
- 1基于Java+SpringBoot+Vue前后端分离婚纱影楼管理系统设计和实现_springboot vue婚纱影楼系统
- 2保姆级教程-如何使用LLAMA2 大模型_如何调用 llama 的 api
- 3Jenkins忘记密码解决方案_jenkins忘记用户名和密码
- 4《Python编程:从入门到实践》第12章:武装飞船_python入门到实践中的 ship.bmg
- 52023美赛E题_2023美赛e题 背景 光污染是用来描述任何过度或不良的使用人工光。一些我们称之为
- 6MYSQL 8 UNDO 表空间 你了解多少
- 7vs code解决无法识别已安装python库的问题(Mac版)
- 8初始MyBatis,w字带你解MyBatis
- 9video 标签设置样式_video标签样式
- 10如何在论文中画出漂亮的插图?
Kafka详解(中)——Kafka客户端操作
赞
踩
3-1 shell列举
kafka安装目录下的bin目录包含了很多运维可操作的shell脚本,列举如下:
| 脚本名称 | 用途描述 |
|---|---|
| connect-distributed.sh | 连接kafka集群模式 |
| connect-standalone.sh | 连接kafka单机模式 |
| kafka-acls.sh | 设置Kafka权限 |
| kafka-broker-api-versions.sh | 检索代理版本信息 |
| kafka-configs.sh | 配置管理脚本 |
| kafka-console-consumer.sh | kafka消费者控制台 |
| kafka-console-producer.sh | kafka生产者控制台 |
| kafka-consumer-groups.sh | kafka消费者组相关信息 |
| kafka-consumer-perf-test.sh | kafka消费者性能测试脚本 |
| kafka-delegation-tokens.sh | 管理Delegation Token |
| kafka-delete-records.sh | 将给定分区的日志向下删除到指定的偏移量 |
| kafka-dump-log.sh | 用来查看Topic的的文件内容 |
| kafka-log-dirs.sh | 查询各个Broker上的各个日志路径的磁盘占用情况 |
| kafka-mirror-maker.sh | 在Kafka集群间实现数据镜像 |
| kafka-preferred-replica-election.sh | 触发preferred replica选举 |
| kafka-producer-perf-test.sh | kafka生产者性能测试脚本 |
| kafka-reassign-partitions.sh | 分区重分配脚本 |
| kafka-replica-verification.sh | 复制进度验证脚本 |
| kafka-run-class.sh | 执行任何带main方法的Kafka类 |
| kafka-server-start.sh | 启动kafka服务 |
| kafka-server-stop.sh | 停止kafka服务 |
| kafka-simple-consumer-shell.sh | deprecated,推荐使用kafka-console-consumer.sh |
| kafka-streams-application-reset.sh | 给Kafka Streams应用程序重设位移,以便重新消费数据 |
| kafka-topics.sh | topic管理脚本 |
| kafka-verifiable-consumer.sh | 可检验的kafka消费者 |
| kafka-verifiable-producer.sh | 可检验的kafka生产者 |
| trogdor.sh | Kafka的测试框架,用于执行各种基准测试和负载测试 |
| zookeeper-server-start.sh | 启动zookeeper服务 |
| zookeeper-server-stop.sh | 停止zookeeper服务 |
| zookeeper-shell.sh | 连接操作zookeeper的脚本,可以查看kafka在zk上的节点信息 |
接下来会详细说明常用脚本的使用方法。
3-2 topic管理
对于kafka的topic操作,我们需要用到的是bin/kafka-topics.sh这个脚本文件。
- 创建topic:创建一个名为my-topic的主题(–bootstrap-server后面是连接Kafka的地址)
bin/kafka-topics.sh --bootstrap-server 192.168.8.128:9092 --create --topic my-topic
- 1
注意:Topic 名称中一定不要同时出现下划线 (’_’) 和小数点 (’.’)。
在创建topic时选项说明:
--topic test :定义topic名称
--partitions 3:指定当前topic的分区数,若不指定则根据配置文件的默认分区数进行创建
--replication-factor 1: 定义副本数为1,副本数不能超过当前集群broker数,否则会抛出InvalidReplicationFactorException异常

- 查看当前服务器所有topic
bin/kafka-topics.sh --bootstrap-server 192.168.8.128:9092 --list
- 1

- 修改topic配置
1.增加分区数:
bin/kafka-topics.sh --bootstrap-server 192.168.8.128:9092 --alter --topic test --partitions 40
- 1
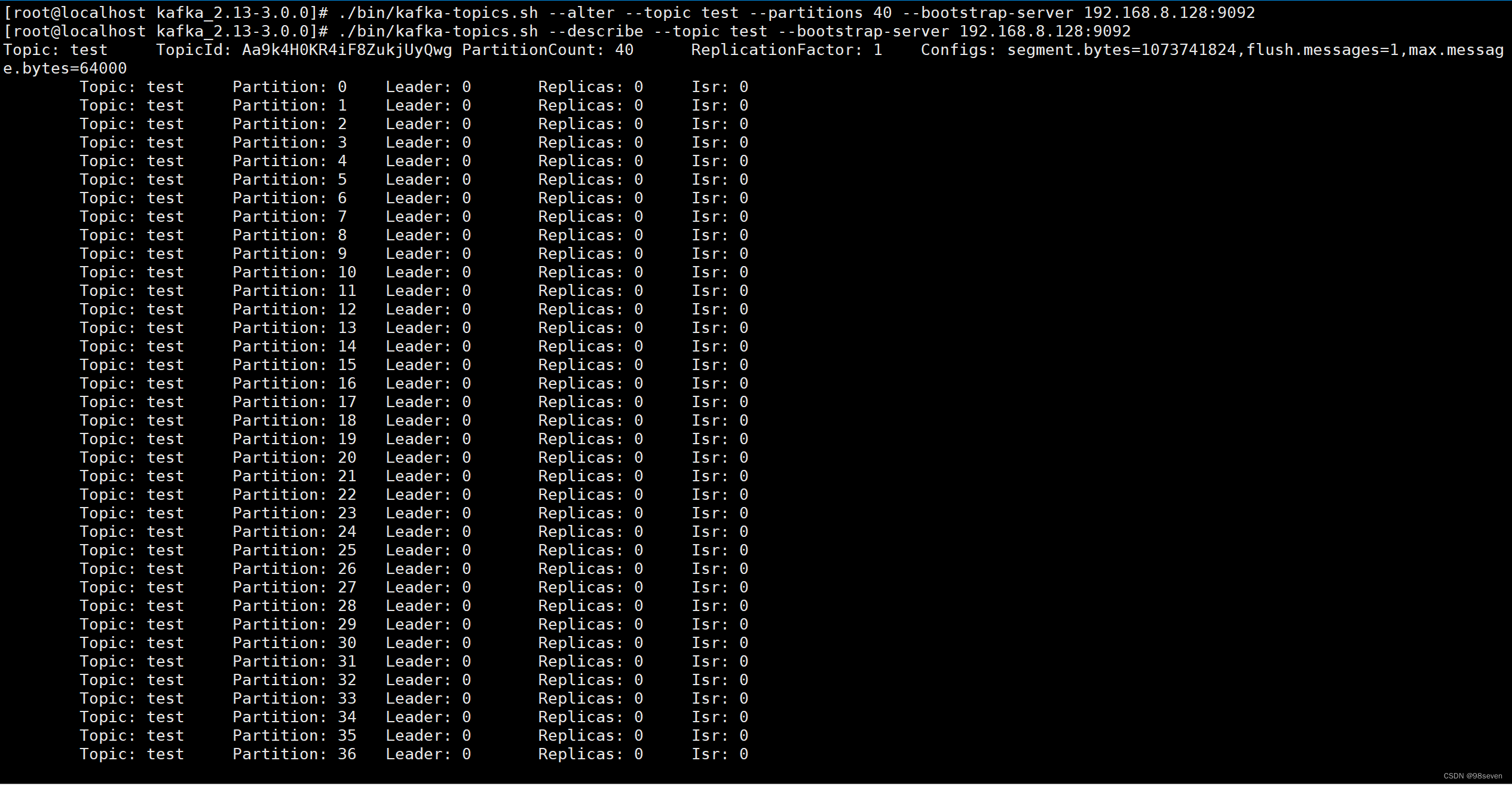
2. 增加配置
bin/kafka-topics.sh --alter --bootstrap-server 192.168.8.128:9092 --topic test --config cleanup.policy=compact
- 1
- 删除配置
bin/kafka-topics.sh --alter --bootstrap-server 192.168.8.128:9092 --topic test --delete-config flush.messages
- 1
当如下所示的属性配置到 Topic 上时,将会覆盖 server.properties 上对应的属性。
