
- 1Redis 那些故障转移、高可用方案
- 2解读一下最近Midjourney开放的中国版_midjourney国内版和国外区别
- 3Java_单元测试、反射
- 4requests 代理设置问题解决方案_requests.post不走代理
- 5ChatGLM2-6B下载/部署/微调_chatglm下载
- 6排序算法--冒泡排序
- 7【EMQX】EMQX中webhook配置数据源 https以及http配置内容 规则引擎转发webhook_webhook emqx
- 8【kubernetes常用命令记录】_查看节点标签
- 9面试官给我挖坑:单台服务器并发TCP连接数到底可以有多少 ?_单台负载机 能发起多少并发
- 10(深度学习)PyCharm 连接配置服务器_pycharm连接服务器
日志管理系统,多种方式总结_日志浏览管理
赞
踩
一、背景简介
项目中日志的管理是基础功能之一,不同的用户和场景下对日志都有特定的需求,从而需要用不同的策略进行日志采集和管理,如果是在分布式的项目中,日志的体系设计更加复杂。
- 日志类型:业务操作、信息打印、请求链路;
- 角色需求:研发端、用户端、服务级、系统级;
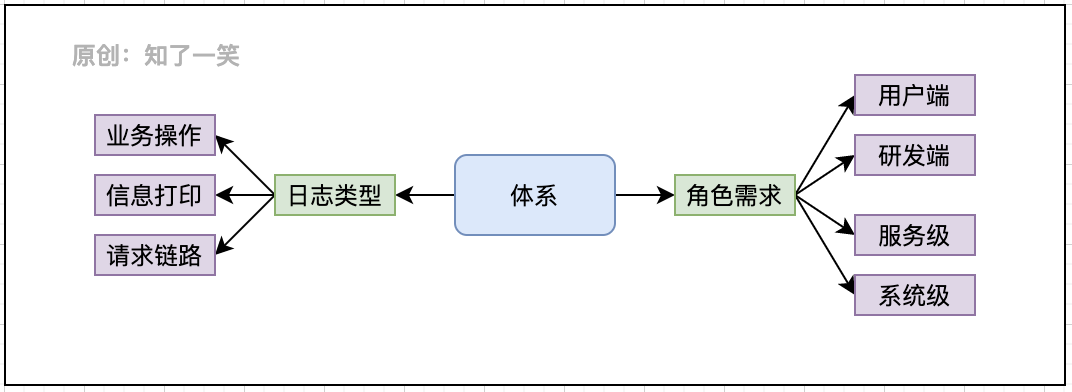
用户与需求
- 用户端:核心数据的增删改,业务操作日志;
- 研发端:日志采集与管理策略,异常日志监控;
- 服务级:关键日志打印,问题发现与排查;
- 系统级:分布式项目中链路生成,监控体系;
不同的场景中,需要选用不同的技术手段去实现日志采集管理,例如日志打印、操作记录、ELK体系等,注意要避免日志管理导致程序异常中断的情况。
越是复杂的系统设计和业务场景,就越依赖日志的输出信息,在大规模的架构中,通常还会搭建独立的日志平台,提供日志数据的采集、存储、分析等整套解决方案。
二、Slf4j组件
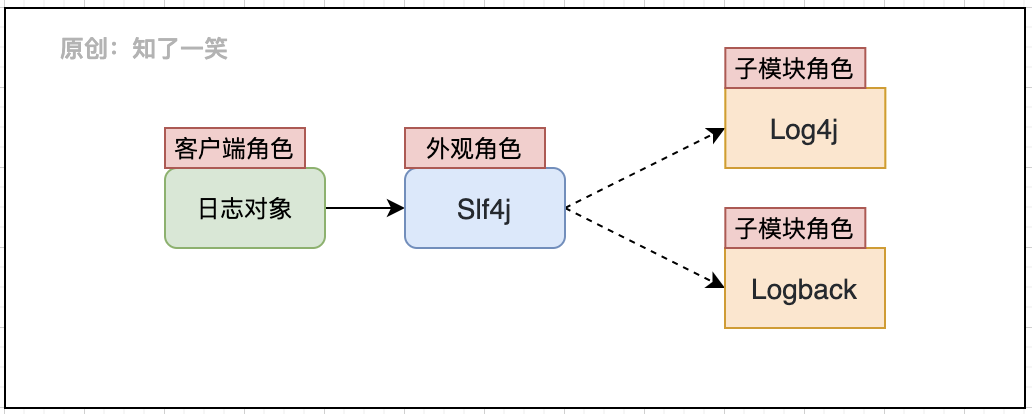
1、外观模式
日志的组件遵守外观设计模式,Slf4j作为日志体系的外观对象,定义规范日志的标准,日志能力的具体实现交由各个子模块去实现;Slf4j明确日志对象的加载方法和功能接口,与客户端交互提供日志管理功能;
private static final org.slf4j.Logger logger = org.slf4j.LoggerFactory.getLogger(Impl.class) ;
- 1
通常禁止直接使用Logback、Log4j等具体实现组件的API,避免组件替换带来不必要的麻烦,可以做到日志的统一维护。
2、SPI接口
从Slf4j和Logback组件交互来看,在日志的使用过程中,基本的切入点即使用Slf4j的接口,识别并加载Logback中的具体实现;SPI定义的接口规范,通常作为第三方(外部)组件的实现。
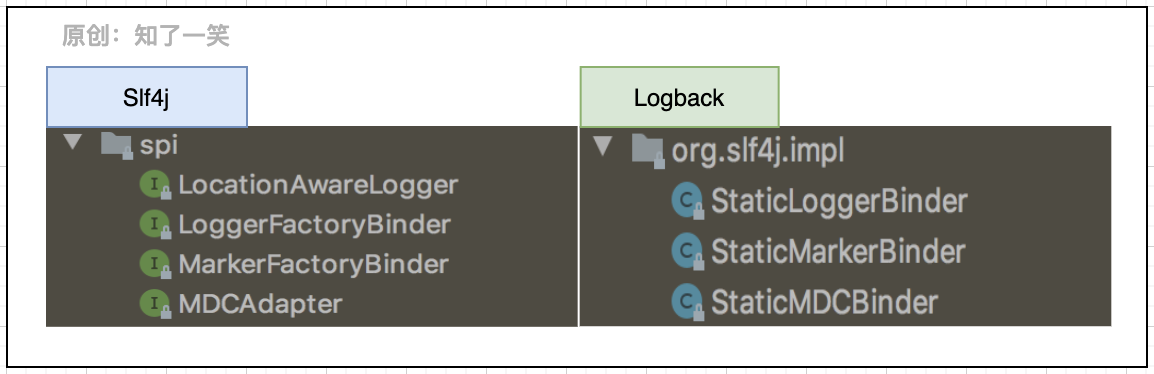
上述SPI作为两套组件的连接点,通过源码大致看下加载过程,追溯LoggerFactory的源码即可:
public final class org.slf4j.LoggerFactory {
private final static void performInitialization() {
