
- 1随笔小记(二十七)_epoch在论文中怎么翻译
- 2YOLOV4学习小总结_yolov4 backbone的公式
- 3SpringBoot普通工具类中实现调用Mapper-1(使用@PostConstruct方式)_springboot 类文件使用@postconstruct初始化后的mapper还是null
- 4FIFO阈值如何设置?将满阈值与FIFO深度的关系?_fifo threshold
- 5python模块matplotlib.pyplot用法_Python matplotlib简介 Pyplot教程
- 6《自拍教程69》Python 批量重命名音频文件,AV专家必备!_69av
- 7Docker入门学习_docker学习
- 8sklearn多项式回归和线性回归
- 9C#搭建高效、便捷的WebSocket服务器和客户端_c# websocket
- 10操作系统实验(四)——页面置换算法(附C语言代码)_操作系统页面置换算法代码
GPU基本介绍与各GPU性能、价格比较_gpu型号
赞
踩
1 GPU基本概念
1.1 CUDA
CUDA(Compute Unified Device Architecture),是显卡厂商NVIDIA推出的运算平台。 CUDA™是一种由NVIDIA推出的通用并行计算架构,该架构使GPU能够解决复杂的计算问题。
CUDA核心数量决定了GPU并行处理的能力,在深度学习、机器学习等并行计算类业务下,CUDA核心多意味着性能好一些。
1.2 Tensor(张量) 内核
CUDA是NVIDIA推出的统一计算架构,NVIDIA过去的几乎每款GPU都有CUDA Core,而Tensor Core是最近几年才有的,Tensor Core是专为执行张量或矩阵运算而设计的专用执行单元,而这些运算正是深度学习所采用的核心计算函数。Tensor核心在训练方面能够提供高达12倍的teraflops (TFLOPS) 峰值,而在推理方面则可提供6倍的TFLOPS峰值。每个Tensor核心每个时钟周期可执行64次浮点混合乘加 (FMA) 运算。

1.3 TFLOPS
FLOPS,即每秒浮点运算次数(亦称每秒峰值速度)是每秒所执行的浮点运算次数(英文:Floating-point operations per second;缩写:FLOPS)的简称,被用来评估电脑效能,尤其是在使用到大量浮点运算的科学计算领域中。
1.4 显存容量
显存容量:其主要功能就是暂时储存GPU要处理的数据和处理完毕的数据。显存容量大小决定了GPU能够加载的数据量大小。(在显存已经可以满足客户业务的情况下,提升显存不会对业务性能带来大的提升。在深度学习、机器学习的训练场景,显存的大小决定了一次能够加载训练数据的量,在大规模训练时,显存会显得比较重要。
1.5 显存位宽
显存位宽:显存在一个时钟周期内所能传送数据的位数,位数越大则瞬间所能传输的数据量越大,这是显存的重要参数之一。
2 GPU架构
- 第一代是2006年推出的G80架构,CUDA的元年;
- 第二代是2008年推出的GT200架构(类似G80);
- 第三代GPU架构Fermi,2010年3月27日英伟达发布的一个显卡架构,支持CUDA;
- Kepler架构在2012推出;
- Maxwell架构在2014年被推出。和上一代Kepler架构相同,采用的也是28nm工艺;
- Pascal架构在2016年3月被推出,采用16nm和14nm的工艺;
- Volta架构:2017年5月。Tensor Core的引入。
- Turing架构在2018年9月的SIGGRAPH正式发布。和Volta相同,Turing也基于TSMC 12nm工艺完成生产。从AI计算的角度,Turing主要面向推理场景。
- Ampere架构在2020年5月发布
3 英伟达GPU类别
gpu架构:Tesla、Fermi、Kepler、Maxwell、Pascal
芯片型号:GT200、GK210、GM104、GF104等
显卡系列:GeForce-家庭娱乐、Quadro-工作站、Tesla-服务器
GeForce显卡型号:G/GS、GT、GTS、GTX、RTX
显卡系列在本质上并没有什么区别,只是NVIDIA希望区分成三种选择,GeFore用于家庭娱乐,Quadro用于工作站,而Tesla系列用 于服务器。Tesla的k型号卡为了高性能科学计算而设计。
GeForce的显卡型号是不同的硬件定制,越往后性能越好,时钟频率越高显存越大,即G/GS<GT<GTS<GTX<RTX。
GTX 到RTX:RTX20显卡采用的“图灵”架构引入了RT计算单元,使其光线追踪性能超越上一代显卡的六倍,拥有了即时处理游戏光追的条件,NVIDIA认为这是一个划时代的进化,于是果断把沿用多年的“GTX”改名为“RTX”。
4 独立GPU市场情况
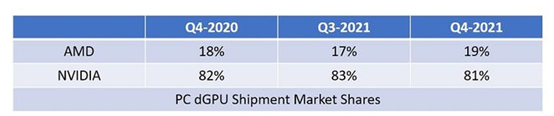
Jon Peddie Research(JPR)发布了新的GPU市场数据统计报告。在台式机和笔记本电脑使用的独立显卡(gpu)中,英伟达(NVIDIA)占据了81%的市场份额,而AMD是19%。英特尔公司主要是在集成GPU上占有市场。
5 各GPU比较
下表价格是2022年2月28日京东查的价格,基本上价格越贵性能越好,虽然价格炒高了很多:


