
- 1迈出学习鸿蒙操作系统的第一步_鸿蒙系统学习路线
- 2ANDROID drawerlayout+fragment侧滑_android fragment drawerlayout
- 3它来了它来了!2020深度学习硬核技术干货集锦!
- 4学习 stm32(TTL)串口通信控制16路舵机控制板(维特智能)_stm32与16路舵机控制板
- 5Flutter 初始Widget&State 简单应用案例分析
- 641.css3设置变形(平移和旋转)_css3平移会导致变形原点改变?
- 7SpringCloud微服务引入其他模块时,无法使用类和方法_springboot微服务新建模块原项目不能用
- 8快应用的用法和常见问题解答(上)
- 9fiddler 经常抓不到浏览器的包_fiddler抓不到浏览器接口
- 10MySql逗号拼接的列拆分为多行_sql按逗号拆分列为多行
Java开发必会技术!docker时间来源
赞
踩
一、分布式架构学习路线图
据统计,人的阅读时间在20分钟以内是能够达到全身心投入的,顾文章单张篇幅以后会尽量缩短,但更新会尽量相应频繁一些。

二、计算机软件发展历史
首先我们了解下计算机软件的发展历史,大概总结概括,分为c/s时代,web1.0时代和web2.0时代。
**c/s时代:**富客户端方案。卖软件可赚钱。例如 qq、影音、游戏。
**1.0时代:**主要是单向信息的发布,即信息门户—广大浏览器客户端 ,互联网内容是由少数编辑人员(或站长)定制的。
表是三大门户,新浪/网易/搜狐。新浪以新闻+广告为主,网易拓展游戏为主,搜狐延伸门户矩阵
**2.0时代:**注重用户的交互。每个人都是内容的供稿者。 RSS订阅扮演一个很重要的作用。
例如:博客、播客、维基、P2P下载、社区、分享服务
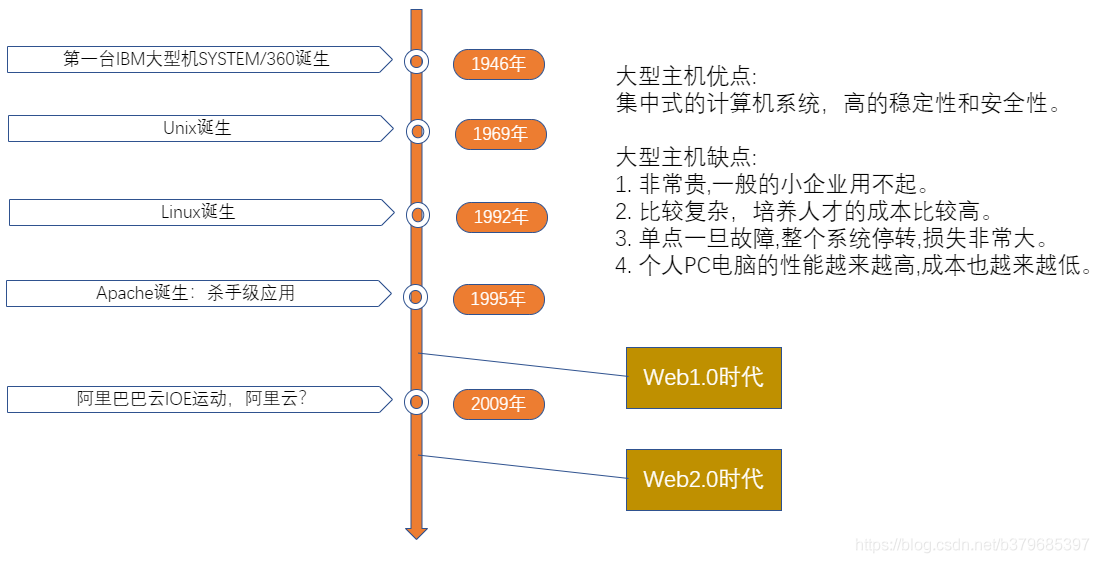
时至今日,互联网的形式演变已经变成全员参与,老少皆宜的活动。因此,互联网相关的技术也是要求越来越高,参与人数的增加也让系统的负担越来越大。
三、技术架构演进史
以下为2017年天猫双11的交易指标。那么大的数据量,那么快的处理请求,显然单台机器,单个服务绝对是无法支撑的。

