
- 1uniapp 怎么设置凸起的底部tabbar_uniapp底部导航栏中间凸起
- 2第二周周报_入职培训第二周周报
- 3vue3 element-plus el-table:列表中相同名称的数据实现行合并_element-ui el-table span-method合并name相同的行
- 4【PyTorch][chapter 16][李宏毅深度学习][Neighbor Embedding][t-SNE]
- 5H264 码率控制原理
- 6Nightingale发布v5.9.2,新功能解决多个生产痛点,真香_夜莺监控( nightingale ) 新建监控大盘
- 7SQL Server 跨服务器同步或定时同步数据库
- 8es (brain split)脑裂问题导致重建索引速度缓慢_fatal error in thread
- 9汉诺塔问题—java详解(附源码)
- 10为什么 Linux 系统默认页大小是 4KB ?_linux为什么一页是4k
kafka为什么性能这么高?
赞
踩
Kafka系统架构
Kafka是一个分布式流处理平台,具有高性能和可伸缩性的特点。它使用了一些关键的设计原则和技术,以实现其高性能。
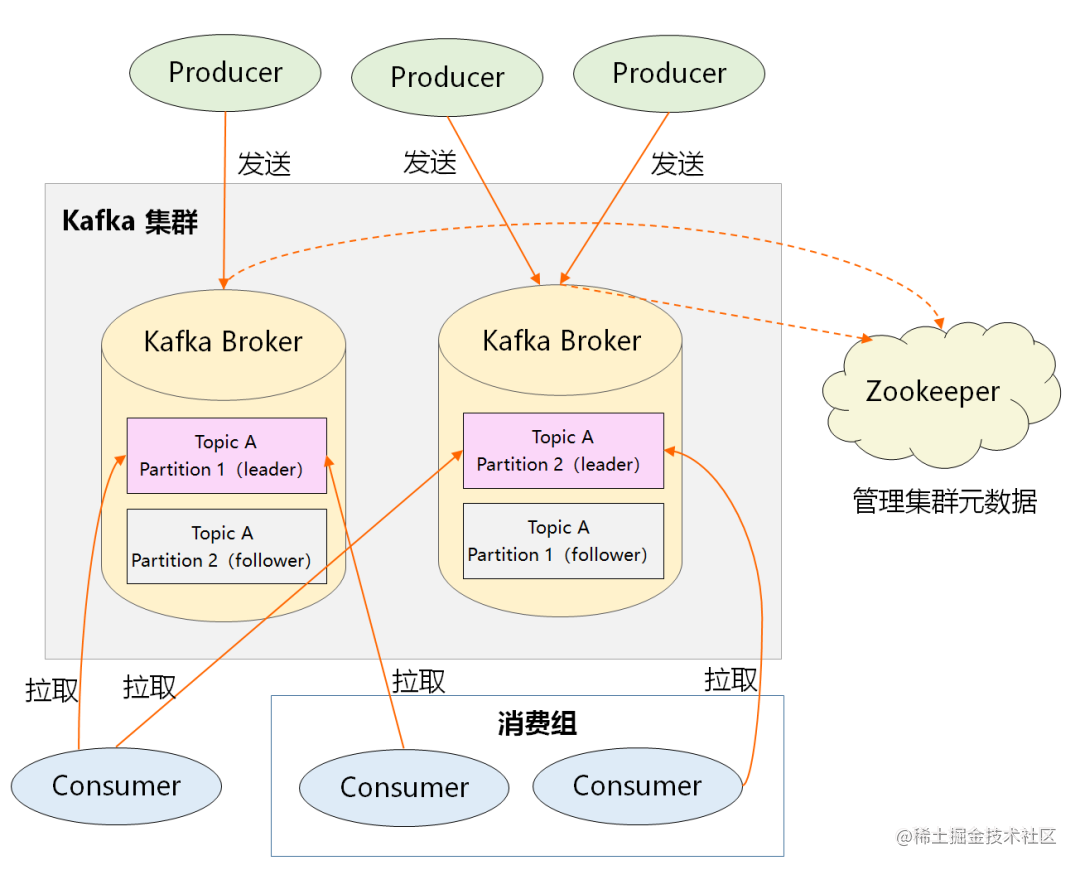
上图是Kafka的架构图,Producer生产消息,以Partition的维度,按照一定的路由策略,提交消息到Broker集群中各Partition的Leader节点,Consumer以Partition的维度,从Broker中的Leader节点拉取消息并消费消息。
- Producer发送消息:Producer生产消息会涉及大量的消息网络传输,如果Producer每生产一个消息就发送到Broker会造成大量的网络消耗,严重影响到Kafka的性能。为了解决这个问题,Kafka使用了批量发送、消息压缩的方式。
- Broker持久化:Broker在持久化消息、读取消息的时候,如果采用传统的IO读写方式,会严重影响Kafka的性能,为了解决这个问题,Kafka采用了分区、顺序写+PageCache的方式。
- Consumer消费消息:采用pull模式,mmap、零拷贝
下面分别从发送消息、持久化、消费消息三个角度介绍Kafka如何提高性能。
Kafka高性能分析
1. 发送消息高性能
1.1 批量发送消息
Producer生成消息发送到Broker,涉及到大量的网络传输,如果一次网络传输只发送一条消息,会带来严重的网络消耗。为了解决这个问题,Kafka采用批量发送的方式,通过将多条消息按照分区进行分组,然后每次发送一个消息集合,从而大大减少了网络传输的 overhead。
