
ONNX深入研究(2):运行时引擎_onnx runtime原理
赞
踩
在上一部分中,我们回顾了加速方法,然后解释了 ONNX 作为通用中间表示 (IR) 的必要性。
在本文中,我们将研究 ONNX 运行时及其工作原理。

NSDT工具推荐: Three.js AI纹理开发包 - YOLO合成数据生成器 - GLTF/GLB在线编辑 - 3D模型格式在线转换 - 可编程3D场景编辑器 - REVIT导出3D模型插件 - 3D模型语义搜索引擎 - Three.js虚拟轴心开发包 - 3D模型在线减面 - STL模型在线切割
1、ONNX Runtime
随着时间的推移,许多框架和运行时引擎在其工具中包含了对 ONNX 格式的支持:

框架

运行时引擎
在运行时引擎中,ONNX Runtime 是最知名的加速器之一。此加速器可用于模型训练和推理。
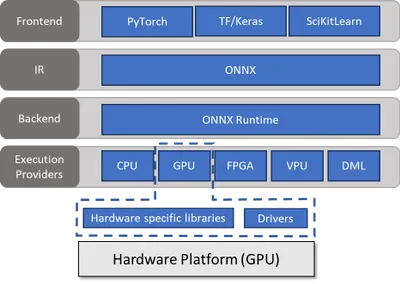
如上所示,ONNX Runtime 作为运行时引擎在不同的硬件上运行 ONNX 模型(可以在不同的框架中开发,然后转换为 ONNX 格式)。这种可能性可以通过 ONNX Runtime 本身提供的 API(以执行提供程序或 EP 的名义)来实现。换句话说,执行提供程序是用于查询硬件功能的硬件加速接口。
2、执行提供程序
执行提供程序(Execution Providers)向 ONNX 运行时公开自己的一组功能。这些功能可以是要执行的节点、其内存分配器等。自定义加速器(如 GPU、VPU 等)是执行提供程序的示例。
通常,ONNX 模型并不总是在特定的执行提供程序上运行,但 ONNX 运行时在包含多个执行提供程序的异构环境中运行模型。还有一个默认执行提供程序,所有无法在专用执行提供程序上运行的节点都将在该默认执行提供程序上运行。
执行提供程序可以分为以下两类:
基于内核的执行提供程序
它们提供 ONNX 中定义的操作的实现。
示例:
- CPUExecutionProvider
- CUDAExecutionProvider
- MKLDNNExecutionProvider
基于运行时的执行提供程序
这些执行提供程序可能没有 ONNX 操作的详细实现,但它们可以全部或部分执行 ONNX 图。
示例:
- nGraphExecutionProvider
- TensorRTExecutionProvider
3、图优化
这组优化可以视为包括应用于模型计算图的所有更改。这些优化可分为三个级别:
3.1 基本优化
此级别的优化在保留功能含义的同时重写图形,并适用于所有执行提供程序。此重写包括以下内容:
常量折叠
静态计算仅依赖于常量初始化的图形部分。这消除了在运行时计算它们的需要。
冗余节点消除
- 身份消除
- 切片消除
- 解压消除
- Dropout 消除
节点融合
- Conv Add 融合
- Conv Mul 融合
