
- 1EHCI和OHCI,UHCI的比较和区别_ehci ohci uhci
- 2YOLOv3,YOLOv4学习_yolov3_cspdarknet_fpn
- 3自然语言处理NLP知识结构_自然语言处理功能模块结构图
- 4六何时适合使用蜻蜓优化算法?_蜻蜓优化算法应用领域
- 5【LSTM分类】基于鲸鱼算法优化空间注意力机制的卷积神经网络结合长短记忆神经网络KOA-CNN-LSTM-SAM-attention实现数据分类附matlab代码
- 6关于Clang
- 7【Phase One SDK】飞思相机SDK的环境配置及调用_phase one linux sdk
- 8小程序源码免费html5,微信小程序静态页面案例(附源码)
- 9Python数据分析,pandas对日期的处理_python记录不同年相同月份的数据
- 10分类和标注词汇(基于nltk)_nltk区分场景类名词和目标类名词
AIGC——DreamTuner通过单张图片生成与该图片主题风格一致的新图像
赞
踩
简介
DreamTuner的能力在于从单个图像生成主体驱动的新通用方法,这意味着用户只需提供一张图片,DreamTuner就能帮助他们生成与原始图片在主题和风格上一致的新图像。
算法重要之处在于其通用性和个性化定制的能力。无论是需要根据特定主题或条件创建个性化图像的场景,还是希望将一个特定主题或风格应用到已有图像中,DreamTuner都能够胜任。
DreamTuner的论文的发布可能会对多个领域产生重大影响。例如,在创意设计领域,设计师可以利用它快速生成符合特定主题或风格的创意作品;在数字内容创作领域,用户可以轻松创建个性化的图像内容,以满足特定需求或品牌形象;在娱乐行业,这项技术可能被用于影视特效、游戏开发等方面,为创作带来更多可能性。

在动漫制作领域,有了DreamTuner这样的工具,能够极大地简化动漫角色的创作过程,让创作者能够更轻松地实现他们的创意。在此之前,想要创建一个全新的动漫角色,可能需要通过不断尝试生成更多类似的角色,或者使用不太可控的图生图功能,这会花费很多时间和精力,并且无法保证生成的图片风格与我想要的一致。
但现在有了DreamTuner,只需上传我喜欢的参考图像,并添加文本描述,比如“坐在公园的长椅上”,DreamTuner就能根据提供的参考图像和描述来生成新的图像。在这个过程中,DreamTuner会保留原始参考图像的关键特征,比如角色的风格和特点,同时根据描述添加新的元素和场景。
这种方式不仅简化了创作过程,还能确保新生成的图像与原始参考图像保持一致的风格和主题,这对于动漫角色创作者来说是一个非常有用的工具。
论文地址:https://arxiv.org/abs/2312.13691
项目地址:https://dreamtuner-diffusion.github.io/
摘要
大型基于扩散的模型在文本到图像的生成方面已经展示了令人印象深刻的能力,并且有望用于需要使用一个或几个参考图像生成定制概念的个性化应用,即主题驱动生成。然而,现有的基于微调的方法需要在主题学习和维持预训练模型的生成能力之间进行权衡。此外,其他基于附加图像编码器的方法往往会由于编码压缩而丢失主题的一些重要细节。
