIfAbsent(url, k -> new ConcurrentHashMap<>());
ChildListener zkListener = listeners.computeIfAbsent(listener, k ->
(parentPath, currentChilds) -> {
for (String child : currentChilds) {
child = URL.decode(child);
if (!anyServices.contains(child)) {
anyServices.add(child); // 记录该节点已经订阅过
// 该ChildListener要做的就是触发对具体Service节点的订阅
subscribe(url.setPath(child).addParameters("interface",
child, "check", String.valueOf(false)), k);
}
}
});
zkClient.create(root, false); // 保证根节点存在
// 第一次订阅的时候,要处理当前已有的Service层节点
List<String> services = zkClient.addChildListener(root, zkListener);
if (CollectionUtils.isNotEmpty(services)) {
for (String service : services) {
service = URL.decode(service);
anyServices.add(service);
subscribe(url.setPath(service).addParameters(INTERFACE_KEY,
service, "check", String.valueOf(false)), listener);
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
ZookeeperRegistry 提供的 doUnsubscribe() 方法实现会将 URL 和 NotifyListener 对应的 ChildListener 从相关的 path 上删除,从而达到不再监听该 path 的效果。
3.4.1 ZookeeperRegistry 工厂类 ZookeeperRegistryFactory
ZookeeperRegistryFactory 实现了 AbstractRegistryFactory,其中的 createRegistry() 方法会创建 ZookeeperRegistry 实例,后续将由该 ZookeeperRegistry 实例完成与 Zookeeper 的交互。
另外,ZookeeperRegistryFactory 中还提供了一个 setZookeeperTransporter() 方法,你可以回顾一下之前我们介绍的 Dubbo SPI 机制,会通过 SPI 或 Spring Ioc 的方式完成自动装载。
根据dubbo 的spi机制 获取 ZookeeperRegistryFactory 实例 ,
zookeeper=org.apache.dubbo.registry.zookeeper.ZookeeperRegistryFactory
ZookeeperRegistryFactory 实例调用 createRegistry 即可方便获取 ZookeeperRegistry 实例
@Override
public Registry createRegistry(URL url) {
return new ZookeeperRegistry(url, zookeeperTransporter);
}
- 1
- 2
- 3
- 4
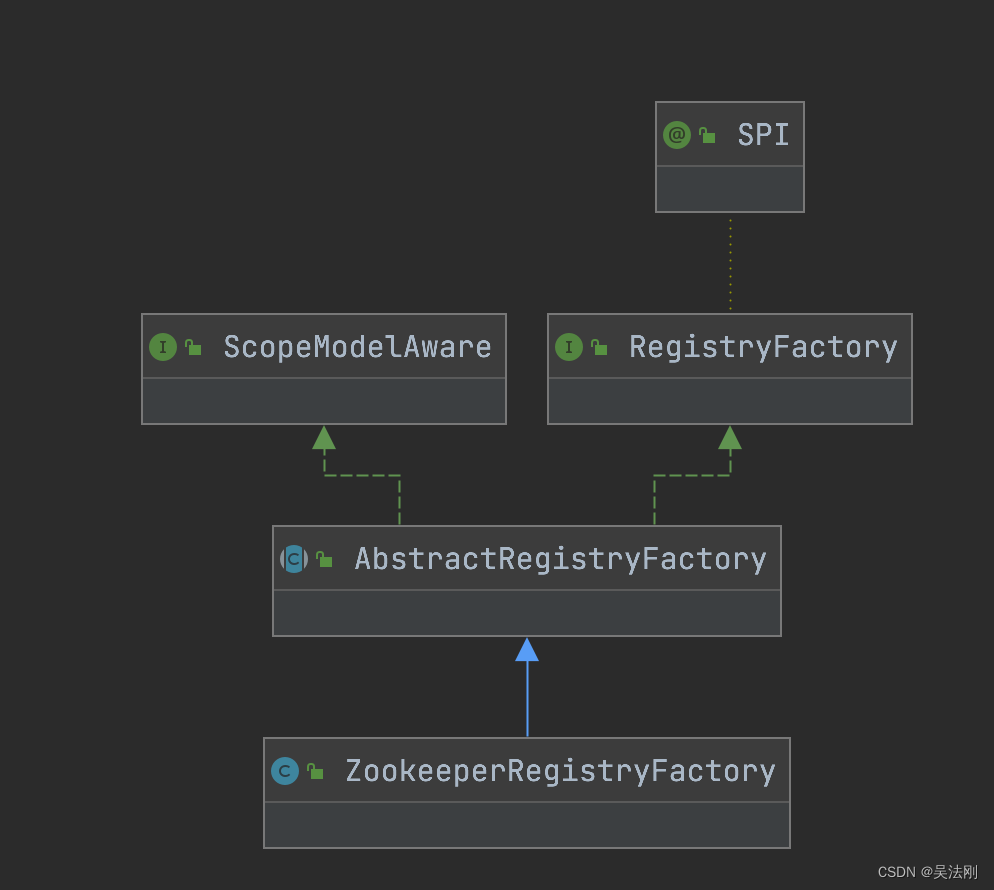
3.4.1.1 RegistryFactory 工厂接口定义
RegistryFactory 接口是 Registry 的工厂接口,负责创建 Registry 对象,具体定义如下所示,其中 @SPI 注解指定了默认的扩展名为 dubbo,@Adaptive 注解表示会生成适配器类并根据 URL 参数中的 protocol 参数值选择相应的实现。
@SPI("dubbo")
public interface RegistryFactory {
@Adaptive({"protocol"})
Registry getRegistry(URL url);
}
- 1
- 2
- 3
- 4
- 5
每个 Registry 实现类都有对应的 RegistryFactory 工厂实现,每个 RegistryFactory 工厂实现只负责创建对应的 Registry 对象。