那么怎么办呢,我们将原本单台部署,单台处理的服务,需要进行拆分以及部署到不同的服务器中去,使其用多台机器去处理,分担压力。但是我们又要保证系统的完整性。这就是分布式的设计。接下来我们看下服务架构的演进史。
架构演进一: 早期雏形
特征:应用程序主要做静态文件读取,返回内容给浏览器。
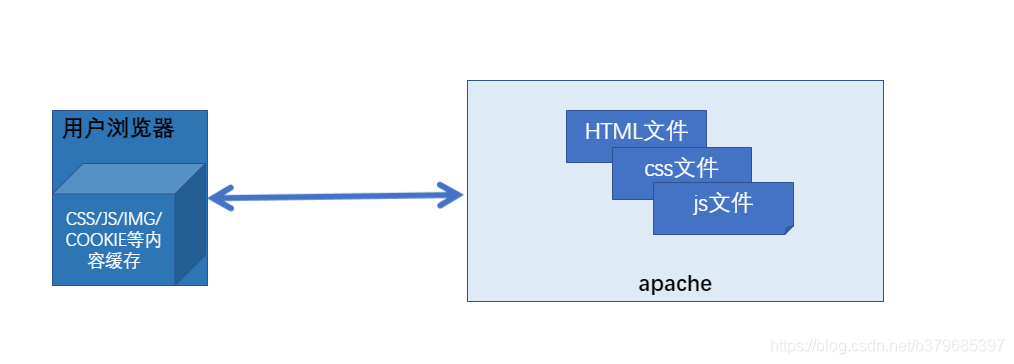
**架构演进二: **数据库开发(LAMP特长)
特征:应用程序主要主要读取数据表值,填充html模块。业务逻辑简单,写sql
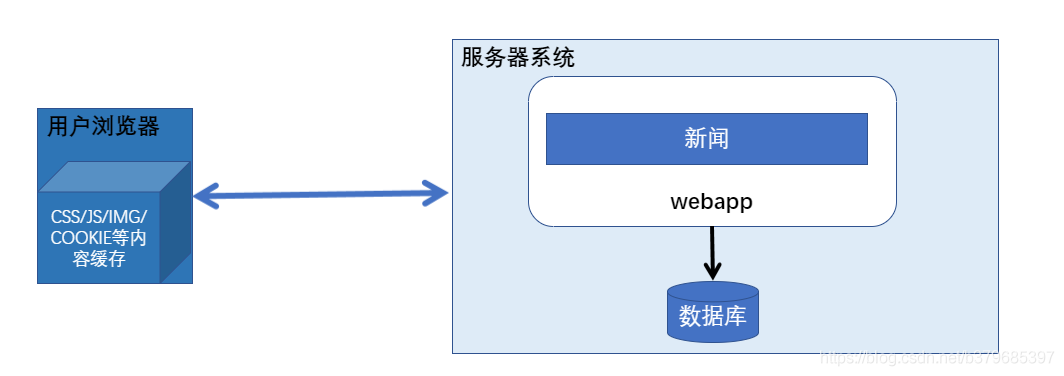
架构演进三: javaweb的雏形
特征:tomcat + servlet + jsp + mysql。一个war包打天下
项目结构:ssh/ssm三层结构。
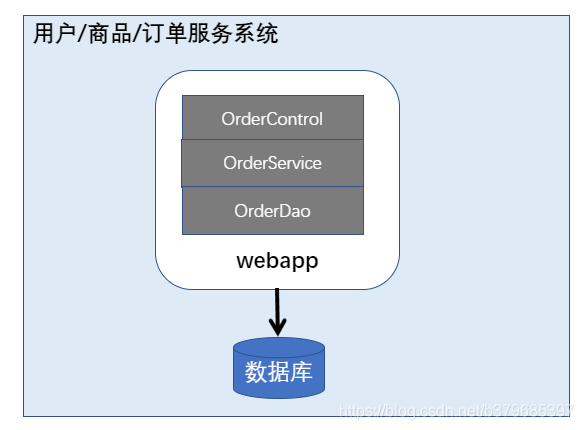
架构演进四: javaweb的集群发展
特征:硬件机器的横向复制,对整个项目结构无影响。
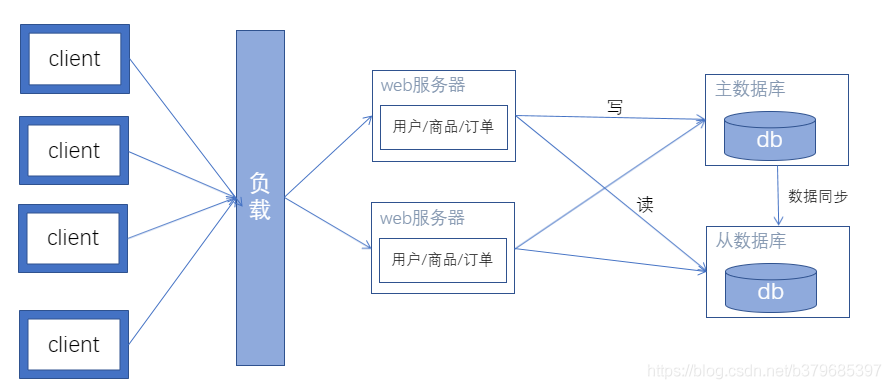
架构演进五: javaweb的分布式发展
特征:将Service层单独分离出去,成为一个单独的项目jar。单独运行。Web服务器通过rpc框架,对分离出去的service进行调用。
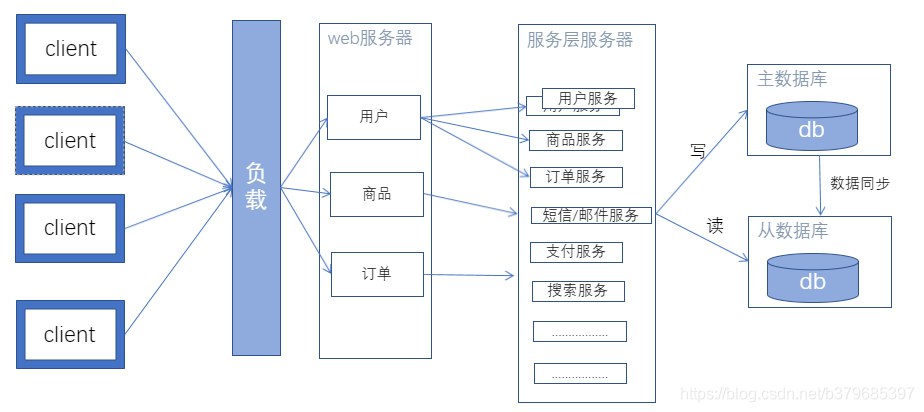
架构演进六: javaweb的微服务发展
特征:从业务角度,细分业务为微服务,每一个微服务是一个完整的服务(从http请求到返回)。在微服务内部,将需要对外提供的接口,包装成rpc接口,对外部开放。
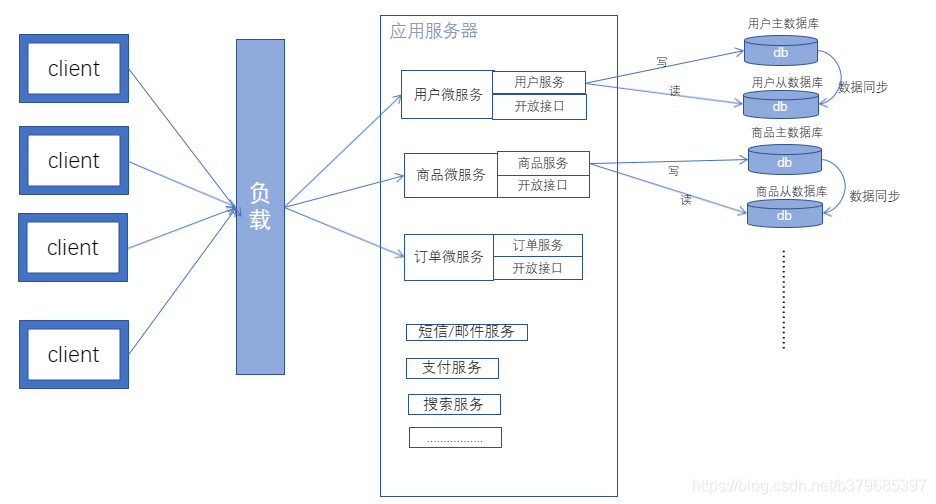
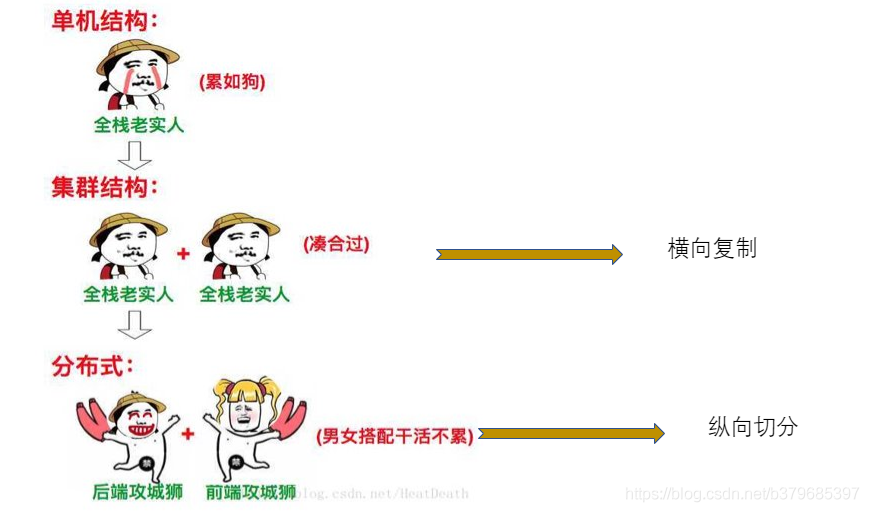
集群与分布式的区别
我在面试的时候,发现很多同学会把集群和分布式混淆,其实他俩完全是两个东西
分布式:纵向拆分,一个业务分拆多个子业务,部署在不同的服务器上。主要是业务层面拆分,进行业务解耦,从而提高服务高可用以及高性能。
集群:横向复制,同一个业务,部署在多个服务器上,前面通过负载均衡,起到分担压力的作用。而且这些服务器中,即使有一两个宕机也不会影响到整体业务。

