
- 1C++迭代器 iterator详解_c++ iterator
- 207代码随想录训练营day07|哈希表part02
- 3基于C++的学生信息管理系统_c++信息管理系统
- 4如何构造linux根文件系统_nsenter.c:(.text.nsenter_main+0x184): undefined re
- 5Pyecharts一文速学-绘制树状图参数详解+Python代码_python绘制树状图
- 6SCons上手教程_scons教程
- 7DOCKER容器中安装JDK1. 8 详细步骤_docker安装jdk1.8
- 8本科学计算机数学吗,计算机科学本科核心课程教材·计算机数学
- 9JavaWeb中Servlet、web应用和web站点的路径细节("/"究竟代表着什么)
- 10统信UOS专业版服务器无人值守安装_uos 无人值守grub参数
全网最全Python金融大数据挖掘与分析,基础篇(附源代码,pycharm专业版无限期申请)
赞
踩
个人公众号 yk 坤帝
后台回复 python金融基础 获取源代码
1.pycharm专业版无限期申请
1.1 Python安装与第一个Python程序
1.2 Python基础知识
1.3 Python最重要的三大语句详解
1.4 函数与模块
附源代码

1.pycharm专业版无限期申请
主要通过pycharm编辑器进行编写代码,如果是学生党,可以直接申请无限期使用pycharm专业版。下面是申请方式:
JetBrains开发工具免费提供学生和教师使用。取得授权后只需要使用相同的 JetBrains 帐号就可以激活其他产品,不需要重复申请。
1. 获得(学生邮箱)教育邮箱
作为学生, 我们在入学时学校已经给了我们教育邮箱, 只是大多数人都不知道罢了, 邮箱为:

如何登陆呢, 这里附上山师学生邮箱官网, 点击下面链接登陆即可 http://mail.stu.sdnu.edu.cn/
注意, 若是用手机端进入的同学, 一定要切换到电脑版在登陆。 如下图:




2. 申请试用Jetbrains试用
当你拥有了你的学生邮箱, 就可以申请试用啦。
- 进入Jetbrains官网 https://account.jetbrains.com/login , 用自己的学生邮箱注册账号 (有时候Jetbrains官网相应的比较慢~请耐心等待) 若看不清下图请右击在新窗口打开~

- 点击sign up后,官方会发一封确认验证邮件到你的邮箱上, 有时候过好几分钟才会发过来, 请耐心等待一下吧。收到邮件设置好账号密码, 然后进入下一步~ 2. 进入 https://www.jetbrains.com/shop/eform/students, 开始填写资料。(有时候Jetbrains官网相应的比较慢~请耐心等待)
个人公众号 yk 坤帝
后台回复 邮箱申请 获取完整资源
1.1 Python安装与第一个Python程序
Python 是 Anaconda 的一个发新版本,安装好了 Anaconda就相当于安装好了Python。
Anaconda 的官网下载地址 https://www.anaconda.com/download/ ,或者直接网页搜索Anaconda,进入官网,选择下载即可。

安装到下图这一步的时候,一定要把第一个勾给勾选上,因为这个对于初学者来说,就相当于自动配置好了环境变量,不然还得麻烦手动配置。

然后一直点Next,下面这一步是否安装额外内容选择skip即可。

其他一直选择Next即可,最后点击Finish,那Python就安装完成啦。
Spyder打开方法如下:
电脑左下角打开Anaconda,点击Spyder即可。

Spyder显示如下界面:
1.其中左边红色框是写代码的地方
2.右边红色框则是输出代码结果的地方
3.上方的绿色的箭头则是运行代码的标志
- 1
- 2
- 3

下面就让我们来写第一个Python程序吧,在左边输入代码的地方,在英文模式下输入:
print (‘hello world’)
- 1
然后点击上方绿色的运行按钮,在Spyder里,也可以按F5来运行程序。

