
- 1mujoco环境安装问题_mujoco安装
- 2大一学生数据结构与算法的先后取舍_acm先学数据结构还是算法
- 3深度学习论文阅读路线图
- 4# hadoop入门第六篇-Hive实例_describle table语句
- 5Flink(四) 状态管理 1_flink 状态管理
- 6从零开始开发微信小程序:全面指南_微信小程序开发指南
- 7一篇文章玩转GDB/LLDB调试Redis源码_lldb 调试 redis
- 8(四)快速图像风格迁移训练模型载入及处理图像_快速风格迁移模型训练
- 9【2024版】超详细Python+Pycharm安装保姆级教程,Python+Pycharm环境配置和使用指南,看完这一篇就够了_安装python和pycharm
- 10大模型越狱攻击框架:集成11种方法,揭示大模型参数量和安全性的新规律
SmolLM: 一个超快速、超高性能的小模型集合
赞
踩
简介
本文将介绍SmolLM。它集合了一系列最尖端的 135M、360M、1.7B 参数量的小模型,这些模型均在一个全新的高质量数据集上训练。本文将介绍数据整理、模型评测、使用方法等相关过程。
SmolLMhttps://hf.co/collections/HuggingFaceTB/smollm-models-6695016cad7167254ce15966
引言
近期,人们对能在本地设备上运行的小语言模型的兴趣日渐增长。这一趋势不仅激发了相关业者对蒸馏或量化等大模型压缩技术的探索,同时也有很多工作开始尝试在大数据集上从头训练小模型。
微软的 Phi 系列、阿里巴巴的 Qwen2 (小于 2B 参数量) 以及 Meta 的 MobileLLM 均展示了这样的结论: 如果设计得当、训练充分,小模型也可以获得很好的性能。然而,这其中关于数据整理、训练细节的相关信息大多都未被披露。
在本文中,我们将介绍SmolLM。这是一个包含一系列最顶尖的小语言模型的集合,这些模型的参数量包括 135M、360M 和 1.7B。这些模型基于SmolLM-Corpus这一仔细整理的高质量数据集而构建,该数据集包含以下三个子集:
SmolLMhttps://hf.co/collections/HuggingFaceTB/smollm-models-6695016cad7167254ce15966
SmolLM-Corpushttps://hf.co/datasets/HuggingFaceTB/smollm-corpus