本章主要讲了一下高性能架构的学习路线,以及技术演进史。接下来聊聊Alibaba百万年薪架构师必备技能——高性能架构学习路线(笔记):中间件、Nginx、缓存、ZK等等…看下方高性能架构进阶技能图…
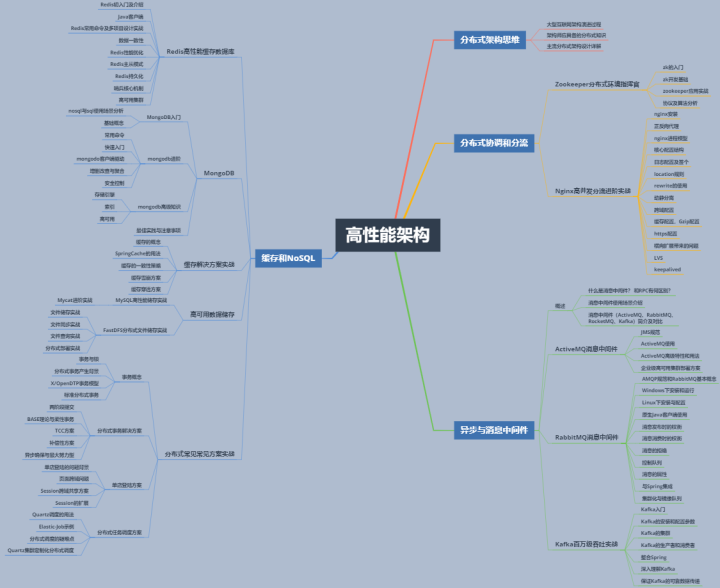
说明:以下全部所说的架构师必备技能之高性能架构学习路线及相关笔记:中间件、Nginx、缓存、ZK等等等,篇幅有限,很多都是截图展示,但是图片都是很高清的,可以清晰的看见其中的内容。
一、Zookeeper分布式环境指挥官