注意:输入时候必须切换到英文模式,其中单引号,双引号在Python中没有区别。
补充:编译器Pycharm安装(推荐安装)
我们之后的教学大多都是使用Pycharm来进行讲解,Pycharm 和Spyder的功能是大致相同的。如果不想安装Pycharm,可以跳过这一步。
注意:第一次运行Pycharm的时候Index缓冲的时间较长,以后就好多了。
到官网 :http://www.jetbrains.com/pycharm/download/#section=windows 下载PyCharm安装包,我们选择免费版(Community)就完全够用了。

下载完后,双击就可以安装了,安装过程中,一直选择Next和Install即可,其中这一页选择下面两项即可。

之后一直点击Next一直到最后的Finish(结束)出现之后点击Finish即可。
按完Finish之后的第一步:这个勾选“Do not import settings“

第二步:选择页面风格,建议选择默认的黑色风格。
第三步:选择辅助工具,直接跳过,啥也不需要选。

第四步:点击“Create New Project”创建Python文件。
第五步:文件进行命名,这一步千万记得点开Project Interpreter,勾选Existing interpreter。

然后点击最右边的 ,如下图:在弹出的页面中选择System Interpreter, 可以看到Interpreter变成了Anaconda3\Python.exe,选择OK。

回到项目创建页面后,点击Create即可创建新的Python Project
第六步:关闭官方小技巧提示,等待最下面的Index缓冲完毕,它缓冲的过程其实是在配置你Python的运行环境。

等到最下面的那个Index已经缓冲完毕后,我们可以进行下一步。
第七步:创建Python文件,如下图,点击之前创建的项目文件夹,然后右键,点击New,选择Python File。

将新的Python文件命名为 hello world。
你之后如果要新建文件的话,可以在File里面选择New Project,如下图所示:

然后重复上诉步骤,注意在选Project Interpreter的时候勾选Existing interpreter。
第八步:在英文模式下输入print(‘hello world’)
其中单引号双引号没有区别 (和Spyder一样)
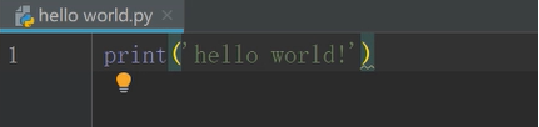
我们在上或者代码输入框内右击,选择Run ‘hello world’。
你也可以通过点击界面右上角的绿色运行按钮 ,
运行程序,或者按住快捷键 Ctrl+ Shift + F10也可以运行程序。

改变字的大小:
大家先点击File,选择下图的Settings。

选择Settings中的Editor,选择Font,如下图所示,在右边的Size里可以调节显示字体的大小以及行间距。

1.2.1 变量、行、缩进与注释
(1) 变量

关于变量的命名:大家尽量用字母a,b,c,a_1,b_1等,或者自己创建的字符,不要用系统自带的函数来命名,比如说不要用print来命名,写成print = 1,这样程序就会头疼了。
使用 “= + − × ÷ > < ” :
输入下面的程序:

运行的结果:
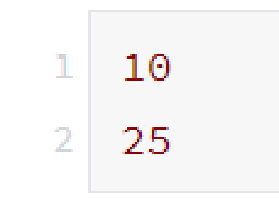
如果我们不打出 print(x)和 print(y), python只会保存x 和 y的结果,并不会显示结果
(2) 行
在Python中,一般来说,很少用逗号或者分号,代码都是一行一行写的,所以每写完一句,在句尾,我们按一下Enter键,就可以进行换行。
(3)缩进 (缩进快捷键是Tab键)
在if,for,while等语句中都会使用到缩进
代码的输入法和中文翻译:


在第3行和第5行的print前面就必须要有缩进,否则Python会报错
注意:如果你要减少缩进,那么按住Shift +Tab键的话就可以撤销原来的缩进,你可以选择一片区域,按住Tab键进行缩进练习,再按住Shift + Tab键撤销原来的缩进
(4) 注释
Python回不运动你的注释,注释在程序中大多是做个提示的作用。
注释有两个方式:

