
- 1新魔百和M301H_关于CW代工_JL(南传)代工_zn及sm代工区分及鸿蒙架构全网通卡刷包刷机教程_m301h刷机
- 2ajax请求报parsererror错误_ajax parsererror是什么错误
- 3云端技术驾驭DAY15——ClusterIP服务、Ingress服务、Dashboard插件、k8s角色的认证与授权
- 4kubeCon2020重磅演讲:基于k8s构建新一代私有云和容器云_captain k8s
- 5HTML+CSS:3D轮播卡片
- 6Python+医学院校二手书管理 毕业设计-附源码201704_基于python的校园二手交易平台论文开题报告
- 7python函数递归求和详解_Python函数中多类型传值和冗余参数及函数的递归调用
- 8【毕业设计】ASP.NET 网上选课系统的设计与实现(源代码+论文)_aspnet毕业设计含代码
- 9Stable Diffusion提示词总结_stable diffusion 提示词详解
- 10玩转k8s:Pod详解_k8s pod配置文件查看
数据分析中应该了解的几种常用预测方法
赞
踩
中文“预测”的含义在“英语”情境下则有两种含义:
evaluate,“估算”,前文归因的方法中,是从因变量Y发现自变量X,也就是Y-->X,“估算”则是“归因”的逆操作——需要从已知的X来推导未知的Y,即X-->Y;
forecast,“预测”,基于“时间序列”来预估未来的数据,比如股票走势、业务发展趋势、交易量预估等等;
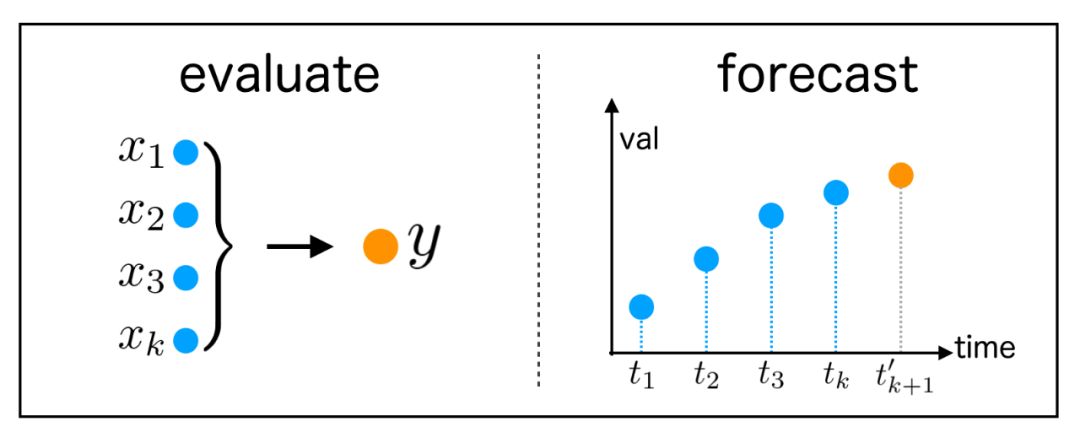
evaluate & forecast
关于 evaluate
“估算”常见有两种情况:
基于关联原则来类推,简称“类推法”,也就是先归类,然后推导。比如格子衫、发量少、戴眼镜、男性、程序员这几个特征是高度关联的,知道“格子衫”和“发量少”就能推断出此人职业很可能是“程序员”;
基于目标数据和已知数据存在“函数关系”,简称“函数法”或者“公式法”,即Y=f(X),基于函数规则就能计算得到目标数据Y。比如评估某次产品运营活动对交易产生的影响量(Y),那么对应需要考虑的X可能包含活动覆盖的人群属性、人群数量、活动方式、优惠力度等;
类推法
类推法可以分为两种:
相似个体类推,相似的个体通常其属性(特征)也具有相似性,如果要推算某个体的某属性,那么找到具有相似性的个体的属性作为预估值即可。
归属群体类推,人以类聚,物以群分,每个类群的整体属性和个体属性差异不会太大(只要不是极端个例),也可以理解为正态分布的群体的某属性的均值可以作为某个未知个体属性的替代值。