- Conv BatchNorm 融合
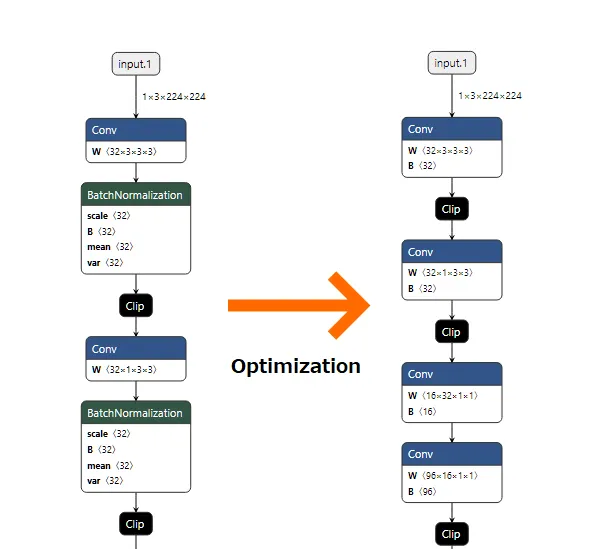
BatchNormalization 层通常放在 Convolution 层之后(以稳定和提高学习效率),但通过将其减少到 Convolution 层的参数,可以将其从网络中移除,因为参数的值在 Inference 阶段将保持不变。
- Relu Clip Fusion
- Reshape Fusion
3.2 扩展优化
此级别的优化包括更复杂的节点集成,这些集成仅适用于分配给 CPU、CUDA 和 ROCm Execution Providers 的节点。其中一些优化包括:
- Matmul Add Fusions
- Conv Activation Fusion
- BERT Embedding Layer Fusion
3.3 布局优化
这些优化会更改数据的布局,并且仅应用于分配给 CPU 执行提供程序的节点。这些优化包括:
使用 NCHWc 布局而不是 NCHW
关于这些优化的两个重要事项是:
它们都是默认启用的,并且在执行下一级优化后,每个优化都会应用于图形。这些优化也可以在不同级别启用和禁用。
- ORT_DISABLE_ALL
- ORT_ENABLE_BASIC
- ORT_ENABLE_EXTENDED
- ORT_ENABLE_ALL
使用 graph_optimization_level 参数,你可以在图形中设置优化级别。
离线和在线模式:
所有优化都可以在线或离线应用。
在在线模式下,初始化推理会话时,我们会在推理之前应用所有启用的优化。每次初始化会话时都这样做会导致时间开销。
在离线模式下,应用图形优化后,ONNX Runtime 会序列化模型并将其保存到磁盘。因此,我们可以通过从磁盘读取优化模型来减少初始设置时间。通过设置 optmized_model_filepath 参数,可以在磁盘上启用优化模型的序列化。
3.4 图转换
可以从其他角度检查优化,例如模型上的应用级别。从这个角度来看,优化通常称为“图转换”。这些转换在三个级别完成:
生成图形后,在任何条件下应用的转换。
示例:强制转换插入、内存复制插入
一般转换和与执行提供商无关的转换
示例:dropout 消除
特定于执行提供商的转换
示例:FPGA 的转置插入
这些转换也可以是全局的或局部的。
在全局模式下,转换应用于整个图形。在 ONNX Runtime 中应用这些转换的接口称为 GraphTransformer。
另一方面,在本地模式下,转换可以被视为应用于子图和某些节点的重写规则。ONNX Runtime 中的 RewritingRule 接口用于实现这些转换。
4、高级架构
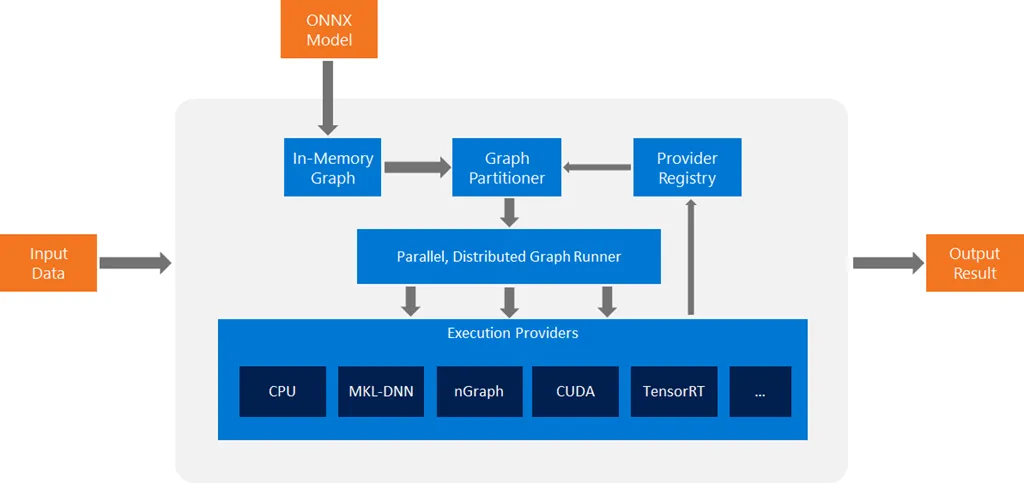
- ONNX Runtime 将模型图转换为其内存中的图表示。
- 应用一系列与硬件无关的优化。