你可以输入#或者‘’‘,或者在Pycharm中,注释的快捷键是Ctrl + /;在Spyder中,注释的快捷键为Ctrl + 1。
1.2.4运算符介绍与实践

1.4.1 函数的定义与调用


上面的函数Python代码写法是左边的例子第一行和第二行。
第三行的意思是让 x=1
弹出的结果回是:x+1=(1)+1=2
例子:

弹出结果改不了,因为没有办法改变x的价值:

(3) len()函数
Length 的缩写是len(): 意思是长度。
主要功能是统计列表元素个数
地下给大家做了一个示范:

(4) replace()函数
Replace:意思是代替
主要功能是替换你想替换的内容
低下给大家做了一个示范:

弹出的结果:

1.2.1 变量、行、缩进与注释
个人公众号 yk 坤帝 后台回复 python金融基础 获取源代码 # 1 变量 x = 10 print(x) x = x + 15 print(x) # 2 行 # 代码都是一行一行写的 # 3 缩进,先不用管这个什么意思,之后会讲,只要知道在if和else后面那个语句要有个缩进,按Tab键快速缩进 x = 10 if x > 0: print('正数') else: print('负数') # 4 注释 ''' 两种注释的方法: 1.#后的内容是注释的内容,# 是shift + 3按出来的 2.三个单引号左右包着 ''' # 这之后是注释内容,快捷键在pycharm里是ctrl + /,在spyder里是ctrl + 1 '''这里面是注释内容'''