1.1 zookeeper基础
ZooKeeper是一种分布式协调服务,用于管理大型主机。在分布式环境中协调和管理服务是一个复杂的过程。ZooKeeper通过其简单的架构和API解决了这个问题。ZooKeeper允许开发人员专注于核心应用程序逻辑,而不必担心应用程序的分布式特性。
1.2 分布式应用的优点
-
(1)可靠性 - 单个或几个系统的故障不会使整个系统出现故障。
-
(2)可扩展性 - 可以在需要时增加性能,通过添加更多机器,在应用程序配置中进行微小的更改,而不会有停机时间。
-
(3)透明性 - 隐藏系统的复杂性,并将其显示为单个实体/应用程序。
1.3 分布式应用的挑战
-
(1)竞争条件 - 两个或多个机器尝试执行特定任务,实际上只需在任意给定时间由单个机器完成。例如,共享资源只能在任意给定时间由单个机器修改。
-
(2)死锁 - 两个或多个操作等待彼此无限期完成。
-
(3)不一致 - 数据的部分失败。
1.4 Zookeeper相关笔记
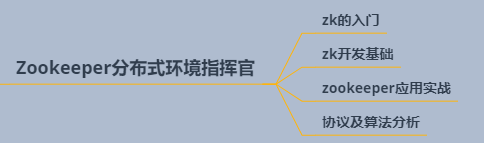
- ZK 手写笔记(1):概述+CPA+环境搭配+一致性协议+基本使用