| Topic级别配置属性 | 类型 | 有效值 | 描述 |
|---|---|---|---|
| cleanup.policy | list | delete(默认) compact | 过期或达到上限日志的清理策略。 delete:删除 compact:压缩 |
| compression.type | string | uncompressed snappy lz4 gzip producer(默认) | 指定给该topic最终的压缩类型 |
| delete.retention.ms | long | 86400000(默认) | 压缩的日志保留的最长时间,也是客户端消费消息的最长时间。 与 log.retention.minutes 的区别在于:一个控制未压缩的数据,一个控制压缩后的数据。 |
| file.delete.delay.ms | long | 60000 | 从文件系统中删除前所等待的时间 |
| flush.messages | long | 9223372036854775807 | 在消息刷到磁盘之前,日志分区收集的消息数 |
| flush.ms | long | 9223372036854775807 | 消息在刷到磁盘之前,保存在内存中的最长时间,单位是ms |
| index.interval.bytes | int | 4096 | 执行 fetch 操作后,扫描最近的 offset 运行空间的大小。 设置越大,代表扫描速度越快,但是也更耗内存。 (一般情况下不需要设置此参数) |
| message.max.bytes | int | 1000012 | log中能够容纳消息的最大字节数 |
| min.cleanable.dirty.ratio | double | 0.5 | 日志清理的频率控制,占该log的百分比。 越大意味着更高效的清理,同时会存在空间浪费问题 |
| retention.bytes | long | -1(默认) | topic每个分区的最大文件大小。 一个 topic 的大小限制 = 分区数 * log.retention.bytes。 -1 表示没有大小限制。 |
| retention.ms | int | 604800000(默认) | 日志文件保留的分钟数。 数据存储的最大时间超过这个时间会根据 log.cleanup.policy 设置的策略处理数据 |
| segment.bytes | int | 1073741824(默认) | 每个 segment 的大小 (默认为1G) |
| segment.index.bytes | int | 10485760(默认) | 对于segment日志的索引文件大小限制(默认为10M) |
注意:
partition数量只能增加,不能减少
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-JcoyuUM8-1651065487273)(Kafka.assets/image-20211022172107197.png)]](https://img-blog.csdnimg.cn/a032da4871fa49f29a269539063659ba.png)
此脚本不能用来修改副本个数。(使用
kafka-reassign-partitions.sh脚本修改副本数)
首先根据需要创建topic文件配置
partitions-topic.json,配置内容如下:{ "partitions": [ { "topic": "test", "partition": 0, "replicas": [1,2] }, { "topic": "test", "partition": 1, "replicas": [1,3] }, { "topic": "test", "partition": 2, "replicas": [2,3] } ], "version":1 }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 执行副本搬迁
bin/kafka-reassign-partitions.sh --bootstrap-server 192.168.8.128:9092 --reassignment-json-file partitions-topic.json --execute
- 1
查看迁移情况:
bin/kafka-reassign-partitions.sh --bootstrap-server 192.168.8.128:9092 --reassignment-json-file partitions-topic.json --verify
- 1
- 删除topic
bin/kafka-topics.sh --bootstrap-server 192.168.8.128:9092 --delete --topic my_topic_name
- 1
- 查看topic详情
bin/kafka-topics.sh --describe --topic my-topic --bootstrap-server 196.168.8.128:9092
- 1
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-b4g2x7PV-1651065487274)(Kafka.assets/image-20211011170325355.png)]](https://img-blog.csdnimg.cn/1bf8dff406324d18b5e070b855883a7a.png)
输出信息中,第一行包含该topic的配置信息(名称,id,分区数,副本数和配置),后面每一行说明一个分区的信息。
其中,Leader,Replicas和Isr后面的数字都是 broker 的 id,Leader 表示该节点负责该分区的所有读写操作,Replicas 表示备份的节点,Isr表示当前 kakfa 集群中可用的 breaker.id 列表。因为目前是单节点,所以所有信息均为0。
3-3 生产者产生数据
消息是kafka中最基本的数据单元,在kafka中,一条消息由key、value两部分构成,在发送一条消息时,我们可以指定这个key,producer的分发机制会根据key来判断当前这条消息应该发送并存储到哪个partition中。默认情况下,kafka采用的是hash取模的分区算法,如果Key为null,则会随机分配一个分区。
生产消息需要使用bin/kafka-console-producer.sh脚本。直接输入消息值(value)即可,输入的每一行表示一条消息,都会导致将单独的事件写入主题。每次回车表示触发“发送”操作,回车后可直接使用“Ctrl + c”退出生产者控制台。