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
1.2.2 数据类型-数字与字符串
# ============================================================================= # 1.2.2 数据类型-数字与字符串 # ============================================================================= 个人公众号 yk 坤帝 后台回复 python金融基础 获取源代码 # 不同类型的数据不可以相加,下面的内容会报错,我把它注释掉了 # a = 1 + '1' # print(a) a = 1 print(type(a)) a = '1' print(type(a)) # 将数字转换成字符串 a = 1 b = str(a) # 将数字转换成字符串,并赋值给变量b c = b + '1' print(c) # 将字符串转换成数字 a = '1' b = int(a) # 将字符串转换成数字,并赋值给变量b c = b + 1 print(c)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
1.2.3 列表与字典
# ============================================================================= # 1.2.3 列表与字典 # ============================================================================= 个人公众号 yk 坤帝 后台回复 python金融基础 获取源代码 # # 列表 class1 = ['丁一', '王二麻子', '张三', '李四', '赵五'] print(class1) list1 = [1, '123', [1, 2, 3]] print(list1) class1 = ['丁一', '王二麻子', '张三', '李四', '赵五'] for i in class1: # 这个for语句之后会重点讲,这边大家先运行看看效果即可 print(i) # 统计列表的元素个数的函数:len函数 class1 = ['丁一', '王二麻子', '张三', '李四', '赵五'] a = len(class1) print(a) # 调取一个列表元素的方法 class1 = ['丁一', '王二麻子', '张三', '李四', '赵五'] a = class1[1] print(a) # 选取多个列表元素的方法:列表切片 class1 = ['丁一', '王二麻子', '张三', '李四', '赵五'] a = class1[1:4] print(a) b = class1[1:] # 选取从第二个元素到最后 c = class1[-3:] # 选取从列表倒数第三个元素到最后 d = class1[:-2] # 选取倒数第二个元素前的所有元素(因为左闭右开,所以不包含倒数第二个元素) print(b) print(c) print(d) # 列表增加元素的办法:append方法,这个先了解下即可 score = [] score.append(80) print(score) score = [] score.append(80) score.append(90) score.append(70) print(score) # 列表转换成字符串,这个先了解下即可,很远之后才用的上 class1 = ['丁一', '王二麻子', '张三', '李四', '赵五'] a = ",".join(class1) print(a) '''字典,关于字典这个知识,先了解下即可''' # 字典名["键名"]提取值 class1 = {'丁一': 85, '王二麻子': 95, '张三': 75, '李四': 65, '赵五': 55} score = class1['王二麻子'] print(score) # 遍历字典内容1 class1 = {'丁一': 85, '王二麻子': 95, '张三': 75, '李四': 65, '赵五': 55} for i in class1: # 这个i代表的是字典中的键,也就是丁一、王二麻子等 print(i) print(class1[i]) # 遍历字典内容2 class1 = {'丁一': 85, '王二麻子': 95, '张三': 75, '李四': 65, '赵五': 55} for i in class1: print(i + ':' + str(class1[i])) # 注意要str把85等数字转换成字符串,才能进行字符串拼接 # 遍历字典内容3 class1 = {'丁一': 85, '王二麻子': 95, '张三': 75, '李四': 65, '赵五': 55} a = class1.items() print(a) '''元组和集合(了解即可)''' # 元组 其实和列表基本一样,区别在于元组里的元素不可修改,及包围的括号为小括号 a = ('丁一', '王二', '张三', '李四', '赵五') # 这就是个元组,是不是和列表很像呢 print(a[1:3]) # 集合 a = ['丁一', '丁一', '王二', '张三', '李四', '赵五'] print(set(a)) # 通过set()函数可以获得一个集合,集合一个主要特点,就是用来去重,结果为:{'丁一', '王二', '赵五', '张三', '李四'}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
1.2.4 运算符介绍与实践
# ============================================================================= # 1.2.4 运算符介绍与实践 # ============================================================================= # 1 算术运算符:+ 、-、*、/ a = 'hello' b = 'world' c = a + ' ' + b print(c) # 2 比较运算符: > , <, == score = -10 if score < 0: print('该新闻是负面新闻,录入数据库') a = 1 b = 2 if a == b: # 注意这边是两个等号 print('a和b相等') else: print('a和b不相等') # 3 逻辑运算符:not,and,or score = -10 year = 2018 if (score < 0) and (year == 2018): print('录入数据库') else: print('不录入数据库')
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
1.3.1 if语句