1.2 消息压缩
消息压缩的目的是为了进一步减少网络传输带宽。而对于压缩算法来说,通常是:数据量越大,压缩效果才会越好。
因为有了批量发送这个前期,从而使得 Kafka 的消息压缩机制能真正发挥出它的威力(压缩的本质取决于多消息的重复性)。对比压缩单条消息,同时对多条消息进行压缩,能大幅减少数据量,从而更大程度提高网络传输率。
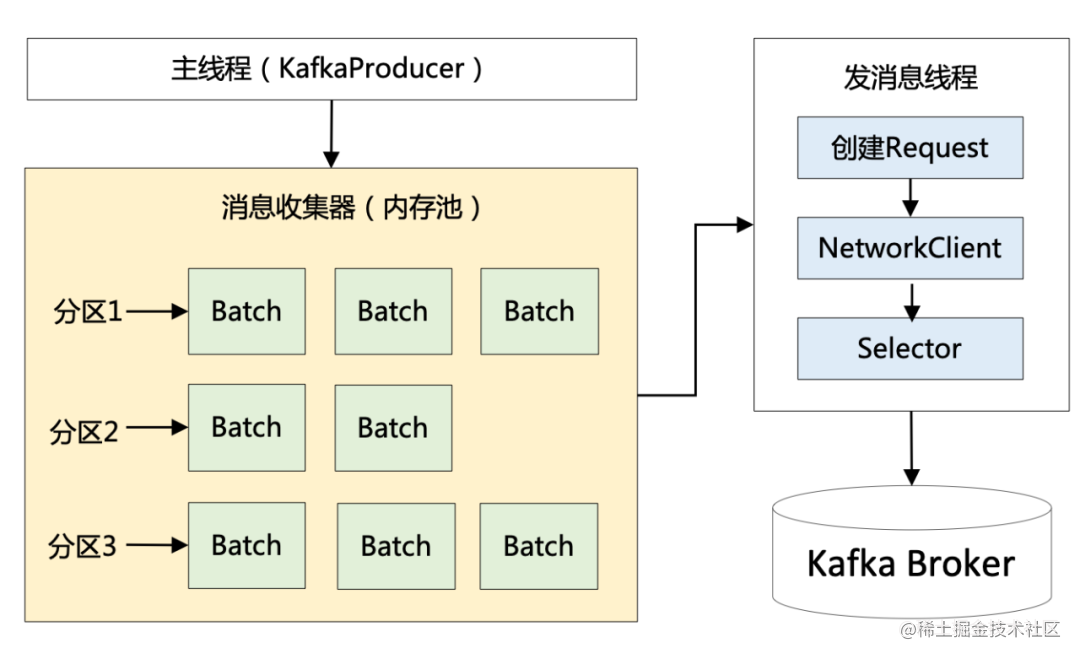
1.3 内存池复用
前面说过 Producer 发送消息是批量的,因此消息都会先写入 Producer 的内存中进行缓冲,直到多条消息组成了一个 Batch,才会通过网络把 Batch 发给 Broker。
当这个 Batch 发送完毕后,显然这部分数据还会在 Producer 端的 JVM 内存中,由于不存在引用了,它是可以被 JVM 回收掉的。
但是大家都知道,JVM GC 时一定会存在 Stop The World 的过程,即使采用最先进的垃圾回收器,也势必会导致工作线程的短暂停顿,这对于 Kafka 这种高并发场景肯定会带来性能上的影响。
有了这个背景,便引出了 Kafka 非常优秀的内存池机制,它和连接池、线程池的本质一样,都是为了提高复用,减少频繁的创建和释放。
具体是如何实现的呢?其实很简单:Producer 一上来就会占用一个固定大小的内存块,比如 64MB,然后将 64 MB 划分成 M 个小内存块(比如一个小内存块大小是 16KB)。
当需要创建一个新的 Batch 时,直接从内存池中取出一个 16 KB 的内存块即可,然后往里面不断写入消息,但最大写入量就是 16 KB,接着将 Batch 发送给 Broker ,此时该内存块就可以还回到缓冲池中继续复用了,根本不涉及垃圾回收。最终整个流程如下图所示:
2. 持久化高性能
2.1 分区
Kafka的消息是一个一个的键值对,键可以设置为默认的null。键有两个用途,可以作为消息的附加信息,也可以用来决定该消息被写入到哪个Partition。Topic的数据被分成一个或多个Partition,Partition是消息的集合,Partition是Consumer消费的最小粒度。
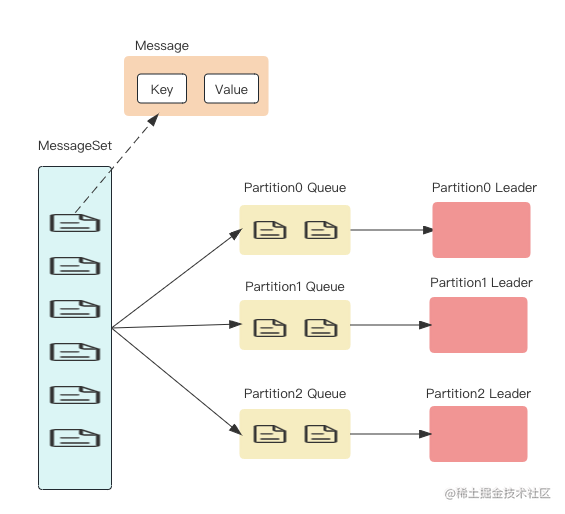
kafka分区.png
Kafka通过将Topic划分成多个Partition,Producer将消息分发到多个本地Partition的消息队列中,每个Partition消息队列中的消息会写入到不同的Leader节点。如上图所示,消息经过路由策略,被分发到不同的Partition对应的本地队列,然后再批量发送到Partition对应的Leader节点。
