
- 1Unity:构建游戏和交互应用的强大引擎
- 2Android基于高德地图实现搜索框的自动输入提示功能_高德输入提示 visibility: visible;
- 3Stable Diffusion 模型下载:FenrisXL(芬里斯XL)
- 4qtablewidget限制输入类型_详解 | 威纶触摸屏数值输入元件应用
- 5十二周-分析类中成员的访问属性_(1)在main 函数中能否用 bl.i,bl.j和bl.引用派生类b对象bl中基类a的员?
- 6【docker镜像导入导出问题】Error response from daemon No command specified_docker-compose no command specified
- 7iOS 9的 Core Image新滤镜_ios ciareaaverage
- 8在Linux中,_exit()、exit(0)、exit(1)、和return的区别!!_exit(1);
- 9【LVI-SAM代码学习记录】
- 10vue+antd——实现折叠与展开组件——基础积累(组件封装)_vue3 antd垂直折叠
【kafka】Kafka 源码解析:Group 协调管理机制_kafka group
赞
踩

1.概述
在 Kafka 的设计中,消费者一般都有一个 group 的概念(当然,也存在不属于任何 group 的消费者),将多个消费者组织成一个 group 可以提升消息的消费处理能力,同时又能保证消息消费的顺序性,不重复或遗漏消费。一个 group 名下的消费者包含一个 leader 角色和多个 follower 角色,虽然在消费消息方面这两类角色是等价的,但是 leader 角色相对于 follower 角色还担负着管理整个 group 的职责。当 group 中有新的消费者加入,或者某个消费者因为一些原因退出当前 group 时,亦或是订阅的 topic 分区发生变化时,都需要为 group 名下的消费者重新分配分区,在服务端确定好分区分配策略之后,具体执行分区分配的工作则交由 leader 消费者负责,并在完成分区分配之后将分配结果反馈给服务端。
前面在分析消费者运行机制时曾多次提到 GroupCoordinator 类,本篇我们就来分析一下 GroupCoordinator 组件的作用和实现。GroupCoordinator 组件主要功能包括对隶属于同一个 group 的消费者进行分区分配、维护内部 offset topic,以及管理消费者和消费者所属的 group 信息等。集群中的每一个 broker 节点在启动时都会创建并启动一个 GroupCoordinator 实例,每个实例都会管理集群中所有消费者 group 的一个子集。
2.GroupCoordinator 组件的定义与启动
GroupCoordinator 类的字段定义如下:
class GroupCoordinator(
val brokerId: Int, // 所属的 broker 节点的 ID
val groupConfig: GroupConfig, // Group 配置对象,记录了 group 中 session 过期的最小时长和最大时长,即超时时长的合法区间
val offsetConfig: OffsetConfig, // 记录 OffsetMetadata 相关的配置项
val groupManager: GroupMetadataManager, // 负责管理 group 元数据以及对应的 offset 信息
val heartbeatPurgatory: DelayedOperationPurgatory[DelayedHeartbeat], // 管理 DelayedHeartbeat 延时任务的炼狱
val joinPurgatory: DelayedOperationPurgatory[DelayedJoin], // 管理 DelayedJoin 延时任务的炼狱
time: Time) extends Logging {
/** 标识当前 GroupCoordinator 实例是否启动 */
private val isActive = new AtomicBoolean(false)
// ... 省略方法定义
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
其中 GroupMetadataManager 类主要用于管理消费者 group 的元数据信息和 offset 相关信息,字段定义如下:
class GroupMetadataManager(val brokerId: Int, // 所属 broker 节点 ID val interBrokerProtocolVersion: ApiVersion, // kafka 版本信息 val config: OffsetConfig, // 记录 OffsetMetadata 相关的配置项 replicaManager: ReplicaManager, // 管理 broker 节点上 offset topic 的分区信息 zkUtils: ZkUtils, time: Time) extends Logging with KafkaMetricsGroup { /** 消息压缩类型 */ private val compressionType: CompressionType = CompressionType.forId(config.offsetsTopicCompressionCodec.codec) /** 缓存每个 group 在服务端对应的 GroupMetadata 对象 */ private val groupMetadataCache = new Pool[String, GroupMetadata] /** 正在加载的 offset topic 分区的 ID 集合 */ private val loadingPartitions: mutable.Set[Int] = mutable.Set() /** 已经加载完成的 offset topic 分区的 ID 集合 */ private val ownedPartitions: mutable.Set[Int] = mutable.Set() /** 标识 GroupCoordinator 正在关闭 */ private val shuttingDown = new AtomicBoolean(false) /** 记录 offset topic 的分区数目 */ private val groupMetadataTopicPartitionCount = getOffsetsTopicPartitionCount /** 用于调度 delete-expired-consumer-offsets 和 GroupCoordinator 迁移等任务 */ private val scheduler = new KafkaScheduler(threads = 1, threadNamePrefix = "group-metadata-manager-") // ... 省略方法定义 }

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
Kafka 服务在启动时针对每一个 broker 节点都会创建一个 GroupCoordinator 实例,并调用 GroupCoordinator#startup 方法启动运行。GroupCoordinator 在启动时主要是调用了 GroupMetadataManager#enableMetadataExpiration 方法启动 delete-expired-group-metadata 定时任务:
def startup(enableMetadataExpiration: Boolean = true) { info("Starting up.") if (enableMetadataExpiration) groupManager.enableMetadataExpiration() isActive.set(true) info("Startup complete.") } def enableMetadataExpiration() { // 启动定时任务调度器 scheduler.startup() // 启动 delete-expired-group-metadata 定时任务 scheduler.schedule(name = "delete-expired-group-metadata", fun = cleanupGroupMetadata, period = config.offsetsRetentionCheckIntervalMs, unit = TimeUnit.MILLISECONDS) }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
定时任务 delete-expired-group-metadata 的主要作用在于从 group 的元数据信息中移除那些已经过期的 topic 分区对应的 offset 元数据,并将这些元数据以消息的形式记录到 offset topic 中,具体执行流程如下:
- 依据当前时间戳计算并获取已经过期的 topic 分区对应的 offset 元数据信息;
- 将状态为 Empty 且名下记录的所有 offset 元数据都已经过期的 group 切换成 Dead 状态;
- 如果 group 已经失效,则从 GroupCoordinator 本地移除对应的元数据信息,并与步骤 1 中获取到的 offset 元数据信息一起封装成消息记录到 offset topic 中。
具体逻辑由 GroupMetadataManager#cleanupGroupMetadata 方法实现,如下:
private[coordinator] def cleanupGroupMetadata(): Unit = { this.cleanupGroupMetadata(None) } def cleanupGroupMetadata(deletedTopicPartitions: Option[Seq[TopicPartition]]) { val startMs = time.milliseconds() var offsetsRemoved = 0 // 遍历处理每个 group 对应的元数据信息 groupMetadataCache.foreach { case (groupId, group) => val (removedOffsets, groupIsDead, generation) = group synchronized { // 计算待移除的 topic 分区对应的 offset 元数据信息 val removedOffsets = deletedTopicPartitions match { // 从 group 元数据信息中移除指定的 topic 分区集合 case Some(topicPartitions) => group.removeOffsets(topicPartitions) // 移除那些 offset 元数据已经过期的,且没有 offset 待提交的 topic 分区集合 case None => group.removeExpiredOffsets(startMs) } // 如果 group 当前状态为 Empty,且名下 topic 分区所有的 offset 已经过期,则将该 group 状态切换成 Dead if (group.is(Empty) && !group.hasOffsets) { info(s"Group $groupId transitioned to Dead in generation ${group.generationId}") group.transitionTo(Dead) } (removedOffsets, group.is(Dead), group.generationId) } // 获取 group 对应在 offset topic 中的分区编号 val offsetsPartition = partitionFor(groupId) val appendPartition = new TopicPartition(Topic.GroupMetadataTopicName, offsetsPartition) getMagic(offsetsPartition) match { // 对应 group 由当前 GroupCoordinator 进行管理 case Some(magicValue) => val timestampType = TimestampType.CREATE_TIME val timestamp = time.milliseconds() // 获取当前 group 在 offset topic 中的分区对象 val partitionOpt = replicaManager.getPartition(appendPartition) partitionOpt.foreach { partition => // 遍历处理每个待移除的 topic 分区对应的 offset 元数据信息,封装成消息数据 val tombstones = removedOffsets.map { case (topicPartition, offsetAndMetadata) => trace(s"Removing expired/deleted offset and metadata for $groupId, $topicPartition: $offsetAndMetadata") val commitKey = GroupMetadataManager.offsetCommitKey(groupId, topicPartition) Record.create(magicValue, timestampType, timestamp, commitKey, null) }.toBuffer trace(s"Marked ${removedOffsets.size} offsets in $appendPartition for deletion.") // 如果当前 group 已经失效,则从本地移除对应的元数据信息,并将 group 信息封装成消息, // 如果 generation 为 0 则表示当前 group 仅仅使用 kafka 存储 offset 信息 if (groupIsDead && groupMetadataCache.remove(groupId, group) && generation > 0) { tombstones += Record.create(magicValue, timestampType, timestamp, GroupMetadataManager.groupMetadataKey(group.groupId), null) trace(s"Group $groupId removed from the metadata cache and marked for deletion in $appendPartition.") } if (tombstones.nonEmpty) { try { // 往 offset topic 中追加消息,不需要 ack,如果失败则周期性任务稍后会重试 partition.appendRecordsToLeader(MemoryRecords.withRecords(timestampType, compressionType, tombstones: _*)) offsetsRemoved += removedOffsets.size trace(s"Successfully appended ${tombstones.size} tombstones to $appendPartition for expired/deleted offsets and/or metadata for group $groupId") } catch { case t: Throwable => error(s"Failed to append ${tombstones.size} tombstones to $appendPartition for expired/deleted offsets and/or metadata for group $groupId.", t) } } } case None => info(s"BrokerId $brokerId is no longer a coordinator for the group $groupId. Proceeding cleanup for other alive groups") } } info(s"Removed $offsetsRemoved expired offsets in ${time.milliseconds() - startMs} milliseconds.") }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