Cosmopedia v2: 通过 Mixtral 模型合成的、包含课文和故事等内容的数据集 (token 数量为 28B)
Python-Edu: 数据样本取自The Stack数据集、根据教育价值打分筛选出来的数据集 (token 数量为 4B)https://hf.co/datasets/bigcode/the-stack-v2-train-full-idshttps://hf.co/HuggingFaceTB/python-edu-scorer
FineWeb-Edu:FineWeb数据集经过去重且根据教育价值打分筛选出来的数据集 (token 数量为 220B)https://hf.co/datasets/HuggingFaceFW/finewebhttps://hf.co/HuggingFaceTB/python-edu-scorer
我们的评测结果显示,在对应的参数量区间内,SmolLM 的模型在一系列常识性推理和世界知识评测标准上均超越了现有的模型。在本文中,我们将介绍训练语料中三个子集的整理方法,并讨论 SmolLM 的训练和评测过程。
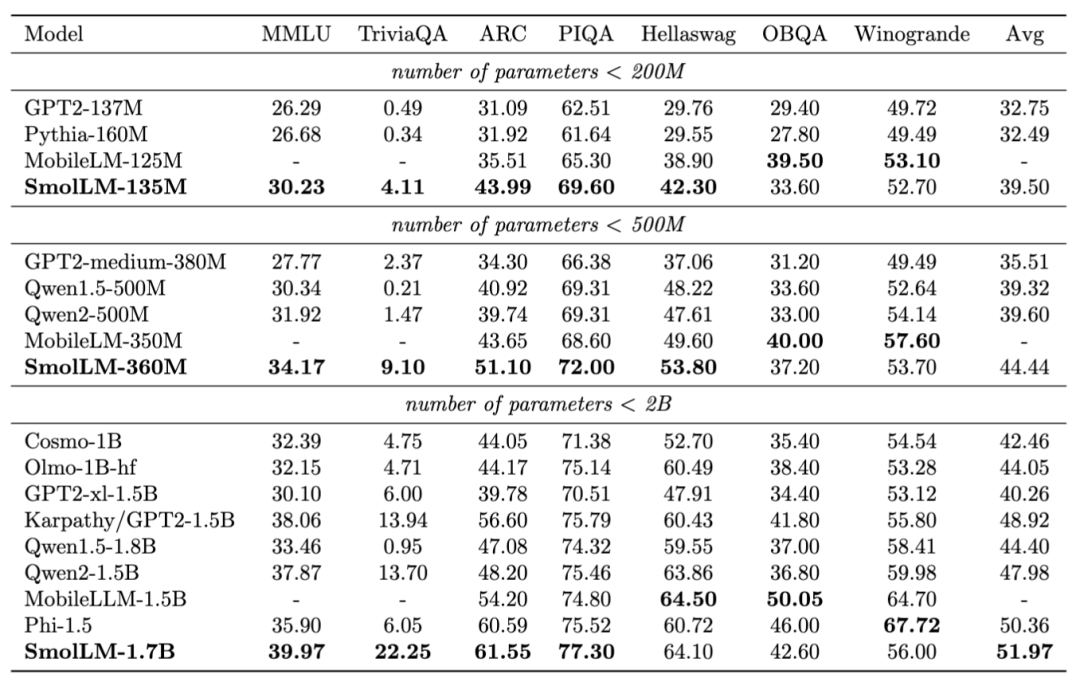
SmolLM 的模型在不同推理和常识评测标准上的测试结果
数据整理
Cosmopedia 数据集: 从 v1 到 v2
Cosmopedia v2 是 Cosmopedia 数据集的增强版。Cosmopedia 是当前最大的合成数据集,常被用来进行与训练。它包含超过三百万的课文、博客、故事等数据,这些数据均由 Mixtral-8x7B-Instruct-v0.1 模型生成。绝大部分数据是通过这种方式生成的: 搜集网页内容 (称为“种子样本”),提供内容所属的主题类别,然后让模型扩写来生成。如图 1 就展示了其中的一个样本示例。这里我们使用大量网络样本来提高数据的多样性,并扩展提示词的话题范围。这篇文章详细介绍了 Cosmopedia 数据集。
这篇文章https://hf.co/blog/cosmopedia

图 1: Cosmopedia 提示词示例.
为了在 v2 版的数据集中进一步优化数据质量,我们曾尝试过以下两种策略:
针对同一提示词,使用多个高性能模型去生成数据
优化提示词本身