其中,RegistryFactoryWrapper 是 RegistryFactory 接口的 Wrapper 类,它在底层 RegistryFactory 创建的 Registry 对象外层封装了一个 ListenerRegistryWrapper ,ListenerRegistryWrapper 中维护了一个 RegistryServiceListener 集合,会将 register()、subscribe() 等事件通知到 RegistryServiceListener 监听器。
3.4.1.2 AbstractRegistryFactory 抽象 缓存层
AbstractRegistryFactory 是一个实现了 RegistryFactory 接口的抽象类,提供了规范 URL 的操作以及缓存 Registry 对象的公共能力。其中,缓存 Registry 对象是使用 HashMap<String, Registry> 集合实现的(REGISTRIES 静态字段)。在规范 URL 的实现逻辑中,AbstractRegistryFactory 会将 RegistryService 的类名设置为 URL path 和 interface 参数,同时删除 export 和 refer 参数。
3.4.1.3 ZookeeperRegistryFactory
我们讲解了 RegistryFactory 这个工厂接口以及其子类 AbstractRegistryFactory,AbstractRegistryFactory 仅仅是提供了缓存 Registry 对象的功能,并未真正实现 Registry 的创建,具体的创建逻辑是由子类完成的
ZookeeperRegistryFactory 实现了 AbstractRegistryFactory,其中的 createRegistry() 方法会创建 ZookeeperRegistry 实例,后续将由该 ZookeeperRegistry 实例完成与 Zookeeper 的交互。
另外,ZookeeperRegistryFactory 中还提供了一个 setZookeeperTransporter() 方法,你可以回顾一下之前我们介绍的 Dubbo SPI 机制,会通过 SPI 或 Spring Ioc 的方式完成自动装载。
3.4.1 ZookeeperClient 是zk的操作客户端
从上面我可以知道ZookeeperRegistry 中依赖: ZookeeperClient 和 ZookeeperTransporter
dubbo-remoting-zookeeper 模块中有两个核心接口:ZookeeperTransporter 接口和 ZookeeperClient 接口。
3.4.1.1 ZookeeperTransporter
dubbo-remoting-zookeeper 模块是 dubbo-remoting 模块的子模块,但它并不依赖 dubbo-remoting 中的其他模块,是相对独立的,所以这里我们可以直接介绍该模块。
简单来说,dubbo-remoting-zookeeper 模块是在 Apache Curator 的基础上封装了一套 Zookeeper 客户端,将与 Zookeeper 的交互融合到 Dubbo 的体系之中。
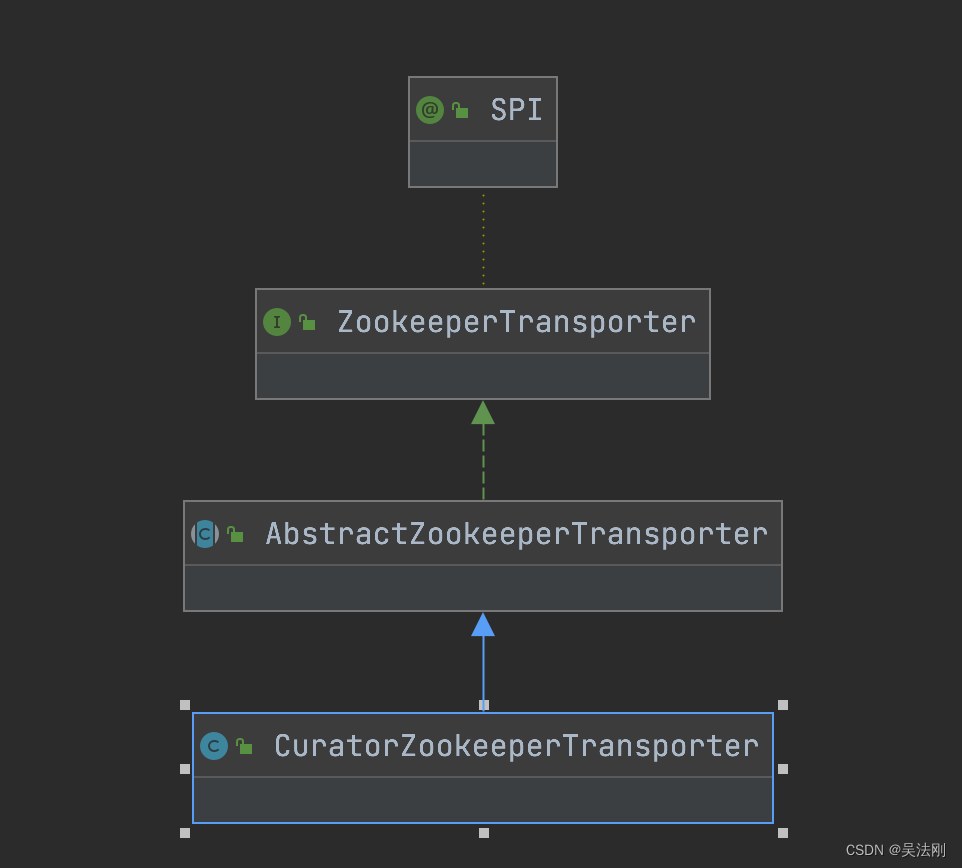
ZookeeperTransporter 只负责一件事情,那就是创建 ZookeeperClient 对象。
@SPI("curator")
public interface ZookeeperTransporter {
@Adaptive({Constants.CLIENT_KEY, Constants.TRANSPORTER_KEY})
ZookeeperClient connect(URL url);
}
- 1
- 2
- 3
- 4
- 5
我们从代码中可以看到,ZookeeperTransporter 接口被 @SPI 注解修饰,成为一个扩展点,默认选择扩展名 “curator” 的实现,其中的 connect() 方法用于创建 ZookeeperClient 实例(该方法被 @Adaptive 注解修饰,我们可以通过 URL 参数中的 client 或 transporter 参数覆盖 @SPI 注解指定的默认扩展名)。
3.4.1.2 AbstractZookeeperTransporter