bin/kafka-console-producer.sh --topic test --bootstrap-server 192.168.8.128:9092
- 1

如需指定消息的key值可以通过--property parse.key=true配置。输入消息时,默认消息的key和value之间使用Table键进行分隔(请勿使用转义字符\t)。
bin/kafka-console-producer.sh --bootstrap-server 192.168.8.128:9092 --topic test --property parse.key=true
- 1

输入如上信息表示所生产的消息“Key1”和"Key2"为消息键,“Value1”和“Value2”为消息值。
下表列举了3.0版本支持的所有参数用法:
| 参数 | 值类型 | 说明 | 有效值 |
|---|---|---|---|
| –bootstrap-server | String | 要连接的服务器 必需(除非指定–broker-list, 但broker-list在新版本中已过时) | 形如:host1:prot1,host2:prot2 |
| –topic | String | (必需)接收消息的主题名称 | |
| –broker-list | String | 已过时要连接的服务器 | 形如:host1:prot1,host2:prot2 |
| –batch-size | Integer | 单个批处理中发送的消息数 | 200(默认值) |
| –compression-codec | String | 压缩编解码器 | none、gzip(默认值) snappy、lz4、zstd |
| –line-reader | String | 默认情况下,每一行都被读取为单独的消息 | kfka.tools. ConsoleProducer$LineMessageReader |
| –max-block-ms | Long | 在发送请求期间, 生产者将阻塞的最长时间 | 60000(默认值) |
| –max-memory-bytes | Long | 生产者用来缓冲等待发送到服务器的总内存 | 33554432(默认值) |
| –max-partition-memory-bytes | Long | 为分区分配的缓冲区大小 | 16384(默认值) |
| –message-send-max-retries | Integer | 最大的重试发送次数 | 3(默认值) |
| –metadata-expiry-ms | Long | 强制更新元数据的时间阈值(ms) | 300000(默认值) |
| –producer-property | String | 将自定义属性传递给生产者的机制 | 形如:key=value |
| –producer.config | String | 生产者配置属性文件 ,注意[–producer-property]优先于此配置 | 配置文件完整路径 |
| –property | String | 自定义消息读取器 | parse.key=true|false key.separator=<key.separator> ignore.error=true|false |
| –request-required-acks | String | 生产者请求的确认方式(具体讲解在Producer API) | 0、1(默认值)、all |
| –request-timeout-ms | Integer | 生产者请求的确认超时时间 | 1500(默认值) |
| –retry-backoff-ms | Integer | 生产者重试前,刷新元数据的等待时间阈值 | 100(默认值) |
| –socket-buffer-size | Integer | TCP接收缓冲大小 | 102400(默认值) |
| –timeout | Integer | 消息排队异步等待处理的时间阈值 | 1000(默认值) |
| –sync | 同步发送消息 | ||
| –version | 显示 Kafka 版本 不配合其他参数时,显示为本地Kafka版本 | ||
| –help | 打印帮助信息 |
3-4 消费者消费数据
消费消息需要使用bin/kafka-console-consumer.sh 脚本。该 shell 脚本的功能通过调用 kafka.tools 包下的 ConsoleConsumer 类,并将提供的命令行参数全部传给该类实现。
打开另一个终端会话并运行控制台使用者客户端以读取刚刚创建的事件:
bin/kafka-console-consumer.sh --topic test --from-beginning --bootstrap-server 192.168.8.128:9092
- 1

默认情况消费出来现实的信息是只有消息的Value值,如果要展示消息的Key,时间戳或其他信息需要通过选项–property进行配置。
bin/kafka-console-consumer.sh --topic my-topic --bootstrap-server 192.168.8.128:9092 --property print.partition=true --property print.key=true --property print.timestamp=true --property print.offset=true
- 1
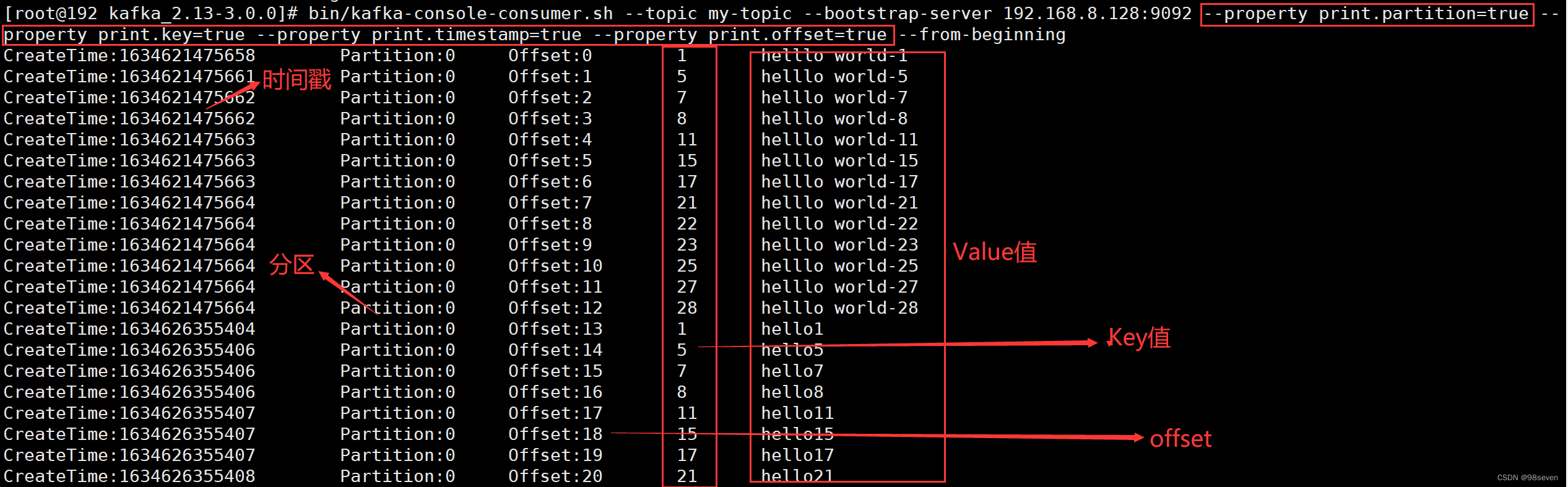
若不适用–from-beginning选项,表示从最新处消费该topic的所有分区的的消息,即仅消费正在写入的消息。加上–from-beginning选项表示从该topic存在的所有消息中从头开始消费。
注意:
consumer默认将offset保存在Kafka一个内置的topic中,该topic名 为
__consumer_offsets
该进程会一直运行,当有新消息进来,这里会直接读取出来消息。当有Leader节点出现错误时,会在剩余的follower中推举出一个leader,而且这些数据还没有丢失,因为follower是leader的备份节点。
| 参数 | 值类型 | 说明 | 有效值 |
|---|---|---|---|
| –topic | string | 被消费的topic | |
| –include | string | 正则表达式,指定要包含以供使用的主题的白名单 | |
| –partition | integer | 指定消费的分区,默认从该分区的末尾开始消费,除非指定了offset | |