- ZK 手写笔记(2):源码解析+应用场景
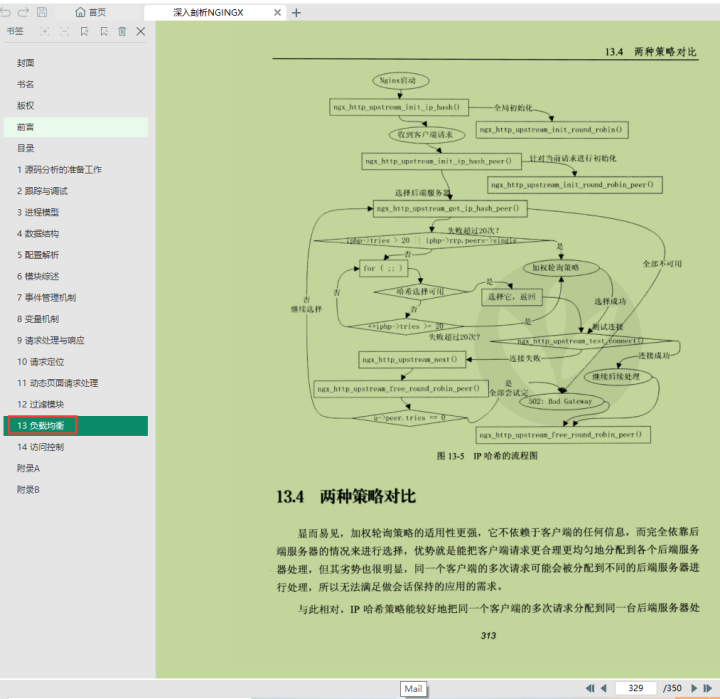
二、Nginx高并发分流进阶实战

2.1 nginx如何实现高并发
-
简单来讲,就是异步,非阻塞,使用了epoll和大量的底层代码优化。
-
稍微详细一点展开的话,就是nginx的特殊进程模型和事件模型的设计。
2.2 进程模型
-
nginx采用一个master进程,多个woker进程的模式。
-
master进程主要负责收集、分发请求。当一个请求过来时,master拉起一个worker进程负责处理这个请求。
-
master进程也要负责监控woker的状态,保证高可靠性
-
woker进程一般设置为跟cpu核心数一致。nginx的woker进程跟apache不一样。apche的进程在同一时间只能处理一个请求,所以它会开很多个进程,几百甚至几千个。而nginx的woker进程在同一时间可以处理额请求数只受内存限制,因此可以处理多个请求。
2.3 事件模型
nginx是异步非阻塞的。
每进来一个request,会有一个worker进程去处理。但不是全程的处理,处理到什么程度呢?处理到可能发生阻塞的地方,比如向上游(后端)服务器转发request,并等待请求返回。那么,这个处理的worker不会这么傻等着,他会在发送完请求后,注册一个事件:“如果upstream返回了,告诉我一声,我再接着干”。于是他就休息去了。此时,如果再有request 进来,他就可以很快再按这种方式处理。而一旦上游服务器返回了,就会触发这个事件,worker才会来接手,这个request才会接着往下走。
web server的工作性质决定了每个request的大部份生命都是在网络传输中,实际上花费在server机器上的时间片不多。这是几个进程就解决高并发的秘密所在。
2.4 Nginx相关笔记