针对第一种策略,我们曾尝试了 llama3-70B-Instruct、Mixtral-8x22B-Instruct-v0.1 以及 Qwen1.5-72B-Chat,但当我们在这些生成数据上训练后,我们发现效果提升很有限。因此,下文我们将聚焦于第二种策略: 我们是怎样改进提示词的。
寻找更好的主题和种子样本
每个提示词都包含三个主要部分: 主题、种子样本和生成风格,这三部分确定了意向受众和我们希望模型生成的内容的类型。
为确保生成的一致性,我们需要将相关性强的种子样本归类到对应的主题里面。在 Cosmopedia v1 里,我们通过对 FineWeb 里的样本进行聚类,来确保主题和对应的样本是一致的 (如图 2)。但这种方法有两点局限性:
这些主题虽然很全面地反映了 web/FineWeb 数据的聚类结果,但可能并没有全面反映真实世界的科目主题分布。
每个聚类内部的样本并没有被进一步过滤,所以可能包含很多低质量样本。
图 2: FineWeb 的聚类结果
因此,在 v2 版数据集中,我们使用BISAC 书籍分类定义的 3.4 万个主题来代替无监督的聚类。BISAC 已被作为一个通用标准,来给书籍进行科目分类。所以使用这种方法不仅能全面涵盖各类主题,也可以使得我们使用的主题在教育价值层面更有专业性。具体而言,我们先使用 BISAC 里 51 个大类中的 5000 个主题,让 Mixtral 模型针对每个主题生成它的多种二级子类。下图就展示了最终各个大类别下的子类主题数量分布。
BISAC 书籍分类https://www.bisg.org/complete-bisac-subject-headings-list
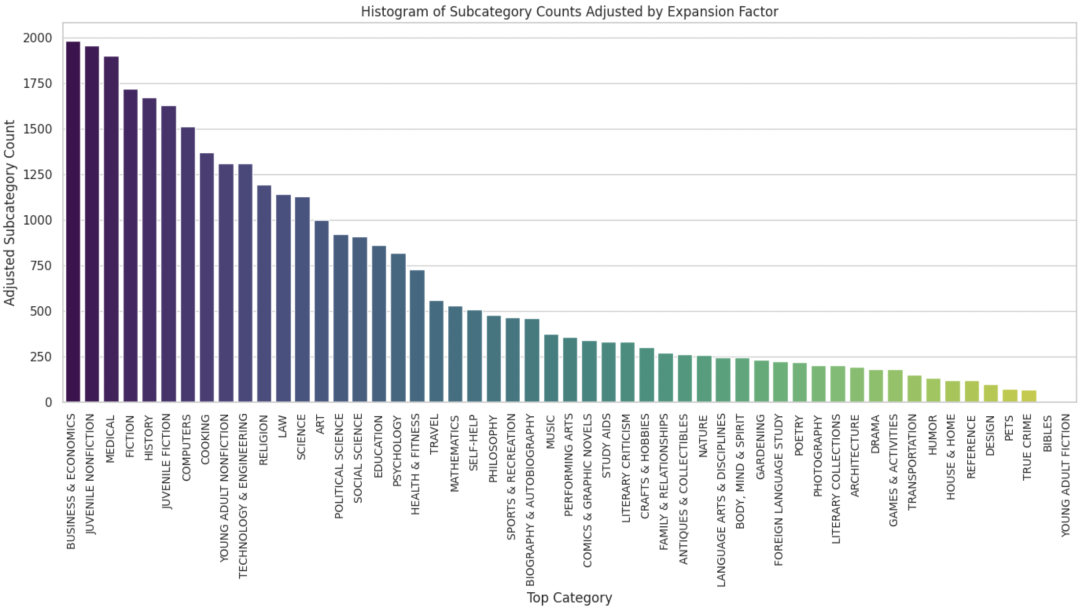
图 3: 不同大类下面的主题数量的统计直方图
在定义好了主题后,我们还需要找到和主题相关的数据条目。和使用搜索引擎类似,我们制作了一个搜索工具,用来检索和每个主题有强相关性的数据。我们使用 BISAC 的大类和子类主题作为搜索的关键词,在FineWeb数据集的CC-MAIN-2024-10和CC-MAIN-2023-50文件夹中进行搜索,两个文件夹包含有超过 5.2 亿的样本。对于每个搜索关键词,我们检索出 1000 条最接近的数据条目。相关代码可以见这里。
FineWebhttps://hf.co/datasets/HuggingFaceFW/fineweb
CC-MAIN-2024-10https://hf.co/datasets/HuggingFaceFW/fineweb/tree/main/data/CC-MAIN-2024-10