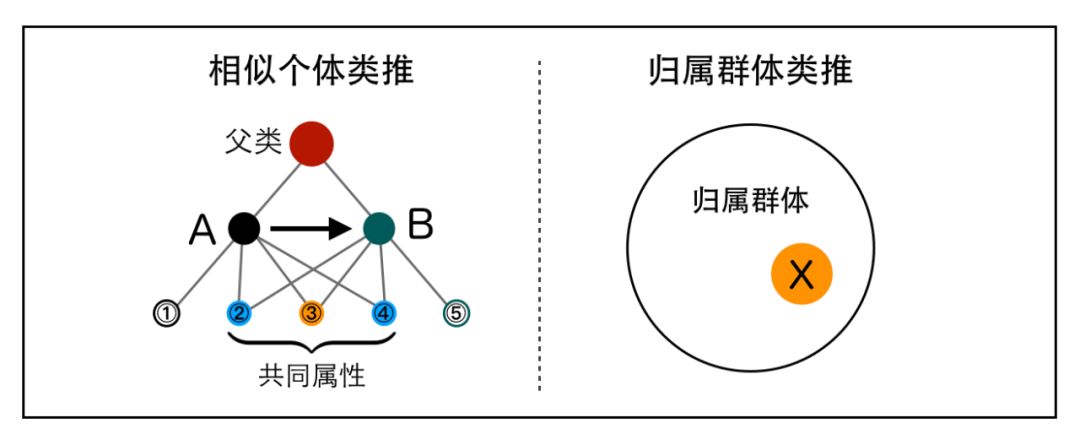
相似个体类推
如上图所示,假如现在我们要想估算主体B的属性③的数值(橙色标记目标数据),那么我们可以找到和B类似(AB在属性②、④上相似)且同时具有属性③的主体A,如果主体A的属性③是已知的,那么该数值可以当做主体B属性③的估算值,如果可以匹配的已知相似属性更多,得到的值一般更精确。
e.g. 要推算京东在微信端交易订单量占整体交易量的占比,可以借鉴唯品会的数据。首先唯品会和京东的业务模式具有较高的相似性——都是电商平台(虽然主要品类结构不一样),主要交易端都是App\PC\Weixin这3个,唯品会和京东都在微信上都有“钱包入口”,整体上覆盖的人群结构也差不多——现在知道了唯品会微信上交易量的占比(数据已经相对稳定),那么该数值可以作为预估京东数据的参考值基准。
注:因为京东在“发现”页还有入口,而且唯品会和京东的交易量级以及品类结构上存在差异,所以数据还需要进一步调整。
归属群体类推
如上图右图,基于背景知识,我们知道要推算的个体X归属于某个群体,那么可以用该群体的属性来推断X的对应属性。
e.g. 我们到野外偶遇一只不知所名的动物(未知的X),发现此动物尖牙利爪长尾巴(已知属性),这和我们平时见到的猫科动物(归属的群体)特征很匹配,我们知道猫科动物大多数是吃肉的,那么可以推断该动物也很可能不是吃素的(肉食动物)。
确定相似性可以参考的特征:
空间属性,比如所处地理位置相同,具有类似的结构或者模式,体量差不多,或者归属的群体是一致的等等;
时间属性,所处的时代相同,主体的生命周期差不多等;
函数法
目标数据和已知数据存在“函数关系”,即Y=f(X),基于函数规则就能计算得到目标数据Y。
常见的两种函数或者公式如下:
连乘公式,常见于存在转化率或集合包含关系的情况
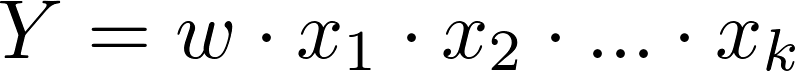
加权公式,常见于存在多个成分或分类的情况
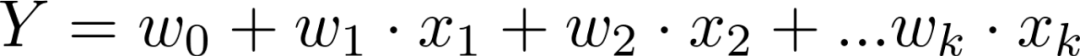
使用函数法需要明确目标数据的函数表达式,以及需要知道函数表达式中各变量的数值。
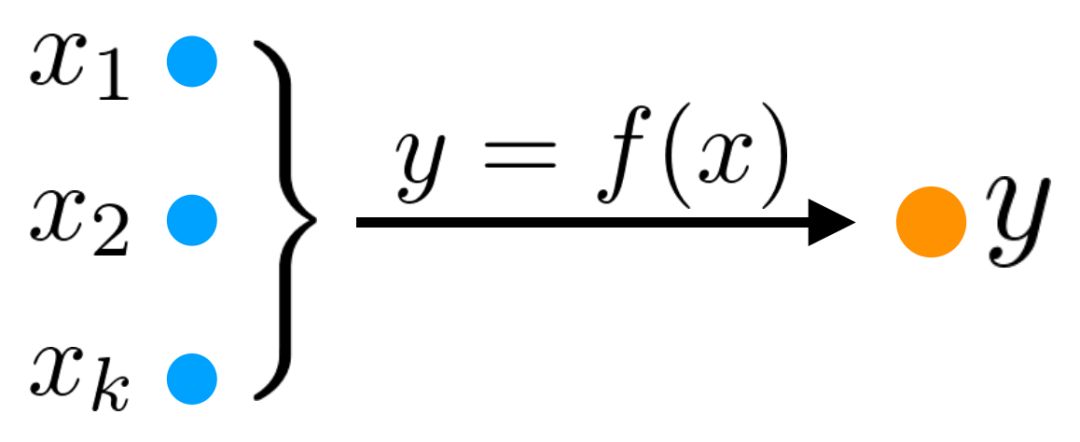
函数法中,因变量Y和自变量X的具有高相关性。
使用函数法进行估算的案例,可以参考前文从一道面试题谈数据推算方法。
在该案例中,估算目标用户群数量时用的就是连乘公式。
