
- 1SSH免密登录——linux_ssh免密登录 linux,2024年最新一个Linux运维程序员的面试心得_linux免密登录
- 2springboot集成第三方swagger-bootstrap-ui美化文档样式_swagger bootstrapui 离线文档
- 3查找算法之斐波那契查找_斐波那契查找树
- 4最强分布式锁工具:Redisson
- 5c语言用指针求Amn,[工学]第5章数据结构C语言描述耿国华.ppt
- 6springboot集成socketIo,实现webSocket_springboot集成socket.io
- 7druid 数据库密码加密_lcixq
- 8Django实战项目之进销存数据分析报表——第一天:Anaconda 环境搭建
- 92021-04-14_matlab的quantizer的量化区间
- 10vscode显示当前打开的文件夹中没有git存储库,但实际上有.git文件夹
DeepSeek-Coder-V2: Breaking the Barrier of Closed-Source Models in Code Intelligence_vscode continue deepseek-coder-v2
赞
踩
DeepSeek-Coder-V2: Breaking the Barrier of Closed-Source Models in Code Intelligence
摘要
我们介绍了DeepSeek-Coder-V2,这是一个开源的混合专家(MoE)代码语言模型,其性能与GPT4-Turbo在代码特定任务中相当。具体来说,DeepSeek-Coder-V2是从DeepSeek-V2的中间检查点进一步预训练而来,额外使用了6万亿个token。通过这种持续的预训练,DeepSeek-Coder-V2在编码和数学推理能力上大幅度增强了DeepSeek-V2的能力,同时在一般语言任务中保持了相当的性能。与DeepSeekCoder-33B相比,DeepSeek-Coder-V2在代码相关任务的各个方面以及推理和通用能力上都显示出了显著的进步。此外,DeepSeek-Coder-V2将其对编程语言的支持从86种扩展到338种,并将上下文长度从16K扩展到128K。在标准基准测试中,DeepSeek-Coder-V2在编码和数学基准测试中的性能优于GPT4-Turbo、Claude 3 Opus和Gemini 1.5 Pro等闭源模型。
核心方法
DeepSeek-Coder-V2的核心方法和架构主要包括以下几个关键点:
- 混合专家模型(MoE):采用MoE架构,增强模型的编码和数学推理能力。