bind();
}
private final static void bind() {
try {
StaticLoggerBinder.getSingleton();
} catch (NoClassDefFoundError ncde) {
String msg = ncde.getMessage();
if (messageContainsOrgSlf4jImplStaticLoggerBinder(msg)) {
Util.report("Failed to load class \"org.slf4j.impl.StaticLoggerBinder\".");
}
}
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
此处只贴出了几行示意性质的源码,在LoggerFactory中执行初始化绑定关联的时候,如果没有找到具体的日志实现组件,是会报告出相应的异常信息,并且采用的是System.err输出错误提示。
三、自定义组件
1、功能封装
对于日志(或其他)常用功能,通常会在代码工程中封装独立的代码包,作为公共依赖,统一管理和维护,对于日志的自定义封装可以参考之前的文档,这里通常涉及几个核心点:
- starter加载:封装包配置成starter组件,可以被框架扫描和加载;
- aop切面编程:通常在相关方法上添加日志注解,即可自动记录动作;
- annotation注解:定义日志记录需要标记的核心参数和处理逻辑;
至于如何组装日志内容,适配业务语义,以及后续的管理流程,则根据具体场景设计相应的策略即可,比如日志怎么存储、是否实时分析、是否异步执行等。
2、对象解析
在自定义注解中,会涉及到对象解析的问题,即在注解中放入要从对象中解析的属性,并且把值拼接到日志内容中,可以增强业务日志的语义可读性。
import org.springframework.expression.Expression;
import org.springframework.expression.spel.standard.SpelExpressionParser;
public class Test {
public static void main(String[] args) {
// Map集合
HashMap<String,Object> infoMap = new HashMap<>() ;
infoMap.put("info","Map的描述") ;
// List集合
ArrayList<Object> arrayList = new ArrayList<>() ;
arrayList.add("List-00");
arrayList.add("List-01");
// User对象
People oldUser = new People("Wang",infoMap,arrayList) ;
People newUser = new People("LiSi",infoMap,arrayList) ;
// 包装对象
WrapObj wrapObj = new WrapObj("WrapObject",oldUser,newUser) ;
// 对象属性解析