| –offset | string | 执行消费的起始偏移量位置 默认值:latest | latest:从最新处开始消费 earliest :从最早处开始消费 offset:从指定偏移量开始消费 |
| –consumer-property | string | 将用户定义的属性以key=value的形式传递给使用者 | |
| –consumer.config | string | 消费者配置属性文件 [consumer-property]配置优先级高于此配置 | |
| –formatter | string | 用于格式化kafka消息以供显示的类的名称 ,kafka.tools下的 | DefaultMessageFormatter LoggingMessageFormatter NoOpMessageFormatter ChecksumMessageFormatter |
| –property | string | 初始化消息格式化程序的属性 | print.timestamp=true|false print.key=true|false print.value=true|false key.separator=<key.separator> line.separator=<line.separator> key.deserializer=<key.deserializer> value.deserializer=<value.deserializer> |
| –from-beginning | 从存在的最早消息开始,而不是从最新消息开始 | ||
| –max-messages | integer | 设置要消费的最大消息数。如果未设置,则连续消耗 | |
| –timeout-ms | integer | 如果没有消息可消费,将在指定时间后终止消费者进程 | |
| –skip-message-on-error | 如果处理消息时出错,请跳过它而不是暂停 | ||
| –bootstrap-server | string | 必需,要连接的服务器 | |
| –key-deserializer | string | 消息的key序列化方式 | |
| –value-deserializer | string | 消息的value序列化方式 | |
| –enable-systest-events | 除记录消费的消息外,还记录消费者的生命周期 (用于系统测试) | ||
| –isolation-level | string | 设置为read_committed以过滤掉未提交的事务性消息 设置为read_uncommitted以读取所有消息 | read_uncommitted, read_uncommitted(默认值) |
| –group | string | 指定消费者所属组的ID |
3-5 配置管理
kafka-configs.sh配置管理脚本,这个脚本主要分两类用法:describe和alter。
-
describe相关用法
- 查看每个topic的配置
bin/kafka-configs.sh --bootstrap-server 192.168.8.128:9092 --describe --entity-type topics- 1
- 查看broker的配置
bin/kafka-configs.sh --bootstrap-server 192.168.8.128:9092 --describe --entity-type brokers --entity-name 0- 1
说明:0是broker.id,因为entity-type为brokers,所以entity-name表示broker.id。
-
alter相关用法
- 给指定topic增加配置
bin/kafka-configs.sh --bootstrap-server 192.168.8.128:9092 --alter --entity-type topics --entity-name TOPIC-TEST-AFEI --add-config retention.ms=600000- 1
- 给指定topic删除配置
bin/kafka-configs.sh --bootstrap-server 192.168.8.128:9092 --alter --entity-type topics --entity-name TOPIC-TEST-AFEI --delete-config max.message.bytes- 1
3-6 查看元数据日志
使用过程中,如果遇到问题,可能需要查看元数据日志。在KRaft中,有两个命令行工具需要特别关注下。kafka-dump-log.sh和kakfa-metadata-shell.log。(元数据不是真正的数据,规范、定义真实数据的数据)
-
kafka-dump-log.sh
Kafka-dump-log.sh是一个之前就有的工具,用来查看Topic的的文件内容。
-
查询Log文件
bin/kafka-dump-log.sh --files kafka-logs/my-topic-0/00000000000000000000.log- 1
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-UZT3SuIx-1651065613020)(Kafka.assets/image-20211028164041786.png)]](https://img-blog.csdnimg.cn/fb142cd78ec34e1d8f317f47dadf5712.png)
-
- 查询Log文件具体信息
bin/kafka-dump-log.sh --files kafka-logs/my-topic-2/00000000000000000000.log --print-data-log
- 1
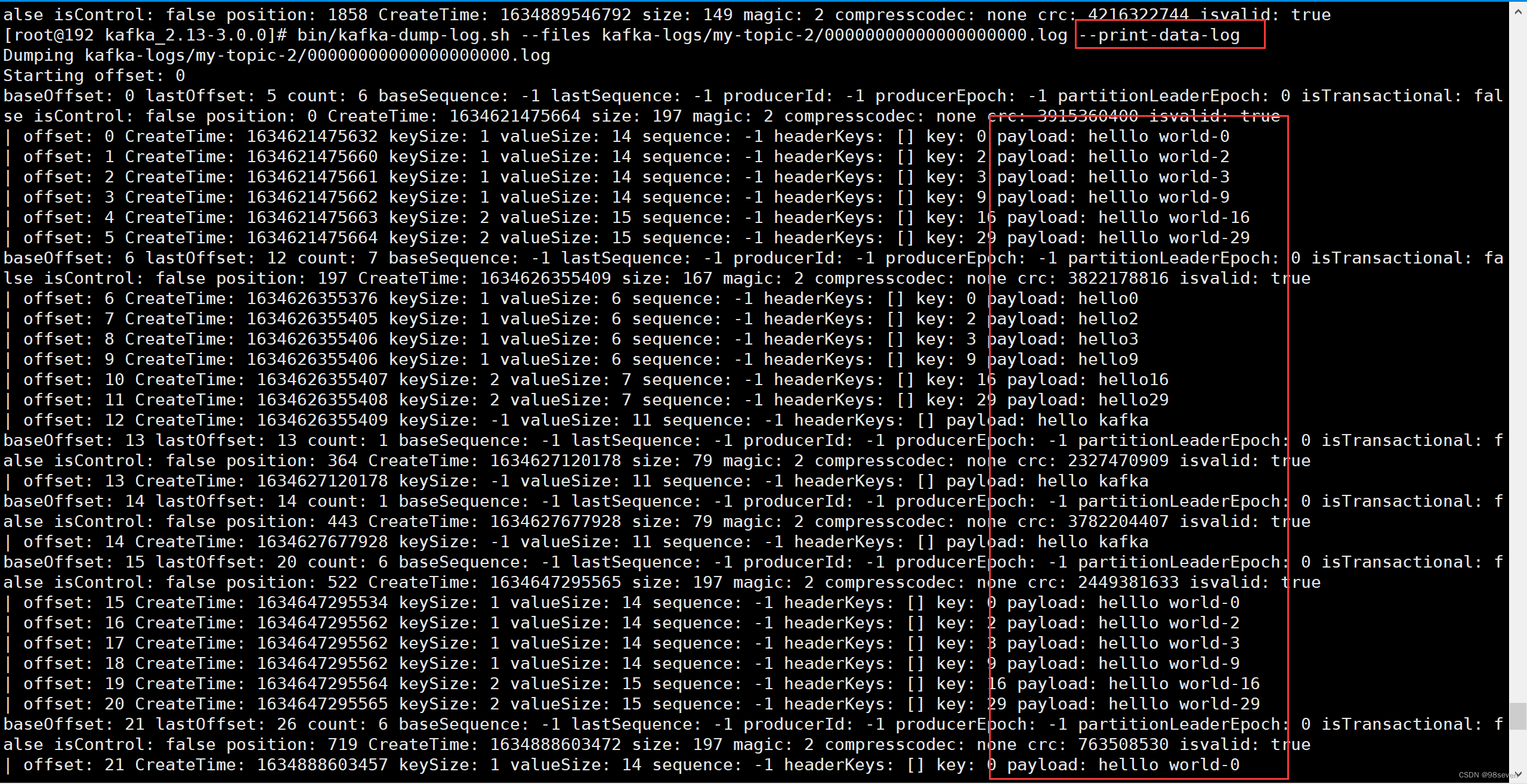
- 查询index文件具体信息
bin/kafka-dump-log.sh --files kafka-logs/my-topic-2/00000000000000000000.index
- 1

- 查询timeindex文件
bin/kafka-dump-log.sh --files kafka-logs/my-topic-2/00000000000000000000.timeindex
- 1

3.0版本中这个工具加了一个参数–cluster-metadata-decoder用来,查看元数据日志,如下所示:
./bin/kafka-dump-log.sh --cluster-metadata-decoder --skip-record-metadata --files /opt/kraft/kraft-combined-logs/__cluster_metadata-0/*.log
- 1
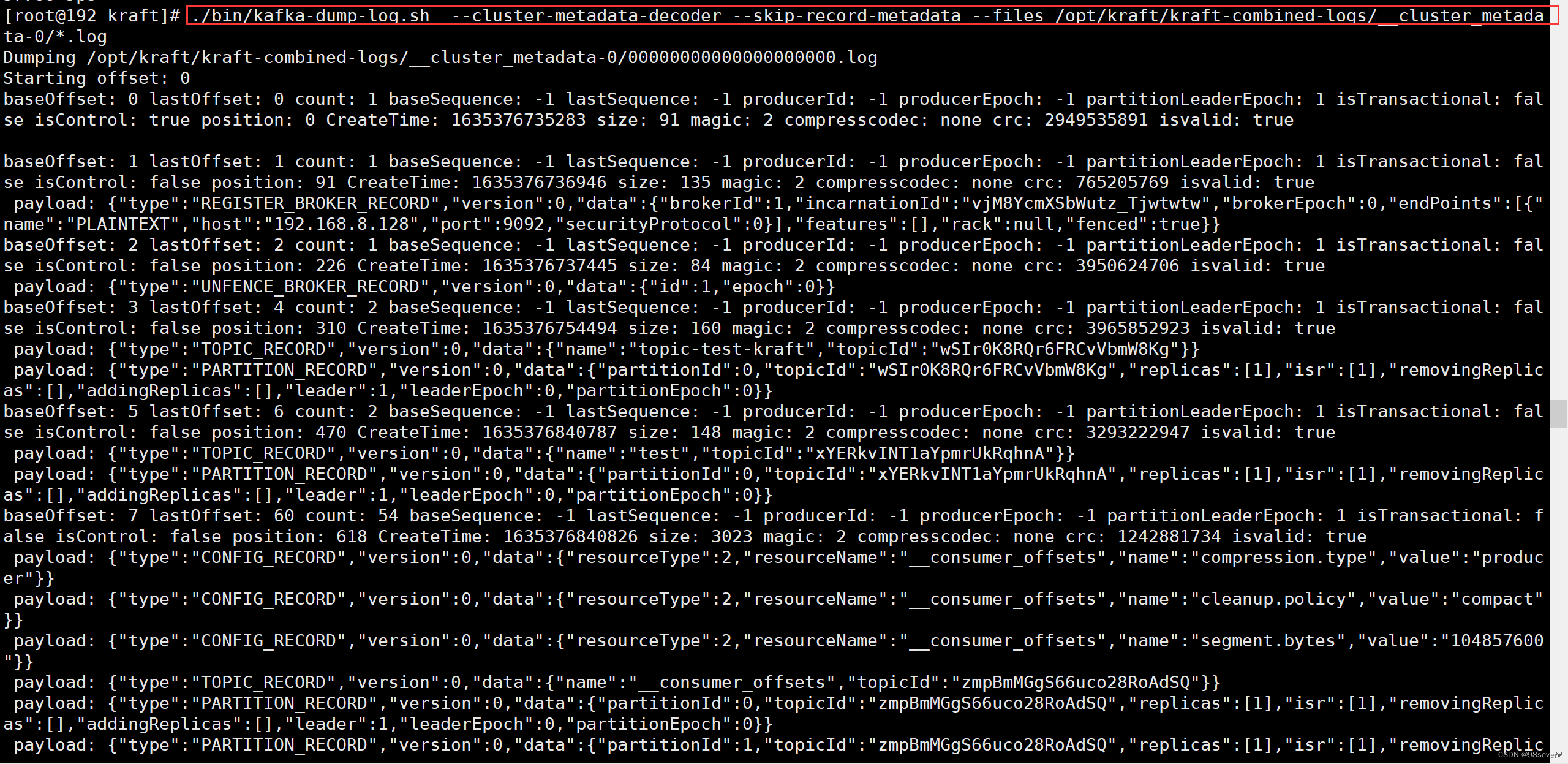
./bin/kafka-dump-log.sh --cluster-metadata-decoder --skip-record-metadata --files /opt/kraft/kraft-combined-logs/__cluster_metadata-0/*.log
Dumping /tmp/kraft-combined-logs/__cluster_metadata-0/00000000000000000000.log
Starting offset: 0
baseOffset: 0 lastOffset: 0 count: 1 baseSequence: -1 lastSequence: -1 producerId: -1 producerEpoch: -1 partitionLeaderEpoch: 1 isTransactional: false isControl: true position: 0 CreateTime: 1614382631640 size: 89 magic: 2 compresscodec: NONE crc: 1438115474 isvalid: true
baseOffset: 1 lastOffset: 1 count: 1 baseSequence: -1 lastSequence: -1 producerId: -1 producerEpoch: -1 partitionLeaderEpoch: 1 isTransactional: false isControl: false position: 89 CreateTime: 1614382632329 size: 137 magic: 2 compresscodec: NONE crc: 1095855865 isvalid: true
payload: {"type":"REGISTER_BROKER_RECORD","version":0,"data":{"brokerId":1,"incarnationId":"P3UFsWoNR-erL9PK98YLsA","brokerEpoch":0,"endPoints":[{"name":"PLAINTEXT","host":"localhost","port":9092,"securityProtocol":0}],"features":[],"rack":null}}
baseOffset: 2 lastOffset: 2 count: 1 baseSequence: -1 lastSequence: -1 producerId: -1 producerEpoch: -1 partitionLeaderEpoch: 1 isTransactional: false isControl: false position: 226 CreateTime: 1614382632453 size: 83 magic: 2 compresscodec: NONE crc: 455187130 isvalid: true
payload: {"type":"UNFENCE_BROKER_RECORD","version":0,"data":{"id":1,"epoch":0}}
baseOffset: 3 lastOffset: 3 count: 1 baseSequence: -1 lastSequence: -1 producerId: -1 producerEpoch: -1 partitionLeaderEpoch: 1 isTransactional: false isControl: false position: 309 CreateTime: 1614382634484 size: 83 magic: 2 compresscodec: NONE crc: 4055692847 isvalid: true
payload: {"type":"FENCE_BROKER_RECORD","version":0,"data":{"id":1,"epoch":0}}
baseOffset: 4 lastOffset: 4 count: 1 baseSequence: -1 lastSequence: -1 producerId: -1 producerEpoch: -1 partitionLeaderEpoch: 2 isTransactional: false isControl: true position: 392 CreateTime: 1614382671857 size: 89 magic: 2 compresscodec: NONE crc: 1318571838 isvalid: true
baseOffset: 5 lastOffset: 5 count: 1 baseSequence: -1 lastSequence: -1 producerId: -1 producerEpoch: -1 partitionLeaderEpoch: 2 isTransactional: false isControl: false position: 481 CreateTime: 1614382672440 size: 137 magic: 2 compresscodec: NONE crc: 841144615 isvalid: true
payload: {"type":"REGISTER_BROKER_RECORD","version":0,"data":{"brokerId":1,"incarnationId":"RXRJu7cnScKRZOnWQGs86g","brokerEpoch":4,"endPoints":[{"name":"PLAINTEXT","host":"localhost","port":9092,"securityProtocol":0}],"features":[],"rack":null}}
baseOffset: 6 lastOffset: 6 count: 1 baseSequence: -1 lastSequence: -1 producerId: -1 producerEpoch: -1 partitionLeaderEpoch: 2 isTransactional: false isControl: false position: 618 CreateTime: 1614382672544 size: 83 magic: 2 compresscodec: NONE crc: 4155905922 isvalid: true
