
- 1unity3D RPG 网络游戏开发精讲
- 2UnityShader入门精要个人总结--基础篇(一)_unity shader入门精要
- 3WinFrom做工控上位机的界面库控件库_工控开关 winform
- 4今年的中秋(好惨啊)
- 5四种el-table的配置排序方式_el-table 排序
- 62402d,d的符号成员
- 7科普一下,ADI的DSP为什么要用专属的仿真器来做调试_usbi仿真器
- 8el-row的:gutter和 el-col的:span_el-row :gutter
- 9django,flask项目docker部署(uwsgi)——关于项目上线的杂七杂八_flask 部署方式uwg
- 10材质面向摄像机_ue5 通过材质使面片始终朝向摄像机
Web下的拒绝服务漏洞(DoS)
赞
踩
声明
由于传播、利用此文所提供的信息而造成的任何直接或者间接的后果及损失,均由使用者本人负责,Vulkey_Chen(戴城)不为此承担任何责任。
Vulkey_Chen(戴城)拥有对此文章的修改和解释权。如欲转载或传播此文章,必须保证此文章的完整性,包括版权声明等全部内容。
未经Vulkey_Chen(戴城)允许,不得任意修改或者增减此文章内容,不得以任何方式将其用于商业目的。
本文所需一定基础知识方能顺畅的进行阅读和理解,基础知识请读者自行搜索学习。
前言
相信很多师傅都了解DDoS攻击,也就是分布式拒绝服务,但这类攻击在很多时候拼的是资源,从攻击者的角度来看进行此类攻击还是需要一定“成本”的,从受害者的角度来看防御此类攻击的“成本”更是昂贵!