SpelExpressionParser parser = new SpelExpressionParser();
// objName
Expression objNameExp = parser.parseExpression("#root.objName");
System.out.println(objNameExp.getValue(wrapObj));
// oldUser
Expression oldUserExp = parser.parseExpression("#root.oldUser");
System.out.println(oldUserExp.getValue(wrapObj));
// newUser.userName
Expression userNameExp = parser.parseExpression("#root.newUser.userName");
System.out.println(userNameExp.getValue(wrapObj));
// newUser.hashMap[info]
Expression ageMapExp = parser.parseExpression("#root.newUser.hashMap[info]");
System.out.println(ageMapExp.getValue(wrapObj));
// oldUser.arrayList[1]
Expression arr02Exp = parser.parseExpression("#root.oldUser.arrayList[1]");
System.out.println(arr02Exp.getValue(wrapObj));
}
}
@Data
@AllArgsConstructor
class WrapObj {
private String objName ;
private People oldUser ;
private People newUser ;
}
@Data
@AllArgsConstructor
class People {
private String userName ;
private HashMap<String,Object> hashMap ;
private ArrayList<Object> arrayList ;
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
注意上面使用的SpelExpressionParser解析器,即Spring框架的原生API;业务中遇到的很多问题,建议都优先从核心依赖(Spring+JDK)中寻找解决方式,多花时间熟悉系统中核心组件的全貌,对开发视野和思路会有极大的帮助。
3、模式设计
这里看一个比较复杂的自定义日志解决思路,通过AOP模式识别日志注解,并解析注解中要记录的对象属性,构建相应的日志主体,最后根据注解标记的场景去适配不同的业务策略:
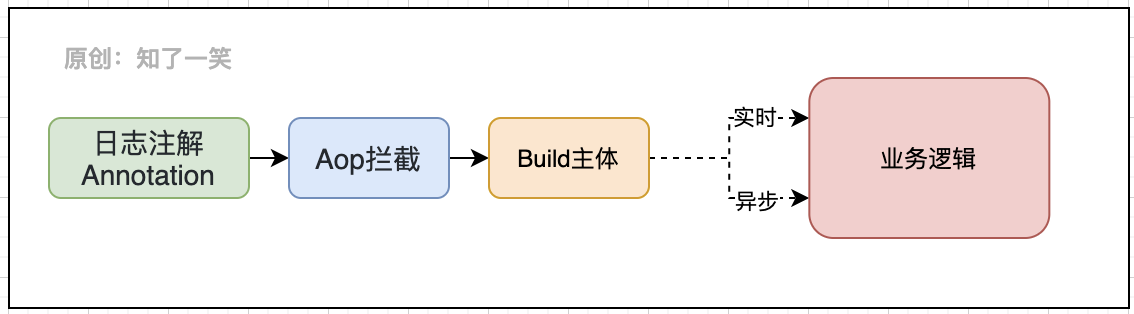
对于功能的通用性要求越高,在封装时内置的适配策略就要越抽象,在处理复杂的逻辑流程时,要善于将不同的组件搭配使用,可以分担业务支撑的压力,形成稳定可靠的解决方案。
四、分布式链路
1、链路识别