为了解决这些问题,提出了一种新的方法DreamTuner,它将定制主题的参考信息从粗到细注入。首先提出了一种用于粗主题身份保存的主题编码器,其中压缩的一般主题特征在视觉-文本交叉注意之前通过额外的注意层引入。然后,我们注意到预训练文本到图像模型中的自注意层自然地执行详细的空间上下文关联功能,我们将它们修改为自主体注意层以细化目标主体的细节,其中生成的图像从参考图像和自身查询详细特征。值得强调的是,自我主体注意是一种优雅、有效且无需训练的方法,用于维护定制概念的详细特征,可以在推理过程中作为即插即用的解决方案使用。最后,通过对单张图像进行额外的微调,DreamTuner在由文本或姿势等其他条件控制的主题驱动图像生成方面取得了卓越的表现。
实现方法
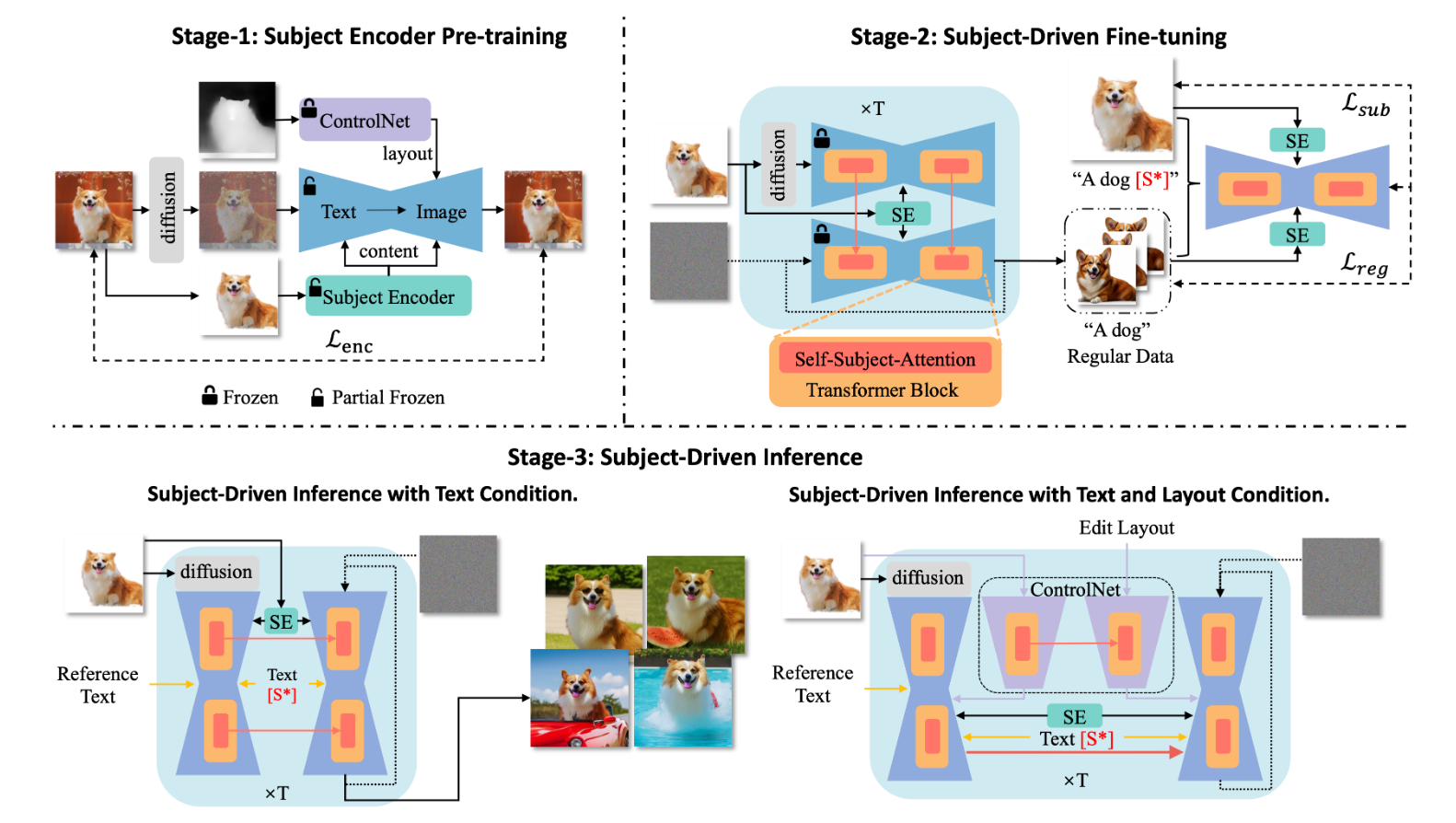
提出DreamTuner作为一个基于微调和图像编码器的主题驱动图像生成的新框架,它保持了主题从粗到细的身份。DreamTuner包括三个阶段:主题编码器预训练、主题驱动微调和主题驱动推理。
首先,对主题编码器进行粗身份保持训练。主题编码器是一种为生成模型提供压缩图像特征的图像编码器。利用冻结控制网实现内容与布局的解耦。然后我们在参考图像和一些在DreamBooth中生成的常规图像上对整个模型进行微调。注意,主体编码器和自我主体注意用于常规图像生成,以细化常规数据。在推理阶段,使用主体编码器、自我主体注意和通过微调得到的主题词[S*],实现由粗到精的主体身份保持。预训练的ControlNet也可用于布局控制生成。
-
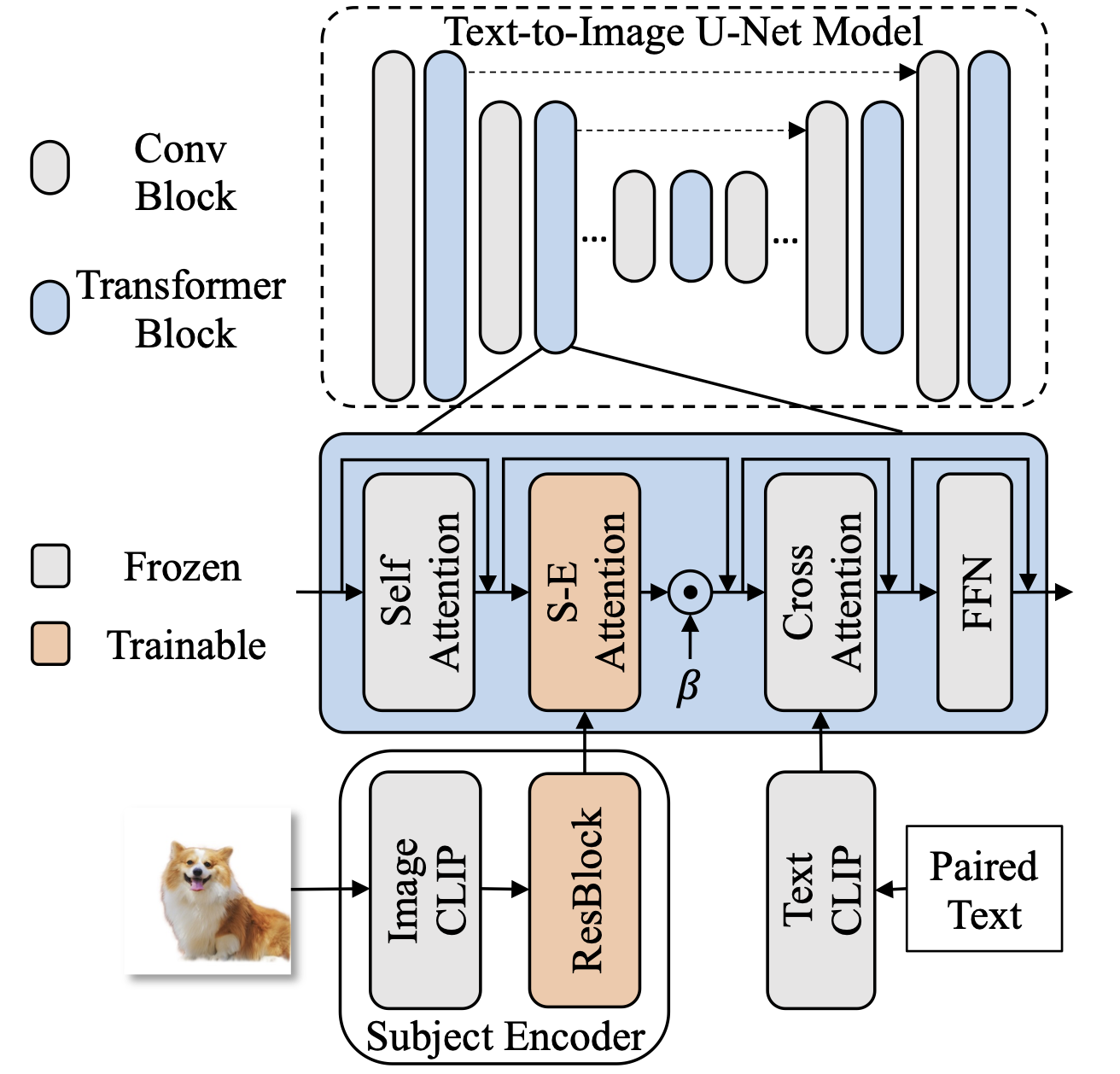
