
- 1BrokenPipeError::[Errno 32] Broken pipe_brokenpipeerror: [errno 32] broken pipe
- 2【数学建模之Python】1.凸优化库cvxpy的安装(2021/7/15安装成功)_cvxopt cvxpy比较
- 3element UI :el-table横向列内容超出宽度,滚动条不显示问题
- 4思科模拟器配置实训(Switch、Router配置实训)
- 5(转)机器视觉会议以及牛人_机器视觉 帖子
- 6跟着我学习 AI丨初识 AI_什么是ai技术
- 7飞腾架构麒麟V10安装达梦数据库客户端_麒麟v10 达梦安装包
- 8SpringBoot-MySql-MyBatis配置多数据源 读写分离_多数据源 validationquery
- 9node-环境安装(二)_服务环境dwp
- 10Java后端发送微信小程序模板订阅消息_微信小程序发送订阅消息使用java
无限可能LangChain——构建代理_langgraph checkpointer
赞
踩
单独来看,语言模型无法采取行动 - 它们只能输出文本。LangChain的一个重要用例是创建代理。代理是使用LLM作为推理引擎的系统,用于确定要采取的行动以及这些行动的输入应该是什么。然后,这些行动的结果可以反馈给代理,并确定是否需要更多的行动,或者是否可以结束。
在本教程中,我们将构建一个可以与多个不同工具进行交互的代理:一个是本地数据库,另一个是搜索引擎。您将能够向该代理提问,观察它调用工具,并与它进行对话。
概念
我们将涵盖的概念是:
- 使用语言模型,特别是它们的工具调用能力
- 创建Retriever以向我们的代理公开特定信息
- 使用搜索工具在线查找内容
- 使用LangGraph代理,它使用LLM来思考要做什么,然后执行它
- 使用LangSmith 调试和跟踪您的应用程序
安装
参考前面文档:
《无限可能LangChain——开启大模型世界》 《无限可能LangChain——构建一个简单的LLM应用程序》
tavily
集成存在于 langchain-community 包中。我们还需要安装 tavily-python 包本身。
pip install -U langchain-community tavily-python langgraph定义工具
我们首先需要创建我们想要使用的工具。我们将使用两个工具: Tavily(在线搜索),然后是我们将创建的本地索引上的检索器。
Tavily
我们在LangChain中有一个内置工具,可以轻松地使用Tavily搜索引擎作为工具。请注意,这需要一个API密钥。但是如果你没有或者不想创建一个,你可以忽略这一步。
Tavily :https://tavily.com/。创建API密钥后,您需要将其导出为: 
export TAVILY_API_KEY="..."from langchain_community.tools.tavily_search import TavilySearchResults
search = TavilySearchResults(max_results=1)
result = search.invoke("今天重庆的天气预报")
print(result)- 1
- 2
- 3
- 4
- 5
API Reference:TavilySearchResults
Retriever
我们还将在我们自己的一些数据上创建一个检索器。有关此处每个步骤的更深入解释,请参阅 教程。
安装依赖:
pip install faiss-cpufrom langchain_community.document_loaders import WebBaseLoader
from langchain_community.vectorstores import FAISS
from langchain_community.embeddings import DashScopeEmbeddings
from langchain_text_splitters import RecursiveCharacterTextSplitter
loader = WebBaseLoader("https://help.aliyun.com/zh/dashscope/product-overview/concepts-and-glossary?spm=a2c4g.11186623.0.0.63955491NXmvJ5")
docs = loader.load()
documents = RecursiveCharacterTextSplitter(
chunk_size=1000, chunk_overlap=200
).split_documents(docs)
vector = FAISS.from_documents(documents, DashScopeEmbeddings())
retriever = vector.as_retriever()
result = retriever.invoke("灵积模型是什么?")
print(result)- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
API Reference:WebBaseLoader | FAISS | OpenAIEmbeddings | RecursiveCharacterTextSplitter
现在我们已经填充了我们将进行检索的索引,我们可以很容易地将其转换为工具(代理正确使用它所需的格式)
from langchain.tools.retriever import create_retriever_tool
retriever_tool = create_retriever_tool(
retriever,
"搜索灵积模型",
"搜索灵积模型的信息,你可以使用这个工具!",
)- 1
- 2
- 3
- 4
- 5
- 6
API Reference:create_retriever_tool
工具列表
现在我们已经创建了两者,我们可以创建一个我们将在下游使用的工具列表。
# 创建工具列表
toolList = [search, retriever_tool]- 1
使用语言模型
接下来,让我们通过调用工具来学习如何使用语言模型。LangChain 支持许多不同的语言模型,您可以互换使用-在下面选择您要使用的语言模型!