payload: {"type":"UNFENCE_BROKER_RECORD","version":0,"data":{"id":1,"epoch":4}}
baseOffset: 7 lastOffset: 8 count: 2 baseSequence: -1 lastSequence: -1 producerId: -1 producerEpoch: -1 partitionLeaderEpoch: 2 isTransactional: false isControl: false position: 701 CreateTime: 1614382712158 size: 159 magic: 2 compresscodec: NONE crc: 3726758683 isvalid: true
payload: {"type":"TOPIC_RECORD","version":0,"data":{"name":"foo","topicId":"5zoAlv-xEh9xRANKXt1Lbg"}}
payload: {"type":"PARTITION_RECORD","version":0,"data":{"partitionId":0,"topicId":"5zoAlv-xEh9xRANKXt1Lbg","replicas":[1],"isr":[1],"removingReplicas":null,"addingReplicas":null,"leader":1,"leaderEpoch":0,"partitionEpoch":0}}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
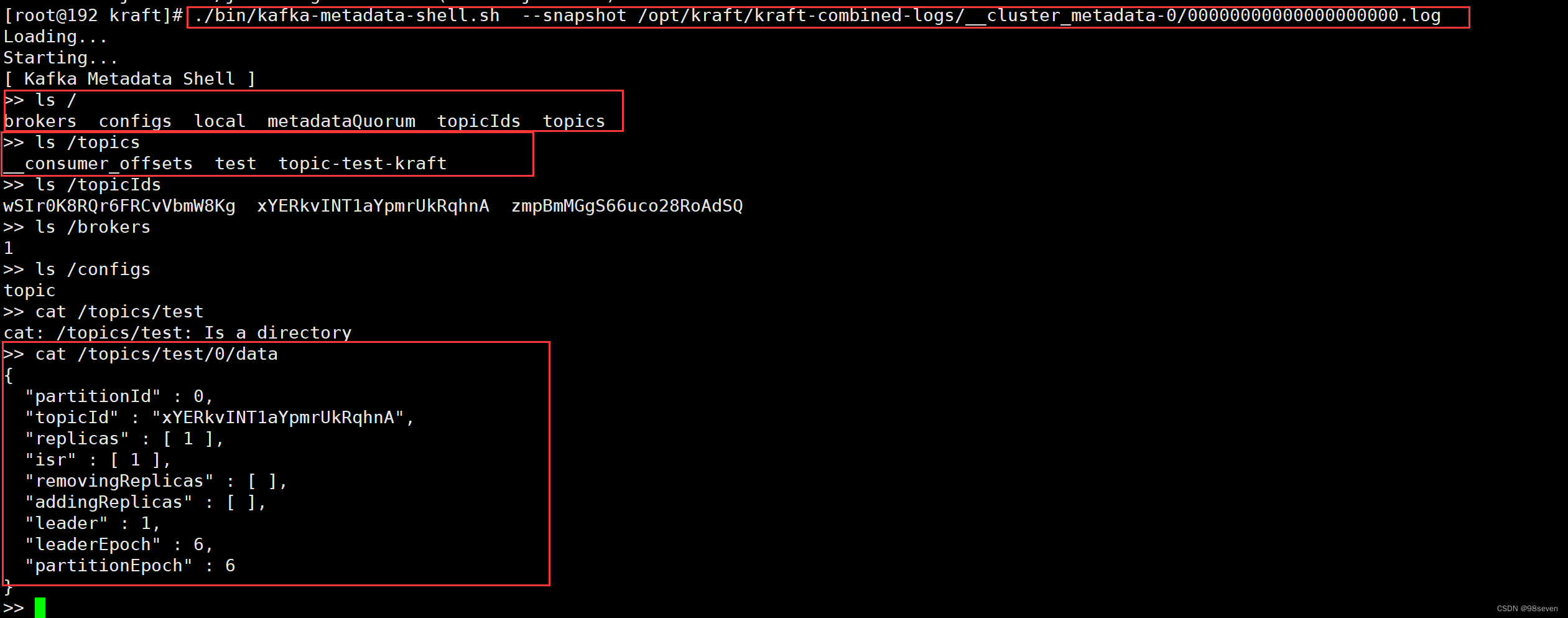
2.kafka-metadata-shell.sh
kafka还提供了一个叫做kafka-metadata-shell.sh的工具,能够看到topic和partion的分布,这些信息原来是可以通过zk获取的,现在可以使用这个命令行获取。
[root@192 kraft]# ./bin/kafka-metadata-shell.sh --snapshot /opt/kraft/kraft-combined-logs/__cluster_metadata-0/00000000000000000000.log
Loading...
Starting...
[ Kafka Metadata Shell ]
>> ls /
brokers configs local metadataQuorum topicIds topics
>> ls /topics
__consumer_offsets test topic-test-kraft
>> ls /topicIds
wSIr0K8RQr6FRCvVbmW8Kg xYERkvINT1aYpmrUkRqhnA zmpBmMGgS66uco28RoAdSQ
>> ls /brokers
1
>> ls /configs
topic
>> cat /topics/test/0/data
{
"partitionId" : 0,
"topicId" : "xYERkvINT1aYpmrUkRqhnA",
"replicas" : [ 1 ],
"isr" : [ 1 ],
"removingReplicas" : [ ],
"addingReplicas" : [ ],
"leader" : 1,
"leaderEpoch" : 6,
"partitionEpoch" : 6
}
>> exit
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
3-7 消费组管理
对消费组的操作用到的是 bin/kafka-consumer-groups.sh脚本,具体使用方法如下:
- 列出消费组
bin/kafka-consumer-groups.sh --bootstrap-server 192.168.8.128:9092 --list
- 1

- 查看消费组详情
bin/kafka-consumer-groups.sh --bootstrap-server 192.168.8.128:9092 --describe --group my-group
- 1
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-cQzWTzDo-1651065801948)(Kafka.assets/image-20211022151331639.png)]](https://img-blog.csdnimg.cn/d907b9d777614f83a28819e5744e879e.png)
各字段含义如下:
| TOPIC | PARTITION | CURRENT-OFFSET | LOG-END-OFFSET | LAG | CONSUMER-ID | HOST | CLIENT-ID |
|---|---|---|---|---|---|---|---|
| topic名字 | 分区id | 当前已消费的条数 | 总条数 | 未消费的条数 | 消费id | 主机ip | 客户端id |
- 查看消费组中所有活动成员的列表
bin/kafka-consumer-groups.sh --bootstrap-server 192.168.8.128:9092 --describe --group test --members
- 1

- 查看分配给每个成员的分区
bin/kafka-consumer-groups.sh --bootstrap-server 192.168.8.128:9092 --describe --group my-group --members --verbose
- 1

此外,–offsets这是默认的描述选项,与–describe选项输出相同。–state提供有用的组级信息。

- 删除一个或多个消费组:使用–delete
> bin/kafka-consumer-groups.sh --bootstrap-server 192.168.8.128:9092 --delete --group my-group --group my-other-group
Deletion of requested consumer groups ('my-group', 'my-other-group') was successful.