CC-MAIN-2023-50https://hf.co/datasets/HuggingFaceFW/fineweb/tree/main/data/CC-MAIN-2023-50
代码参考https://github.com/huggingface/cosmopedia/tree/main/fulltext_search
最终,我们集成了涵盖 3.4 万个主题的 3400 万条数据。接下来需要确定的是,哪种生成风格效果最好。
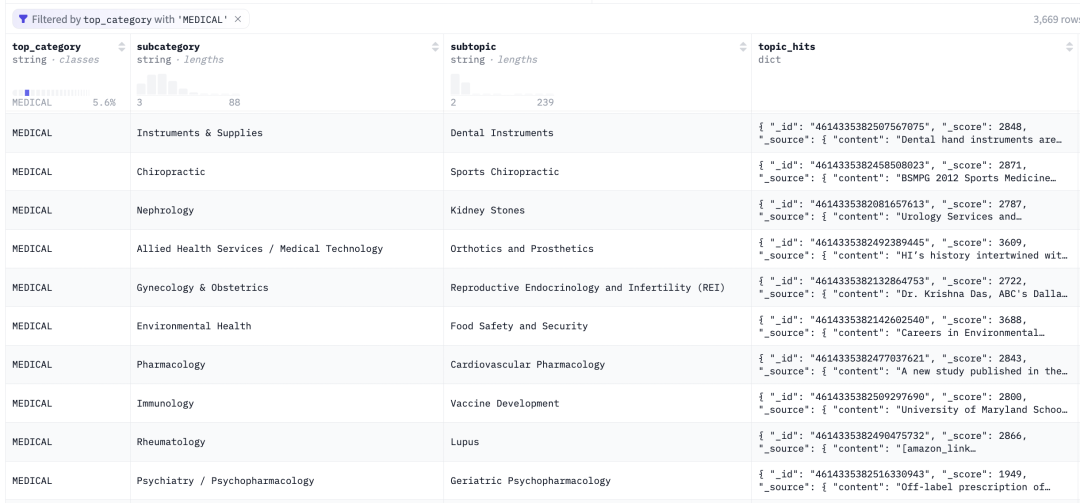
图 4: “Medical” 大类下的子类主题和对应的网页数据样本.
生成风格
为了确定最有效的生成风格,我们通过训练 1.8B 模型进行了对比实验,其中我们使用不同的 Cosmopedia v1 子集数据,共计有 80 亿 token 的数据量。在生成训练数据时,我们只生成 20 亿 token 的数据量,训练 4 轮,以此来节省时间 (使用 Mixtral 生成 20 亿 token 需要大约 1000 个 GPU 小时)。训练和评测的各项配置和FineWeb ablation models一致。每个训练我们都跑两遍,每次用不同的随机种子,最终评测分数取两次的平均。
FineWeb ablation modelshttps://hf.co/spaces/HuggingFaceFW/blogpost-fineweb-v1
至于训练结果对比,我们对比了 Cosmopedia v1 的这些子集:
两个 web 样本集:web_samples_v1和web_samples_v2https://hf.co/datasets/HuggingFaceTB/cosmopedia/tree/main/data/web_samples_v1https://hf.co/datasets/HuggingFaceTB/cosmopedia/tree/main/data/web_samples_v2
stories子集https://hf.co/datasets/HuggingFaceTB/cosmopedia/tree/main/data/stories
stanford和openstax两个子集https://hf.co/datasets/HuggingFaceTB/cosmopedia/tree/main/data/stanfordhttps://hf.co/datasets/HuggingFaceTB/cosmopedia/tree/main/data/openstax