LangChain 支持内置的 Tavily 工具、支持 DashScopeEmbeddings 工具、支持自定义函数工具。
from langchain_community.tools.tavily_search import TavilySearchResults search = TavilySearchResults(max_results=1) from langchain_community.document_loaders import WebBaseLoader from langchain_community.vectorstores import FAISS from langchain_community.embeddings import DashScopeEmbeddings from langchain_text_splitters import RecursiveCharacterTextSplitter loader = WebBaseLoader("https://help.aliyun.com/zh/dashscope/product-overview/concepts-and-glossary?spm=a2c4g.11186623.0.0.63955491NXmvJ5") docs = loader.load() documents = RecursiveCharacterTextSplitter( chunk_size=1000, chunk_overlap=200 ).split_documents(docs) vector = FAISS.from_documents(documents, DashScopeEmbeddings()) retriever = vector.as_retriever() from langchain.tools.retriever import create_retriever_tool retriever_tool = create_retriever_tool( retriever, "search_dashscope_knowledge", "当需要搜索灵积模型相关知识的时候必须使用该工具", ) from langchain_core.tools import tool @tool def multiply(first_int: int, second_int: int) -> int: """两个数的乘积.""" return first_int * second_int # 创建工具列表 toolList = [search, retriever_tool, multiply] from langchain_community.chat_models.tongyi import ChatTongyi llm = ChatTongyi(model="qwen-max") llm_with_tools = llm.bind_tools([search, retriever_tool, multiply]) # 未使用工具 msg = llm.invoke("你好") print(msg) # 建议使用工具:search_dashscope_knowledge msg = llm_with_tools.invoke("灵积模型是什么") print(msg) # 建议使用工具:multiply msg = llm_with_tools.invoke("计算 10 的 5 倍") print(msg)

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48

LangSmith 日志记录: human: 你好 搜索通义千问模型 自定义工具

这还没有调用那个工具——大模型只是告诉我们建议使用哪个工具。为了真正调用它,下面我们需要创建我们的代理。
创建代理
我们现在可以在几个查询上运行代理!请注意,目前,这些都是 无状态查询(也就是它不会记住以前的交互)。 请注意,代理将返回最终交互结束时的状态(包括任何输入,我们稍后将看到如何仅获取输出)。
首先,让我们看看当不需要调用工具时它是如何响应的:
# 创建一个代理
agent_executor = create_react_agent(llm, toolList)- 1
msg = agent_executor.invoke(
{"messages": [HumanMessage(content="你好")]}
)
print(msg)
- 1
- 2
- 3
- 4
{'messages': [HumanMessage(content='你好', id='3ef97e5e-e34d-4ca9-81e3-fddee5ecb1a7'), AIMessage(content='你好!有什么可以帮助你的吗?', response_metadata={'model_name': 'qwen-max', 'finish_reason': 'stop', 'request_id': '5ac46b01-4af0-9c07-bb72-0871767e00a5', 'token_usage': {'input_tokens': 376, 'output_tokens': 7, 'total_tokens': 383}}, id='run-1e3c757e-7b6d-44d2-9979-c38be2a9d7da-0')]}