3.Group 状态定义与转换
GroupState 特质定义了 group 的状态,并由 GroupCoordinator 进行维护。围绕 GroupState 特质,Kafka 实现了 5 个样例对象,分别用于描述 group 的 5 种状态:
PreparingRebalance:表示 group 正在准备执行分区再分配操作。AwaitingSync:表示 group 正在等待 leader 消费者的分区分配结果,新版本已更名为 CompletingRebalance。Stable:表示 group 处于正常运行状态。Dead:表示 group 名下已经没有消费者,且对应的元数据已经(或正在)被删除。Empty:表示 group 名下已经没有消费者,并且正在等待记录的所有 offset 元数据过期。
Group 状态之间的转换以及转换原因如下图和表所示:
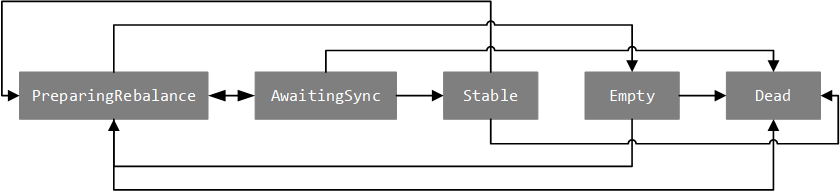
| 当前状态 | 目标状态 | 转换原因 |
|---|---|---|
| PreparingRebalance | AwaitingSync | group 之前名下所有的消费者都已经申请加入,或者等待消费者申请加入超时。 |
| PreparingRebalance | Empty | group 名下的所有消费者都已经离开。 |
| PreparingRebalance | Dead | group 对应的元数据信息被移除。 |
| AwaitingSync | Stable | group 收到来自 leader 消费者的分区分配结果。 |
| AwaitingSync | PreparingRebalance | 1. 有消费者申请加入或退出; 2. 名下消费者更新了元数据信息; 3. 名下消费者心跳超时。 |
| AwaitingSync | Dead | group 对应的元数据信息被移除。 |
| Stable | PreparingRebalance | 1. 有消费者申请加入或退出; 2. 名下消费者心跳超时。 |
| Stable | Dead | group 对应的元数据信息被移除。 |
| Empty | PreparingRebalance | 有消费者申请加入。 |
| Empty | Dead | 1. group 名下所有的 offset 元数据信息已经过期; 2. group 对应的元数据信息被移除。 |
| Dead | 无 |
4.故障转移机制
在 Kafka 0.8.2.2 版本中引入了使用 offset topic 存储消费 offset 位置数据,以解决之前版本中采用 ZK 存储所面临的性能压力和不稳定性,并由 GroupCoordinator 组件负责维护。Offset topic 与 Kafka 中的普通 topic 除了用途上的区别之外,在性质上没有任何区别,Kafka 默认为 offset topic 设置了 50 个分区,每个分区分配 3 个副本。当某个 broker 节点宕机时,如果该节点上正好运行着 offset topic 某个分区的 leader 副本,考虑服务可用性需要选举一个位于其它可用 broker 节点上的满足条件的 follower 副本作为新的 leader 副本,同时由位于该 broker 节点上的 GroupCoordinator 实例继续维护对应的 offset topic 分区。因为涉及到 GroupCoordinator 实例的变更,所以需要在新的 GroupCoordinator 实例接管维护这些 offset topic 分区时,需要在这些 GroupCoordinator 实例上恢复对应 group 的元数据信息(一个 offset topic 分区中记录了一批 group 的元数据和 offset 消费数据)。
之前的文章在分析 Kafka 的分区副本机制时曾介绍了对 LeaderAndIsrRequest 请求的处理,ReplicaManager 定义了 ReplicaManager#becomeLeaderOrFollower 方法用于对指定 topic 分区的副本执行角色切换。该方法接收一个 (Iterable[Partition], Iterable[Partition]) => Unit 类型的回调函数,用于分别处理完成 leader 角色和 follower 角色切换的分区对象集合,回调函数的具体定义位于 KafkaApis#handleLeaderAndIsrRequest 方法中,实现如下:
// 完成 GroupCoordinator 的迁移操作
def onLeadershipChange(updatedLeaders: Iterable[Partition], updatedFollowers: Iterable[Partition]) {
updatedLeaders.foreach { partition =>
// 仅处理 offset topic,当 broker 节点维护 offset topic 分区的 leader 副本时回调执行
if (partition.topic == Topic.GroupMetadataTopicName) coordinator.handleGroupImmigration(partition.partitionId)
}
updatedFollowers.foreach { partition =>
// 仅处理 offset topic,当 broker 节点维护 offset topic 分区的 follower 副本时回调执行
if (partition.topic == Topic.GroupMetadataTopicName) coordinator.handleGroupEmigration(partition.partitionId)
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
由上述实现可以看到该回调函数仅处理 offset topic 对应的分区,当 GroupCoordinator 实例开始维护 offset topic 某个分区的 leader 副本时会触发执行 GroupCoordinator#handleGroupImmigration 方法,而当 GroupCoordinator 实例开始维护 offset topic 某个分区的 follower 副本时会触发执行 GroupCoordinator#handleGroupEmigration 方法,下面分别对这两个方法的实现进行分析。
方法 GroupCoordinator#handleGroupImmigration 的实现如下:
def handleGroupImmigration(offsetTopicPartitionId: Int) {
groupManager.loadGroupsForPartition(offsetTopicPartitionId, onGroupLoaded)
}
private def onGroupLoaded(group: GroupMetadata) {
group synchronized {
info(s"Loading group metadata for ${group.groupId} with generation ${group.generationId}")
assert(group.is(Stable) || group.is(Empty))
// 遍历更新当前 group 名下所有消费者的心跳信息
group.allMemberMetadata.foreach(completeAndScheduleNextHeartbeatExpiration(group, _))
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
关于 GroupCoordinator#completeAndScheduleNextHeartbeatExpiration 方法的执行逻辑我们将在下一小节进行分析,这里我们主要来看一下 GroupMetadataManager#loadGroupsForPartition 方法的实现,该方法会基于 offset topic 更新对应 group 的元数据,并初始化每个 topic 分区对应的 offset 信息:
def loadGroupsForPartition(offsetsPartition: Int, onGroupLoaded: GroupMetadata => Unit) { // 构建 offset topic 对应的 topic 分区对象 val topicPartition = new TopicPartition(Topic.GroupMetadataTopicName, offsetsPartition) def doLoadGroupsAndOffsets() { info(s"Loading offsets and group metadata from $topicPartition") inLock(partitionLock) { // 检测当前 offset topic 分区是否正在加载,如果已经处于加载中则返回 if (loadingPartitions.contains(offsetsPartition)) { info(s"Offset load from $topicPartition already in progress.") return } else { loadingPartitions.add(offsetsPartition) } } try { // 基于 offset topic 加载更新对应 group 的元数据信息,初始化每个 topic 分区对应的 offset 信息 this.loadGroupsAndOffsets(topicPartition, onGroupLoaded) } catch { case t: Throwable => error(s"Error loading offsets from $topicPartition", t) } finally { inLock(partitionLock) { ownedPartitions.add(offsetsPartition) loadingPartitions.remove(offsetsPartition) } } } // 异步调度执行 scheduler.schedule(topicPartition.toString, doLoadGroupsAndOffsets) }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
具体加载更新的过程采用异步调度的策略执行,实现位于 GroupMetadataManager#loadGroupsAndOffsets 方法中,该方法会读取对应 topic 分区下的所有消息数据,并依据消息的类型分别处理:
private[coordinator] def loadGroupsAndOffsets(topicPartition: TopicPartition, onGroupLoaded: GroupMetadata => Unit) { // 获取指定 topic 分区的 HW 值 def highWaterMark: Long = replicaManager.getHighWatermark(topicPartition).getOrElse(-1L) val startMs = time.milliseconds() // 获取并处理 topic 分区对应的 Log 对象 replicaManager.getLog(topicPartition) match { case None => // 不存在 warn(s"Attempted to load offsets and group metadata from $topicPartition, but found no log") case Some(log) => var currOffset = log.logStartOffset val buffer = ByteBuffer.allocate(config.loadBufferSize) // 记录 topic 分区与对应的 offset 信息映射关系 val loadedOffsets = mutable.Map[GroupTopicPartition, OffsetAndMetadata]() val removedOffsets = mutable.Set[GroupTopicPartition]() // 记录 group 与对应的 group 元数据信息映射关系 val loadedGroups = mutable.Map[String, GroupMetadata]() val removedGroups = mutable.Set[String]() // 从 Log 对象中第一个 LogSegment 开始读取日志数据,直到 HW 位置为止, // 加载 offset 信息和 group 元数据信息 while (currOffset < highWaterMark && !shuttingDown.get()) { buffer.clear() // 读取日志数据到内存 val fileRecords = log .read(currOffset, config.loadBufferSize, maxOffset = None, minOneMessage = true) .records.asInstanceOf[FileRecords] val bufferRead = fileRecords.readInto(buffer, 0) // 遍历处理消息集合(深层迭代) MemoryRecords.readableRecords(bufferRead).deepEntries.asScala.foreach { entry => val record = entry.record require(record.hasKey, "Group metadata/offset entry key should not be null") // 依据消息的 key 决定当前消息的类型 GroupMetadataManager.readMessageKey(record.key) match { // 如果是记录 offset 的消息 case offsetKey: OffsetKey => val key = offsetKey.key if (record.hasNullValue) { // 删除标记,则移除对应的 offset 信息 loadedOffsets.remove(key) removedOffsets.add(key) } else { // 非删除标记,解析并更新 key 对应 offset 信息 val value = GroupMetadataManager.readOffsetMessageValue(record.value) loadedOffsets.put(key, value) removedOffsets.remove(key) } // 如果是记录 group 元数据的消息 case groupMetadataKey: GroupMetadataKey => val groupId = groupMetadataKey.key val groupMetadata = GroupMetadataManager.readGroupMessageValue(groupId, record.value) if (groupMetadata != null) { // 非删除标记,记录加载的 group 元数据信息 trace(s"Loaded group metadata for group $groupId with generation ${groupMetadata.generationId}") removedGroups.remove(groupId) loadedGroups.put(groupId, groupMetadata) } else { // 删除标记 loadedGroups.remove(groupId) removedGroups.add(groupId) } // 未知的消息 key 类型 case unknownKey => throw new IllegalStateException(s"Unexpected message key $unknownKey while loading offsets and group metadata") } currOffset = entry.nextOffset } } // 将在 offset topic 中存在 offset 信息的 topic 分区以是否在 offset topic 中包含 group 元数据信息进行区分 val (groupOffsets, emptyGroupOffsets) = loadedOffsets .groupBy(_._1.group) .mapValues(_.map { case (groupTopicPartition, offset) => (groupTopicPartition.topicPartition, offset) }) .partition { case (group, _) => loadedGroups.contains(group) } // 遍历处理在 offset topic 中存在 group 元数据信息的 group loadedGroups.values.foreach { group => val offsets = groupOffsets.getOrElse(group.groupId, Map.empty[TopicPartition, OffsetAndMetadata]) // 更新 group 对应的元数据信息,主要是更新名下每个 topic 分区对应的 offset 信息 loadGroup(group, offsets) onGroupLoaded(group) } // 遍历处理在 offset topic 中不存在 group 元数据信息的 group,但是存在 offset 信息,新建一个 emptyGroupOffsets.foreach { case (groupId, offsets) => val group = new GroupMetadata(groupId) // 更新 group 对应的元数据信息,主要是更新名下每个 topic 分区对应的 offset 信息 loadGroup(group, offsets) onGroupLoaded(group) } // 检测需要删除的 group 元数据信息,如果对应 group 在本地有记录且在 offset topic 中存在 offset 信息, // 则不应该删除,此类 group 一般仅依赖 kafka 存储 offset 信息,而不存储对应的 group 元数据信息 removedGroups.foreach { groupId => if (groupMetadataCache.contains(groupId) && !emptyGroupOffsets.contains(groupId)) throw new IllegalStateException(s"Unexpected unload of active group $groupId while loading partition $topicPartition") } } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106
Offset topic 中主要记录了 group 的元数据和对应的 offset 的消费位置信息,上述方法会分别解析这两类数据并据此来恢复 GroupCoordinator 本地记录的对应 group 的元数据信息。如果 offset topic 中包含对应 group 的元数据信息则恢复时会直接复用,否则会创建一个空的 GroupMetadata 对象(这类 group 一般仅使用 Kafka 存储 offset 位置数据),并应用 GroupMetadataManager#loadGroup 方法更新 group 名下每个 topic 分区的 offset 值,同时将 group 元数据记录到 GroupCoordinator 本地缓存中:
private def loadGroup(group: GroupMetadata, offsets: Map[TopicPartition, OffsetAndMetadata]): Unit = { // 遍历处理每个 topic 分区的 offset 信息,兼容更新老版本的过期时间 val loadedOffsets = offsets.mapValues { offsetAndMetadata => // 对应老版本的 offset 元数据,设置过期时间戳为 commit 时间加上系统默认的保留时间(默认为 24 小时) if (offsetAndMetadata.expireTimestamp == OffsetCommitRequest.DEFAULT_TIMESTAMP) offsetAndMetadata.copy(expireTimestamp = offsetAndMetadata.commitTimestamp + config.offsetsRetentionMs) else offsetAndMetadata } trace(s"Initialized offsets $loadedOffsets for group ${group.groupId}") // 更新 group 名下每个 topic 分区的 offset 信息 group.initializeOffsets(loadedOffsets) // 更新 group 对应的元数据信息 val currentGroup = this.addGroup(group) if (group != currentGroup) debug(s"Attempt to load group ${group.groupId} from log with generation ${group.generationId} failed because there is already a cached group with generation ${currentGroup.generationId}") }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
下面继续来看 GroupCoordinator 实例开始维护 offset topic 某个分区的 follower 副本的执行逻辑,实现位于 GroupCoordinator#handleGroupEmigration 方法中:
def handleGroupEmigration(offsetTopicPartitionId: Int) { groupManager.removeGroupsForPartition(offsetTopicPartitionId, onGroupUnloaded) } private def onGroupUnloaded(group: GroupMetadata) { group synchronized { info(s"Unloading group metadata for ${group.groupId} with generation ${group.generationId}") val previousState = group.currentState // 将当前 group 切换成 Dead 状态 group.transitionTo(Dead) // 依据前置状态分别处理 previousState match { case Empty | Dead => case PreparingRebalance => // 遍历响应所有消费者的 JoinGroupRequest 请求,返回 NOT_COORDINATOR_FOR_GROUP 错误码 for (member <- group.allMemberMetadata) { if (member.awaitingJoinCallback != null) { member.awaitingJoinCallback(joinError(member.memberId, Errors.NOT_COORDINATOR_FOR_GROUP.code)) member.awaitingJoinCallback = null } } // 尝试执行 DelayedJoin 延时任务 joinPurgatory.checkAndComplete(GroupKey(group.groupId)) case Stable | AwaitingSync => // 遍历响应所有消费者的 JoinGroupRequest 请求,返回 NOT_COORDINATOR_FOR_GROUP 错误码 for (member <- group.allMemberMetadata) { if (member.awaitingSyncCallback != null) { member.awaitingSyncCallback(Array.empty[Byte], Errors.NOT_COORDINATOR_FOR_GROUP.code) member.awaitingSyncCallback = null } // 尝试执行 DelayHeartbeat 延时任务 heartbeatPurgatory.checkAndComplete(MemberKey(member.groupId, member.memberId)) } } } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
当 GroupCoordinator 不再管理相应的 group 时,会将本地记录的 group 状态切换成 Dead,同时针对来自该 group 名下消费者的 JoinGroupRequest 请求均会响应 NOT_COORDINATOR_FOR_GROUP 错误。此外,还会从本地移除之前管理的 offset topic 分区对象,以及对应的 group 元数据信息,实现如下:
def removeGroupsForPartition(offsetsPartition: Int, onGroupUnloaded: GroupMetadata => Unit) { // 构建 offset topic 对应的 topic 分区对象 val topicPartition = new TopicPartition(Topic.GroupMetadataTopicName, offsetsPartition) // 异步调度执行 scheduler.schedule(topicPartition.toString, removeGroupsAndOffsets) def removeGroupsAndOffsets() { var numOffsetsRemoved = 0 var numGroupsRemoved = 0 inLock(partitionLock) { // 从已经加载完成的 offset topic 分区集合中移除指定的分区,表示当前 GroupCoordinator 实例不再管理对应的 group ownedPartitions.remove(offsetsPartition) // 遍历移除本地缓存的 group 对应的元数据信息 for (group <- groupMetadataCache.values) { if (partitionFor(group.groupId) == offsetsPartition) { onGroupUnloaded(group) groupMetadataCache.remove(group.groupId, group) numGroupsRemoved += 1 numOffsetsRemoved += group.numOffsets } } } } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
5.心跳报活机制