该城市总人口1000W,设符合用车条件的人群(16-60)占比为60%(这个数据也可以到国家人口普查数据上找);设上述人群中有互联网产品使用经验的比例为60%(可以查下中国互联网普及率);设有短距离出行需求的人数比例为15%(大多数时候选择的交通工具是地铁、公交、自驾);设该公司在该城市的市场份额为30%(假设要和ofo、摩拜3分天下,这里的30%是假设只有3家投放单车时的值),基于以上假设可以得到目标用户数为:1000W*60%*60%*15%*30% ≈ 16W人
AhongPlus,公众号:数据分析007从一道面试题谈数据推算方法
e.g. 假设现在需要预估一次运营活动带来的交易量,那么可以先对交易量“细分”,看看活动覆盖哪些人群、覆盖哪些端口、不同人群或端口的交易转化率(可以参考历史数据或业务经验)等,把每个细分人群细分端口的交易计算出来,再进行加总即可。
关于 forecast
基于时间序列的趋势预测,是基于历史数据预测未来发生的事件。
e.g. 进行年度KPI预测的时候,可以拟合历年的实际交易数据——一般业务过了成熟期,就能看到比较明显的S曲线(sigmoid curve)——基于拟合的曲线就能大致预测出下一年的交易量了。这个预测值可以作为基准,还要考虑业务上新的变化对数据进行调整,比如产品功能改变、人群定位变化等、渠道入口发生改变等。
e.g. 交易预估流程(先用线性回归预测2018年度的总交易,然后拆分到季度)
注:此处交易是有明显的季节性变化趋势的。
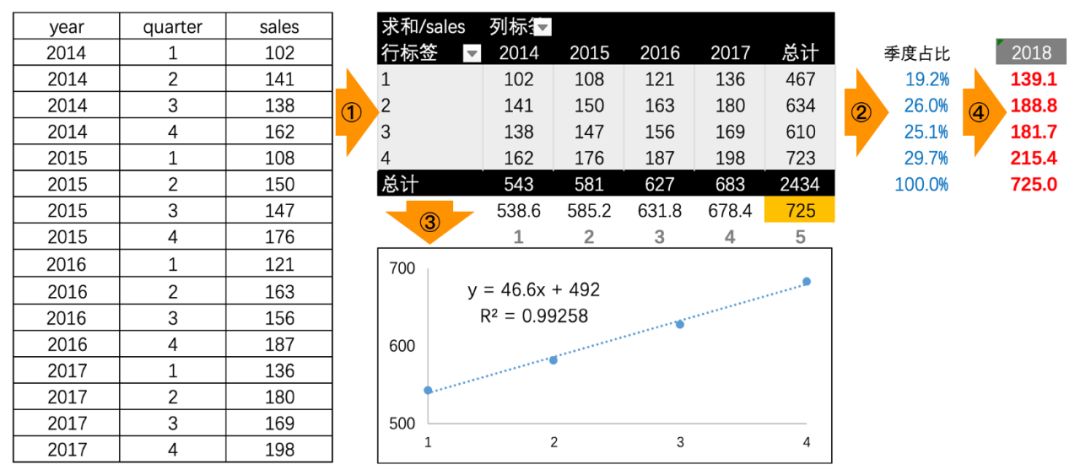
注:该案例也可以Holt-Winters法来操作,把Residual的部分区分出来。
时间序列可以分解(decomposition)为4部分:
参考:https://en.wikipedia.org/wiki/Decomposition_of_time_series
长期趋势(Trend),比如持续的增长或者降低,这种趋势可能是线性也可能是非线性的(比如S型曲线);
季节变化(Seasonal),通常是一年时间内的周期波动(可能季度、月度或者周等不同时间颗粒度),季节变化通常是因为受到人们活动的周期性的影响而出现的。比如:①人行为上的周期性,e.g.一天的作息、一年4季的购衣需求、不同年龄阶段的行为模式等;②周期性的社会活动,e.g.节假日、定期行业集会等;③商业业务的周期性,e.g.唯品会的早10晚8上新、公众号通常在上班前或者下班后发布消息等;
发展周期(Cycle),不同于季节变化,发展周期的时间跨度更长(通常是两年以上),而且和事物的生命周期有关(比如产品的生命周期等);