Partition它是 Kafka 并发处理的最小粒度,很好地解决了存储的扩展性问题。随着分区数的增加,Kafka 的吞吐量得以进一步提升。
2.2 顺序IO
- 随机写与顺序写
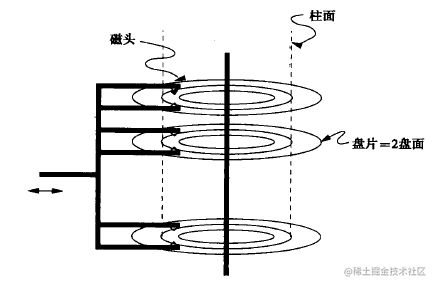
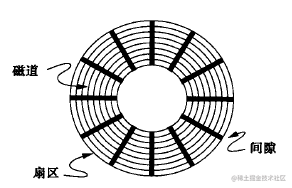
上图是磁盘的简易模型图。磁盘上的数据由柱面号、盘片号、扇区号标识。当需要从磁盘读数据时,系统会将数据逻辑地址传给磁盘,磁盘的控制电路按照寻址逻辑地址翻译成物理地址,即确定要读的数据在哪个磁道,哪个扇区。
为了实现读取这个扇区的数据,需要将磁头放到这个扇区上方,为了实现这一点:
- 首先必须找到柱面,即磁头需要移动对准相应磁道,这个过程叫做寻道或定位;
- 盘面确定以后,盘片开始旋转,将目标扇区旋转到磁头下
因此一次读数据请求完成过程由三个动作组成:
- 寻道:磁头移动定位到指定磁道,这部分时间代价最高,最大可达到0.1s左右;
- 旋转延迟:等待指定扇区旋转至磁头下。与硬盘自身性能有关,xxxx转/分;
- 数据传输:数据通过系统总线从磁盘传送到内存的时间。
对于从磁盘中读取数据的操作,叫做IO操作,这里有两种情况:
- 假设我们所需要的数据是随机分散在磁盘的不同盘片的不同扇区中的,那么找到相应的数据需要等到磁臂通过寻址作用旋转到指定的盘片,然后盘片寻找到对应的扇区,才能找到我们所需要的一块数据,一次进行此过程直到找完所有数据,称为随机IO,读取数据速度较慢。
- 假设我们已经找到了第一块数据,并且其他所需的数据就在这一块数据后边,那么就不需要重新寻址,可以依次拿到我们所需的数据,称为顺序IO。
顺序IO相对于随机IO,减少了大量的磁盘寻址过程,提高了数据的查询效率。
Broker写消息
Broker中需要将大量的消息做持久化,而且存在大量的消息查询场景,如果采用传统的IO操作,会带来大量的磁盘寻址,影响消息的查询速度,限制了Kafka的性能。为了解决这个问题,Kafka采用顺序写的方式来做消息持久化。Producer传递到Broker的消息集中的每条消息都会分配一个顺序值,用来标记Producer所生产消息的顺序,每一批消息的顺序值都从0开始。下图给出一个例子,Producer写到Partition的消息有3条消息,对应的顺序值是[0,1,2]。
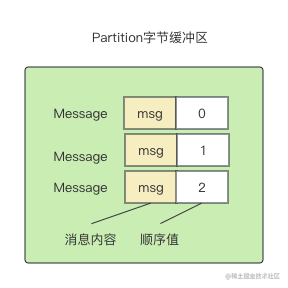
Producer创建的消息集中每条消息的顺序值只是相对于本批次的序号,所以这个值不能直接存储在日志文件中。服务端会将每条消息的顺序值转换成绝对偏移量(Broker从Partition维度来标记消息的顺序,用于控制Consumer消费消息的顺序)。Kafka通过nextOffset(下一个偏移量)来记录存储在日志中最近一条消息的偏移量。