为了准确地看到到底发生了什么(并确保它没有调用工具),我们可以看看 LangSmith 跟踪
现在让我们在一个应该调用检索器的示例上尝试一下
# 建议使用工具:search_dashscope_knowledge
msg = agent_executor.invoke(
{"messages": [HumanMessage(content="灵积模型是什么")]}
)
print(msg)- 1
- 2
- 3
- 4
{'messages': [HumanMessage(content='灵积模型是什么', id='af2612cf-5c10-4c1a-a4ef-b2835e4c135b'), AIMessage(content='', additional_kwargs={'tool_calls': [{'function': {'name': 'search_dashscope_knowledge', 'arguments': '{"query": "灵积模型"}'}, 'id': '', 'type': 'function'}]}, response_metadata={'model_name': 'qwen-max', 'finish_reason': 'tool_calls', 'request_id': '91288216-0c80-9f2e-9e41-b5644cd1adf3', 'token_usage': {'input_tokens': 379, 'output_tokens': 22, 'total_tokens': 401}}, id='run-7430443e-0e55-4a01-87de-47ebda298634-0', tool_calls=[{'name': 'search_dashscope_knowledge', 'args': {'query': '灵积模型'}, 'id': ''}]), ToolMessage(content='什么是DashScope灵积模型服务_模型服务灵积(DashScope)-阿里云帮助中心\n\n\n\n\n\n\n\n\n\n\n\n\n产品解决方案文档与社区权益中心定价云市场合作伙伴支持与服务了解阿里云备案控制台\n文档产品文档输入文档关键字查找\n模型服务灵积\n\n\n\n\n产品概述\n\n\n\n\n\n快速入门\n\n\n\n\n\n操作指南\n\n\n\n\n\n开发参考\n\n\n\n\n\n实践教程\n\n\n\n\n\n服务支持\n\n\n\n首页\n\n\n\n模型服务灵积\n\n\n\n产品概述\n\n反馈上一篇:产品简介下一篇:产品计费 \n文档推荐\n\nDashScope灵积模型服务通过标准化的API提供“模型即服务”(Model-as-a-Service,MaaS)。不同于以往以任务为中心的AI API,DashScope构建在面向未来的、以模型为中心的理念下,因此也引入了一些新的概念和术语。开发者可以通过本文了解DashScope灵积模型服务的有关概念和术语,从而更好的使用DashScope进行AI应用开发。模型和模型服务“模型即服务”是DashScope灵积模型服务的本质:让各种模型的能力触手可得。DashScope将各类AI模型通过标准化的封装形成API服务,以方便应用开发者调用。通过DashScope,丰富多样化的模型不仅能通过推理API被集成,也能通过训练微调API实现模型定制化。DashScope为AI模型提供云原生的Serverless服务,使得开发者无需关注模型服务API背后的服务器管理,也可直接获得稳定可靠的服务。此外DashScope也为有需求的用户提供特定模型的独占服务。在DashScope灵积模型服务中,每个模型都拥有其唯一的模型名称字符串。例如,qwen-turbo\xa0代表的是通义千问大模型、paraformer-v1\xa0代表的是Paraformer语音识别模型等等。模型名称字符串是模型的代号,用于在DashScope API中以指定被调用的模型,通过model=‘模型名称字符串’\xa0给出。API-KEYDashScope灵积模型服务使用API-KEY作为调用API的密钥。API-KEY承担了调用鉴权、计量计费等功能。API-KEY被广泛应用于DashScope API中,通过 api-key\n\nAPI详情\n\n\n安装DashScope SDK\n\n\n快速开始\n\n\n快速开始\n\n\n计量计费\n\n\n模型介绍\n\n\n计量计费规则\n\n\n模型体验中心\n\n\n\n本页导读 (0)\n为什么选择阿里云什么是云计算全球基础设施技术先进稳定可靠安全合规分析师报告产品和定价全部产品免费试用产品动态产品定价价格计算器云上成本管理解决方案技术解决方案文档与社区文档开发者社区天池大赛培训与认证权益中心免费试用高校计划企业扶持计划推荐返现计划支持与服务基础服务企业增值服务迁云服务官网公告健康看板信任中心关注阿里云关注阿里云公众号或下载阿里云APP,关注云资讯,随时随地运维管控云服务联系我们:4008013260法律声明Cookies政策廉正举报安全举报联系我们加入我们友情链接阿里巴巴集团淘宝网天猫全球速卖通阿里巴巴国际交易市场1688阿里妈妈飞猪阿里云计算AliOS万网高德UC友盟优酷钉钉支付宝达摩院淘宝海外阿里云盘饿了么© 