随机噪声(Reminder,或Residual),不能归于以上3类的部分被称为不规则剩余(Irregular Remainder),可以看做是时间序列数据中的随机成分;
举个例子,原始时间序列如下图所示:
数据源:https://raw.githubusercontent.com/jbrownlee/Datasets/master/airline-passengers.csv

可以分解为3部分(此处不考虑“发展周期”因素):
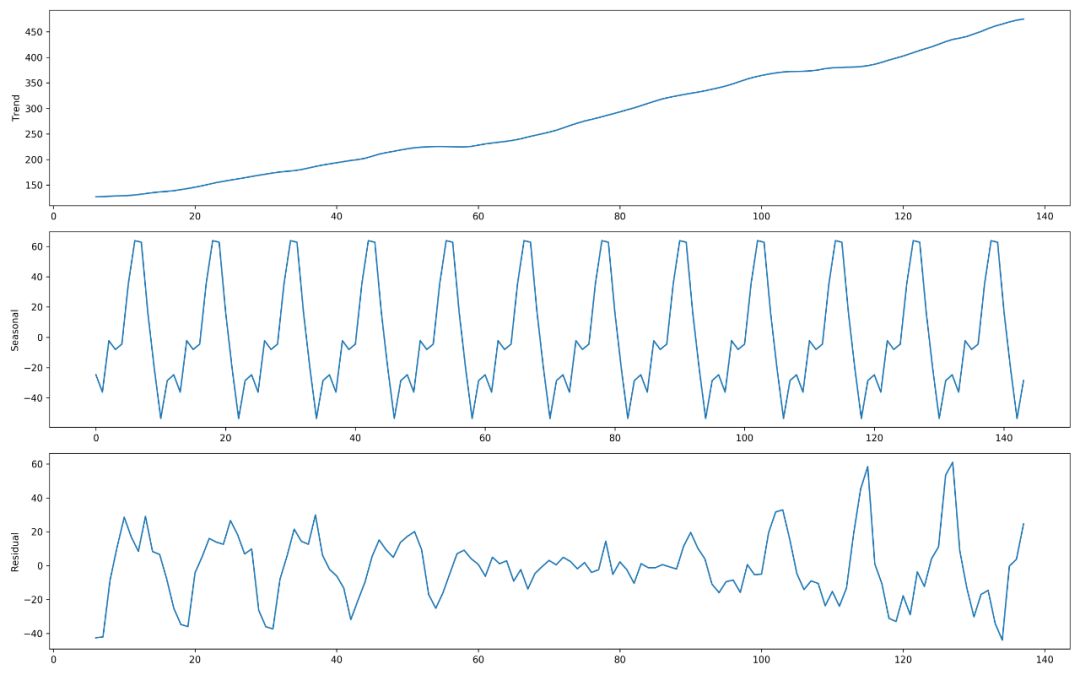
注:此处采用Holt-Winters’ additive method来分解,调用函数为statsmodels.tsa.seasonal.seasonal_decompose
时间序列预测的流程可以参考下图
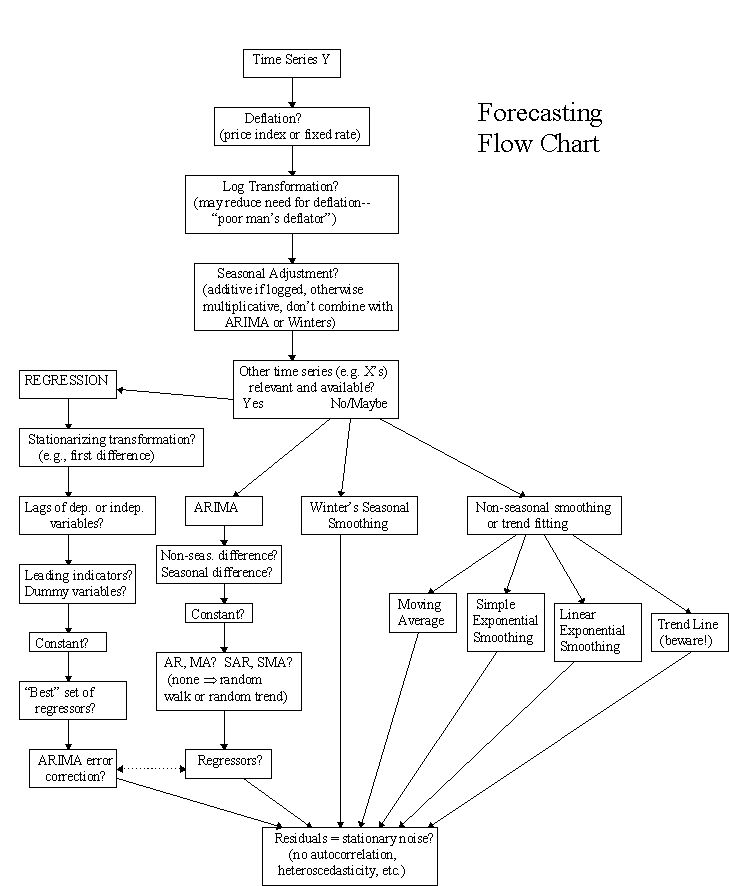
来源:http://people.duke.edu/~rnau/411fcst.htm
对于数据转化和预测方法的选择可以参考
http://people.duke.edu/~rnau/whatuse.htm
https://otexts.com/fpp2/transformations.html
https://hbr.org/1971/07/how-to-choose-the-right-forecasting-technique
Selecting Forecasting Methods, J. Scott Armstrong
时间序列预测常见方法:
回归模型,对于历史数据进行拟合(可能是线性也可能是非线性),线性的情况意味着长期的变化趋势基本一致(平稳增长或者平稳下降),非线性的情况则说明变化的速度不稳定(比如生长曲线);
ARIMA模型,差分自回归移动平均模型(Autoregressive integrated moving average),ARIMA由自回归模型、移动平均模型和差分法结合而来;
更多参考https://otexts.com/fpp2/arima.html
https://en.wikipedia.org/wiki/Autoregressive_integrated_moving_average
Holt Winters'方法,也被称之为季节分解法,将原始时间序列分为level(基线)、trend(变化趋势)、season(季节性波动)3部分;
更多参考https://otexts.com/fpp2/holt-winters.html
移动平均法(Moving Average),通常用于时间序列比较平稳的情况(stationary);