| Message | 绝对偏移量 | 顺序值 |
| Message0 | 900 | 0 |
| Message1 | 901 | 1 |
| Message2 | 902 | 2 |
如上表所示,消息写入前,nextOffset是899,Message0、Message1、Message2是连续写入的三条消息,消息被写入后其绝对偏移量分别是900、901、902,对应的顺序值分别是0、1、2,nextOffset变成902。
Broker将每个Partition的消息追加到日志中,是以日志分段(Segment)为单位的。当Segment的大小达到阈值(默认是1G)时,会新创建一个Segment保存新的消息,每个Segment都有一个基准偏移量(baseOffset,每个Segment保存的第一个消息的绝对偏移量),通过这个基准偏移量,就可以计算出每条消息在Partition中的绝对偏移量。 每个日志分段由数据文件和索引文件组,数据文件(文件名以log结尾)保存了消息集的具体内容,索引文件(文件名以index结尾)保存了消息偏移量到物理位置的索引。如下图所示:

Broker中通过下一个偏移量元数据(nextOffsetMetaData),指定当前写入日志的消息的起始偏移值,在追加消息后,更新nextOffsetMetaData,作为下一批消息的起始偏移量。核心代码如下所示:
代码块
- @volatile **var** nextOffsetMetadata = **new** LogOffsetMetadata(activeSegment.nextOffset(),
-
- activeSegment.baseOffset, activeSegment.size.toInt);
-
- **def** append(messages:ByteBufferMessageSet, assignOffsets:Boolean) = {
-
- *//LogAppendInfo*对象,代表这批消息的概要信息,然后对消息进行验证
-
- **var** appendInfo = analyzeAndValidateMessageSet(messages)
-
- **var** validMessages = trimInvalidBytes(messages, appendInfo)
-
- *//* 获取最新的”下一个偏移量“作为第一条消息的绝对偏移量
-
- appendInfo.firstOffset = nextOffsetMetadata.messageOffset