消费者依赖于心跳机制向 GroupCoordinator 报活,向对应的 GroupCoordinator 实例发送 HeartbeatRequest 请求,GroupCoordinator 实例同样依赖于消费者的心跳来判断消费者的上下线。KafkaApis 定义了 KafkaApis#handleHeartbeatRequest 方法处理 HeartbeatRequest 请求,具体的处理逻辑则委托给 GroupCoordinator#handleHeartbeat 方法执行,该方法首先会校验目标 GroupCoordinator 实例是合法且能够处理当前请求,然后依据目标 group 的状态对本次心跳请求进行处理。只有当目标 group 处于 PreparingRebalance 或 Stable 状态时,且当前消费者确实属于该 group 才能够正常响应请求,对于处于其它状态的 group 而言只是简单返回对应的错误码。
正常响应 HeartbeatRequest 请求的逻辑位于 GroupCoordinator#completeAndScheduleNextHeartbeatExpiration 方法中,实现如下:
private def completeAndScheduleNextHeartbeatExpiration(group: GroupMetadata, member: MemberMetadata) {
// 更新对应消费者的心跳时间
member.latestHeartbeat = time.milliseconds()
// 获取 DelayedHeartbeat 延时任务关注的消费者
val memberKey = MemberKey(member.groupId, member.memberId)
// 尝试完成之前添加的 DelayedHeartbeat 延时任务
heartbeatPurgatory.checkAndComplete(memberKey)
// 计算下一次的心跳超时时间
val newHeartbeatDeadline = member.latestHeartbeat + member.sessionTimeoutMs
// 创建新的 DelayedHeartbeat 延时任务,并添加到炼狱中进行管理
val delayedHeartbeat = new DelayedHeartbeat(this, group, member, newHeartbeatDeadline, member.sessionTimeoutMs)
heartbeatPurgatory.tryCompleteElseWatch(delayedHeartbeat, Seq(memberKey))
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
对于 HeartbeatRequest 请求的正常响应会更新当前消费者的最近一次心跳时间,并尝试完成关注该消费者的 DelayedHeartbeat 延时任务,同时创建新的 DelayedHeartbeat 延时任务,延迟时间为下次心跳超时时间。在整个 GroupCoordinator 实现中有多个地方调用了上述方法,这也意味着心跳机制不单单依赖于 HeartbeatRequest 请求,实际上只要是消费者发往 GroupCoordinator 的请求都可以携带心跳信息,例如 JoinGroupRequest、SyncGroupRequest,以及 OffsetCommitRequest 等等。
下面来看一下延时任务 DelayedHeartbeat 的实现,重点看一下 DelayedHeartbeat#tryComplete 方法和 DelayedHeartbeat#onExpiration 方法,这两个方法分别调用了 GroupCoordinator#tryCompleteHeartbeat 和 GroupCoordinator#onExpireHeartbeat 方法,而 DelayedHeartbeat#onComplete 方法则是一个空实现,也就是说延时任务 DelayedHeartbeat 的真正执行逻辑就是从炼狱中删除该延时任务,这也符合心跳机制的目的,正常的心跳无需多做处理,只有在消费者的心跳超时时才需要处理相关异常的情况。
方法 GroupCoordinator#tryCompleteHeartbeat 会检测当前消费者的状态,如果满足以下 3 个条件之一则强制执行 DelayedHeartbeat 延时任务,表示对应消费者心跳正常:
- 消费者正在等待 JoinGroupResponse 或 SyncGroupResponse 响应。
- 消费者最近一次心跳时间距离延时任务到期时间在消费者会话超时时间范围内。
- 消费者已经离开之前所属的 group。
方法 GroupCoordinator#onExpireHeartbeat 会检测当前消费者是否已经离线,如果是则依据所属 group 的当前状态执行:
- 如果目标 group 已经失效(Dead/Empty),则什么也不做;
- 如果目标 group 处于
正常运行状态(Stable),或者正在等待 leader 消费者的分区分配结果(AwaitingSync),则因当前消费者的下线可能导致之前的分区分配结果已经失效,所以需要重新分配分区; - 如果目标 group 处于
准备执行分区再分配状态(PreparingRebalance),则无需请求再次重新分配分区,但是因为当前消费者的下线,可能让关注目标 group 的 DelayedJoin 延时任务满足执行条件,所以尝试执行。
具体逻辑实现位于 GroupCoordinator#onMemberFailure 方法中,实现如下:
private def onMemberFailure(group: GroupMetadata, member: MemberMetadata) {
trace("Member %s in group %s has failed".format(member.memberId, group.groupId))
// 将对应的消费者从 GroupMetadata 中删除
group.remove(member.memberId)
group.currentState match {
// 对应 group 已经失效,什么也不做
case Dead | Empty =>
// 之前的分区分配结果可能已经失效,切换 GroupMetadata 状态为 PreparingRebalance,准备再次重新分配分区
case Stable | AwaitingSync => this.maybePrepareRebalance(group)
// 某个消费者下线,可能满足关注该 group 的 DelayedJoin 的执行条件,尝试执行
case PreparingRebalance => joinPurgatory.checkAndComplete(GroupKey(group.groupId))
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
其中 GroupCoordinator#maybePrepareRebalance 方法的执行逻辑将在下一小节介绍分区再分配机制时进行分析。
6.分区再分配机制
前面在分析消费者运行机制时,我们曾站在消费者的视角分析了分区再分配机制的执行过程,本小节我们继续从服务端的视角介绍集群对分区再分配操作过程中涉及到的来自消费者的请求的处理细节,主要包括 GroupCoordinatorRequest、JoinGroupResult 和 SyncGroupRequest 这 3 个请求。

上述时序图描绘了分区再分配期间客户端与服务端的交互过程。
6.1 GroupCoordinatorRequest 请求处理
当消费者与 GroupCoordinator 进行交互之前,需要先发送 GroupCoordinatorRequest 请求到负载较小的 broker 节点,以获取管理当前 group 的 GroupCoordinator 实例所在的 broker 节点的位置信息。KafkaApis 提供了 KafkaApis#handleGroupCoordinatorRequest 方法用于处理 GroupCoordinatorRequest 请求,方法实现如下:
def handleGroupCoordinatorRequest(request: RequestChannel.Request) { val groupCoordinatorRequest = request.body.asInstanceOf[GroupCoordinatorRequest] // 权限验证 if (!authorize(request.session, Describe, new Resource(Group, groupCoordinatorRequest.groupId))) { val responseBody = new GroupCoordinatorResponse(Errors.GROUP_AUTHORIZATION_FAILED.code, Node.noNode) requestChannel.sendResponse(new RequestChannel.Response(request, responseBody)) } else { // 获取 group 对应的 offset topic 的分区 ID val partition = coordinator.partitionFor(groupCoordinatorRequest.groupId) // 从 MetadataCache 中获取 offset topic 的相关信息,如果未创建则进行创建 val offsetsTopicMetadata = this.getOrCreateGroupMetadataTopic(request.listenerName) val responseBody = if (offsetsTopicMetadata.error != Errors.NONE) { // 创建 offset topic 信息失败 new GroupCoordinatorResponse(Errors.GROUP_COORDINATOR_NOT_AVAILABLE.code, Node.noNode) } else { // 获取当前 group 对应 offset topic 分区 leader 副本所在的节点 val coordinatorEndpoint = offsetsTopicMetadata.partitionMetadata().asScala .find(_.partition == partition) .map(_.leader()) // 创建 GroupCoordinatorResponse 对象,将 leader 副本所在节点信息返回给客户端 coordinatorEndpoint match { case Some(endpoint) if !endpoint.isEmpty => new GroupCoordinatorResponse(Errors.NONE.code, endpoint) case _ => new GroupCoordinatorResponse(Errors.GROUP_COORDINATOR_NOT_AVAILABLE.code, Node.noNode) } } trace("Sending consumer metadata %s for correlation id %d to client %s.".format(responseBody, request.header.correlationId, request.header.clientId)) // 将响应对象加入到 channel 中,等待发送 requestChannel.sendResponse(new RequestChannel.Response(request, responseBody)) } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
Kafka 会依据请求的 group 的 ID 查找对应 offset topic 分区 leader 副本所在的 broker 节点,并将节点信息封装成 GroupCoordinatorResponse 响应发送给消费者。接下来消费者会向对应的 broker 节点建立连接并发送 JoinGroupRequest 请求申请加入对应的 group。
6.2 JoinGroupRequest 请求处理
针对来自消费者申请加入指定 group 的 JoinGroupRequest 请求,GroupCoordinator 实例会为 group 中的消费者确定最终的分区分配策略,并选举新的 group leader 消费者。KafkaApis 定义了 KafkaApis#handleJoinGroupRequest 方法处理 JoinGroupRequest 请求,不过该方法只是简单解析了请求对象,并执行权限校验,以及定义了回调函数用于向客户端发送 JoinGroupResponse 响应,具体处理请求的过程则交由 GroupCoordinator#handleJoinGroup 方法实现:
def handleJoinGroup(groupId: String, memberId: String, clientId: String, clientHost: String, rebalanceTimeoutMs: Int, sessionTimeoutMs: Int, protocolType: String, protocols: List[(String, Array[Byte])], responseCallback: JoinCallback) { if (!isActive.get) { // GroupCoordinator 实例未启动 responseCallback(joinError(memberId, Errors.GROUP_COORDINATOR_NOT_AVAILABLE.code)) } else if (!validGroupId(groupId)) { // groupId 不合法 responseCallback(joinError(memberId, Errors.INVALID_GROUP_ID.code)) } else if (!isCoordinatorForGroup(groupId)) { // 当前 GroupCoordinator 实例并不负责管理当前 group responseCallback(joinError(memberId, Errors.NOT_COORDINATOR_FOR_GROUP.code)) } else if (isCoordinatorLoadingInProgress(groupId)) { // 当前 GroupCoordinator 实例正在加载该 group 对应的 offset topic 分区信息 responseCallback(joinError(memberId, Errors.GROUP_LOAD_IN_PROGRESS.code)) } else if (sessionTimeoutMs < groupConfig.groupMinSessionTimeoutMs || sessionTimeoutMs > groupConfig.groupMaxSessionTimeoutMs) { // 会话时长超时,保证消费者是活跃的 responseCallback(joinError(memberId, Errors.INVALID_SESSION_TIMEOUT.code)) } else { // 获取并处理 group 对应的元数据信息 groupManager.getGroup(groupId) match { // 对应的 group 不存在 case None => if (memberId != JoinGroupRequest.UNKNOWN_MEMBER_ID) { // 指定了消费者 ID,但是对应的 group 不存在,则拒绝请求 responseCallback(joinError(memberId, Errors.UNKNOWN_MEMBER_ID.code)) } else { // group 不存在,且消费者 ID 未知的情况下,创建 GroupMetadata 对象,并将消费者加入到对应的 group,同时执行分区再均衡操作 val group = groupManager.addGroup(new GroupMetadata(groupId)) this.doJoinGroup(group, memberId, clientId, clientHost, rebalanceTimeoutMs, sessionTimeoutMs, protocolType, protocols, responseCallback) } // 对应的 group 存在,将消费者加入到对应的 group,并执行分区再均衡操作 case Some(group) => this.doJoinGroup(group, memberId, clientId, clientHost, rebalanceTimeoutMs, sessionTimeoutMs, protocolType, protocols, responseCallback) } } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