按照前面对 Registry 分析的思路,作为一个抽象实现,AbstractZookeeperTransporter 肯定是实现了创建 ZookeeperClient 之外的其他一些增强功能,然后由子类继承。不然的话,直接由 CuratorZookeeperTransporter 实现 ZookeeperTransporter 接口创建 ZookeeperClient 实例并返回即可,没必要在继承关系中再增加一层抽象类。
public class CuratorZookeeperTransporter extends
AbstractZookeeperTransporter {
// 创建ZookeeperClient实例
public ZookeeperClient createZookeeperClient(URL url) {
return new CuratorZookeeperClient(url);
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
AbstractZookeeperTransporter 的核心功能有如下:
- 缓存 ZookeeperClient 实例;
- 在某个 Zookeeper 节点无法连接时,切换到备用 Zookeeper 地址。
在配置 Zookeeper 地址的时候,我们可以配置多个 Zookeeper 节点的地址,这样的话,当一个 Zookeeper 节点宕机之后,Dubbo 就可以主动切换到其他 Zookeeper 节点。例如,我们提供了如下的 URL 配置:
zookeeper://127.0.0.1:2181/org.apache.dubbo.registry.RegistryService?backup=127.0.0.1:8989,127.0.0.1:9999
AbstractZookeeperTransporter 的 connect() 方法首先会得到上述 URL 中配置的 127.0.0.1:2181、127.0.0.1:8989 和 127.0.0.1:9999 这三个 Zookeeper 节点地址,然后从 ZookeeperClientMap 缓存(这是一个 Map,Key 为 Zookeeper 节点地址,Value 是相应的 ZookeeperClient 实例)中查找一个可用 ZookeeperClient 实例。如果查找成功,则复用 ZookeeperClient 实例;如果查找失败,则创建一个新的 ZookeeperClient 实例返回并更新 ZookeeperClientMap 缓存。
ZookeeperClient 实例连接到 Zookeeper 集群之后,就可以了解整个 Zookeeper 集群的拓扑,后续再出现 Zookeeper 节点宕机的情况,就是由 Zookeeper 集群本身以及 Apache Curator 共同完成故障转移。
3.4.1.3 ZookeeperClient
从名字就可以看出,ZookeeperClient 接口是 Dubbo 封装的 Zookeeper 客户端,该接口定义了大量的方法,都是用来与 Zookeeper 进行交互的。
- create() 方法:创建 ZNode 节点,还提供了创建临时 ZNode 节点的重载方法。
- getChildren() 方法:获取指定节点的子节点集合。
- getContent() 方法:获取某个节点存储的内容。
- delete() 方法:删除节点。
- add_Listener() / remove_Listener() 方法:添加/删除监听器。
- close() 方法:关闭当前 ZookeeperClient 实例。
AbstractZookeeperClient 作为 ZookeeperClient 接口的抽象实现,主要提供了如下几项能力:
- 缓存当前 ZookeeperClient 实例创建的持久 ZNode 节点;
- 管理当前 ZookeeperClient 实例添加的各类监听器;
- 管理当前 ZookeeperClient 的运行状态。
我们来看 AbstractZookeeperClient 的核心字段,首先是 persistentExistNodePath(ConcurrentHashSet类型)字段,它缓存了当前 ZookeeperClient 创建的持久 ZNode 节点路径,在创建 ZNode 节点之前,会先查这个缓存,而不是与 Zookeeper 交互来判断持久 ZNode 节点是否存在,这就减少了一次与 Zookeeper 的交互。
dubbo-remoting-zookeeper 对外提供了 StateListener、DataListener 和 ChildListener 三种类型的监听器。
-
StateListener:主要负责监听 Dubbo 与 Zookeeper 集群的连接状态,包括 SESSION_LOST、CONNECTED、RECONNECTED、SUSPENDED 和 NEW_SESSION_CREATED。