2009-2024 Aliyun.com 版权所有 增值电信业务经营许可证: 浙B2-20080101 域名注册服务机构许可: 浙D3-20210002 京D3-20220015浙公网安备 33010602009975号浙B2-20080101-4', name='search_dashscope_knowledge', id='fd5f24e8-7316-44c8-bb53-bcc9ae9c68a3', tool_call_id=''), AIMessage(content='DashScope灵积模型服务是阿里云提供的一种“模型即服务”(Model-as-a-Service,MaaS)解决方案。它允许开发者通过标准化API访问多种AI模型,不仅提供了模型的推理API,还支持模型的训练和微调,以便进行定制化服务。不同于传统以任务为中心的AI API,DashScope更侧重于模型本身,使模型能力更易于获取和集成。\n\n每个模型在DashScope中都有一个唯一的模型名称字符串,作为其标识符,用于在API调用中指定所要使用的模型。例如,`qwen-turbo`代表通义千问大模型,`paraformer-v1`代表Paraformer语音识别模型等。\n\n服务的特点包括:\n- **云原生Serverless**:用户无需管理服务器,即可获得稳定、可靠的服务。\n- **API-KEY鉴权与计费**:通过API-KEY进行调用鉴权和计量计费,简化了开发者在集成AI功能时的权限管理和成本控制流程。\n- **模型多样化**:提供丰富的预训练模型,覆盖多种应用场景,如语言处理、图像识别、语音识别等。\n- **可定制化**:用户可根据特定需求对模型进行微调,以更好地适应个性化场景。\n\n总之,DashScope灵积模型服务旨在降低AI应用的开发门槛,加速AI技术的应用落地,让企业和开发者能够更加便捷地利用先进的AI模型来提升产品和服务的智能化水平。', response_metadata={'model_name': 'qwen-max', 'finish_reason': 'stop', 'request_id': 'e0b22a7d-91a3-9a10-b0d5-0d2dba07fe2b', 'token_usage': {'input_tokens': 1176, 'output_tokens': 305, 'total_tokens': 1481}}, id='run-52a6b054-4460-494c-8cca-2c6a3e3a6041-0')]}
让我们来看看 LangSmith跟踪 看看发生了什么。 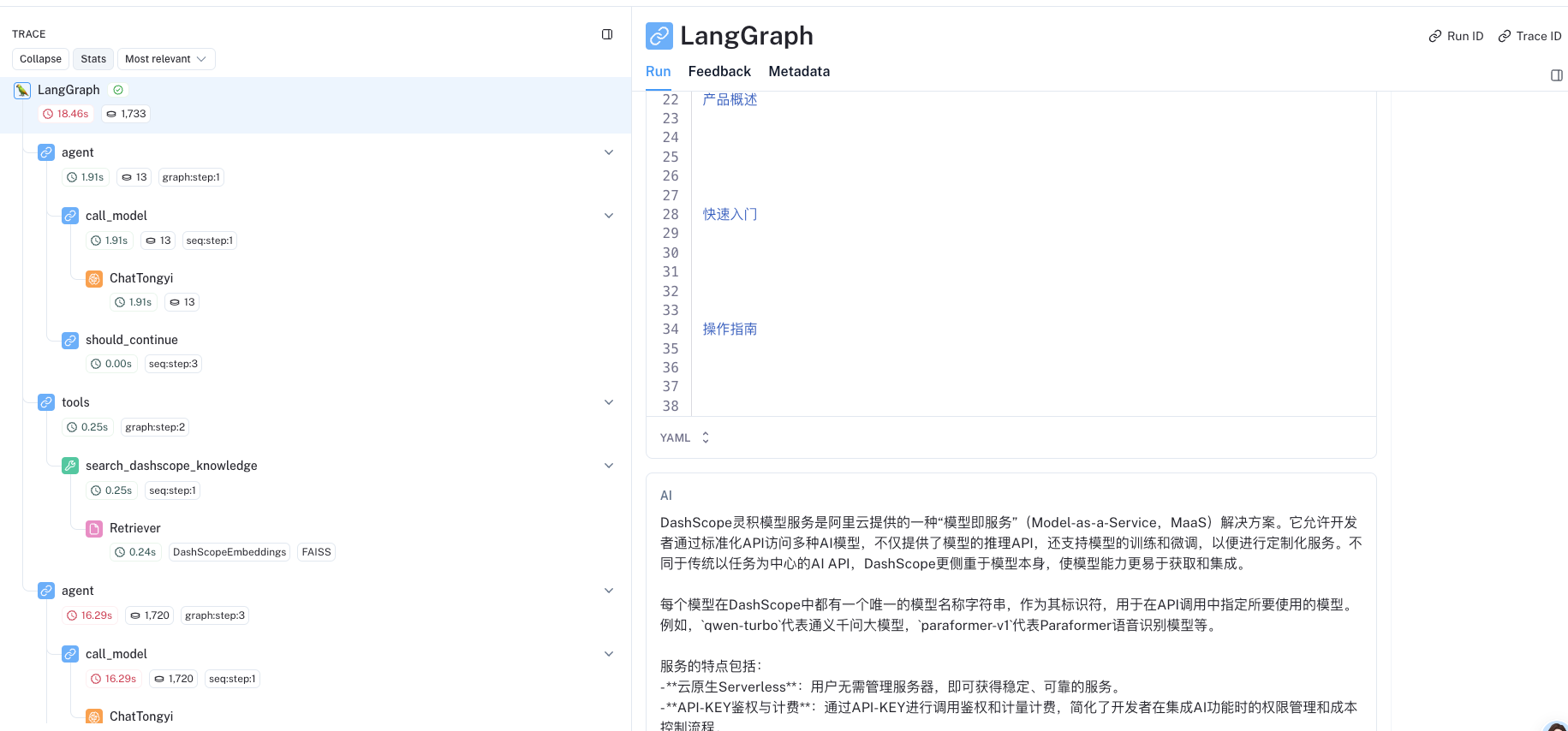
现在让我们尝试一个需要调用自定义工具的示例:
# 建议使用工具:multiply
msg = llm_with_tools.invoke("计算 10 的 5 倍等于的结果")
print(msg)- 1
- 2
content='' additional_kwargs={'tool_calls': [{'function': {'name': 'multiply', 'arguments': '{"first_int": 10, "second_int": 5}'}, 'id': '', 'type': 'function'}]} response_metadata={'model_name': 'qwen-max', 'finish_reason': 'tool_calls', 'request_id': '7896135e-75e2-93e3-af68-2edb0af85023', 'token_usage': {'input_tokens': 387, 'output_tokens': 25, 'total_tokens': 412}} id='run-987b56a8-5a09-4d68-a217-9bf8459350da-0' tool_calls=[{'name': 'multiply', 'args': {'first_int': 10, 'second_int': 5}, 'id': ''}]我们可以去看看 LangSmith跟踪 以确保它有效地调用搜索工具。 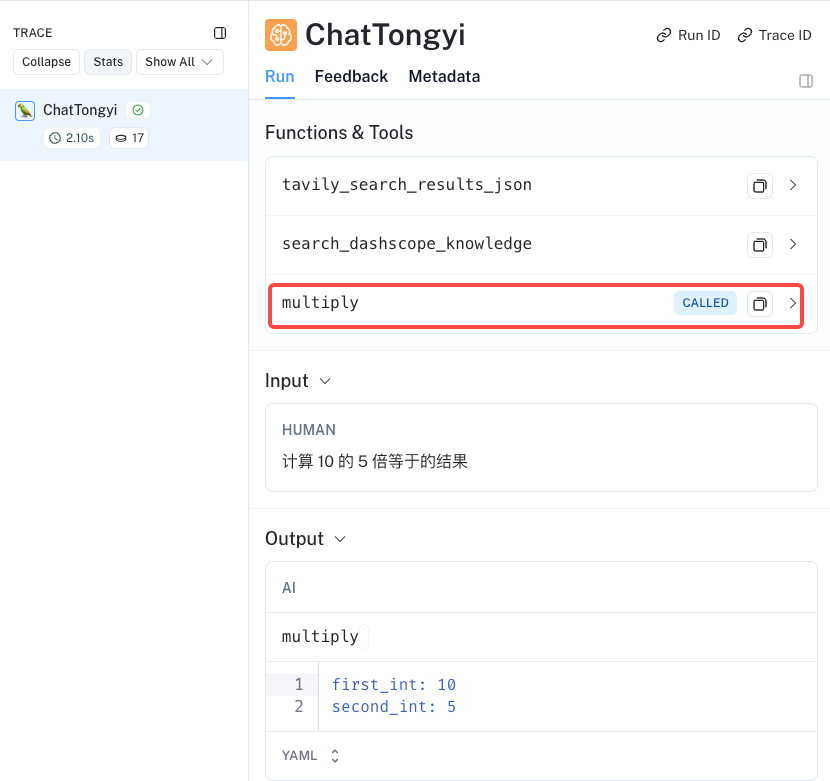
流式消息
我们已经看到了如何使用.invoke调用代理以获取最终响应。如果代理正在执行多个步骤,这可能需要一段时间。为了显示中间进度,我们可以在消息发生时流回消息。
for chunk in agent_executor.stream( {"messages": [HumanMessage(content="你好")]} ):print(chunk) print("----") # 建议使用工具:search_dashscope_knowledge for chunk in agent_executor.stream( {"messages": [HumanMessage(content="灵积模型是什么")]} ):print(chunk) print("----") # 建议使用工具:multiply for chunk in llm_with_tools.stream("计算 10 的 5 倍的结果"):print(chunk) print("----")