-
- **if** (assignOffsets) { *//* 如果每条消息的偏移量都是递增的
-
- *//* 消息的起始偏移量来自于最新的”下一个偏移量“,而不是消息自带的顺序值
-
- **var** offset = **new** AtomicLong(nextOffsetMetadata.messageOffset);
-
- *//* 基于起始偏移量,为有效的消息集的每条消息重新分配绝对偏移量
-
- validMessages = validMessages.validateMessagesAndAssignOffsets(offset);
-
- appendInfo.lastOffset = offset.get - 1 *//* 最后一条消息的绝对偏移量
-
- }
-
- **var** segment = maybeRoll(validMessages.sizeInBytes) *//* 如果达到*Segment*大小的阈值,需要创建新的*Segment*
-
- segment.append(appendInfo.firstOffset,validMessages) *//* 追加消息到当前分段
-
- updateLogEndOffset(appendInfo.lastOffset + 1) *//* 修改最新的”下一个偏移量“
-
- **if** (unflushedMessages >= config.flushInterval) {
-
- flush() *//* 如果没有刷新的消息数大于配置的,那么将消息刷入到磁盘
-
- }
-
- }
-
- *//* 更新日志的”最近的偏移量“,传入的参数一般是最后一条消息的偏移量加上*1*
-
- *//* 使用发需要获取日志的”最近的量“时,就不需要再做加一的操作了
-
- **private** **def** updateLogEndOffset(messageOffset:Long) {
-
- nextOffsetMetadata = **new** LogOffsetMetadata(messageOffset, activeSegment.baseOffset,activeSegment.size.toInt)
-
- }

nextOffsetMetaData的读写操作发生在持久化和读取消息中,具体流程如下所示:
1、Producer发送消息集到Broker,Broker将这一批消息追加到日志;
2、每条消息需要指定绝对偏移量,Broker会用nextOffsetMetaData的值作为起始偏移值;
3、Broker将每条带有偏移量的消息写入到日志分段中;