拒绝服务是一个老生常谈的话题,而发生在Web层面的拒绝服务风险一直不被重视;虽然其不如RCE、SQLi之类的漏洞更加直接的影响数据和服务,但令服务器宕机这类风险还是不容小视。
试想如果攻击者去利用不费成本的Web层拒绝服务风险造成服务器、应用、模块…瘫痪宕机,岂不是令那些斥巨资建设/购买“DDoS防护”一脸懵~
原理及案例
资源生成大小可控
现在有许多资源是由服务器生成然后返回给客户端的,而此类“资源生成”接口如若有参数可以被客户端控制(可控),并没有做任何资源生成大小限制,这样就会造成拒绝服务风险。
此类场景多为:图片验证码、二维码
图片验证码在登录、注册、找回密码…等功能比较常见:
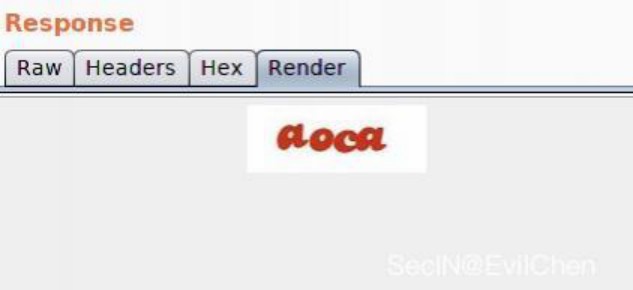
关注一下接口地址:https://attack/validcode?w=130&h=53
参数值:w=130&h=53,我们可以理解为生成的验证码大小长为130,宽为53
可以将w=130修改为w=130000000000000000,让服务器生成超大的图片验证码从而占用服务器资源造成拒绝服务。
Zip炸弹
不知道各位有没有听说过Zip炸弹,一个42KB的压缩文件(Zip),解压完其实是个4.5PB的“炸弹”。
先不说4.5PB这个惊人的大小,光解压都会占用极大的内存。
该文件的下载地址:https://www.bamsoftware.com/hacks/zipbomb/42.zip

解压这个
42.zip以后会出现16个压缩包,每个压缩包又包含16个,如此循环5次,最后得到16的5次方个文件,也就是1048576个文件,这一百多万个最终文件,每个大小为4.3GB。
