
- 1数据科学中心——首席数据科学家_腾讯 数据科学中心
- 2【毕业设计选题】 大数据方向 选题建议
- 3adb命令行窗口不能输入中文或者不显示中文文件(夹)_adb pull 不支持中文路径
- 4深入探讨Python海象运算符
- 5记录——TortoiseGit合并分支操作_tortoisegit 合并分支
- 6maven配置:基于docker‐maven‐plugin构建、推送docker镜像(mvn docker:build ‐DpushImage)_maven docker plugin
- 7HC05与STM32进行串口通讯实现与手机APP的数据透传_stm32蓝牙hc05发送数据给app
- 8【小黑送书—第九期】>>重磅!这本30w人都在看的Python数据分析畅销书:更新了!
- 927.Linux网络编程 掌握三次握手建立连接过程掌握四次握手关闭连接的过程掌握滑动窗口的概念掌握错误处理函数封装实现多进程并发服务器实现多线程并发服务器_获取与 mail.hist.edu.cn 建立连接的三次握手情况。
- 10Mac上如何安装Mysql5以及可视化工具navicat_可视化工具navicatmac 版
DeepSeek Coder V2重大升级:AI先行者技术深度融合_deepseek v2 部署最少几张卡
赞
踩
全新最强模型已上线!!

去年,最强开源代码模型 DeepSeek-Coder 亮相,大力推动开源代码模型发展。
今年,最强开源 MoE 模型 DeepSeek-V2 发布,悄然引领模型结构创新潮流。
今天,全球首个在代码、数学能力上与GPT-4-Turbo争锋的模型,DeepSeek-Coder-V2,正式上线和开源。
全球顶尖的代码、数学能力
DeepSeek-Coder-V2 沿用 DeepSeek-V2 的模型结构,总参数 236B,激活 21B,在代码、数学的多个榜单上位居全球第二,介于最强闭源模型 GPT-4o 和 GPT-4-Turbo 之间。

国内第一梯队的通用能力
在拥有世界前列的代码、数学能力的同时,DeepSeek-Coder-V2 还具有良好的通用性能,在中英通用能力上位列国内第一梯队。
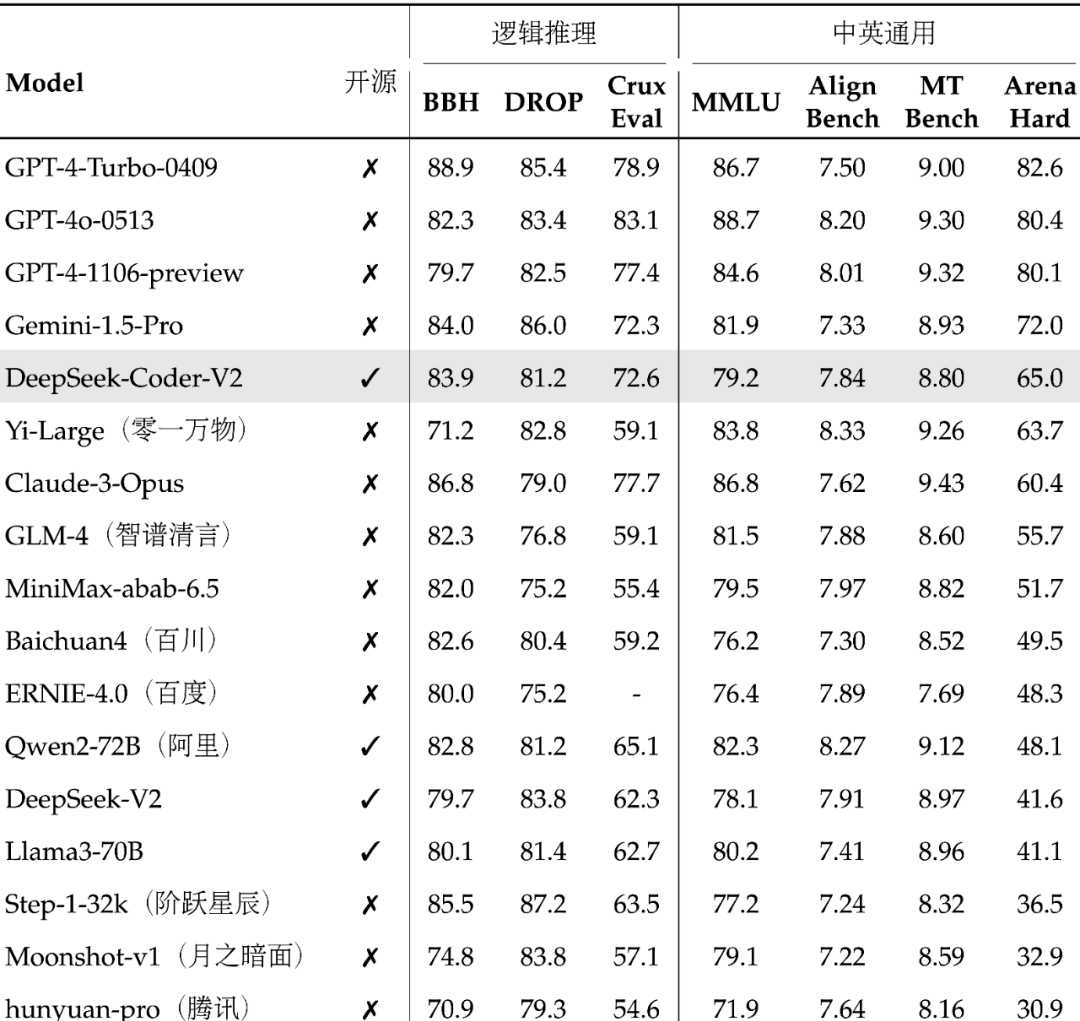
DeepSeek-Coder-V2 和
DeepSeek-V2 的差异
虽然 DeepSeek-Coder-V2 在评测中综合得分更高,但在实际应用中,两个模型各有所长。DeepSeek-V2 是文科生,DeepSeek-Coder-V2 是理科生,精通的技能点不同:

全面开源,两种规模
一如既往,DeepSeek-Coder-V2 模型、代码、论文均开源,免费商用,无需申请。
无需下载,网络搜索“aicbo”就能免费试用
开源模型包含236B和16B两种参数规模
DeepSeek-Coder-V2:总参 236B(即官网和 API 版模型),单机 8*80G 可部署,单机 8*80G 可微调https://github.com/deepseek-ai/DeepSeek-Coder-V2/blob/main/paper.pdf(需要技巧)
DeepSeek-Coder-V2-Lite:总参 16B,激活 2.4B,支持 FIM,代码能力接近 DeepSeek-Coder-33B(V1),单卡 40G 可部署,单机 8*80G 可训练。

API服务
DeepSeek-Coder-V2 API 支持 32K 上下文,价格和 DeepSeek-V2 一致,还是大家熟悉的低价:

本地私有化部署
DeepSeek 提供本地私有化部署服务,标准化成品交付,开箱即用,轻松升级。
价格 199元/套/年,支持灵活的商务方案(登录官网,联系客服)。
价格包含:
一台推理训练一体化的高性能服务器(Nvidia H20、Huawei 910B 或其它同级别显卡,8 显卡互联)。
模型:DeepSeek-V2-236B、Coder-V2-236B、后续其它模型。
一站式软件套件:推理、微调、运维等。
对每个客户,DeepSeek 均会针对应用场景,使用公开数据、脱敏数据进行训练和调优。客户可以使用私有数据进一步微调。
不低于 5 人日/年的技术支持。
预期性能:
输入:20000 tokens/s
输出:5000~10000 tokens/s
官网已上线 DeepSeek-Coder-V2
访问对话官网:Aicbo,与 DeepSeek-Coder-V2 永久免费畅聊。

DeepSeek 当下与未来
上月 DeepSeek-V2 发布后,深度求索以其卓越的性价比赢得赞誉。但我们的终极目标,始终是打造性能最强大的模型,Coder-V2 的推出,正是向这一愿景迈进的关键一步。我们相信,只有强大的模型能力、普惠的技术应用,才能开启人工智能发展的新篇章
敬请期待,下次发布,未来已来!