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
{'agent': {'messages': [AIMessage(content='你好!有什么可以帮助你的吗?', response_metadata={'model_name': 'qwen-max', 'finish_reason': 'stop', 'request_id': 'f6587cb5-91d9-9abe-a314-2603e821293d', 'token_usage': {'input_tokens': 376, 'output_tokens': 7, 'total_tokens': 383}}, id='run-0ac0c665-226f-4f4e-9c6d-e48db1122731-0')]}}
----
{'agent': {'messages': [AIMessage(content='', additional_kwargs={'tool_calls': [{'function': {'name': 'search_dashscope_knowledge', 'arguments': '{"query": "灵积模型"}'}, 'id': '', 'type': 'function'}]}, response_metadata={'model_name': 'qwen-max', 'finish_reason': 'tool_calls', 'request_id': 'e116a070-fc52-9585-8379-8bbac48c92c9', 'token_usage': {'input_tokens': 379, 'output_tokens': 22, 'total_tokens': 401}}, id='run-a0d58c7f-8534-47e5-8208-462ba2cc975c-0', tool_calls=[{'name': 'search_dashscope_knowledge', 'args': {'query': '灵积模型'}, 'id': ''}])]}}
{'tools': {'messages': [ToolMessage(content='什么是DashScope灵积模型服务_模型服务灵积(DashScope)-阿里云帮助中心\n\n\n\n\n\n\n\n\n\n\n\n\n产品解决方案文档与社区权益中心定价云市场合作伙伴支持与服务了解阿里云备案控制台\n文档产品文档输入文档关键字查找\n模型服务灵积\n\n\n\n\n产品概述\n\n\n\n\n\n快速入门\n\n\n\n\n\n操作指南\n\n\n\n\n\n开发参考\n\n\n\n\n\n实践教程\n\n\n\n\n\n服务支持\n\n\n\n首页\n\n\n\n模型服务灵积\n\n\n\n产品概述\n\n反馈上一篇:产品简介下一篇:产品计费 \n文档推荐\n\nDashScope灵积模型服务通过标准化的API提供“模型即服务”(Model-as-a-Service,MaaS)。不同于以往以任务为中心的AI API,DashScope构建在面向未来的、以模型为中心的理念下,因此也引入了一些新的概念和术语。开发者可以通过本文了解DashScope灵积模型服务的有关概念和术语,从而更好的使用DashScope进行AI应用开发。模型和模型服务“模型即服务”是DashScope灵积模型服务的本质:让各种模型的能力触手可得。DashScope将各类AI模型通过标准化的封装形成API服务,以方便应用开发者调用。通过DashScope,丰富多样化的模型不仅能通过推理API被集成,也能通过训练微调API实现模型定制化。DashScope为AI模型提供云原生的Serverless服务,使得开发者无需关注模型服务API背后的服务器管理,也可直接获得稳定可靠的服务。此外DashScope也为有需求的用户提供特定模型的独占服务。在DashScope灵积模型服务中,每个模型都拥有其唯一的模型名称字符串。例如,qwen-turbo\xa0代表的是通义千问大模型、paraformer-v1\xa0代表的是Paraformer语音识别模型等等。模型名称字符串是模型的代号,用于在DashScope API中以指定被调用的模型,通过model=‘模型名称字符串’\xa0给出。API-KEYDashScope灵积模型服务使用API-KEY作为调用API的密钥。API-KEY承担了调用鉴权、计量计费等功能。