-
DataListener:主要监听某个节点存储的数据变化。
-
ChildListener:**主要监听某个 ZNode 节点下的子节点变化。
在 AbstractZookeeperClient 中维护了 stateListeners、listeners 以及 childListeners 三个集合,分别管理上述三种类型的监听器。虽然监听内容不同,但是它们的管理方式是类似的,所以这里我们只分析 listeners 集合的操作:
public void addDataListener(String path,
DataListener listener, Executor executor) {
// 获取指定path上的DataListener集合
ConcurrentMap<DataListener, TargetDataListener> dataListenerMap =
listeners.computeIfAbsent(path, k -> new ConcurrentHashMap<>());
// 查询该DataListener关联的TargetDataListener
TargetDataListener targetListener =
dataListenerMap.computeIfAbsent(listener,
k -> createTargetDataListener(path, k));
// 通过TargetDataListener在指定的path上添加监听
addTargetDataListener(path, targetListener, executor);
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
这里的 createTargetDataListener() 方法和 addTargetDataListener() 方法都是抽象方法,由 AbstractZookeeperClient 的子类实现,TargetDataListener 是 AbstractZookeeperClient 中标记的一个泛型。
为什么 AbstractZookeeperClient 要使用泛型定义?这是因为不同的 ZookeeperClient 实现可能依赖不同的 Zookeeper 客户端组件,不同 Zookeeper 客户端组件的监听器实现也有所不同,而整个 dubbo-remoting-zookeeper 模块对外暴露的监听器是统一的,就是上面介绍的那三种。因此,这时就需要一层转换进行解耦,这层解耦就是通过 TargetDataListener 完成的。
在最新的 Dubbo 版本中,CuratorZookeeperClient 是 AbstractZookeeperClient 的唯一实现类,在其构造方法中会初始化 Curator 客户端并阻塞等待连接成功:
public CuratorZookeeperClient(URL url) {
super(url);
int timeout = url.getParameter("timeout", 5000);
int sessionExpireMs = url.getParameter("zk.session.expire",
60000);
CuratorFrameworkFactory.Builder builder =
CuratorFrameworkFactory.builder()
.connectString(url.getBackupAddress())//zk地址(包括备用地址)
.retryPolicy(new RetryNTimes(1, 1000)) // 重试配置
.connectionTimeoutMs(timeout) // 连接超时时长
.sessionTimeoutMs(sessionExpireMs); // session过期时间
... // 省略处理身份验证的逻辑
client = builder.build();
// 添加连接状态的监听
client.getConnectionStateListenable().addListener(
new CuratorConnectionStateListener(url));
client.start();
boolean connected = client.blockUntilConnected(timeout,
TimeUnit.MILLISECONDS);
... // 检测connected这个返回值,连接失败抛出异常
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