基于微服务实现的分布式系统,处理一个请求会经过多个子服务,如果过程中某个服务发生异常,需要定位这个异常归属的请求动作,从而更好的去判断异常原因并复现解决。
定位的动作则依赖一个核心的标识:TraceId-轨迹ID,即请求在各个服务流转时,会携带该请求绑定的TraceId,这样可以识别不同服务的哪些动作为同一个请求产生的。
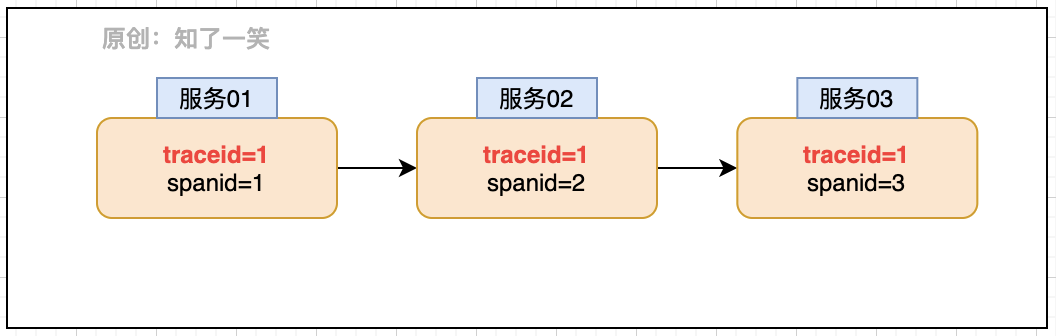
通过TraceId和SpanId即可还原出请求的链路视图,再结合相关日志打印记录等动作,则可以快速解决异常问题。在微服务体系中Sleuth组件提供了该能力的支撑。
链路视图的核心参数可以集成Slf4j组件中,这里可以参考org.slf4j.MDC语法,MDC提供日志前后的参数传递映射能力,内部包装Map容器管理参数;在Logback组件中,StaticMDCBinder提供该能力的绑定,这样日志打印也可以携带链路视图的标识,做到该能力的完整集成。
2、ELK体系
链路视图产生的日志是非常庞大的,那这些文档类的日志如何管理和快速查询使用同样是个关键问题,很常见的一个解决方案即ELK体系,现在已更新换代为ElasticStack产品。
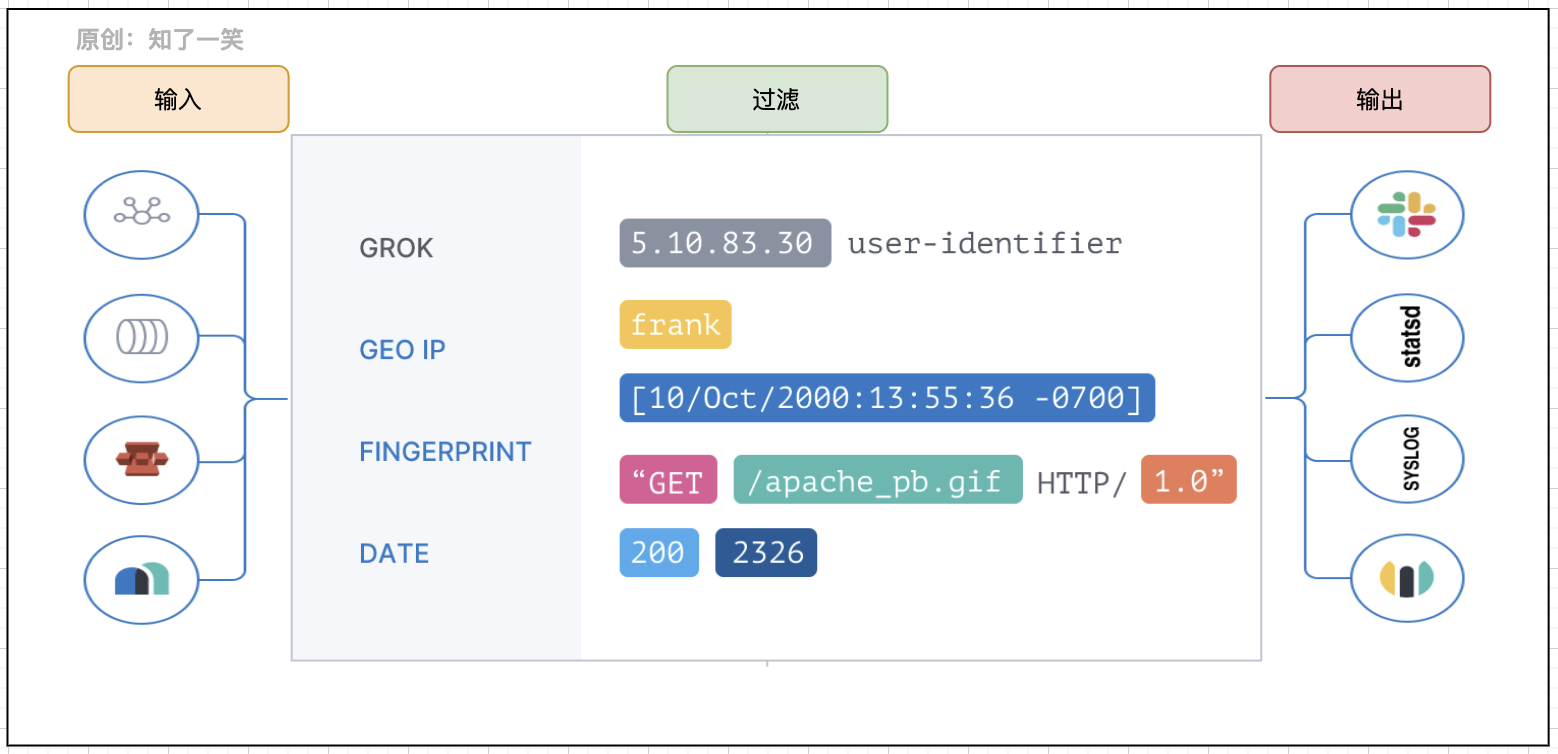
- Kibana:可以在Elasticsearch中使用图形和图表对数据进行可视化;
- Elasticsearch:提供数据的存储,搜索和分析引擎的能力;
- Logstash:数据处理管道,能够同时从多个来源采集、转换、推送数据;
Logstash提供日志采集和传输能力,Elasticsearch存储大量JSON格式的日志记录,Kibana则可以视图化展现数据。
3、服务与配置
配置依赖:需要在服务中配置Logstash地址和端口,即日志传输地址,以及服务名称;
spring:
application:
name: app_serve
logstash:
destination:
uri: Logstash-地址
port: Logstash-端口
- 1
- 2
- 3
- 4
- 5
- 6
- 7
配置读取:Logback组件配置中加载上述核心参数,这样在配置上下文中可以通过name的值使用该参数;
<springProperty scope="context" name="APP_NAME" source="spring.application.name" defaultValue="butte_app" />
<springProperty scope="context" name="DES_URI" source="logstash.destination.uri" />
<springProperty scope="context" name="DES_PORT" source="logstash.destination.port" />
- 1
- 2
- 3
日志传输:对传输内容做相应的配置,指定LogStash服务配置,编码,核心参数等;
<appender name="LogStash" class="net.logstash.logback.appender.LogstashTcpSocketAppender">
<!-- 日志传输地址 -->