- 1
- 2
- 3
-
重置消费者的偏移量
选项说明:
--to-latest:重置偏移量为最新处--to-earliest:重置偏移量为最早处--to-offset <Long: offset>:重置偏移量为指定值
bin/kafka-consumer-groups.sh --bootstrap-server 192.168.8.128:9092 --reset-offsets --group consumergroup1 --topic topic1 --to-latest
- 1
3-8 导入导出
kafka connect 是一个可扩展的、可靠的在kafka和其他系统之间流传输的数据工具。简而言之就是他可以通过Connector(连接器)简单、快速的将大集合数据导入和导出kafka。可以接收整个数据库或收集来自所有的应用程序的消息到kafka的topic中,主要用来与其他中间件建立流式通道。
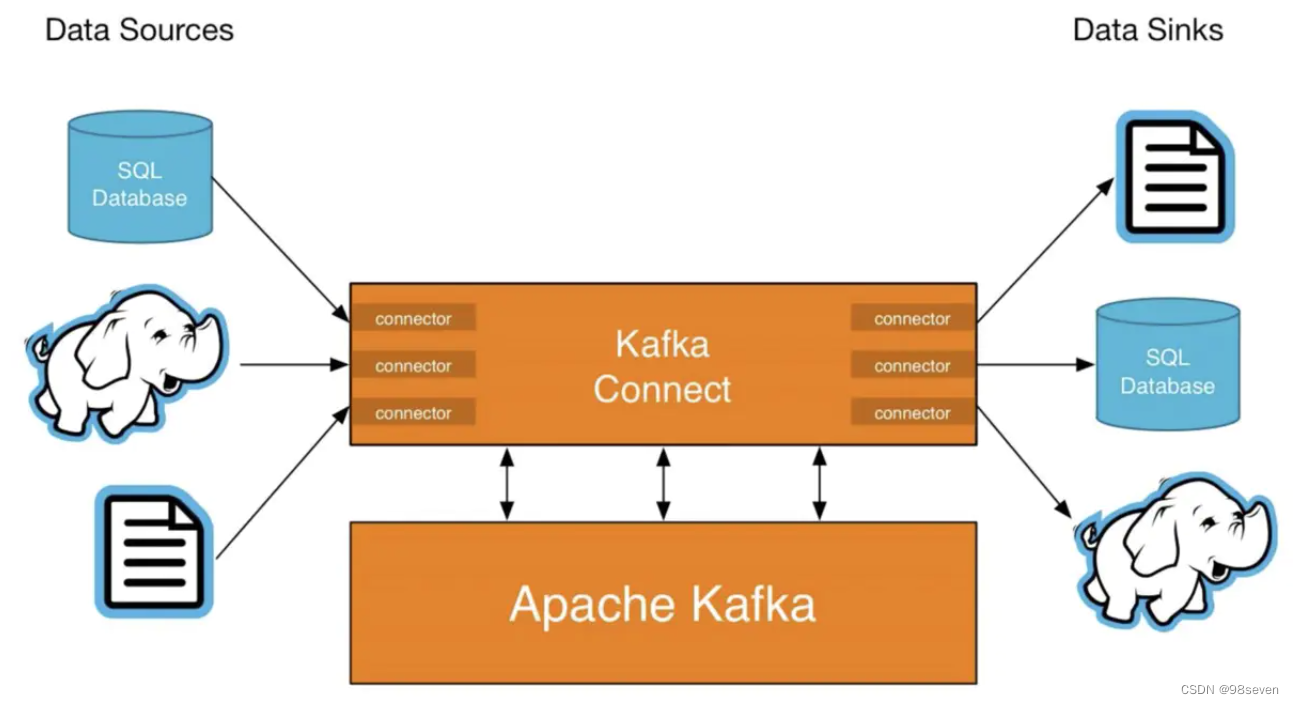
Kafka connect的核心组件:
- Source:负责将外部数据写入到Kafka的topic
- Sink:负责从topic读取数据到指定地方
- Connectors:通过管理task来协调数据流的高级抽象
- Converters:kafka connect和其他存储系统直接发送或者接受数据之间转换数据,converter会把bytes数据转换成kafka connect内部的格式,也可以把kafka connect内部存储格式的数据转变成bytes,converter对connector来说是解耦的,所以其他的connector都可以重用。
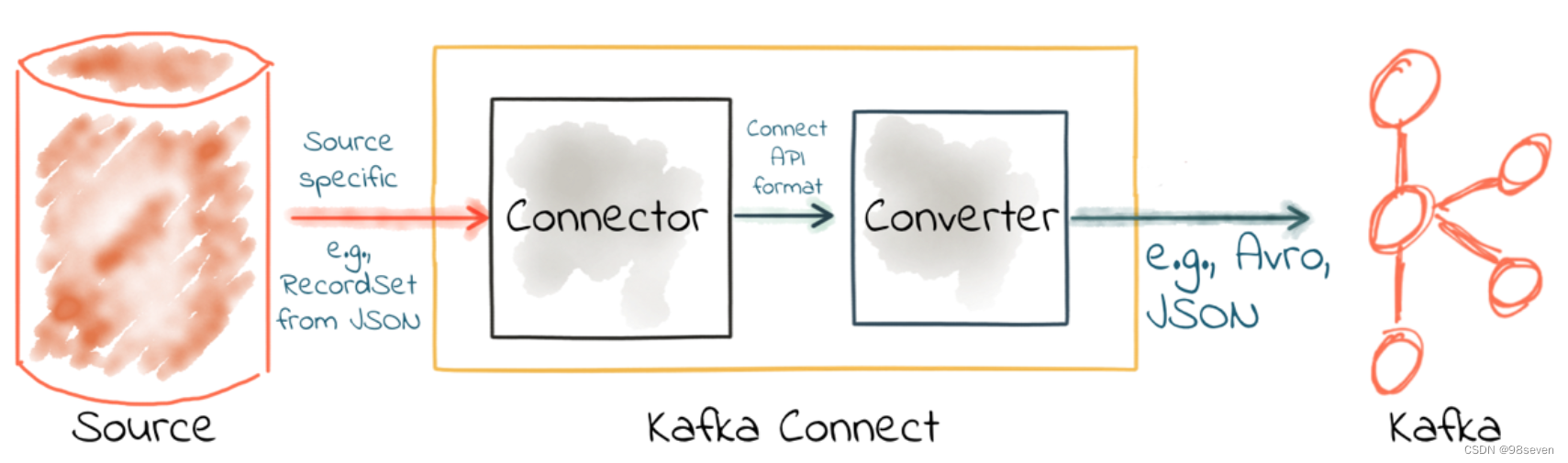

注意:读取后的数据的Schema是固定的,包含的列如下:
| Column | Type | 说明 |
|---|---|---|
| key | binary | 消息的key |
| value | binary | 消息的value |
| topic | string | 主题 |
| partition | int | 分区 |
| offset | long | 偏移量 |
| timestamp | long | 时间戳 |
Kafka connect的两种工作模式:
standalone:在standalone模式中,用单一进程负责执行所有连接操作,使用connect-standalone.sh脚本。distributed:distributed模式具有高扩展性,以及提供自动容错机制。可以使用一个group.ip来启动很多worker进程,在有效的worker进程中它们会自动的去协调执行任务,使用connect-distributed.sh脚本启动。
Kafka connect客户端操作:
1.创建一些文本信息
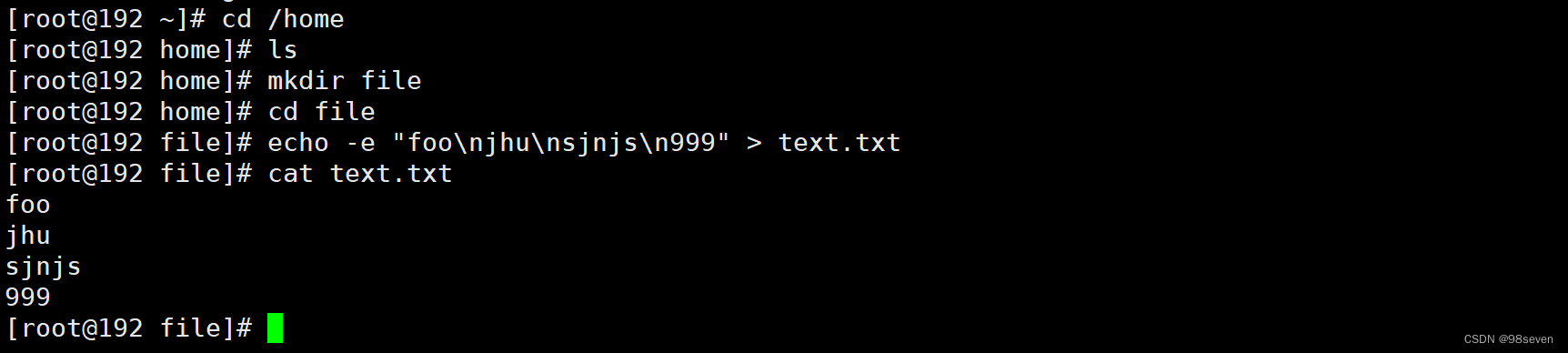
2.开启两个连接器运行在独立模式
独立模式意味着运行一个单一的,本地的,专用的进程。使用的是bin/connect-standalone.sh这个脚本。
bin/connect-standalone.sh config/connect-standalone.properties config/connect-file-source.properties config/connect-file-sink.properties
- 1
执行这个脚本的时候会带三个配置文件(若执行的是connect-distributed.sh脚本,第一个参数应选择相应的connect-distributed.properties):connect-standalone.properties是Kafka Connect处理的配置,connect-standalone.properties配置文件如下:
#kafka服务地址
bootstrap.servers=192.168.8.128:9092
#把数据导入到kafka的某个topic时,topic中数据的key按照某种converter转化,默认是json格式
key.converter=org.apache.kafka.connect.json.JsonConverter
#把数据导入到kafka的某个topic时,topic中数据的value按照某种converter转化,默认是json格式
value.converter=org.apache.kafka.connect.json.JsonConverter
#指定topic中数据的key和value是否包含schema信息,消息由playload和schema组成