CuratorZookeeperClient 与 Zookeeper 交互的全部操作,都是围绕着这个 Apache Curator 客户端展开的, Apache Curator 的具体使用方式在前面的第 6 和 7 课时已经介绍过了,这里就不再赘述。
内部类 CuratorWatcherImpl 就是 CuratorZookeeperClient 实现 AbstractZookeeperClient 时指定的泛型类,它实现了 TreeCacheListener 接口,可以添加到 TreeCache 上监听自身节点以及子节点的变化。在 childEvent() 方法的实现中我们可以看到,当 TreeCache 关注的树型结构发生变化时,会将触发事件的路径、节点内容以及事件类型传递给关联的 DataListener 实例进行回调:
public void childEvent(CuratorFramework client, TreeCacheEvent event) throws Exception {
if (dataListener != null) {
TreeCacheEvent.Type type = event.getType();
EventType eventType = null;
String content = null;
String path = null;
switch (type) {
case NODE_ADDED:
eventType = EventType.NodeCreated;
path = event.getData().getPath();
content = event.getData().getData() == null ? "" : new String(event.getData().getData(), CHARSET);
break;
case NODE_UPDATED:
...
case NODE_REMOVED:
...
// 省略其他时间的处理
}
// 回调DataListener,传递触发事件的path、节点内容以及事件类型
dataListener.dataChanged(path, content, eventType);
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
在 CuratorZookeeperClient 的 addTargetDataListener() 方法实现中,我们可以看到 TreeCache 的创建、启动逻辑以及添加 CuratorWatcherImpl 监听的逻辑:
protected void addTargetDataListener(String path, CuratorZookeeperClient.CuratorWatcherImpl treeCacheListener, Executor executor) {
// 创建TreeCache
TreeCache treeCache = TreeCache.newBuilder(client, path).setCacheData(false).build();
treeCacheMap.putIfAbsent(path, treeCache); // 缓存TreeCache
if (executor == null) { // 添加监听
treeCache.getListenable().addListener(treeCacheListener);
} else {
treeCache.getListenable().addListener(treeCacheListener, executor);
}
treeCache.start(); // 启动
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
如果需要在回调中获取全部 Child 节点,那么 dubbo-remoting-zookeeper 调用方需要使用 ChildListener(在下面即将介绍的 ZookeeperRegistry 中可以看到 ChildListener 相关使用方式)。CuratorWatcherImpl 也是 ChildListener 与 CuratorWatcher 的桥梁,具体实现方式与上述逻辑类似,这里不再展开。
到此为止,dubbo-remoting-zookeeper 模块的核心实现就介绍完了,该模块作为 Dubbo 与 Zookeeper 交互的基础,不仅支撑了基于 Zookeeper 的注册中心的实现,还支撑了基于 Zookeeper 的服务发现的实现。这里我们重点关注基于 Zookeeper 的注册中心实现。