因此整个解压过程结束以后,会得到1048576 * 4.6 GB = 4508876.8 GB,也就是4508876.8 ÷ 1024 ÷ 1024 = 4.5 PB。
通过以上说明,我们可以寻找存在解压功能的Web场景进行拒绝服务攻击,但是这里有一个前置条件就是需要解压并可以递归解压。
那我们想要完成这一攻击就非常的困难了,“前辈”也提到了非递归的Zip炸弹,也就是没有嵌套Zip文件文件的,如下表格:
存在解压功能的Web场景还是比较多的,可以根据实际业务场景进行寻找。
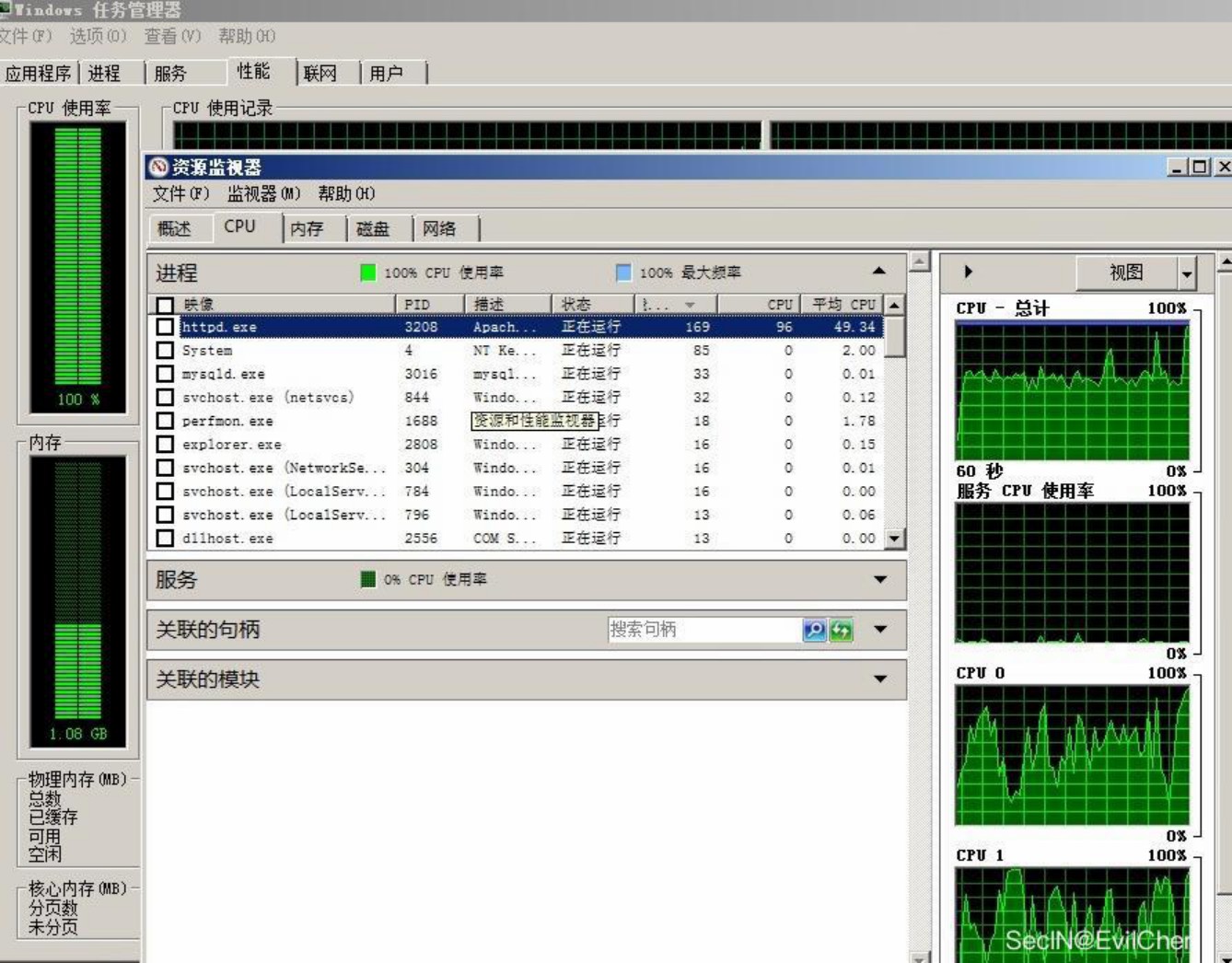
根据实际业务场景发现一处上传模板文件功能,根据简单的测试,发现此处上传Zip文件会自动解压:

这里我选择上传zbsm.zip上去,看一下服务器反应:

这里整个服务的请求都没有返回结果,成功造成拒绝服务。
XDoS(XML拒绝服务攻击)
XDoS,XML拒绝服务攻击,其就是利用DTD产生XML炸弹,当服务端去解析XML文档时,会迅速占用大量内存去解析,下面我们来看几个XML文档的例子。
据说这被称为十亿大笑DoS攻击,其文件内容为:
]> <keyz>&key9;keyz>
这是一段实体定义,从下向上观察第一层发现key9由10个key8组成,由此类推得出key[n]由10个key[n-1]组成,那么最终算下来实际上key9由10^9(1000000000)个key[..]组成,也算是名副其实了~
本地测试解析该XML文档,大概占用内存在2.5GB左右(其他文章中出现的均为3GB左右内存):
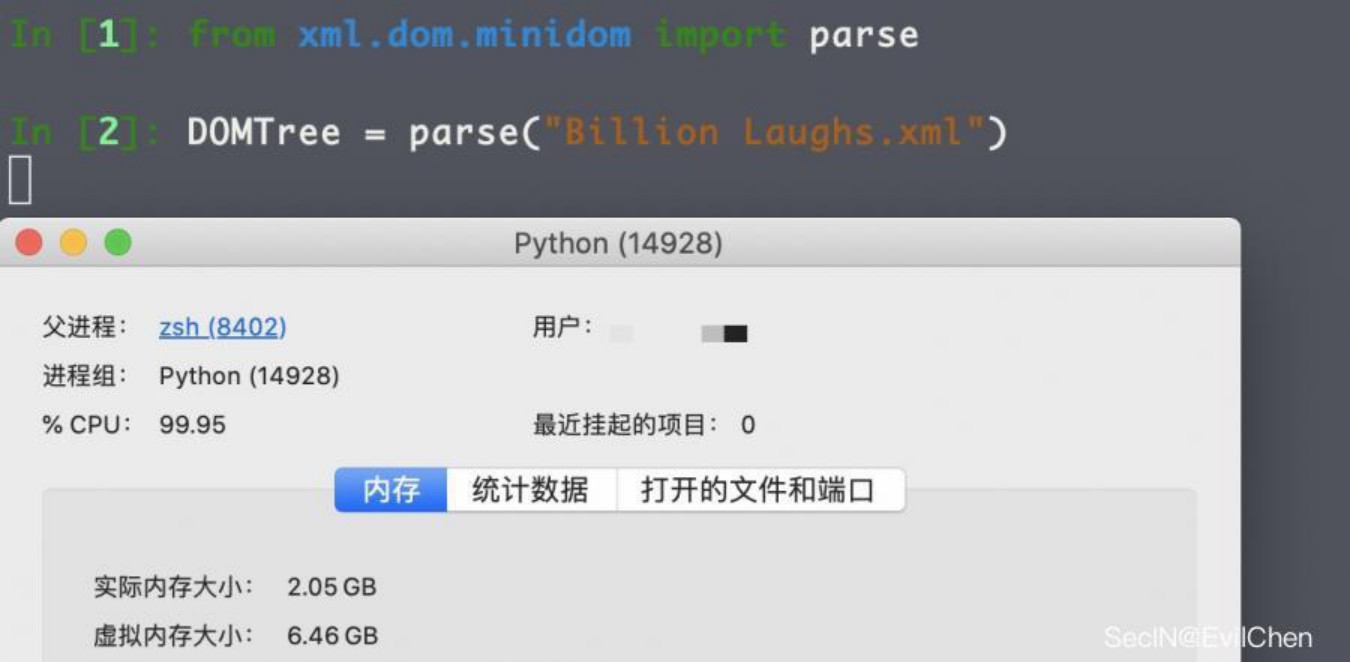
试想:这只是9层级炸弹,如果再多一点呢?