key.converter.schemas.enable=true
value.converter.schemas.enable=true
#保存偏移量的路径
offset.storage.file.filename=/tmp/connect.offsets
#保存connector运行中offset到topic的频率
offset.flush.interval.ms=10000
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
connect-distributed.properties配置文件如下:
#kafka服务地址
bootstrap.servers=192.168.8.128:9092
#集群的id,要注意这个id不能和consumer group的id冲突
group.id=connect-cluster
#把数据导入到kafka的某个topic时,topic中数据的key按照某种converter转化,默认是json格式
key.converter=org.apache.kafka.connect.json.JsonConverter
#把数据导入到kafka的某个topic时,topic中数据的value按照某种converter转化,默认是json格式
value.converter=org.apache.kafka.connect.json.JsonConverter
#指定topic中数据的key和value是否包含schema信息
key.converter.schemas.enable=true
value.converter.schemas.enable=true
#用于保存connector运行中offset的topic,当connector宕机时可以继续从某个offset开始运行
offset.storage.topic=connect-offsets
offset.storage.replication.factor=1
#用于保存connector配置信息的topic(注意:此topic只能由一个partition)
config.storage.topic=connect-configs
config.storage.replication.factor=1
#用于保存connector和task状态的topic
status.storage.topic=connect-status
status.storage.replication.factor=1
#保存connector运行中offset到topic的频率
offset.flush.interval.ms=10000
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
connect-file-source.properties配置文件如下:
name=local-file-source
connector.class=FileStreamSource
tasks.max=1
# 指定读取的文件路径
file=/home/file/text.txt
# 指定将数据写入的topic
topic=connect-test
- 1
- 2
- 3
- 4
- 5
- 6
- 7
connect-file-sink.properties配置文件如下:
name=local-file-sink
connector.class=FileStreamSink
tasks.max=1
# 指定消息输出文件路径
file=/home/file/test.sink.txt
# 指定从该topic读取数据
topics=connect-test
- 1
- 2
- 3
- 4
- 5
- 6
- 7
Kafka connect核心组件有source和sink。source负责将外部数据写入到Kafka的topic中,sink负责从Kafka的topic读取数据并写入到指定地方。
执行运行的shell命令,一旦进程开始,导入连接器读取text.txt文件内容写入到connect-test主题,导出连接器从主题connect-test读取消息写入到文件test.sink.txt,而且可以看到connect-test的topic已经创建了。
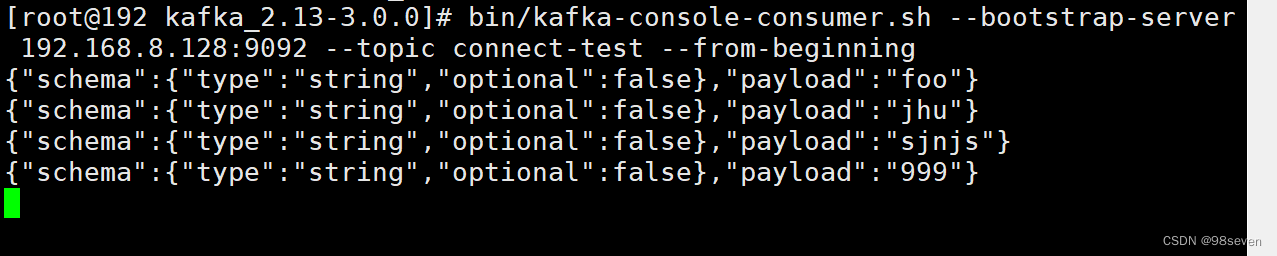
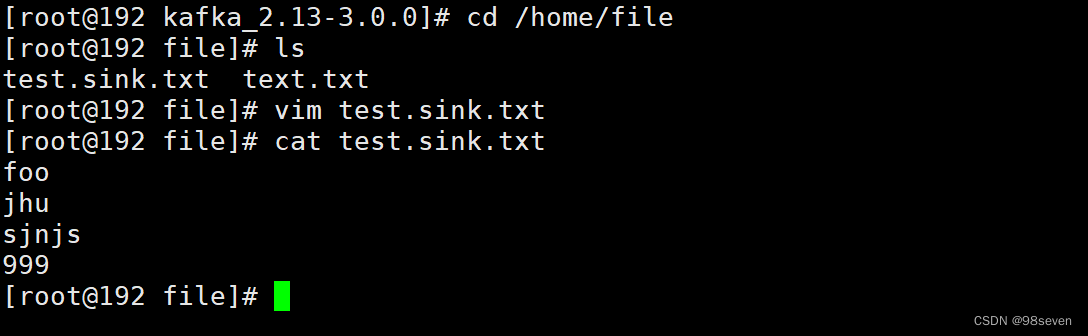
如果在text.txt追加内容,输出文件test.sink.txt也会从kafka的主题中消费消息。