4、Broker获取这一批消息中最后一条消息的偏移量,加1后更新nextOffsetMetaData;
5、Consumer根据这个变量的最新值拉取消息。一旦这个值发生变化,Consumer就能拉取到新写入的消息。
由于写入到日志分段中的消息集,都是以nextOffsetMetaData作为起始的绝对偏移量。因为这个起始偏移量总是递增,所以每一批消息的偏移量也保持递增,而且每一个Partition的所有日志分段中,所有消息的偏移量都是递增。如下图所示,新创建日志分段的基准偏移量,比之前的分段的基准偏移量要大,同一个日志分段中,新消息的偏移量也比之前消息的偏移量要大。
建立索引文件的目的:快速定位指定偏移量消息在数据文件中的物理位置。其中索引文件保存的是一部分消息的相对偏移量到物理位置的映射,使用相对偏移量而不是绝对偏移量是为了节约内存。
2.3 Page Cache
Kafka 用到了 Page Cache 技术,简单理解就是:利用了操作系统本身的缓存技术,在读写磁盘日志文件时,其实操作的都是内存,然后由操作系统决定什么时候将 Page Cache 里的数据真正刷入磁盘。
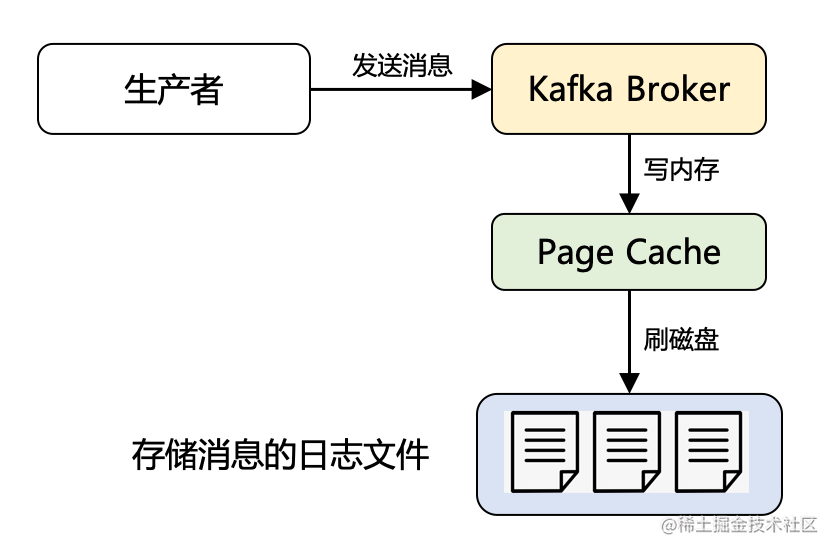
Page Cache 缓存的是最近会被使用的磁盘数据,利用的是「时间局部性」原理,依据是:最近访问的数据很可能接下来再访问到。而预读到 Page Cache 中的磁盘数据,又利用了「空间局部性」原理,依据是:数据往往是连续访问的。
而 Kafka 作为消息队列,消息先是顺序写入,而且立马又会被消费者读取到,无疑非常契合上述两条局部性原理。因此,页缓存可以说是 Kafka 做到高吞吐的重要因素之一。
除此之外,页缓存还有一个巨大的优势。用过 Java 的人都知道:如果不用页缓存,而是用 JVM 进程中的缓存,对象的内存开销非常大(通常是真实数据大小的几倍甚至更多),此外还需要进行垃圾回收,GC 所带来的 Stop The World 问题也会带来性能问题。可见,页缓存确实优势明显,而且极大地简化了 Kafka 的代码实现。
3. 消费消息高性能
3.1 基于索引文件的查询
Kafka通过索引文件提高对磁盘上消息的查询效率。
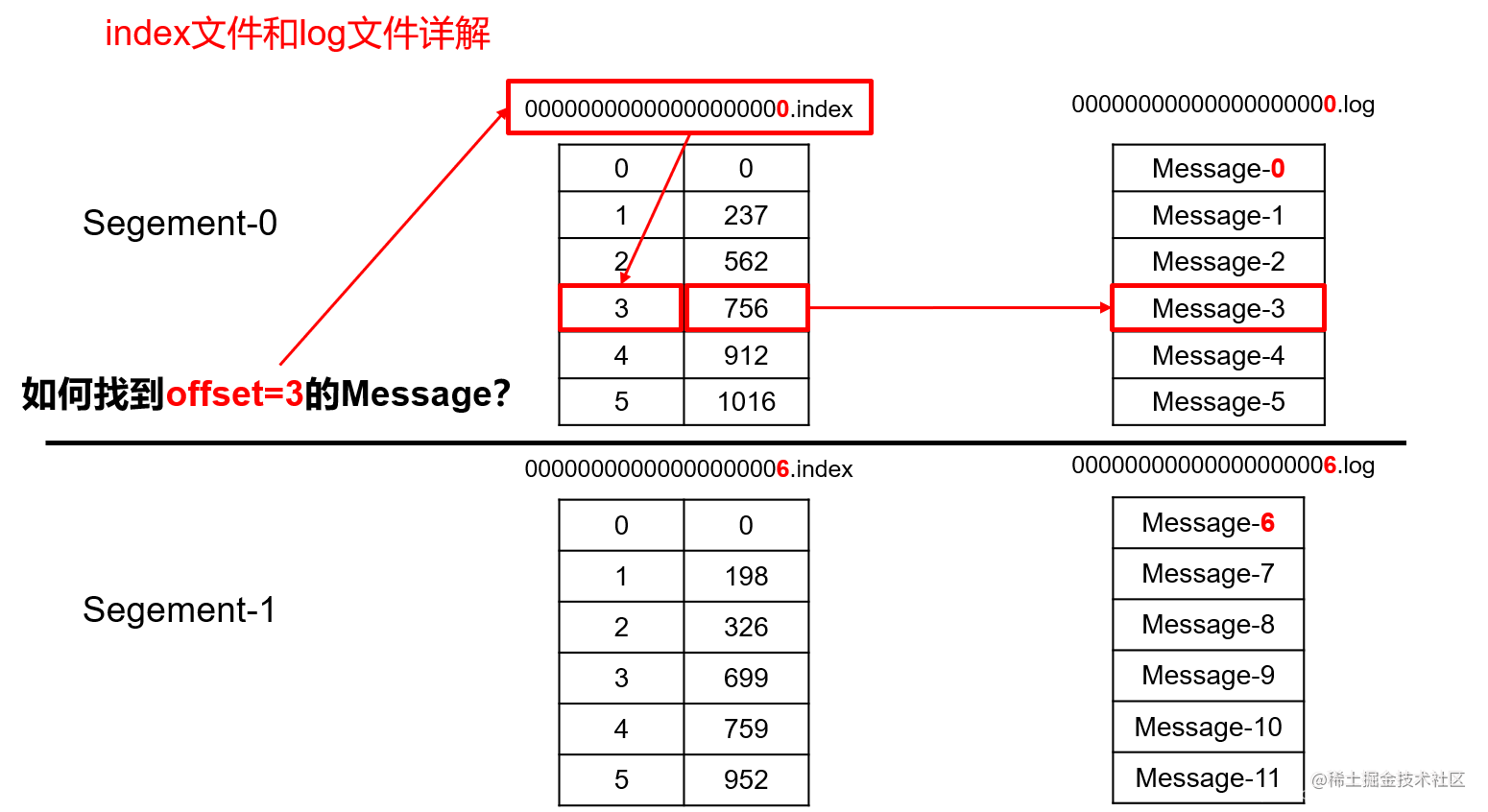
如何通过offset找到对应消息
1. 先找到 offset=3 的 message 所在的 segment文件(利用二分法查找),先判断.index文件名称offset(baseOffset )是否小于3;
• 若小于,则继续二分与下一个.inde文件名称offset比较;
• 若大于,则返回上次小于3的.index文件,这里找到的就是在第一个segment文件。