GroupCoordinator 实例在具体处理 JoinGroupRequest 请求之前,首先会执行一系列的校验操作以保证发送请求的消费者和目标 group 都是合法的,且对应的 GroupCoordinator 能够正常处理当前请求。如果目标 group 不存在,则在未指定对应的消费者 ID 时会首先新建 group,然后将当前消费者添加到对应 group 中开始执行分区再分配操作。方法 GroupCoordinator#doJoinGroup 会校验消费者 ID (如果指定的话)能否被当前 group 识别,以及消费者指定的分区分配策略能否被当前 group 支持,如果这些条件都不能满足,则没有必要再继续为该消费者分配分区,方法实现如下:
private def doJoinGroup(group: GroupMetadata, memberId: String, clientId: String, clientHost: String, rebalanceTimeoutMs: Int, sessionTimeoutMs: Int, protocolType: String, protocols: List[(String, Array[Byte])], responseCallback: JoinCallback) { group synchronized { if (!group.is(Empty) // 消费者指定的分区分配策略,对应的 group 不支持 && (group.protocolType != Some(protocolType) || !group.supportsProtocols(protocols.map(_._1).toSet))) { responseCallback(joinError(memberId, Errors.INCONSISTENT_GROUP_PROTOCOL.code)) } else if (memberId != JoinGroupRequest.UNKNOWN_MEMBER_ID && !group.has(memberId)) { // 消费者 ID 不能够被识别 responseCallback(joinError(memberId, Errors.UNKNOWN_MEMBER_ID.code)) } else { // 依据 group 的当前状态分别进行处理 group.currentState match { // 目标 group 已经失效 case Dead => // 对应的 group 的元数据信息已经被删除,说明已经迁移到其它 GroupCoordinator 实例或者不再可用,直接返回错误码 responseCallback(joinError(memberId, Errors.UNKNOWN_MEMBER_ID.code)) // 目标 group 正在执行分区再均衡操作 case PreparingRebalance => if (memberId == JoinGroupRequest.UNKNOWN_MEMBER_ID) { // 对于未知 ID 的消费者申请加入,创建对应的元数据信息,并分配 ID,同时切换 group 的状态为 PreparingRebalance,准备执行分区再分配 this.addMemberAndRebalance(rebalanceTimeoutMs, sessionTimeoutMs, clientId, clientHost, protocolType, protocols, group, responseCallback) } else { // 对于已知 ID 的消费者重新申请加入,更新对应的元数据信息,同时切换 group 的状态为 PreparingRebalance,准备执行分区再分配 val member = group.get(memberId) this.updateMemberAndRebalance(group, member, protocols, responseCallback) } // 目标 group 正在等待 leader 消费者的分区分配结果 case AwaitingSync => if (memberId == JoinGroupRequest.UNKNOWN_MEMBER_ID) { // 对于未知 ID 的消费者申请加入,创建对应的元数据信息,并分配 ID,同时切换 group 的状态为 PreparingRebalance,准备执行分区再分配 this.addMemberAndRebalance(rebalanceTimeoutMs, sessionTimeoutMs, clientId, clientHost, protocolType, protocols, group, responseCallback) } else { // 对于已知 ID 的消费者重新申请加入 val member = group.get(memberId) if (member.matches(protocols)) { // 分区分配策略未发生变化,返回 GroupMetadata 的信息 responseCallback(JoinGroupResult( members = if (memberId == group.leaderId) { group.currentMemberMetadata } else { Map.empty }, memberId = memberId, generationId = group.generationId, subProtocol = group.protocol, leaderId = group.leaderId, errorCode = Errors.NONE.code)) } else { // 分区分配策略发生变化,更新对应的元数据信息,同时切换 group 的状态为 PreparingRebalance,准备执行分区再分配 this.updateMemberAndRebalance(group, member, protocols, responseCallback) } } // 目标 group 运行正常,或者正在等待 offset 过期 case Empty | Stable => if (memberId == JoinGroupRequest.UNKNOWN_MEMBER_ID) { // 对于未知 ID 的消费者申请加入,创建对应的元数据信息,并分配 ID,同时切换 group 的状态为 PreparingRebalance,准备执行分区再分配 this.addMemberAndRebalance(rebalanceTimeoutMs, sessionTimeoutMs, clientId, clientHost, protocolType, protocols, group, responseCallback) } else { // 对于已知 ID 的消费者重新申请加入 val member = group.get(memberId) if (memberId == group.leaderId || !member.matches(protocols)) { // 当前消费者是 group leader 或支持的分区分配策略发生变化,更新对应的元数据信息,同时切换 group 的状态为 PreparingRebalance,准备执行分区再分配 this.updateMemberAndRebalance(group, member, protocols, responseCallback) } else { // 分区分配策略未发生变化,返回 GroupMetadata 信息 responseCallback(JoinGroupResult( members = Map.empty, memberId = memberId, generationId = group.generationId, subProtocol = group.protocol, leaderId = group.leaderId, errorCode = Errors.NONE.code)) } } } // 如果当前 group 正在准备执行分区再分配,尝试执行 DelayedJoin 延时任务 if (group.is(PreparingRebalance)) joinPurgatory.checkAndComplete(GroupKey(group.groupId)) } } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
对于满足条件的消费者来说,需要依据 group 的当前运行状态分而治之。如果当前 group 的状态为 Dead,则说明对应的 group 不再可用,或者已经由其它 GroupCoordinator 实例管理,直接响应 UNKNOWN_MEMBER_ID 错误,消费者可以再次请求获取新接管的 GroupCoordinator 实例所在的位置信息。
如果当前 group 的状态为 PreparingRebalance,则说明对应的 group 正在准备执行分区再分配操作,此时:
- 对于新加入的消费者(未指定 ID),首先需要为其创建消费者 ID 和元数据信息,并交由目标 group 进行管理,然后开始执行分区再分配操作。
- 对于已存在的消费者(已指定 ID),首先需要更新消费者最终的分区分配策略和回调响应函数,然后开始执行分区再分配操作。
如果当前 group 的状态为 AwaitingSync,则说明对应的 group 正在等待 leader 消费者的分区分配结果,此时:
- 对于新加入的消费者(未指定 ID),首先需要为其创建消费者 ID 和元数据信息,并交由目标 group 进行管理,然后开始执行分区再分配操作。
- 对于已存在的消费者(已指定 ID),如果分区分配策略未发生变化则无需再重复分配,如果分区分配策略发生变化则需要
先更新消费者最终的分区分配策略和回调响应函数,然后开始执行分区再分配操作。
如果当前 group 的状态为 Empty 或 Stable,则说明对应的 group 目前处于一个正常运行的状态,此时:
- 对于新加入的消费者(未指定 ID),首先需要为其创建消费者 ID 和元数据信息,并交由目标 group 进行管理,然后开始执行分区再分配操作。
- 对于已存在的消费者(已指定 ID),如果不是 leader,或者分区分配策略未发生变化,则无需再重复分配,否则需要先更新消费者最终的分区分配策略和回调响应函数,然后开始执行分区再分配操作。
上述过程中多次调用了 GroupCoordinator#addMemberAndRebalance 方法为消费者创建元数据信息并分配 ID,并将对应的消费者元数据信息记录到 group 元数据信息中。方法 GroupMetadata#add 定义了 如果当前 group 名下还未选举 leader 消费者,则以第一个加入到当前 group 的消费者作为 leader 角色 ,然后调用 GroupCoordinator#updateMemberAndRebalance 方法更新消费者的分区分配策略和响应回调函数。这两个方法分别实现如下:
private def addMemberAndRebalance(rebalanceTimeoutMs: Int, sessionTimeoutMs: Int, clientId: String, clientHost: String, protocolType: String, protocols: List[(String, Array[Byte])], group: GroupMetadata, callback: JoinCallback): MemberMetadata = { // 基于 UUID 生成消费者的 ID val memberId = clientId + "-" + group.generateMemberIdSuffix // 创建新的 MemberMetadata 元数据信息对象 val member = new MemberMetadata(memberId, group.groupId, clientId, clientHost, rebalanceTimeoutMs, sessionTimeoutMs, protocolType, protocols) // 设置回调函数,即 KafkaApis#sendResponseCallback 方法,用于向客户端发送 JoinGroupResponse 响应 member.awaitingJoinCallback = callback // 添加到 GroupMetadata 中,第一个加入 group 的消费者成为 leader 角色 group.add(member) // 尝试切换 group 的状态为 PreparingRebalance this.maybePrepareRebalance(group) member } private def updateMemberAndRebalance(group: GroupMetadata, member: MemberMetadata, protocols: List[(String, Array[Byte])], callback: JoinCallback) { // 更新 MemberMetadata 支持的协议 member.supportedProtocols = protocols // 更新 MemberMetadata 的响应回调函数 member.awaitingJoinCallback = callback // 尝试执行状态切换 this.maybePrepareRebalance(group) }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