- 根据可用的执行提供程序,ONNX Runtime 将图分解为一组子图。
ONNX Runtime 使用贪婪方法将节点分配给执行提供程序。可用的执行提供程序按指定顺序考虑。按照此顺序,尽可能将子图分配给特殊执行提供程序。默认执行提供程序被视为最后一个执行提供程序,负责执行未分配给其他执行提供程序的剩余子图。
- 每个子图都分配给一个执行提供程序。
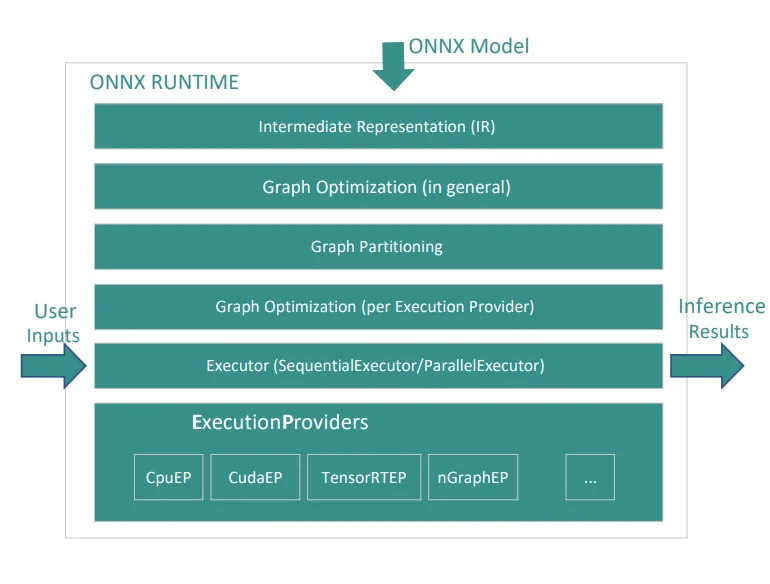
5、ONNX 运行时性能调优
除了可以灵活地选择模型和执行提供程序外,还可以调整超参数以提高性能。
5.1 多线程
ONNX 运行时支持两种执行模式:顺序和并行。执行模式控制图形的运算符是顺序执行还是并行执行。默认情况下,执行模式为顺序。
多个运算符的并行执行安排在操作间线程池上。Eigen 库线程池的优化版本用于操作间并行化。借助 ONNX 运行时中的 inter_op_num_threads 参数,我们可以在此模式下设置线程数。当我们处于并行执行模式时使用此参数。
运算符的执行也使用操作内线程池进行并行化。OpenMP 用于操作内并行化。借助 ONNX 运行时中的 intra_op_num_threads 参数,我们可以在此模式下设置线程数。当我们处于顺序执行模式时使用此参数。
5.2 内存管理
默认情况下,内存竞技场不会将未使用的内存返回给操作系统。通过设置一些参数,用户可以在一定时间内释放内存。目前,唯一支持的时间段是每次运行结束时。
基于区域的内存竞技场是一种内存管理类型,其中每个分配的对象都分配给一个区域。区域(区域、竞技场或区域)或内存上下文是可以重新分配或释放的分配对象的集合。简单来说,竞技场是一块连续且较大的内存,分配一次后可以手动管理其不同部分。竞技场的重要之处在于完全控制内存的分配方式。唯一失控的是初始化库的调用。
大多数时候,我们有一个动态形状模型,有时可能会处理需要大量内存的请求。由于 arena 默认不释放内存,arena 增长产生的内存将作为服务此请求的一部分永远保留,因此大多数后续请求可能都不需要该内存,这意味着为某些异常分配的大量内存仍然存在。
有两种策略可以根据传入的请求扩展或收缩内存:
- kNextPowerOfTwo:后续扩展/收缩的值更大/更小(乘以/除以 2)
- kSameAsRequested:根据需要扩展/收缩
5.3 分析和日志记录
ONNX Runtime 以 JSON 文件的形式向开发人员提供与模型分析相关的信息(多线程、运算符延迟等)。此文件可以通过以下两种方式之一生成:
- Onnxruntime_perf_test.exe
- 将参数 enable_profiling 设置为 True
对于日志记录,log_severity_level 参数用于设置日志级别。要查看所有日志,应将此参数的值设置为 0(详细)。
原文链接:ONNX深入研究(2) - BimAnt