API-KEY被广泛应用于DashScope API中,通过 api-key\n\nAPI详情\n\n\n安装DashScope SDK\n\n\n快速开始\n\n\n快速开始\n\n\n计量计费\n\n\n模型介绍\n\n\n计量计费规则\n\n\n模型体验中心\n\n\n\n本页导读 (0)\n为什么选择阿里云什么是云计算全球基础设施技术先进稳定可靠安全合规分析师报告产品和定价全部产品免费试用产品动态产品定价价格计算器云上成本管理解决方案技术解决方案文档与社区文档开发者社区天池大赛培训与认证权益中心免费试用高校计划企业扶持计划推荐返现计划支持与服务基础服务企业增值服务迁云服务官网公告健康看板信任中心关注阿里云关注阿里云公众号或下载阿里云APP,关注云资讯,随时随地运维管控云服务联系我们:4008013260法律声明Cookies政策廉正举报安全举报联系我们加入我们友情链接阿里巴巴集团淘宝网天猫全球速卖通阿里巴巴国际交易市场1688阿里妈妈飞猪阿里云计算AliOS万网高德UC友盟优酷钉钉支付宝达摩院淘宝海外阿里云盘饿了么© 2009-2024 Aliyun.com 版权所有 增值电信业务经营许可证: 浙B2-20080101 域名注册服务机构许可: 浙D3-20210002 京D3-20220015浙公网安备 33010602009975号浙B2-20080101-4', name='search_dashscope_knowledge', tool_call_id='')]}}
{'agent': {'messages': [AIMessage(content='DashScope灵积模型服务是阿里云提供的一种“模型即服务”(Model-as-a-Service,MaaS)解决方案。它允许开发者访问和利用多种人工智能模型,而无需直接管理底层基础设施或复杂的模型部署。与传统以任务为中心的AI API不同,DashScope侧重于以模型为中心的方法,使得模型的能力更易于获取和应用。\n\n### 关键特点:\n\n- **模型多样化**: DashScope集成了多种AI模型,涵盖自然语言处理、图像识别、语音识别等多种领域,如通义千问大模型(qwen-turbo)、Paraformer语音识别模型(paraformer-v1)等。\n \n- **标准化API接口**: 所有模型都通过标准化的API提供服务,便于开发者集成到自己的应用程序中,只需指定模型名称即可调用相应的服务。\n\n- **云原生Serverless服务**: DashScope以Serverless方式提供模型服务,这意味着开发者无需担心服务器管理和运维,即可获得稳定、弹性的模型服务支持。\n\n- **API-KEY鉴权与计费**: 通过API-KEY进行调用鉴权和计量计费,确保服务的安全可控及透明计费。\n\n- **模型定制化能力**: 不仅提供模型推理服务,还支持对特定模型进行训练微调,以满足用户的个性化需求。\n\n- **服务模式灵活**: 提供既有共享模型服务,也有针对特定需求的独占模型服务选项。\n\n总之,DashScope灵积模型服务降低了企业和开发者应用先进AI技术的门槛,使其能够更加聚焦于业务创新和模型的应用,而非模型的搭建和运维。', response_metadata={'model_name': 'qwen-max', 'finish_reason': 'stop', 'request_id': '8730206d-bd5f-98f2-a23b-0ef2d3c8e8d0', 'token_usage': {'input_tokens': 1176, 'output_tokens': 334, 'total_tokens': 1510}}, id='run-a4dddf0b-4ad2-416e-a3c8-f79dc953ee63-0')]}}
----
content='' additional_kwargs={'tool_calls': [{'type': 'function', 'function': {'name': 'multiply', 'arguments': ''}, 'id': ''}]} id='run-3eef0407-3cf6-4531-bdc8-9180e0543b50' invalid_tool_calls=[{'name': 'multiply', 'args': '', 'id': '', 'error': None}] tool_call_chunks=[{'name': 'multiply', 'args': '', 'id': '', 'index': 0}]
content='' additional_kwargs={'tool_calls': [{'type': 'function', 'function': {'name': '', 'arguments': '{"first_int": 1'}, 'id': ''}]} id='run-3eef0407-3cf6-4531-bdc8-9180e0543b50' tool_calls=[{'name': '', 'args': {'first_int': 1}, 'id': ''}] tool_call_chunks=[{'name': '', 'args': '{"first_int": 1', 'id': '', 'index': 0}]
content='' additional_kwargs={'tool_calls': [{'type': 'function', 'function': {'name': '', 'arguments': '0, "second_int": 5'}, 'id': ''}]} id='run-3eef0407-3cf6-4531-bdc8-9180e0543b50' invalid_tool_calls=[{'name': '', 'args': '0, "second_int": 5', 'id': '', 'error': None}] tool_call_chunks=[{'name': '', 'args': '0, "second_int": 5', 'id': '', 'index': 0}]