# ============================================================================= # 1.3.1 if语句 # ============================================================================= score = 100 year = 2018 if (score < 0) and (year == 2018): print('录入数据库') else: print('不录入数据库') score = 85 if score >= 60: print('及格') else: print('不及格') # 多种情况,这个用到的较少,了解即可 score = 55 if score >= 80: print('优秀') elif (score >= 60) and (score < 80): print('及格') else: print('不及格')
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
1.3.2 for语句
# ============================================================================= # 1.3.2 for语句 # ============================================================================= 个人公众号 yk 坤帝 后台回复 python金融基础 获取源代码 class1 = ['丁一', '王二麻子', '张三', '李四', '赵五'] for i in class1: print(i) # 这个i只是个代号,可以换成任何别的内容 class1 = ['丁一', '王二麻子', '张三', '李四', '赵五'] for haha in class1: print(haha) # for和range函数合用 for i in range(3): print('hahaha') ''' 总结 (1)对于"for i in 区域"来说,如果说这个区域是一个列表,那么那个i就表示这个列表里的每一个元素; (2)对于"for i in 区域"来说,如果说这个区域是一个range(n),那么那个i就表示0到n -1这n个数字,之前提到过,python中序号都是从0开始的,所以这边也是从0开始,到n - 1结束。 (3)对于"for i in 区域"来说,若区域是一个字典,那么i就表示字典的键名; ''' # 注意python中序号都是从0开始的 for i in range(5): print(i) # 在实战中的应用 title = ['标题1', '标题2', '标题3', '标题4', '标题5'] for i in range(len(title)): # len(title)表示一个有多少个新闻,这里是5;这里的i就表示数字0-4 print(str(i+1) + '.' + title[i]) # 这个其实把字符串进行一个拼接
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
1.3.3 while语句
# =============================================================================
# 1.3.3 while语句
# =============================================================================
个人公众号 yk 坤帝
后台回复 python金融基础 获取源代码
a = 1
while a < 3:
print(a)
a = a + 1 # 或者写成 a += 1,+=是一种偷懒的写法
# while True在爬虫实战中用于24小时不间断爬取,在第7讲将会详细讲解
while True:
print('hahaha')
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
1.3.4 try except异常处理语句
# ============================================================================= # 1.3.4 try except异常处理语句 # ============================================================================= 个人公众号 yk 坤帝 后台回复 python金融基础 获取源代码 try: print(1 + 'a') except: print('主代码运行失败') # 下面为实战中的演示 try: # 这里是百度新闻爬取的代码 print(1 + '1') print('百度新闻爬取成功') except: print('百度新闻爬取失败') try: # 这里是百度新闻爬取的代码,之后第五第七章会讲 print(1 + 'a') print('百度新闻爬取成功') except: print('百度新闻爬取失败') try: # 这里是新浪财经新闻爬取的代码,之后爬虫进阶课会讲 print('新浪财经新闻爬取成功') except: print('新浪财经新闻爬取失败') try: # 这里是微信推文爬取的代码,之后爬虫进阶课会讲 print('微信推文爬取成功') except: print('微信推文爬取失败')
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
1.4.1函数的定义与调用
# ============================================================================= # 1.4.1函数的定义与调用 # ============================================================================= 个人公众号 yk 坤帝 后台回复 python金融基础 获取源代码 # 定义及调用函数 def y(x): print(x+1) y(1) # 调用函数 def y(x): print(x+1) y(1) # 第一次调用函数 y(2) # 第二次调用函数 y(3) # 第三次调用函数 # 传入两个参数 def y(x, z): print(x + z + 1) y(1, 2) # 有时候不需要参数也可以定义函数,这个了解即可 def y(): x = 1 print(x+1) y() # 调用函数 # 函数在实战中的应用展示 def baidu(company): # 这里是具体爬虫代码,之后会讲 print(company + 'completed!') companys = ['华能信托', '阿里巴巴', '百度集团', '腾讯', '京东', '万科', '华为集团'] for i in companys: baidu(i) ''' 复习: 对于"for i in 区域"来说,如果说这个区域是一个列表,那么那个i就表示这个列表里的每一个元素; '''
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
1.4.2 函数返回值、作用域