外部实体引用,文档内容如下:
]> <keyz>&wechat;keyz>
这个理解起来就很简单了,就是从外部的链接中去获取解析实体,而我们可以设置这个解析URL为一个超大文件的下载地址,以上所举例就是微信的。
当然,我们也可以设置一个不返回结果的地址,如果外部地址不返回结果,那么这个解析就会在此处一直挂起从而占用内存。
内部实体引用,文档内容如下:
]> <keyz>&a;...&a;keyz>
其意思就是实体a的内容又臭又长,而后又N次引用这个实体内容,这就会造成解析的时候占用大量资源。

一开始通过此处上传doc文档的功能,发现了一枚XXE注入,提交后厂商进行修复,但复测后发现其修复的结果就是黑名单SYSTEM关键词,没办法通过带外通道读取敏感数据了~
抱着试一试的心态将Billion Laughs的Payload放入到doc文档中(这里与XXE doc文档制作方式一样修改[Content_Types].文件,重新打包即可):
上传之后产生的效果就是网站延时极高,至此就完成了整个测试。
ReDoS(正则表达式拒绝服务攻击)
ReDoS,正则表达式拒绝服务攻击,顾名思义,就是由正则表达式造成的拒绝服务攻击,当编写校验的正则表达式存在缺陷或者不严谨时,攻击者可以构造特殊的字符串来大量消耗服务器的系统资源,造成服务器的服务中断或停止。
在正式了解ReDoS之前,我们需要先了解一下正则表达式的两类引擎:
| 名称 | 区别 | 应用 | 匹配方式 |
|---|---|---|---|
| DFA | DFA对于文本串里的每一个字符只需扫描一次,速度快、特性少 | awk(大多数版本)、egrep(大多数版本)、flex、lex、MySQL、Procmail… | 文本比较正则 |
| NFA | NFA要翻来覆去标注字符、取消标注字符,速度慢,但是特性(如:分组、替换、分割)丰富 | GNU Emacs、Java、grep(大多数版本)、less、more、.NET语言、PCRE library、Perl、PHP(所有三套正则库)、Python、Ruby、set(大多数版本)、vi… | 正则比较文本 |
文本比较正则:看到一个子正则,就把可能匹配的文本全标注出来,然后再看正则的下一个部分,根据新的匹配结果更新标注。
正则比较文本:看见一个字符,就把它跟正则比较,匹配就标注下来,然后接着往下匹配。一旦不匹配,就忽略这个字符,以此类推,直到回到上一次标注匹配的地方。
那么存在ReDoS的核心就是NFA正则表达式引擎,它的多模式会让自身陷入递归险境,从而导致占用大量CPU资源,性能极差,严重则导致拒绝服务。
简单的聊一下什么是回溯,这里有一个正则表达式:
ke{1,3}y
其意图很简单,e字符需要匹配1-3次,k、y匹配一次即可。