我们发现,当训练文本是基于 stanford 和 openstax 的主题和种子样本时,总体的性能最好,其 MMLU 和 ARC 指标均高于两个 web 样本集。而 stories 仅仅有助于常识性的相关指标。在实现了 v2 版数据集检索新主题和种子样本的代码后,我们也可以对比这次实验的指标数据,来判断我们新生成的提示词的质量好坏。
接下来,我们还要探索哪种受众风格最好。我们使用相同的课文类提示词生成课文内容,但针对两种目标受众: 中学生和大学生。我们发现,在针对中学生受众的生成数据上训练,模型在除了 MMLU 的各项指标上取得了最好的分数。一个合理的解释是,这些指标一般都是对初级或中级的科学知识进行考察,而 MMLU 则包含了针对高级甚至专家级知识的问题。
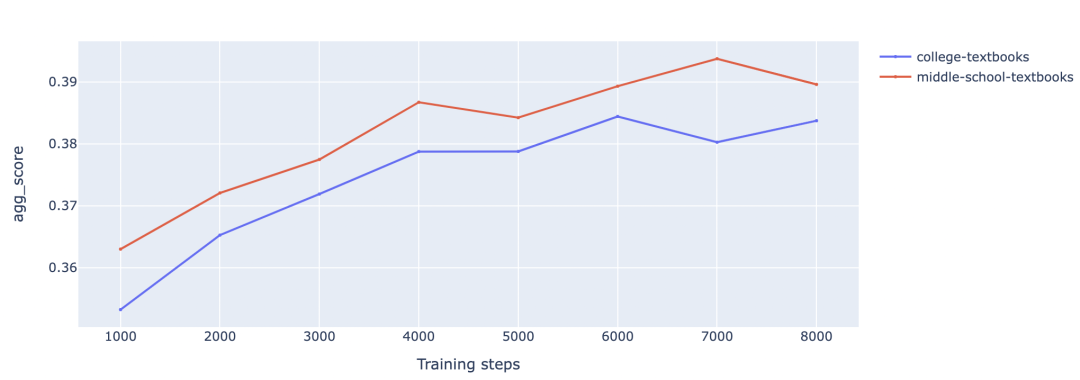
不同受众的课文数据上的评测结果
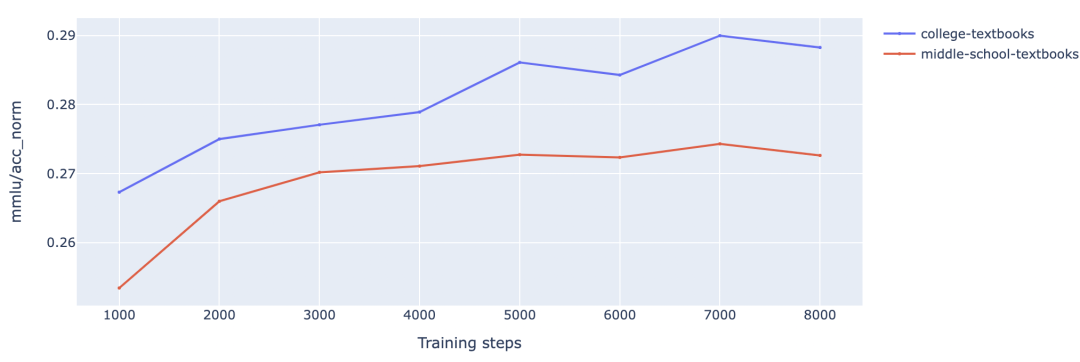
不同受众的课文数据上的评测结果
对于 v2 版本数据,我们生成的数据中,40% 面向中学生受众,30% 面向大学生受众,剩下 30% 混合了各种不同受众群体,且融合了 v1 中 stories、stanford 等风格的课文风格。除此之外,我们还生成了 10 亿代码相关的课文,这部分数据基于AutoMathText数据集的Python代码部分。
AutoMathTexthttps://hf.co/datasets/math-ai/AutoMathText
Pythonhttps://hf.co/datasets/math-ai/AutoMathText/tree/main/data/code/python
最终,我们生成了 3900 万合成数据,按 token 数量算,规模达到了 20 亿,涵盖课文、故事、文章、代码,假想受众的多样性也很高,涵盖主题超过 3.4 万。
FineWeb-Edu 数据集
FineWeb-Edu 数据集由我们在几个月前随着FineWeb 数据集的技术报告公开,它包含 1.3 万亿 的 token。其内容来自教育相关的网页,这些网页信息从
Copyright © 2003-2013 www.wpsshop.cn 版权所有,并保留所有权利。