- Nginx 常见应用技术指南[Nginx Tips]

- 深入剖析Nginx

三、rabbitMQ消息中间件

-
(1)Broker:消息中间件实例, 可能是单个节点也可能是运行在多节点集群上的逻辑实体
-
(2)消息(Message):消息由消息头和消息体两部分组成。消息头中包括routing-key、priority等标准消息头以及其它自定义消息头,用于定义RabbitMQ对消息行为。消息体是字节流,包含消息内容。
-
(3)连接(Connection):客户端与 Broker 之间的 TCP连接
-
(4)信道(Channel) :Channel 是建立在 TCP 连接上的逻辑(虚拟)连接。多个 Channel 复用同一个 TCP 连接, 以避免建立 TCP 连接的巨大开销。 RabbitMQ 官方要求每个线程使用独立的 Channel, 禁止多个线程共用 Channel。
-
(5)生产者(Publisher):发送消息的客户端线程
-
(6)消费者(Consumer):处理消息的客户端线程
-
(7)交换机(Exchange):交换机负责将消息投递到相应的队列
-
(8)队列(Queue):接收并保存交换机投递的消息,直至被消费者成功消费。逻辑结构遵循先进先出FIFO。
-
(9)绑定(Binding):将队列(Queue)注册到交换机(Exchange)的路由表
-
(10)虚拟主机(Vhost):每个Broker下可建立多个vhost, 每个 vhost 可建立独立的 Exchange、Queue、绑定及权限系统。同一个 Broker 下的 vhost 共享 Connection、Channel 和 用户系统,就是说可以使用同一个用户身份使用同一个 Channel 访问不同 vhost。
3.1 rabbitMQ消息中间件相关笔记

- RabbitMQ-最完整最全教程
- RabbitMQ实战指南
四、ActiveMQ消息中间件

-
(1)多种语言和协议编写客户端。语言: Java,C,C++,C#,Ruby,Perl,Python,PHP。应用协议: OpenWire,Stomp REST,WS Notification,XMPP,AMQP
-
(2)完全支持JMS1.1和J2EE 1.4规范 (持久化,XA消息,事务)
-
(3) 对Spring的支持,ActiveMQ可以很容易内嵌到使用Spring的系统里面去,而且也支持Spring2.0的特性
-
(4) 通过了常见J2EE服务器(如 Geronimo,JBoss 4,GlassFish,WebLogic)的测试,其中通过JCA 1.5 resource adaptors的配置,可以让ActiveMQ可以自动的部署到任何兼容J2EE 1.4 商业服务器上
-
(5) 支持多种传送协议:in-VM,TCP,SSL,NIO,UDP,JGroups,JXTA
-
(6)支持通过JDBC和journal提供高速的消息持久化
-
(7)从设计上保证了高性能的集群,客户端-服务器,点对点
-
(8) 支持Ajax
-
(9)支持与Axis的整合
-
(10)可以很容易的调用内嵌JMS provider,进行测试
五、Kafka百万级吞吐实战

kafka 最初是 LinkedIn 的一个内部基础设施系统。最初开发的起因是,LinkedIn 虽然有了数据库和其他系统可以用来存储数据,但是缺乏一个可以帮助处理持续数据流的组件。所以在设计理念上,开发者不想只是开发一个能够存储数据的系统,如关系数据库、Nosql 数据库、搜索引擎等等,更希望把数据看成一个持续变化和不断增长的流,并基于这样的想法构建出一个数据系统,一个数据架构。
Kafka外在表现很像消息系统,允许发布和订阅消息流,但是它和传统的消息系统有很大的差异,
-
首先,Kafka是个现代分布式系统,以集群的方式运行,可以自由伸缩。
-
其次,Kafka可以按照要求存储数据,保存多久都可以。
-
第三,流式处理将数据处理的层次提示到了新高度,消息系统只会传递数据,Kafka 的流式处理能力可以让我们用很少的代码就能动态地处理派生流和数据集。所以 Kafka 不仅仅是个消息中间件
Kafka 不仅仅是一个消息中间件,同时它是一个流平台,这个平台上可以发布和订阅数据流(Kafka 的流,有一个单独的包 Stream 的处理),并把它们保存起来,进行处理,这个是 Kafka 作者的设计理念。
5.1 Kafka百万级吞吐实战相关笔记
- 手写“Kafka笔记”
- Kafka源码解析与实战
六、Redis高性能缓存数据库