现在我们遇到了两个需要匹配的字符串:
- keeey
- key
字符串keeey的匹配过程是一气呵成的:匹配k完成之后,完整匹配e,最后是匹配y
字符串key的匹配过程就发生了回溯,其匹配过程如下图所示(橙色为匹配,黄色为不匹配):
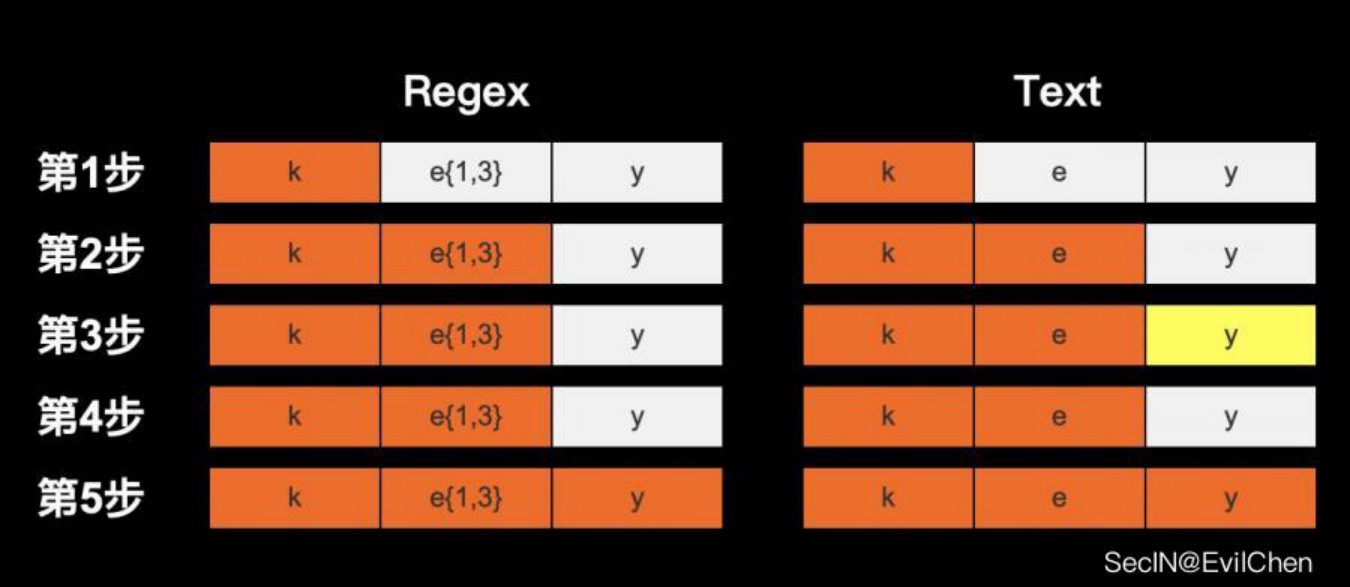
前两步属于正常,但从第3步开始就不一样了,这里字符串key已经有一个e被e{1,3}匹配,但它不会就此作罢,而会继续向后用正则e{1,3}匹配字符y,而当发现字符不匹配后,就忽略该字符,返回到上一次标注匹配的字符e再进行一次匹配,至此就发生了一次回溯,最后匹配y结束整个正则匹配过程。
那么为什么会产生回溯呢?这跟NFA的贪婪模式有关(贪婪模式默认是开启的)。
我们想要彻底摸清楚整个过程就要抛根问底,究其原理,所以来了解一下贪婪模式~
根据以上所举的案例我们可以理解贪婪模式导致的回溯其实就是:不撞南墙不回头
以下所列的元字符,大家应该都清楚其用法:
i. ?: 告诉引擎匹配前导字符0次或一次,事实上是表示前导字符是可选的。
ii. +: 告诉引擎匹配前导字符1次或多次。
iii. *: 告诉引擎匹配前导字符0次或多次。
iv. {min, max}: 告诉引擎匹配前导字符min次到max次。min和max都是非负整数。如果有逗号而max被省略了,则表示max没有限制;如果逗号和max都被省略了,则表示重复min次。
默认情况下,这个几个元字符都是贪婪的,也就是说,它会根据前导字符去匹配尽可能多的内容。这也就解释了之前所举例的回溯事件了。
错误的使用以上所列的元字符就会导致拒绝服务的风险,此类称之为恶意的正则表达式,其表现形式为:
- 使用重复分组构造
- 在重复组内会出现:重复、交替重叠
简单的表达出来就是以下几种情况(有缺陷的正则表达式会包含如下部分):
- (a+)+
- ([a-zA-Z]+)*
- (a|aa)+
- (a|a?)+
- (.*a){x} for x > 10
对于复杂的恶意正则表达式,靠人工去看难免有些许费劲,推荐一款工具:https://github.com/superhuman/rxxr2/tree/fix-multiline (安装参考项目的readme)
该工具支持大批量的正则表达式检测,并给出检测结果。
实际场景
很庆幸的是大多Web脚本语言的正则引擎都为NFA,所以也很方便我们做一些Web层面的挖掘。
做测试的时候大家有没有发现过这样一个逻辑:密码中不能包含用户名

这是一个用户添加的功能,其校验是通过后端的,请求包如下
POST /index/userAdd HTTP/1.1 Host: [host] ... nickname=xxx&password=xxx&...
当password中包含nickname则提示密码中不能包含用户名