<destination>${DES_URI:- }:${DES_PORT:- }</destination>
<!-- 日志传输编码 -->
<encoder class="net.logstash.logback.encoder.LoggingEventCompositeJsonEncoder">
<providers>
<timestamp>
<timeZone>UTC</timeZone>
</timestamp>
<!-- 日志传输参数 -->
<pattern>
<pattern>
{
"severity": "%level",
"service": "${APP_NAME:-}",
"trace": "%X{X-B3-TraceId:-}",
"span": "%X{X-B3-SpanId:-}",
"exportable": "%X{X-Span-Export:-}",
"pid": "${PID:-}",
"thread": "%thread",
"class": "%logger{40}",
"rest": "%message"
}
</pattern>
</pattern>
</providers>
</encoder>
</appender>
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
输出格式:还可以通过日志的格式设定,管理日志文件或者控制台的输出内容;
<pattern>%d{yyyy-MM-dd HH:mm:ss} %contextName [%thread] %-5level %logger{100} - %msg %n</pattern>
- 1
关于Logback组件日志的其他配置,例如输出位置,级别,数据传输方式等,可以多参考官方文档,不断优化。
4、数据通道
再看看数据传输到Logstash服务后,如何再传输到ES的,这里也需要相应的传输配置,注意logstash和ES推荐使用相同的版本,本案例中是6.8.6版本。
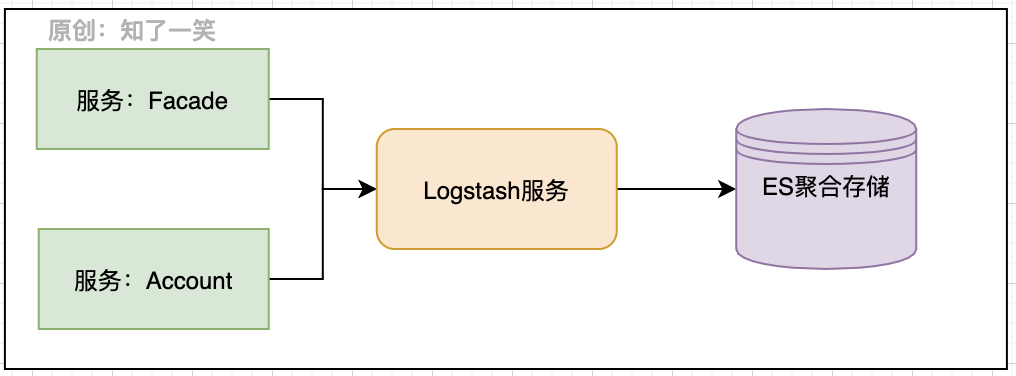
配置文件:logstash-butte.conf
input {
tcp {
host => "192.168.37.139"
port => "5044"
codec => "json"
}
}
output {
elasticsearch {
hosts => ["http://localhost:9200"]
index => "log-%{+YYYY.MM.dd}"
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 输入配置:指定logstash连接的host和端口,并且指定数据格式为json类型;
- 输出配置:指定日志数据输出的ES地址,并指定index索引按天的创建方式;
启动logstash服务
/opt/logstash-6.8.6/bin/logstash -f /opt/logstash-6.8.6/config/logstash-butte.conf
- 1
这样完整的ELK日志管理链路就实现了,通过使用Kibana工具就可以查看日志记录,根据TraceId就可以找到视图链路。