由上述实现可以看到这两个方法最终都调用了 GroupCoordinator#maybePrepareRebalance 方法,该方法会校验 group 的当前状态,如果是 Stable、AwaitingSync,以及 Empty 中的一种,则会调用 GroupCoordinator#prepareRebalance 方法切换 group 的状态为 PreparingRebalance,并创建相应的 DelayedJoin 延时任务,等待 group 名下所有的消费者发送 JoinGroupRequest 请求申请加入到当前 group 中。
private def prepareRebalance(group: GroupMetadata) { // 如果处于 AwaitingSync 状态,说明在等待 leader 消费者的分区分配结果, // 此时对于来自 follower 的 SyncGroupRequest 请求,直接响应 REBALANCE_IN_PROGRESS 错误 if (group.is(AwaitingSync)) resetAndPropagateAssignmentError(group, Errors.REBALANCE_IN_PROGRESS) // 将 group 状态切换成 PreparingRebalance 状态,准备执行分区再分配操作 group.transitionTo(PreparingRebalance) info("Preparing to restabilize group %s with old generation %s".format(group.groupId, group.generationId)) // 分区再均衡超时时长是所有消费者设置的超时时长的最大值 val rebalanceTimeout = group.rebalanceTimeoutMs // 创建 DelayedJoin 延时任务,用于等待消费者申请加入当前 group val delayedRebalance = new DelayedJoin(this, group, rebalanceTimeout) val groupKey = GroupKey(group.groupId) // 关注当前 group // 将延时任务添加到炼狱中进行管理 joinPurgatory.tryCompleteElseWatch(delayedRebalance, Seq(groupKey)) }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
上述方法首先会校验 group 当前状态是不是 AwaitingSync,如果是则说明当前 GroupCoordinator 实例正在等待 leader 消费者的分区分配的结果,此时如果有来自 follower 消费者的 SyncGroupRequest 请求,则直接响应 REBALANCE_IN_PROGRESS 错误,同时需要清空 group 名下所有消费者记录的分区分配信息。然后切换 group 的状态为 PreparingRebalance,表示开始准备执行分区再分配,并创建 DelayedJoin 延时任务等待 group 名下所有消费者发送 JoinGroupRequest 请求申请加入当前 group。
下面来看一下延时任务 DelayedJoin 的实现,这里的延时时长等于 group 名下所有消费者设置的超时时长的最大值。我们重点看一下 DelayedJoin#tryComplete 和 DelayedJoin#onComplete 方法,这两个方法分别调用了 GroupCoordinator#tryCompleteJoin 和 GroupCoordinator#onCompleteJoin 方法。其中 GroupCoordinator#tryCompleteJoin 方法基于消费者元数据信息 MemberMetadata#awaitingJoinCallback 字段判断 group 名下已知的消费者是否都已经发送了 JoinGroupRequest 请求,如果是则强制完成 DelayedJoin 延时任务,方法实现如下:
def tryCompleteJoin(group: GroupMetadata, forceComplete: () => Boolean): Boolean = {
group synchronized {
// 判断所有已知的消费者是否是否都已经申请加入,
// 基于 awaitingJoinCallback 回调函数,只有发送了 JoinGroupRequest 请求的消费者才会设置该回调
if (group.notYetRejoinedMembers.isEmpty) forceComplete() else false
}
}
def notYetRejoinedMembers: List[MemberMetadata] = members.values.filter(_.awaitingJoinCallback == null).toList
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
消费者元数据信息的 MemberMetadata#awaitingJoinCallback 字段实际上就是在 KafkaApis#handleJoinGroupRequest 方法中定义的 sendResponseCallback 回调函数,用于向客户端发送 JoinGroupResponse 响应。所以这里我们可以依据该字段判断对应消费者是否发送了 JoinGroupRequest 请求,因为只有发送了该请求才会为 MemberMetadata#awaitingJoinCallback 字段赋值。
当延时任务 DelayedJoin 被执行时会触发调用 GroupCoordinator#onCompleteJoin 方法,实现如下:
def onCompleteJoin(group: GroupMetadata) { var delayedStore: Option[DelayedStore] = None group synchronized { // 移除那些已知的但是未申请重新加入当前 group 的消费者 group.notYetRejoinedMembers.foreach { failedMember => group.remove(failedMember.memberId) } if (!group.is(Dead)) { // 递增 group 的年代信息,并选择 group 最终使用的分区分配策略,如果 group 名下存在消费者则切换状态为 AwaitingSync,否则切换成 Empty group.initNextGeneration() if (group.is(Empty)) { info(s"Group ${group.groupId} with generation ${group.generationId} is now empty") // 如果 group 名下已经没有消费者,将空的分区分配信息记录到 offset topic delayedStore = groupManager.prepareStoreGroup(group, Map.empty, error => { if (error != Errors.NONE) { warn(s"Failed to write empty metadata for group ${group.groupId}: ${error.message}") } }) } else { info(s"Stabilized group ${group.groupId} generation ${group.generationId}") // 向 group 名下所有的消费者发送 JoinGroupResponse 响应, for (member <- group.allMemberMetadata) { assert(member.awaitingJoinCallback != null) val joinResult = JoinGroupResult( members = if (member.memberId == group.leaderId) { group.currentMemberMetadata } else { Map.empty }, memberId = member.memberId, generationId = group.generationId, subProtocol = group.protocol, leaderId = group.leaderId, errorCode = Errors.NONE.code) // 该回调函数在 KafkaApis#handleJoinGroupRequest 中定义(对应 sendResponseCallback 方法),用于将响应对象放入 channel 中等待发送 member.awaitingJoinCallback(joinResult) member.awaitingJoinCallback = null // 心跳机制 this.completeAndScheduleNextHeartbeatExpiration(group, member) } } } } // 往 offset topic 中追加消息 delayedStore.foreach(groupManager.store) }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
DelayedJoin 延时任务在等待期间主要是等待关注的 group 名下的消费者发送 JoinGroupRequest 请求的情况,一旦任务满足执行条件(也可能是因为超时)则执行:
- 剔除那些已知的但是未申请重新加入当前 group 的消费者;
- 如果目标 group 状态已经为 Dead,则结束任务;
- 否则,递增 group 的年代信息,并为 group 名下的消费者确定最终的分区分配策略,同时依据名下是否存在消费者来将 group 状态切换成 AwaitingSync 或 Empty;
- 如果切换后的 group 状态为 Empty,则将空的分区分配结果追加到 topic offset 中;
- 如果切换后的 group 状态为 AwaitingSync,则向 group 名下所有的消费者发送 JoinGroupResponse 响应,并等待 leader 消费者的 SyncGroupRequest 请求反馈分区的分配结果。
其中 步骤 3 的实现位于 GroupMetadata#initNextGeneration 方法中,该方法会依据 group 名下是否存在消费者将 group 切换成相应的状态,如果名下存在消费者还会确定最终的分区分配策略。方法实现如下:
def initNextGeneration(): Unit = {
assert(notYetRejoinedMembers == List.empty[MemberMetadata])
if (members.nonEmpty) {
generationId += 1
// 基于投票的方式选择一个所有消费者都支持的分区分配策略
protocol = selectProtocol
transitionTo(AwaitingSync)
} else {
generationId += 1
protocol = null
transitionTo(Empty)
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
确定最终的分区分配策略, 简单来说就是从消费者都支持的分区分配策略中投票选举一个得票最高的策略作为最终策略 ,实现如下:
def selectProtocol: String = { if (members.isEmpty) throw new IllegalStateException("Cannot select protocol for empty group") // 计算所有消费者都支持的分区分配策略 val candidates = candidateProtocols // 选择所有消费者都支持的协议作为候选协议集合, // 每个消费者都会通过 vote 方法进行投票(为支持的协议中的第一个协议投一票), // 最终选择投票最多的分区分配策略 val votes: List[(String, Int)] = allMemberMetadata .map(_.vote(candidates)) .groupBy(identity) .mapValues(_.size) .toList votes.maxBy(_._2)._1 }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
其中 MemberMetadata#vote 方法的投票策略实际上就是从消费者自身支持的分区分配策略和 group 名下所有消费者都支持的分区分配策略中选择第 1 个进行投票。
步骤 4 的实现位于 GroupMetadataManager#prepareStoreGroup 方法中,这一步主要的逻辑就是基于分区分配结果(不过这里的分区分配结果是空集合)创建 Kafka 消息,并写入到 offset topic 中。方法实现如下:
def prepareStoreGroup(group: GroupMetadata, groupAssignment: Map[String, Array[Byte]], responseCallback: Errors => Unit): Option[DelayedStore] = { // 依据 group 对应 offset topic 分区的消息版本进行处理 getMagic(partitionFor(group.groupId)) match { case Some(magicValue) => val groupMetadataValueVersion = { if (interBrokerProtocolVersion < KAFKA_0_10_1_IV0) 0.toShort else GroupMetadataManager.CURRENT_GROUP_VALUE_SCHEMA_VERSION } val timestampType = TimestampType.CREATE_TIME val timestamp = time.milliseconds() // 创建记录 GroupMetadata 信息的消息,其中 value 是分区的分配结果 val record = Record.create(magicValue, timestampType, timestamp, GroupMetadataManager.groupMetadataKey(group.groupId), GroupMetadataManager.groupMetadataValue(group, groupAssignment, version = groupMetadataValueVersion)) // 获取 group 对应的 offset topic 分区对象 val groupMetadataPartition = new TopicPartition(Topic.GroupMetadataTopicName, partitionFor(group.groupId)) // 构造 offset topic 分区与消息集合的映射关系 val groupMetadataRecords = Map(groupMetadataPartition -> MemoryRecords.withRecords(timestampType, compressionType, record)) val generationId = group.generationId // ... 省略 putCacheCallback 回调函数,该函数在消息完成追加到 offset topic 之后被回调,后面再进行分析 // 这里并没有真正追加消息,而是记录到 DelayedStore 中,具体追加由 GroupMetadataManager#store 方法追加 Some(DelayedStore(groupMetadataRecords, putCacheCallback)) case None => responseCallback(Errors.NOT_COORDINATOR_FOR_GROUP) None } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
方法会基于分区分配结果创建 Kafka 消息并写入到 offset topic 对应的分区中(前面的小节分析 GroupCoordinator 故障转移时有基于此类消息在新的 GroupCoordinator 节点上恢复 group 的元数据信息),需要注意的是这里并没有执行真正的写入操作,而是将待写入的数据和写入完成的回调函数封装成 DelayedStore 对象,等待后续调用 GroupMetadataManager#store 方法时才执行真正的写入操作:
def store(delayedStore: DelayedStore) {
// 调用 ReplicaManager#appendRecords 方法往 offset topic 中追加消息
replicaManager.appendRecords(
config.offsetCommitTimeoutMs.toLong,
config.offsetCommitRequiredAcks, // -1,需要 ISR 集合中所有的副本都同步了该消息才认为消息成功追加
internalTopicsAllowed = true, // 指定允许向内部 topic 追加消息,即 offset topic
delayedStore.partitionRecords, // 分区与对应消息之间的映射
delayedStore.callback) // 回调函数
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
上述方法中的回调函数实际上也就是在 GroupMetadataManager#prepareStoreGroup 方法中定义的 putCacheCallback 方法,当消息被追加到 offset topic 中后会回调执行该方法:
def putCacheCallback(responseStatus: Map[TopicPartition, PartitionResponse]) { if (responseStatus.size != 1 || !responseStatus.contains(groupMetadataPartition)) throw new IllegalStateException("Append status %s should only have one partition %s".format(responseStatus, groupMetadataPartition)) // 获取消息追加响应结果 val status = responseStatus(groupMetadataPartition) val responseError = if (status.error == Errors.NONE) { // 追加成功 Errors.NONE } else { // ... 追加异常,对错误码执行一些转换操作,省略 } // 执行回调函数 responseCallback(responseError) }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
当消息被追加到 offset topic 中之后会依据消息的追加结果封装成对应的错误码,并回调 responseCallback 方法,这是一个 Errors => Unit 的函数,在本步骤中该函数只是简单的在追加失败时打印一行警告日志,毕竟追加的消息本来就是空的。
6.3 SyncGroupRequest 请求处理
对于 GroupCoordinator 实例而言,分区再分配操作的最后一步是处理来自 leader 消费者的 SyncGroupRequest 请求,以获取 leader 消费者基于服务端确定的分区分配策略为当前 group 名下消费者分配分区的结果信息。KafkaApis 中定义了 KafkaApis#handleSyncGroupRequest 方法处理该请求,而具体的处理逻辑则交由 GroupCoordinator#handleSyncGroup 方法实现,该方法首先会校验 GroupCoordinator 实例的运行状态,保证能够处理来自对应消费者的 SyncGroupRequest 请求,具体处理逻辑实现如下:
private def doSyncGroup(group: GroupMetadata, generationId: Int, memberId: String, groupAssignment: Map[String, Array[Byte]], responseCallback: SyncCallback) { var delayedGroupStore: Option[DelayedStore] = None group synchronized { if (!group.has(memberId)) { // 当前消费者不属于该 group responseCallback(Array.empty, Errors.UNKNOWN_MEMBER_ID.code) } else if (generationId != group.generationId) { // group 年代信息不合法 responseCallback(Array.empty, Errors.ILLEGAL_GENERATION.code) } else { group.currentState match { case Empty | Dead => // 直接返回错误码 responseCallback(Array.empty, Errors.UNKNOWN_MEMBER_ID.code) case PreparingRebalance => // 直接返回错误码 responseCallback(Array.empty, Errors.REBALANCE_IN_PROGRESS.code) case AwaitingSync => // 设置对应消费者的响应回调函数 group.get(memberId).awaitingSyncCallback = responseCallback // 仅处理来自 leader 消费者发来的 SyncGroupRequest 请求 if (memberId == group.leaderId) { info(s"Assignment received from leader for group ${group.groupId} for generation ${group.generationId}") // 将未分配分区的消费者对应的分区分配结果填充为空的字节数组 val missing = group.allMembers -- groupAssignment.keySet val assignment = groupAssignment ++ missing.map(_ -> Array.empty[Byte]).toMap // 将 GroupMetadata 相关信息以消息的形式写入到对应的 offset topic 分区中 delayedGroupStore = groupManager.prepareStoreGroup(group, assignment, // ... 追加消息完成的回调响应逻辑,省略,后面针对性分析 ) } case Stable => // 将已有的分区分配结果返回给当前消费者 val memberMetadata = group.get(memberId) responseCallback(memberMetadata.assignment, Errors.NONE.code) // 心跳相关操作 this.completeAndScheduleNextHeartbeatExpiration(group, group.get(memberId)) } } } // 执行写 offset topic 逻辑 delayedGroupStore.foreach(groupManager.store) }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
GroupCoordinator 依赖于目标 group 的当前状态对 SyncGroupRequest 请求分而治之,对于 Empty、Dead 和 PreparingRebalance 状态而言直接返回对应的错误码,此时没有正常响应 SyncGroupRequest 请求的意义和条件,下面主要分析一下 AwaitingSync 和 Stable 状态。
对于 AwaitingSync 状态而言,此时 GroupCoordinator 正在等待 leader 消费者的分区分配结果(即 SyncGroupRequest 请求),所以位于此状态的 group 只处理来自 leader 消费者的 SyncGroupRequest 请求。如果消费者的数目多于 topic 的分区数,则多出来的消费者不会分配分区,因为 Kafka 在设计上要求一个分区至多被一个消费者消费,所以这些多出来的消费者的分区分配信息会被置空。然后 GroupCoordinator 实例会调用 GroupMetadataManager#prepareStoreGroup 方法将分区分配信息写入到 offset topic 中,该方法的执行逻辑已在前面分析过,所以这里不再重复撰述,重点来看一下该方法的回调函数实现。我们前面已经介绍了当消息完成追加到 offset topic 中之后会回调参数指定的回调函数,而这里的回调逻辑实现如下:
(error: Errors) => { group synchronized { // 检查 group 的状态(正在等待 leader 消费者将分区的分配结果发送给 GroupCoordinator)和年代信息 if (group.is(AwaitingSync) && generationId == group.generationId) { if (error != Errors.NONE) { // 清空分区的分配结果,并发送异常响应 resetAndPropagateAssignmentError(group, error) // 切换 group 状态为 PreparingRebalance,再次尝试分配分区 maybePrepareRebalance(group) } else { // 设置分区的分配结果,发送正常的 SyncGroupResponse 响应 setAndPropagateAssignment(group, assignment) group.transitionTo(Stable) } } } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
如果追加消息失败,则在回调逻辑中会清空分区的分配结果,并将错误信息返回给 leader 消费者,同时 GroupCoordinator 实例会切换状态为 PreparingRebalance 准备再次尝试分配分区。如果追加消息成功,则会将分区分配结果更新到 group 名下对应消费者的元数据信息中,同时向 leader 消费者响应正常的 SyncGroupResponse,同时切换 group 的状态为 Stable,开始正常运行。
对于 Stable 状态而言,此时 group 处于正常运行中,所以对于来自消费者的 SyncGroupRequest 请求,只是简单将历史的分区分配结果直接返回,不做特殊处理。
6.4 消费者请求处理
6.4.1 OffsetFetchRequest 请求处理
当完成执行分区再分配操作之后,消费者一般会被重新分配新的分区,此时消费者需要向集群发送 OffsetFetchRequest 请求以获取对应 topic 分区上次消费者的 offset 值,并从该位置继续消费,以防止消息的重复消费或遗漏消费。
KafkaApis 定义了 KafkaApis#handleOffsetFetchRequest 方法用于处理 OffsetFetchRequest 请求,该方法会对请求的 topic 分区执行权限校验,如果校验通过则会依据请求中指定的版本号决定是从 ZK 还是 offset topic 中获取目标 topic 分区的 offset 位置信息。目前新版本的 Kafka 为了避免 ZK 压力对于服务可用性的影响,已经默认使用 offset topic 取代 ZK 记录消费者消费的 offset 位置信息,所以本小节仅介绍基于 offset topic 的 OffsetFetchRequest 请求处理过程。
具体的处理逻辑交由 GroupCoordinator#handleFetchOffsets 方法执行,如果在请求中未指明要获取 offset 的 topic 分区,则表示期望获取当前 group 范围内所有 topicc 分区最近一次提交的 offset 值。方法实现如下:
def handleFetchOffsets(groupId: String, partitions: Option[Seq[TopicPartition]] = None): (Errors, Map[TopicPartition, OffsetFetchResponse.PartitionData]) = { if (!isActive.get) { // 当前 GroupCoordinator 实例未启动运行 (Errors.GROUP_COORDINATOR_NOT_AVAILABLE, Map()) } else if (!isCoordinatorForGroup(groupId)) { // 当前 GroupCoordinator 实例并不负责管理当前 group debug("Could not fetch offsets for group %s (not group coordinator).".format(groupId)) (Errors.NOT_COORDINATOR_FOR_GROUP, Map()) } else if (isCoordinatorLoadingInProgress(groupId)) { // 当前 GroupCoordinator 实例正在加载该 group 对应的 offset topic 分区信息 (Errors.GROUP_LOAD_IN_PROGRESS, Map()) } else { // 返回指定 topic 分区集合对应的最近一次提交的 offset 位置信息 (Errors.NONE, groupManager.getOffsets(groupId, partitions)) } } def getOffsets(groupId: String, topicPartitionsOpt: Option[Seq[TopicPartition]]): Map[TopicPartition, OffsetFetchResponse.PartitionData] = { trace("Getting offsets of %s for group %s.".format(topicPartitionsOpt.getOrElse("all partitions"), groupId)) // 获取 group 对应的元数据信息 val group = groupMetadataCache.get(groupId) if (group == null) { // group 对应的元数据信息不存在,则统一返回 offset 为 -1 topicPartitionsOpt.getOrElse(Seq.empty[TopicPartition]).map { topicPartition => (topicPartition, new OffsetFetchResponse.PartitionData(OffsetFetchResponse.INVALID_OFFSET, "", Errors.NONE)) }.toMap } else { group synchronized { if (group.is(Dead)) { // 对应的 group 名下已经没有消费者,并且元数据信息已经被删除 topicPartitionsOpt.getOrElse(Seq.empty[TopicPartition]).map { topicPartition => (topicPartition, new OffsetFetchResponse.PartitionData(OffsetFetchResponse.INVALID_OFFSET, "", Errors.NONE)) }.toMap } else { topicPartitionsOpt match { // 请求未指定 topic 分区,表示请求 group 名下全部 topic 分区对应的最近一次提交的 offset 值 case None => group.allOffsets.map { case (topicPartition, offsetAndMetadata) => topicPartition -> new OffsetFetchResponse.PartitionData(offsetAndMetadata.offset, offsetAndMetadata.metadata, Errors.NONE) } // 查找指定 topic 分区集合对应的最近一次提交的 offset 值 case Some(_) => topicPartitionsOpt.getOrElse(Seq.empty[TopicPartition]).map { topicPartition => val partitionData = group.offset(topicPartition) match { case None => new OffsetFetchResponse.PartitionData(OffsetFetchResponse.INVALID_OFFSET, "", Errors.NONE) case Some(offsetAndMetadata) => new OffsetFetchResponse.PartitionData(offsetAndMetadata.offset, offsetAndMetadata.metadata, Errors.NONE) } topicPartition -> partitionData }.toMap } } } } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
Group 元数据信息的 GroupMetadata#offsets 字段缓存了每个 topic 分区最近一次提交的 offset 位置信息和用户自定义数据,所以这里只要获取对应 topic 分区的 offset 值即可。
6.4.2 OffsetCommitRequest 请求处理
消费者在完成对指定 offset 的消费之后,会基于配置和相应的场景以 OffsetCommitRequest 请求的方式向服务端提交该 offset 值。服务端在接收到 OffsetCommitRequest 请求之后,需要为每个消费者记录对应 topic 分区的消费位置。
KafkaApis 定义了 KafkaApis#handleOffsetCommitRequest 方法用于处理 OffsetCommitRequest 请求,该方法会校验目标 topic 是否存在,以及是否有对于该 topic 的读取权限,如果满足条件则会依据请求中指定的版本号决定将对应的 offset 位置信息记录到 ZK 还是 offset topic,本小节同样仅介绍基于 offset topic 的 OffsetCommitRequest 请求处理过程。
具体的处理逻辑交由 GroupCoordinator#handleCommitOffsets 方法执行,该方法首先会校验 GroupCoordinator 的状态,确保能够正常处理当前 OffsetCommitRequest 请求,并在允许的条件下调用 GroupCoordinator#doCommitOffsets 方法将 offset 消费位置信息封装成消息追加到 offset topic 中:
private def doCommitOffsets(group: GroupMetadata, memberId: String, generationId: Int, offsetMetadata: immutable.Map[TopicPartition, OffsetAndMetadata], responseCallback: immutable.Map[TopicPartition, Short] => Unit) { var delayedOffsetStore: Option[DelayedStore] = None group synchronized { if (group.is(Dead)) { // 目标 group 已经失效,直接响应错误码 responseCallback(offsetMetadata.mapValues(_ => Errors.UNKNOWN_MEMBER_ID.code)) } else if (generationId < 0 && group.is(Empty)) { // 目标 group 的信息不是由 kafka 维护,而仅仅依赖于 kafka 记录 offset 消费信息 delayedOffsetStore = groupManager.prepareStoreOffsets(group, memberId, generationId, offsetMetadata, responseCallback) } else if (group.is(AwaitingSync)) { // 目标 group 目前正在执行分区再分配操作 responseCallback(offsetMetadata.mapValues(_ => Errors.REBALANCE_IN_PROGRESS.code)) } else if (!group.has(memberId)) { // 目标 group 并不包含当前消费者 responseCallback(offsetMetadata.mapValues(_ => Errors.UNKNOWN_MEMBER_ID.code)) } else if (generationId != group.generationId) { // 目标 group 年代信息不一致 responseCallback(offsetMetadata.mapValues(_ => Errors.ILLEGAL_GENERATION.code)) } else { // 将记录 offset 信息的消息追加到对应的 offset topic 对应分区中 val member = group.get(memberId) completeAndScheduleNextHeartbeatExpiration(group, member) delayedOffsetStore = groupManager.prepareStoreOffsets(group, memberId, generationId, offsetMetadata, responseCallback) } } // 执行真正的追加消息操作 delayedOffsetStore.foreach(groupManager.store) }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
具体追加消息到 offset topic 的过程已在前面分析过,不再重复撰述。
6.4.3 LeaveGroupRequest 请求处理
当消费者取消对指定 topic 的订阅,或者配置了 internal.leave.group.on.close=true 指明在关闭消费者时一同退出所属的 group,以及消费者因一些异常原因离线时,会向对应的 GroupCoordinator 节点发送 LeaveGroupRequest 请求,已告知集群对应的消费者已经失效,可能需要触发分区再分配操作。
KafkaApis 定义了 KafkaApis#handleLeaveGroupRequest 方法用于处理 LeaveGroupRequest 请求,该方法首先会对消费者执行权限校验,并在权限校验通过的前提下委托 GroupCoordinator 处理相应的离线策略。具体逻辑实现位于 GroupCoordinator#handleLeaveGroup 方法中:
def handleLeaveGroup(groupId: String, memberId: String, responseCallback: Short => Unit) { if (!isActive.get) { // GroupCoordinator 实例未启动 responseCallback(Errors.GROUP_COORDINATOR_NOT_AVAILABLE.code) } else if (!isCoordinatorForGroup(groupId)) { // 当前 GroupCoordinator 实例并不负责管理当前 group responseCallback(Errors.NOT_COORDINATOR_FOR_GROUP.code) } else if (isCoordinatorLoadingInProgress(groupId)) { // 当前 GroupCoordinator 实例正在加载该 group 对应的 offset topic 分区信息 responseCallback(Errors.GROUP_LOAD_IN_PROGRESS.code) } else { groupManager.getGroup(groupId) match { // 对应的 group 不存在或已经失效 case None => responseCallback(Errors.UNKNOWN_MEMBER_ID.code) case Some(group) => group synchronized { if (group.is(Dead) || !group.has(memberId)) { responseCallback(Errors.UNKNOWN_MEMBER_ID.code) } else { val member = group.get(memberId) // 设置 MemberMetadata#isLeaving 为 true,并尝试完成对应的 DelayedHeartbeat 延时任务 this.removeHeartbeatForLeavingMember(group, member) // 从 group 元数据信息中移除对应的 MemberMetadata 对象,并切换状态 this.onMemberFailure(group, member) // 调用回调响应函数 responseCallback(Errors.NONE.code) } } } } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
如果发送 LeaveGroupRequest 请求的消费者所属的 group 存在且运行正常,则服务端首先会将对应消费者元数据信息的 MemberMetadata#isLeaving 字段设置为 true,标识当前消费者已经离线,并尝试触发关注当前消费者的 DelayedHeartbeat 延时任务。此外,还会将该消费者从之前所属的 group 元数据信息中移除,并依据 group 当前的状态决定是触发分区再分配操作,还是触发执行关注该 group 的 DelayedJoin 延时任务,相关实现位于 GroupCoordinator#onMemberFailure 方法中,前面已经分析过该方法,这里不再重复撰述。
7.总结
本文我们分析了 GroupCoordinator 组件的作用和实现,该组件与消费者之间关系密切,消费者在运行期间除了从 ReplicaManager 组件拉取消息进行消费,剩余的交互基本都由 GroupCoordinator 组件负责处理。Kafka 依赖该组件对消费者所属的 group 实施管理,并对 group 名下的消费者进行协调,主要提供了分区分配与再平衡支持、记录 group 的消费 offset 位置信息,以及维护与消费者之间的心跳等功能。此外,GroupCoordinator 内置了故障转移机制,以保证在 topic offset 对应分区 leader 副本失效时,能够切换到新的 GroupCoordinator 实例继续对外提供服务。