利用Python简单还原一下后端逻辑:
# -*- coding: utf-8 -*- import sys,re username = sys.argv[1] password = sys.argv[2] regex = re.compile(username) if (regex.match(password)): print u'密码中不能包含用户名' else: print u'用户添加成功'

这时候用户名是一个正则,密码是一个待匹配字符串,而这时候我们都可以进行控制,也就能构建恶意的正则的表达式和字符串进行ReDoS攻击。
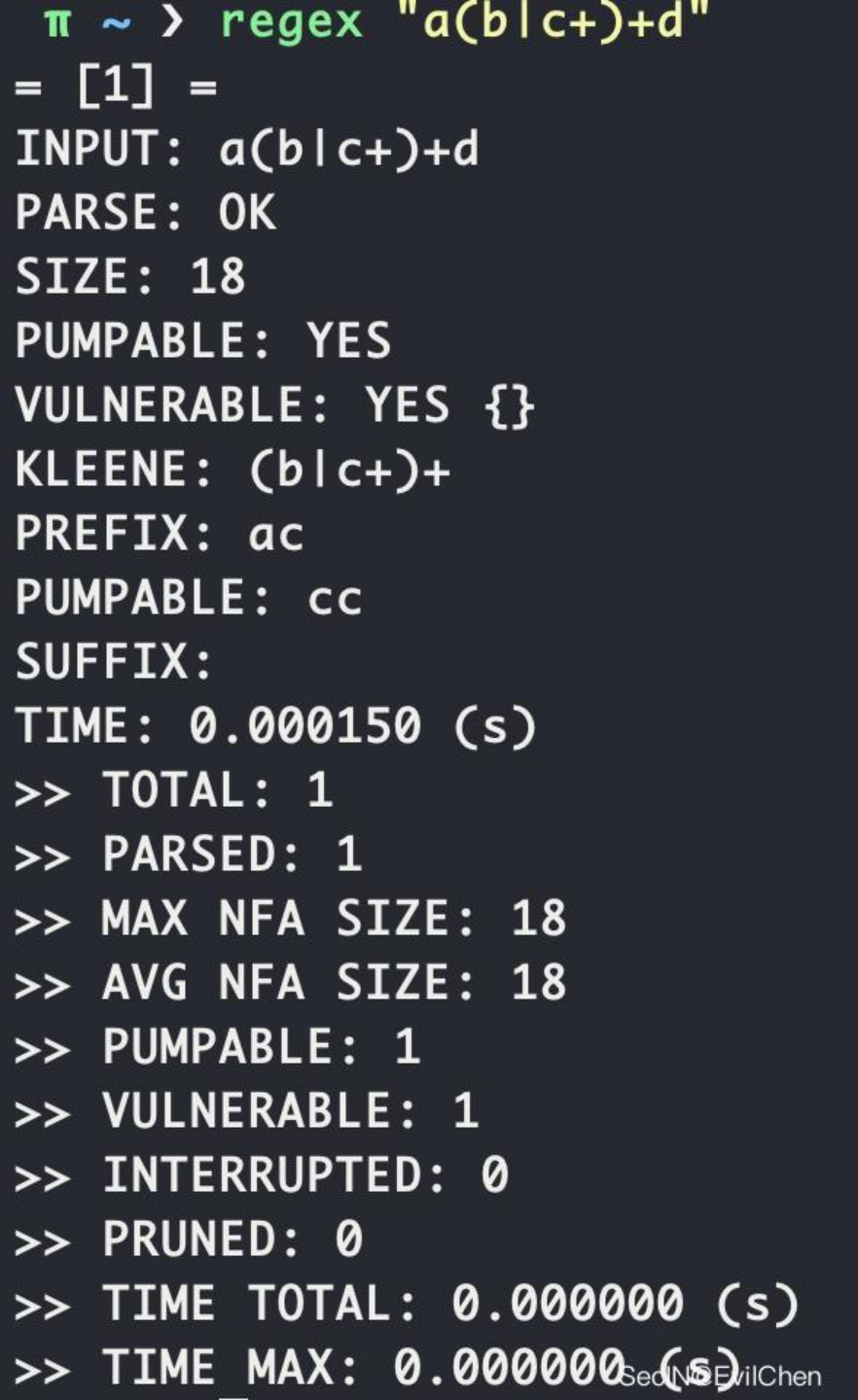
恶意的正则表达式:a(b|c+)+d
字符串(我们要想让其陷入回溯模式就不能让其匹配到,所以使用ac......cx的格式即可):acccccccccccccccccccccccccccccccccccccccccccccccccccccccccccccccccccccccccccccccccccccccccccccccccccccccccccccccccccccccccccccccccx
如下图所示ReDoS攻击成功:

我们只需要以同样的方式替换原请求包中的参数值即可(前提是该功能没有限制字符串长度和特殊字符)~
还有更多应用场景等待去发现,这里就不过多赘述了~
数据查询数量可控
想必如下这类接口大家都见多了吧:
- /api/getInfo?page=1&page_size=10 ...
- /api/viewData?startTime=&endTime=1591258015173 ...
- ...
而这类接口通常都是调用数据的,当一个系统数据量十分大(这也是拒绝服务的前提)的时候就需要分页功能去优化性能,那我们尝试将这个可控的数据查询量的参数数值进行修改会怎么样?比如page_size=10000,再去请求会发现服务器明显有返回延迟(大量数据的查询展示):

那如果是page_size=100000000000呢?想象一下,从查询到数据格式的处理返回展示,要占用巨大的服务器资源,我们如果尝试去多次重放此类请求,服务器终究还是无法承受这样的“力量”,最后导致宕机…
时间参数startTime也是如此,我们可以置空或设为0让其查询数据的时间范围为最大…以此类推、举一反三。
References
https://bbs.pediy.com/thread-252487.htm
https://www.checkmarx.com/wp-content/uploads/2015/03/ReDoS-Attacks.pdf
https://zhuanlan.zhihu.com/p/41800341