2. 找到的 segment 中的.index文件,用查找的offset减去.index文件名的offset,也就是00000.index文件,我们要查找的offset为3的message在该.index文件内的索引为3(index采用稀疏存储的方式,它不会为每一条message都建立索引,而是每隔4k左右,建立一条索引,避免索引文件占用过多的空间。缺点是没有建立索引的offset不能一次定位到message的位置,需要做一次顺序扫描,但是扫描的范围很小)。
3. 根据找到的相对offset为3的索引,确定message存储的物理偏移地址为756。
4. 根据物理偏移地址,去.log文件找相应的Message
Kafka的索引文件的特性:
• 索引文件映射偏移量到文件的物理位置,它不会对每条消息都建立索引,所以是稀疏的。
• 索引条目的偏移量存储的是相对于“基准偏移量”的“相对偏移量” ,不是消息的“绝对偏移量” 。
• 偏移量是有序的,查询指定的偏移量时,使用二分查找可以快速确定偏移量的位置。
• 指定偏移量如果在索引文件中不存在,可以找到小于等于指定偏移量的最大偏移量。
• 稀疏索引可以通过内存映射方式,将整个索引文件都放入内存,加快偏移量的查询。
由于Broker是将消息持久化到当前日志的最后一个分段中,写入文件的方式是追加写,采用了对磁盘文件的顺序写。对磁盘的顺序写以及索引文件加快了Broker查询消息的速度。
3.2 mmap
注意:mmap 和 page cache 是两个概念,网上很多资料把它们混淆在一起。此外,还有资料谈到 Kafka 在读 log 文件时也用到了 mmap,通过对 2.8.0 版本的源码分析,这个信息也是错误的,其实只有索引文件的读写才用到了 mmap。
究竟如何理解 mmap?前面提到,常规的文件操作为了提高读写性能,使用了 Page Cache 机制,但是由于页缓存处在内核空间中,不能被用户进程直接寻址,所以读文件时还需要通过系统调用,将页缓存中的数据再次拷贝到用户空间中。
而采用 mmap 后,它将磁盘文件与进程虚拟地址做了映射,并不会招致系统调用,以及额外的内存 copy 开销,从而提高了文件读取效率。
至于为什么 log 文件不采用 mmap?这个问题社区并没有给出官方答案,网上的答案只能揣测作者的意图。个人比较认同 stackoverflow 上的这个答案:
mmap 有多少字节可以映射到内存中与地址空间有关,32 位的体系结构只能处理 4GB 甚至更小的文件。Kafka 日志通常足够大,可能一次只能映射部分,因此读取它们将变得非常复杂。然而,索引文件是稀疏的,它们相对较小。将它们映射到内存中可以加快查找过程,这是内存映射文件提供的主要好处。