6.1 Redis的数据结构和相关常用命令
-
Key:Redis采用Key-Value型的基本数据结构,任何二进制序列都可以作为Redis的Key使用(例如普通的字符串或一张JPEG图片)
-
String:String是Redis的基础数据类型,Redis没有Int、Float、Boolean等数据类型的概念,所有的基本类型在Redis中都以String体现。
-
SET:为一个key设置value,可以配合EX/PX参数指定key的有效期,通过NX/XX参数针对key是否存在的情况进行区别操作,时间复杂度O(1)
-
GET:获取某个key对应的value,时间复杂度O(1)
-
GETSET:为一个key设置value,并返回该key的原value,时间复杂度O(1)
-
MSET:为多个key设置value,时间复杂度O(N)
-
MSETNX:同MSET,如果指定的key中有任意一个已存在,则不进行任何操作,时间复杂度O(N)
-
MGET:获取多个key对应的value,时间复杂度O(N)
-
INCR:将key对应的value值自增1,并返回自增后的值。只对可以转换为整型的String数据起作用。时间复杂度O(1)
-
INCRBY:将key对应的value值自增指定的整型数值,并返回自增后的值。只对可以转换为整型的String数据起作用。时间复杂度O(1)
-
DECR/DECRBY:同INCR/INCRBY,自增改为自减。
6.2 Redis高性能缓存数据库相关笔记
- Redis高性能缓存

- Redis实战

- Redis设计与实现

六、分布式系统常用技术及案例分析(PDF)

本PDF分为三大部分,即分布式系统基础理论、分布式系统常用技术以及经典的分布式系统案例分析。
-
第一部分主要介绍分布式系统基础理论知识,总结一些在设计分布式系统时需要考虑的范式、知识点以及可能会面临的问题,其中包括线程、通信、一致性、容错性、CAP理论、安全性和并发等相关内容;同时讲述分布式系统的常见架构体系,其中也包括最近比较火的RESTful风格架构、微服务、容器技术等
-
第二部分主要列举了在分布式系统应用中经常用到的一些主流技术,并介绍这些技术的作用和用法;这些技术涵盖了分布式消息服务、分布式计算、分布式存储、分布式监控系统、分布式版本控制、RESTful、微服务、容器等领域的内容。
-
第三部分选取了以淘宝网和Twitter为代表的国内外知名互联网企业的大型分布式系统案例,分析其架构设计以及演变过程;这部分相当于是对第二部分零散的技术点做一个“串烧”,让读者可以结合技术的理论,看到实战的效果。
面试资料整理汇总

这些面试题是我朋友进阿里前狂刷七遍以上的面试资料,由于面试文档很多,内容更多,没有办法一一为大家展示出来,所以只好为大家节选出来了一部分供大家参考,需要全部文档的,关注小编后,点击这里即可免费领取。
面试的本质不是考试,而是告诉面试官你会做什么,所以,这些面试资料中提到的技术也是要学会的,不然稍微改动一下你就凉凉了
让读者可以结合技术的理论,看到实战的效果。
面试资料整理汇总
[外链图片转存中…(img-xC8u6cyc-1626166090550)]
[外链图片转存中…(img-pW2jbriR-1626166090550)]
这些面试题是我朋友进阿里前狂刷七遍以上的面试资料,由于面试文档很多,内容更多,没有办法一一为大家展示出来,所以只好为大家节选出来了一部分供大家参考,需要全部文档的,关注小编后,点击这里即可免费领取。
面试的本质不是考试,而是告诉面试官你会做什么,所以,这些面试资料中提到的技术也是要学会的,不然稍微改动一下你就凉凉了
在这里祝大家能够拿到心仪的offer!