主题编码器作为图像编码器被提出,为主题驱动的生成提供了一个粗略的参考。这里采用冷冻CLIP图像编码器来提取参考图像的压缩特征。通过显著目标检测(SOD)模型或分割模型去除输入图像的背景,以突出主题。
-
引入了一些残差块(ResBlock)来进行域移位。CLIP提取的多层特征在通道维度上进行拼接,然后通过残差块调整到与生成的特征相同的维度。采用额外的主题编码器-注意(S-E-A)层,将主题编码器的编码参考特征注入到文本-图像模型中。这一注意层在视觉-文本交叉注意层之前添加,因为交叉注意层是控制生成图像一般外观的模块。
-
根据与交叉注意相同的设置和输出层的初始值为零,构建主题编码器注意。引入一个附加系数β来调节主体编码器的影响。此外,主题编码器将为文本到图像的生成提供参考图像的内容和布局。然而,在大多数情况下,主题驱动生成不需要布局。
-
进一步引入ControlNet来帮助解耦内容和布局。具体来说,训练主题编码器连同冻结深度控制网。由于ControlNet提供了参考图像的布局,因此主题编码器可以更加专注于主题内容。
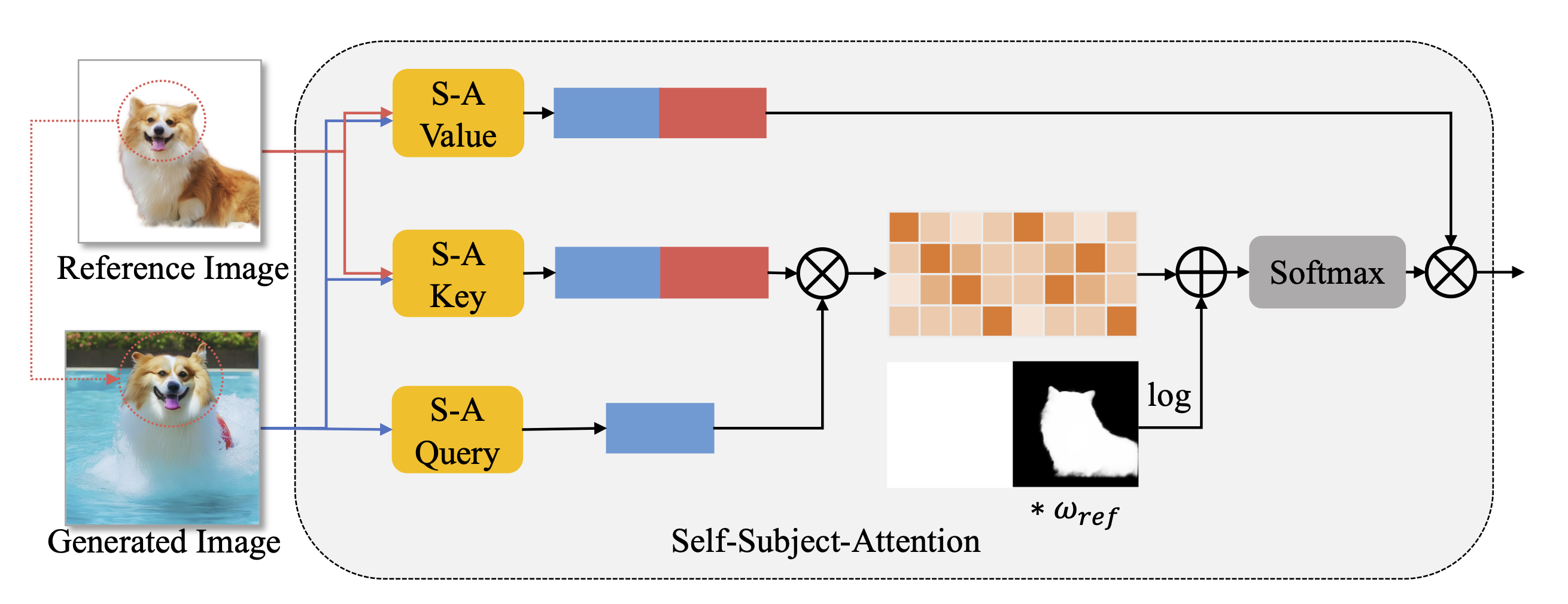
由于主题编码器为生成过程提供了特定主题的总体外观,我们进一步提出了基于原始自注意层的自我主题注意,以保持良好的主题身份。这个方法涉及将预先训练好的文本到图像U-Net模型提取的参考图像特征注入到自注意层中。参考特征与生成图像的特征具有相同的分辨率,可以提供精细化的详细参考。具体而言,在每个时间步长t对参考图像进行扩散前处理,然后从噪声后的参考图像中提取每个自注意层前的参考特征,使其与时间步长t生成的图像特征具有相同的数据分布。利用参考特征将原始自注意层修改为自主体注意层。