content='' additional_kwargs={'tool_calls': [{'type': 'function', 'function': {'name': '', 'arguments': '}'}, 'id': ''}]} id='run-3eef0407-3cf6-4531-bdc8-9180e0543b50' invalid_tool_calls=[{'name': '', 'args': '}', 'id': '', 'error': None}] tool_call_chunks=[{'name': '', 'args': '}', 'id': '', 'index': 0}]
content='' additional_kwargs={'tool_calls': [{'type': 'function', 'function': {'name': '', 'arguments': ''}, 'id': ''}]} response_metadata={'finish_reason': 'tool_calls', 'request_id': '1b6594da-f866-94fa-83ab-b812a20678b0', 'token_usage': {'input_tokens': 387, 'output_tokens': 25, 'total_tokens': 412}} id='run-3eef0407-3cf6-4531-bdc8-9180e0543b50' invalid_tool_calls=[{'name': '', 'args': '', 'id': '', 'error': None}] tool_call_chunks=[{'name': '', 'args': '', 'id': '', 'index': 0}]
----- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
https://smith.langchain.com/public/de70d1a5-8f4f-4b7e-b98b-98f20abda3c2/r 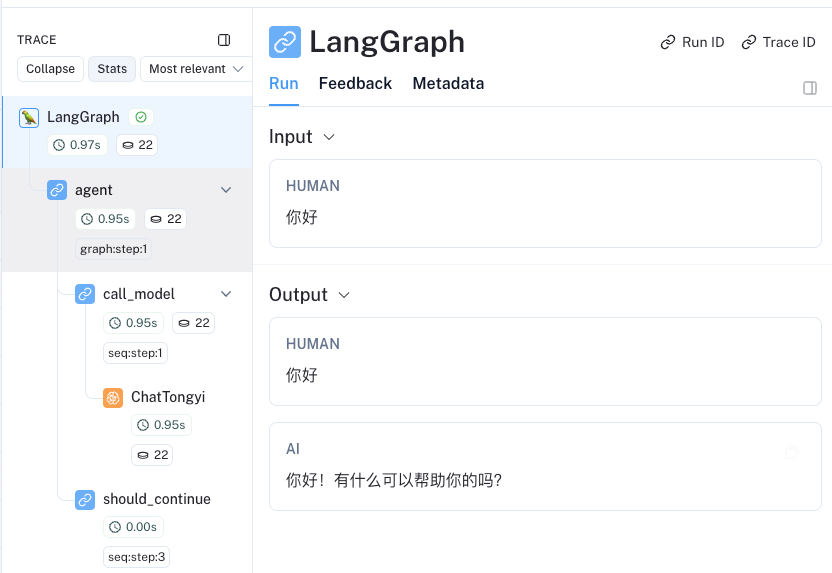
https://smith.langchain.com/public/e66cecfe-06fb-447a-91ab-e7ba4a39e668/r 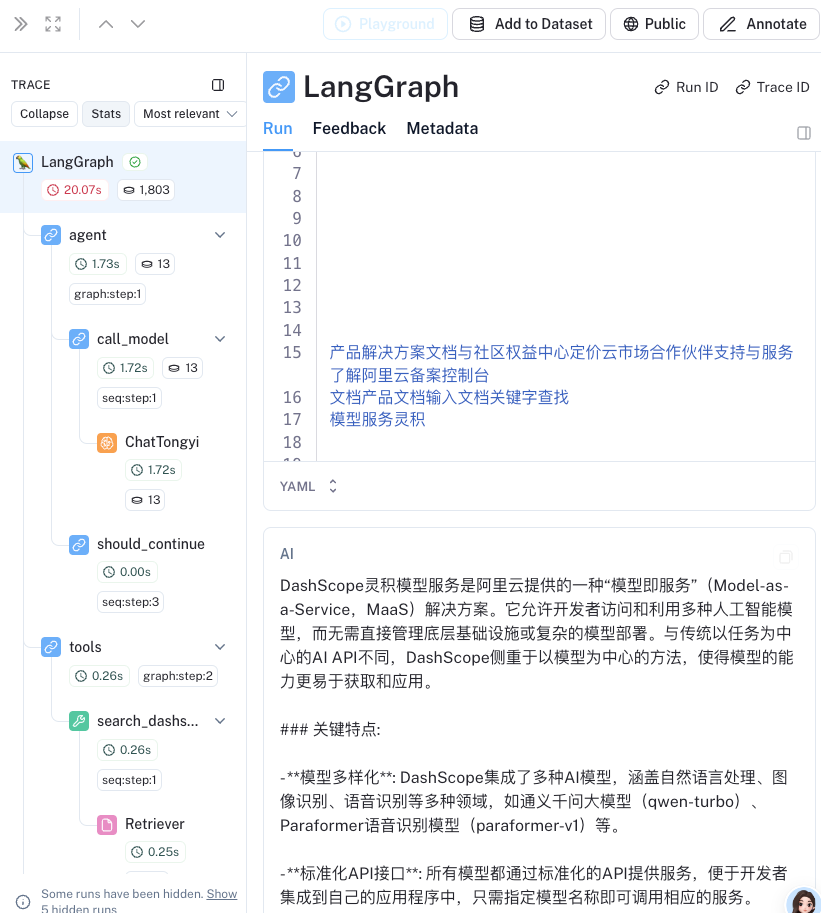
https://smith.langchain.com/public/50d1ab01-b39c-454d-804a-eaacb1bd61d3/r 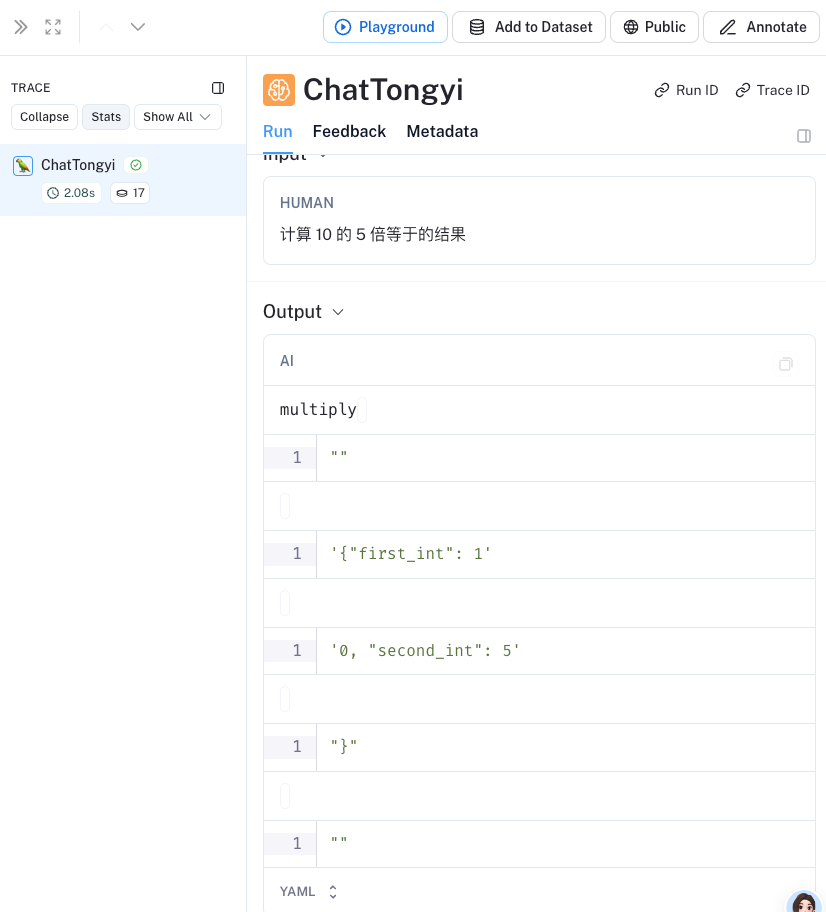
Streaming tokens
除了流回消息之外,流回令牌也很有用。我们可以使用 .astream_events方法。
此.astream_events方法仅适用于Python 3.11或更高版本。
async def main(): async for event in agent_executor.astream_events( {"messages": [HumanMessage(content="你好")]},version="v1" ): kind = event["event"] if kind == "on_chain_start": if ( event["name"] == "Agent" ): print( f"Starting agent: {event['name']} with input: {event['data'].get('input')}" ) elif kind == "on_chain_end": if ( event["name"] == "Agent" ): print() print("--") print( f"Done agent: {event['name']} with output: {event['data'].get('output')['output']}" ) if kind == "on_chat_model_stream": content = event["data"]["chunk"].content if content: print(content, end="|") elif kind == "on_tool_start": print("--") print( f"Starting tool: {event['name']} with inputs: {event['data'].get('input')}" ) elif kind == "on_tool_end": print(f"Done tool: {event['name']}") print(f"Tool output was: {event['data'].get('output')}") print("--") import asyncio if __name__ == "__main__": asyncio.run(main())