指数平滑法(Exponential Smoothing),对于参与预测的时间周期进行加权,可以看做是加权版的移动平均法;
关于时间序列预测的实操(Python)可以参考:
https://www.analyticsvidhya.com/blog/2018/02/time-series-forecasting-methods/
https://www.analyticsvidhya.com/blog/2016/02/time-series-forecasting-codes-python/
基于时间序列的趋势预测时,需要注意:
要有完成的观测周期,小心“黑天鹅”现象——火鸡观测了1000天没有被吃掉,不能代表第1001天依然好运,所以完整的观测周期很重要;
数据的周期长短要视具体的业务场景,比如可能考察产品的周期性,也可能是某个用户群等,不同的场景的时间颗粒度也不一样;
发展趋势中需要区分自然因素和“人工”因素,自然因素是不可控的(比如PEST等外部因素的影响),“人工”因素是可控的,在进行预测时最好将不可控的随机成分和可控的稳定成分区分开;
业务发展的预测要考虑市场环境以及产品生命周期,有可能这个市场本身就在缩小,或者产品已经经历了成熟期;
注意观测期和预测期是否会出现一些大的变化,比如产品的功能、业务覆盖的人群、外部市场环境等,对预测指标影响较大的因素出现时,那么观测期的数据和预测期的数据大概率不能“同日而语”,需要进行较大的调整;
其他注意事项可以参考:http://people.duke.edu/~rnau/notroubl.htm
参考资料:
活动数据,驱动业务的数据分析实战,陈哲,8.3.1
http://people.duke.edu/~rnau/411home.htm
Forecasting: Principles and Practice,https://otexts.com/fpp2/
http://ucanalytics.com/blogs/forecasting-time-series-analysis-manufacturing-case-study-example-part-1/
https://corporatefinanceinstitute.com/resources/knowledge/modeling/forecasting-methods/
http://www.forexabode.com/forex-school/technical-indicators/moving-averages/which-moving-averages-of-what-time-frames-are-best/