# ============================================================================= # 1.4.2 函数返回值、作用域 # ============================================================================= 个人公众号 yk 坤帝 后台回复 python金融基础 获取源代码 # 这里的company只是个代号,你可以换成任何东西,比如keyword,cat,dog都可以,注意函数内容里的company也要相应改变 def baidu(keyword): # 这里是具体爬虫代码,第七章会讲 print(keyword + 'completed!') companys = ['华能信托', '阿里巴巴', '百度', '腾讯', '京东', '万科', '建设银行'] for i in companys: baidu(i) '''2.返回值''' def y(x): return(x+1) y(1) '''return相当于看不见的print,它是把原来该print的值赋值给了y(x)这个函数,学术点的说法就是该函数的返回值为:x+1''' def y(x): return(x+1) a = y(1) print(a) # 这样才能把 y(1) 打印出来,或者直接写print(y1) # 在实战中的应用 def baidu(keyword): # 这里是具体爬虫代码,之后讲 return(keyword + 'completed!') a = baidu('华能信托') print(a) # return不加括号也是可以的 def baidu(keyword): # 这里是具体爬虫代码,第七章会讲 return keyword + 'completed!' #这里把括号去掉了 a = baidu('华能信托') print(a) '''3.变量作用域(了解即可)''' x = 1 def y(x): x = x + 1 print(x) y(3) print(x) # 其实函数参数只是个代号,可以换成任何内容 x = 1 def y(z): z = z + 1 print(z) y(3) print(x)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
1.4.3 一些重要的基本函数介绍
# ============================================================================= # 1.4.3 一些重要的基本函数介绍 # ============================================================================= 个人公众号 yk 坤帝 后台回复 python金融基础 获取源代码 # 1 print函数,记得加括号即可,快捷方式,写pri的时候按一下tab键会自动变成print() print('hello world') print(1, 'hello', [1, 2, '123']) # 通过逗号,也可以同时打印多个内容(可以是不同类型的数据),会通过空格自动分隔 print(str(1) + 'hello') # 如果通过+号字符串拼接,则需要是同样是字符串类型 # 2 str函数与int函数 - 字符串与数字转换 score = 85 print('A公司今日评分为' + str(score) + '分。') # 不加str就成了字符串与数字相加会报错的 score = '85' score = int(score) # 不加int的话,下面字符串'85'和数字80没法比较 if score > 80: print('OK') # 2 len函数 # len函数可以统计列表里元素的个数 title = ['标题1', '标题2', '标题3', '标题4', '标题5'] href = ['网址1', '网址2', '网址3', '网址4', '网址5'] for i in range(len(title)): # len(title)表示一个有多少个新闻,这里是5 href[i] = 'www.baidu.com/' + href[i] # 这个其实就相当于 a = a + 1 print(str(i+1) + '.' + title[i]) # 这个其实把字符串进行一个拼接 print(href[i]) # len函数还可以统计字符串个数 a = '123华小智abcd' print(len(a)) # 4 replace函数 - 替换你想替换的内容 a ='<em>阿里巴巴</em>电商脱贫成“教材” 累计培训逾万名县域干部' a = a.replace('<em>','') a = a.replace('</em>','') print(a) # 5 strip函数 - 删除空白符 a =' 华能信托2018年上半年行业综合排名位列第5 ' a = a.strip() print(a) # 6 split函数 - 分割字符串 a = '2018年12月12日 08:07' a = a.split(' ')[0] print(a) # 注意,split分割完是一个列表 a = '2018年12月12日 08:07' a = a.split(' ') print(a) # 7 异常处理函数try except函数,其实应该叫异常处理语句,后来调整到1.3.4小节了 try: print(1 + 'a') except: print('主代码运行失败') try: # 这里是百度新闻爬取的代码 print(1 + '1') print('百度新闻爬取成功') except: print('百度新闻爬取失败') try: # 这里是百度新闻爬取的代码,之后第五第七章会讲 print(1 + 'a') print('百度新闻爬取成功') except: print('百度新闻爬取失败') try: # 这里是新浪财经新闻爬取的代码,之后爬虫进阶课会讲 print('新浪财经新闻爬取成功') except: print('新浪财经新闻爬取失败') try: # 这里是微信推文爬取的代码,之后爬虫进阶课会讲 print('微信推文爬取成功') except: print('微信推文爬取失败')
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
1.4.4 Python库与模块介绍
# ============================================================================= # 1.4.4 Python库与模块介绍 # ============================================================================= 个人公众号 yk 坤帝 后台回复 python金融基础 获取源代码 # 显示时间的一种方式 import time print(time.strftime("%Y/%m/%d")) # 显示时间的另一种方式 from datetime import datetime print(datetime.now()) # 上面的代码也可以这么写,不一定要写成from import import datetime print(datetime.datetime.now()) # 尝试获取百度首页的网页源代码,可以把这个网址换成别的试试看 import requests url = 'https://www.baidu.com/' res = requests.get(url).text print(res) # 获取Python官网首页的网页源代码 import requests url = 'https://www.python.org' res = requests.get(url).text # print(res) # 获取到的内容较多,感兴趣的读者可以将注释取消看看运行结果,小技巧:按Ctrl+/可以添加和取消注释
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
个人公众号 yk 坤帝
后台回复 python金融基础 获取源代码