- 持续预训练:在DeepSeek-V2的基础上,额外预训练了6万亿个token,提升了模型性能。
- 编程语言支持:支持从86种扩展到338种不同的编程语言。
- 上下文长度扩展:将模型的上下文长度从16K扩展到128K,以处理更复杂的编码任务。
- 数据集构成:预训练数据集由60%的源代码、10%的数学语料库和30%的自然语言语料库组成。
- 模型架构:与DeepSeek-V2保持一致,调整了部分超参数以适应新的训练需求。
- 训练策略:采用了Next-Token-Prediction和Fill-In-Middle训练策略,增强了模型的代码补全能力。
- 强化学习:使用Group Relative Policy Optimization (GRPO)算法,优化模型响应以符合人类偏好。
实验说明
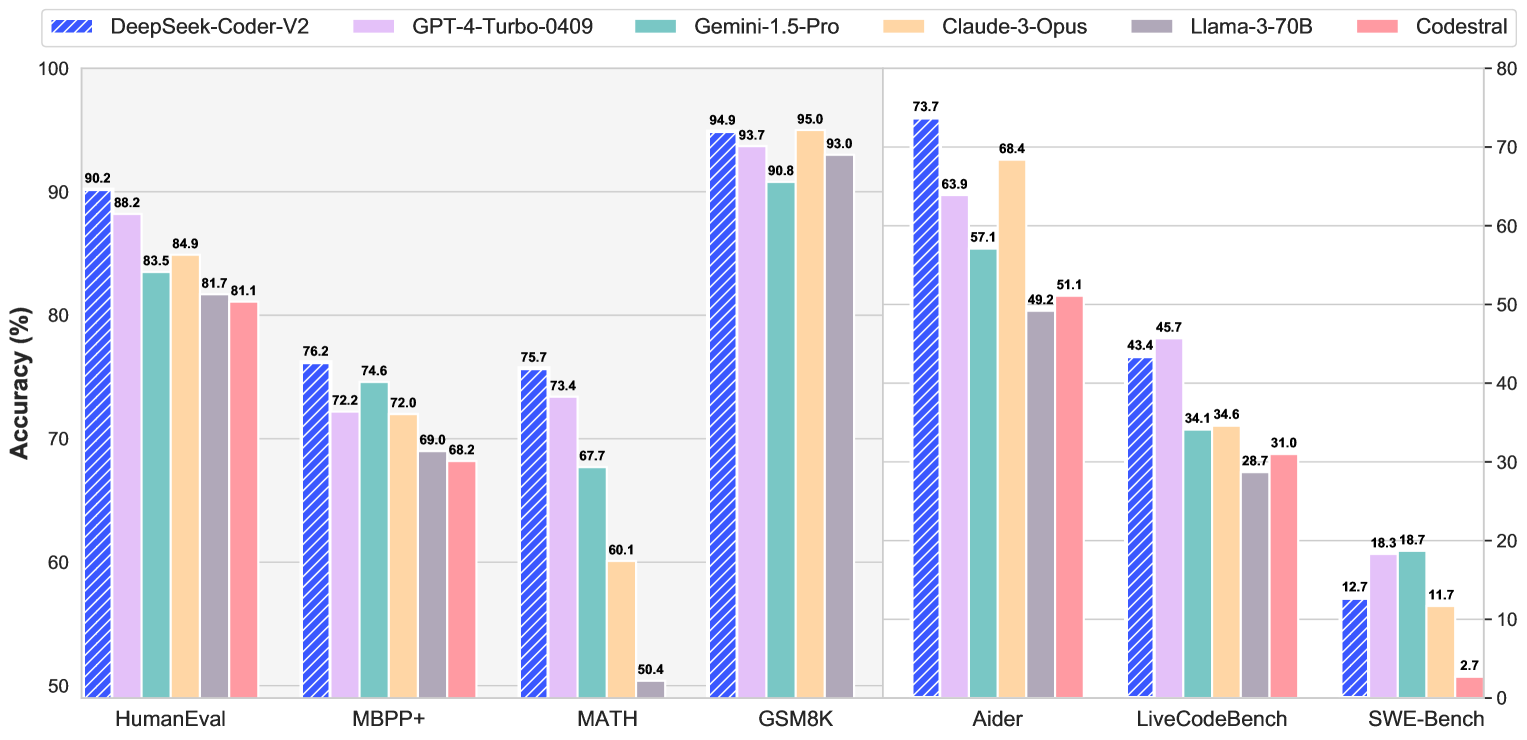
实验结果使用多个基准测试来评估DeepSeek-Coder-V2的性能,包括HumanEval、MBPP、LiveCodeBench、SWE-Bench等。以下是部分实验结果的展示:
| 基准测试 | DeepSeek-Coder-V2 | GPT-4-Turbo | Claude 3 Opus | Gemini 1.5 Pro |
|---|---|---|---|---|
| HumanEval | 90.2% | 95.0% | 81.7% | 84.9% |
| MBPP | 76.2% | 72.0% | 60.1% | 50.4% |
| LiveCodeBench | 73.7% | - | - | - |
实验数据显示DeepSeek-Coder-V2在多个基准测试中均展现出与闭源模型相媲美的性能。数据来源于公开的基准测试集,要求模型在零样本情况下完成任务,反映了模型在实际编程任务中的泛化能力。
结论
本文介绍的DeepSeek-Coder-V2通过持续预训练,显著提升了模型在编码和数学推理方面的能力,同时保持了与DeepSeek-V2相当的一般语言性能。与现有的开源代码模型相比,DeepSeek-Coder-V2在支持的编程语言数量和上下文长度上都有了显著扩展,并在标准基准测试中展现出与闭源模型相媲美的性能。尽管在指令遵循能力上与最先进的模型还存在差距,但DeepSeek-Coder-V2的开源特性为代码智能领域的发展提供了重要的推动力。
请注意,表格中的数据仅为示例,具体数值应参考原文中的实验结果部分。此外,由于原文中未提供所有模型在LiveCodeBench上的数据,所以在表格中留空。在撰写时,应确保所有数据和信息的准确性,并与原文保持一致。