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
/opt/homebrew/lib/python3.11/site-packages/langchain_core/_api/beta_decorator.py:87: LangChainBetaWarning: This API is in beta and may change in the future.
warn_beta(
你好|!|有什么|可以帮助你的吗?|% - 1
- 2
内存缓存
如前所述,这个代理是无状态的。这意味着它不记得以前的交互。为了给它内存,我们需要传入一个检查指针。传入检查指针时,我们还必须传入一个 thread_id 调用代理时(因此它知道从哪个线程/对话恢复)。
# 创建缓存
from langgraph.checkpoint.sqlite import SqliteSaver
memory = SqliteSaver.from_conn_string(":memory:")
# 创建代理
from langgraph.prebuilt import create_react_agent
from langchain_core.messages import HumanMessage
agent_executor = create_react_agent(llm, toolList, checkpointer=memory)
config = {"configurable": {"thread_id": "abc123"}}- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
agent_executor = chat_agent_executor.create_tool_calling_executor(
model, tools, checkpointer=memory
)
config = {"configurable": {"thread_id": "abc123"}}- 1
- 2
- 3
- 4
for chunk in agent_executor.stream(
{"messages": [HumanMessage(content="你好,我是小明")]},config=config
):print(chunk)- 1
- 2
{'agent': {'messages': [AIMessage(content='你好,小明!很高兴能为你服务。有什么可以帮助你的吗?', response_metadata={'model_name': 'qwen-max', 'finish_reason': 'stop', 'request_id': '9b6a6bc9-0814-990b-8d0e-b57d22accb99', 'token_usage': {'input_tokens': 380, 'output_tokens': 15, 'total_tokens': 395}}, id='run-652cdac8-b1e9-4c9d-9efc-eb0a01bd5d5d-0')]}}for chunk in agent_executor.stream(
{"messages": [HumanMessage(content="我的名字是什么?")]},config=config
):print(chunk)- 1
- 2
{'agent': {'messages': [AIMessage(content='你的名字是小明。', response_metadata={'model_name': 'qwen-max', 'finish_reason': 'stop', 'request_id': '6643c950-f2f1-960e-a38a-24fcb7557099', 'token_usage': {'input_tokens': 409, 'output_tokens': 6, 'total_tokens': 415}}, id='run-4639c443-a3fb-413a-a294-c8a72ee67df2-0')]}}运行日志: https://smith.langchain.com/public/2813f856-3042-4ae8-88fd-aea5e3b92931/r https://smith.langchain.com/public/1dba567b-446f-47a9-9133-ded23ea64f38/r
结论
就这样结束了!在这个快速的开始中,我们介绍了如何创建一个简单的代理。然后我们展示了如何流回响应——不仅是中间步骤,还有令牌!我们还添加了内存,这样你就可以和他们对话了。代理是一个复杂的话题,有很多东西要学!
有关代理的更多信息,请查看 LangGraph 文档。这有它自己的一组概念、教程和操作指南。
欢迎关注微信公众号【千练极客】,尽享更多干货文章! 
本文由博客一文多发平台 OpenWrite 发布!

