
热门标签
热门文章
- 1XSS漏洞分类_xssdey
- 2关闭NetworkManager的作用
- 3【.dll 没有被指定在windows上运行】
- 4【独家源码】ssm基于专家系统房产营销智能推荐系统77ao8计算机毕业设计问题的解决方案与方法_智能推荐系统数据库课程设计方案
- 52024云服务器ECS_云主机_服务器托管_e实例-阿里云
- 6uni-app 苹果手机底部安全区域的适配问题_uniapp 底部按钮安全区域适配
- 7python中列表推导式的基本格式_python3基础之如何使用列表推导式
- 8Docker 设置国内镜像源,加速下载_docker国内镜像下载
- 9高通9008工具 qpst 安装时报错 qpst server returned unexpected error attempting 解决办法
- 10Flutter Modul集成到IOS项目_flutter项目集成到ios项目
当前位置: article > 正文
如何用Python将普通视频变成动漫视频_python 实现视频转动漫
作者:你好赵伟 | 2024-02-21 13:34:47
赞
踩
python 实现视频转动漫
容我废话一下
最近几个月,毒教材被曝光引发争议,那些编写度教材的人着实可恶。咱程序员也没有手绘插画能力,但咱可以借助强大的深度学习模型将视频转动漫。所以今天的目标是让任何具有python语言基本能力的程序员,实现短视频转动漫效果。
效果展示

一、思路流程
- 读取视频帧
- 将每一帧图像转为动漫帧
- 将转换后的动漫帧转为视频
难点在于如何将图像转为动漫效果。这里我们使用基于深度学习的动漫效果转换模型,考虑到许多读者对这块不了解,因此我这边准备好了源码和模型,直接调用即可。不想看文章细节的可以直接拖到文章末尾,获取源码。
二、图像转动漫
为了让大家不关心深度学习模型,已经为大家准备好了转换后的onnx类型模型。接下来按顺序介绍运行onnx模型流程。
安装onnxruntime库
pip install onnxruntime
- 1
如果想要用GPU加速,可以安装GPU版本的onnxruntime:
pip install onnxruntime-gpu
- 1
需要注意的是:
onnxruntime-gpu的版本跟CUDA有关联,具体对应关系如下:
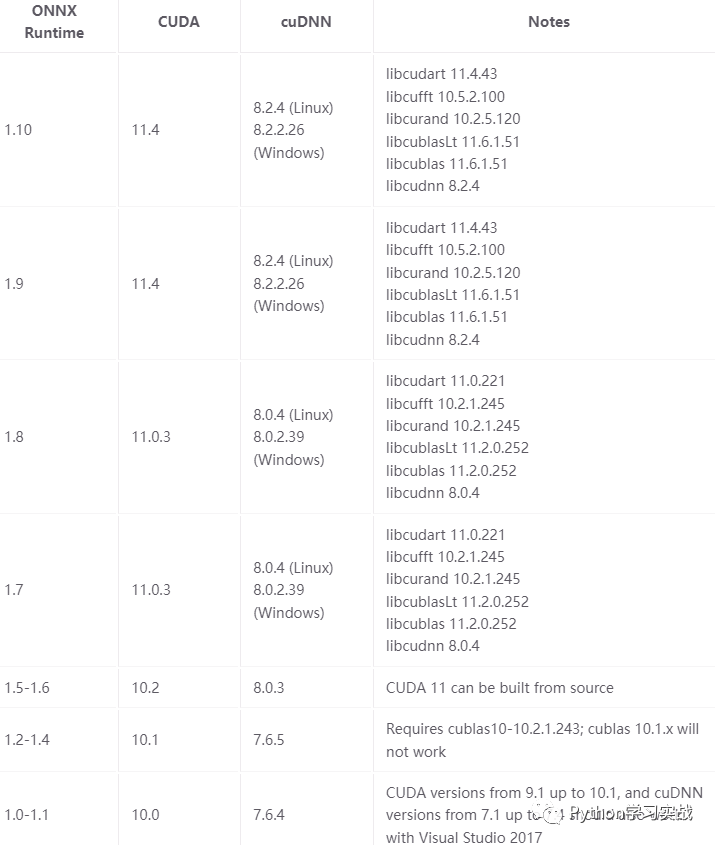
当然,如果用CPU运行,那就不需要考虑那么多了。考虑到通用性,本文全部以CPU版本onnxruntime。
运行模型
先导入onnxruntime库,创建InferenceSession对象,调用run函数。
如下所示
import onnxruntime as rt
sess = rt.InferenceSession(MODEL_PATH)
inp_name = sess.get_inputs()[0].name
out = sess.run(None, {inp_name: inp_image})
- 1
- 2
- 3
- 4
具体到我们这里的动漫效果,实现细节如下:
import cv2 import numpy as np import onnxruntime as rt # MODEL = "models/anime_1.onnx" MODEL = "models/anime_2.onnx" sess = rt.InferenceSession(MODEL) inp_name = sess.get_inputs()[0].name def infer(rgb): rgb = np.expand_dims(rgb, 0) rgb = rgb * 2.0 / 255.0 - 1 rgb = rgb.astype(np.float32) out = sess.run(None, {inp_name: rgb}) out = out[0][0] out = (out+1)/2*255 out = np.clip(out, 0, 255).astype(np.uint8) return out def preprocess(rgb): pad_w = 0 pad_h = 0 h,w,__ = rgb.shape N = 2**3 if h%N!=0: pad_h=(h//N+1)*N-h if w%2!=0: pad_w=(w//N+1)*N-w # print(pad_w, pad_h, w, h) rgb = np.pad(rgb, ((0,pad_h),(0, pad_w),(0,0)), "reflect") return rgb, pad_w, pad_h

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
其中, preprocess函数确保输入图像的宽高是8的整数倍。这里主要是因为考虑到深度学习模型有下采样,确保每次下采样能被2整除。
单帧效果展示



三、视频帧读取与视频帧写入
这里使用Opencv库,提取视频中每一帧并调用回调函数将视频帧回传。在将图片转视频过程中,通过定义VideoWriter类型变量WRITE确保唯一性。具体实现代码如下:
import cv2 from tqdm import tqdm WRITER = None def write_frame(frame, out_path, fps=30): global WRITER if WRITER is None: size = frame.shape[0:2][::-1] WRITER = cv2.VideoWriter( out_path, cv2.VideoWriter_fourcc(*'mp4v'), # 编码器 fps, size) WRITER.write(frame) def extract_frames(video_path, callback): video = cv2.VideoCapture(video_path) num_frames = int(video.get(cv2.CAP_PROP_FRAME_COUNT)) for _ in tqdm(range(num_frames)): _, frame = video.read() if frame is not None: callback(frame) else: break
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
完整源码获取点击下方微信名片获取哟~
给大家推荐一套爬虫教程,涵盖常见大部分案例,非常实用!
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/你好赵伟/article/detail/124104
推荐阅读
相关标签