3.3 零拷贝
Kafka中存在大量的网络数据持久化到磁盘(Producer到Broker)和磁盘文件通过网络发送(Broker到Consumer)的过程。这一过程的性能直接影响到Kafka的整体性能。Kafka采用零拷贝这一通用技术解决该问题。
零拷贝技术可以减少数据拷贝和共享总线操作的次数,消除传输数据在存储器之间不必要的中间拷贝次数,减少用户应用程序地址空间和操作系统内核地址空间之间因为上下文切换而带来的开销,从而有效地提高数据传输效率。
以将磁盘文件通过网络发送为例。下面展示了传统方式下读取数据后并通过网络发送所发生的数据拷贝:
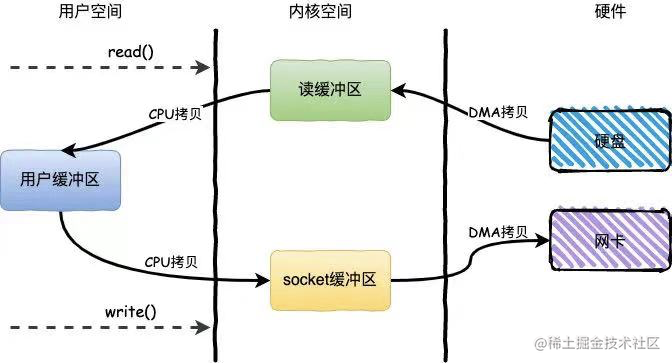
• 一个读操作发生后,DMA执行了一次数据拷贝,数据从磁盘拷贝到内核空间;
• cpu将数据从内核空间拷贝至用户空间
• 调用send(),cpu发生第三次数据拷贝,由cpu将数据从用户空间拷贝至内核空间(socket缓冲区)
• send()执行结束后,DMA执行第四次数据拷贝,将数据从内核拷贝至协议引擎
Linux 2.4+内核通过sendfile系统调用,提供了零拷贝。数据通过DMA拷贝到内核态Buffer后,直接通过DMA拷贝到NIC Buffer,无需CPU拷贝,这也是零拷贝这一说法的来源。除了减少数据拷贝外,因为整个读文件-网络发送由一个sendfile调用完成,整个过程只有两次上下文切换,没有cpu数据拷贝,因此大大提高了性能。零拷贝过程如下图所示。
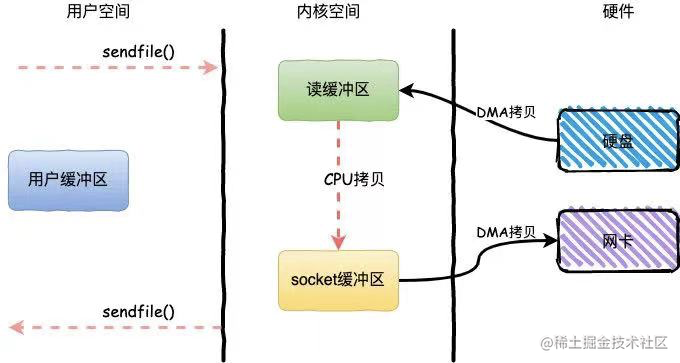
- sendfile()通过DMA将文件内容拷贝到一个读取缓冲区,然后由内核将数据拷贝到与输出套接字相关联的内核缓冲区。
从具体实现来看,Kafka的数据传输通过TransportLayer来完成,其子类PlaintextTransportLayer通过Java NIO的FileChannel的transferTo()和transferFrom()方法实现零拷贝。transferTo()和transferFrom()并不保证一定能使用零拷贝,实际上是否能使用零拷贝与操作系统相关,如果操作系统提供sendfile这样的零拷贝系统调用,则这两个方法会通过这样的系统调用充分利用零拷贝的优势,否则并不能通过这两个方法本身实现零拷贝。
3.4 批量拉取
和生产者批量发送消息类似,消息者也是批量拉取消息的,每次拉取一个消息集合,从而大大减少了网络传输的 overhead。
生产者其实在 Client 端对批量消息进行了压缩,这批消息持久化到 Broker 时,仍然保持的是压缩状态,最终在 Consumer 端再做解压缩操作。