将生成图像的特征作为查询,将生成图像特征与参考图像特征的拼接作为键和值。为了消除参考图像背景的影响,使用显著目标检测(SOD)模型创建前景蒙版,用0和1表示背景和前景。此外,遮罩还可以通过权重策略来调整参考图像的影响程度,即将遮罩乘以调整系数ωref。掩码作为注意偏差,因此使用log函数作为预处理。
将原来的分类器自由引导方法也修改为:
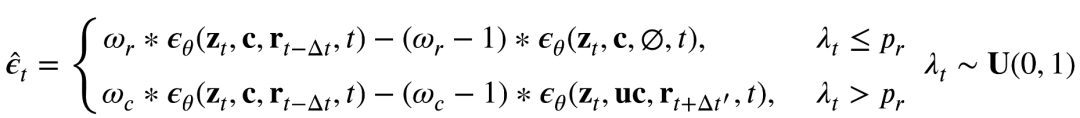
其中zt为时间步长t时生成的图像,c为条件,uc为不希望的条件,rt - Δt和rt Δt '为时间步长t - Δt和t Δt '时的扩散噪声参考图像,Δt和Δt '为小时间步长偏差,ωr和ωc为引导尺度,λ t为最终输出。第一个方程强调参考图像的引导,第二个方程强调条件的引导,其中pr控制选择第一个的可能性。
自我主体注意图的可视化
我们将生成过程的中间时间步(t=25)和最后时间步(t=0)的自我主体注意图可视化,文字为“1girl [S*],坐在桌旁,手里端着一杯茶,阳光从窗户射进来”。我们选择Diffusion U-Net模型的Encoder layer 7、8和Decoder layer 4、5的注意图,即当生成的图像分辨率为512512时,特征分辨率为1616的层。生成的图像显示在左边,参考图像显示在右边。注意力地图上,影响力大的区域呈红色,影响力小的区域呈蓝色。红色框表示查询。解码器第5层的一些关键注意图如下所示。可以发现所生成的图像将从参考图像中查询精炼的主题信息。

所有的注意力图都被可视化为视频:

实验结果
文本控制动画角色驱动图像生成的结果
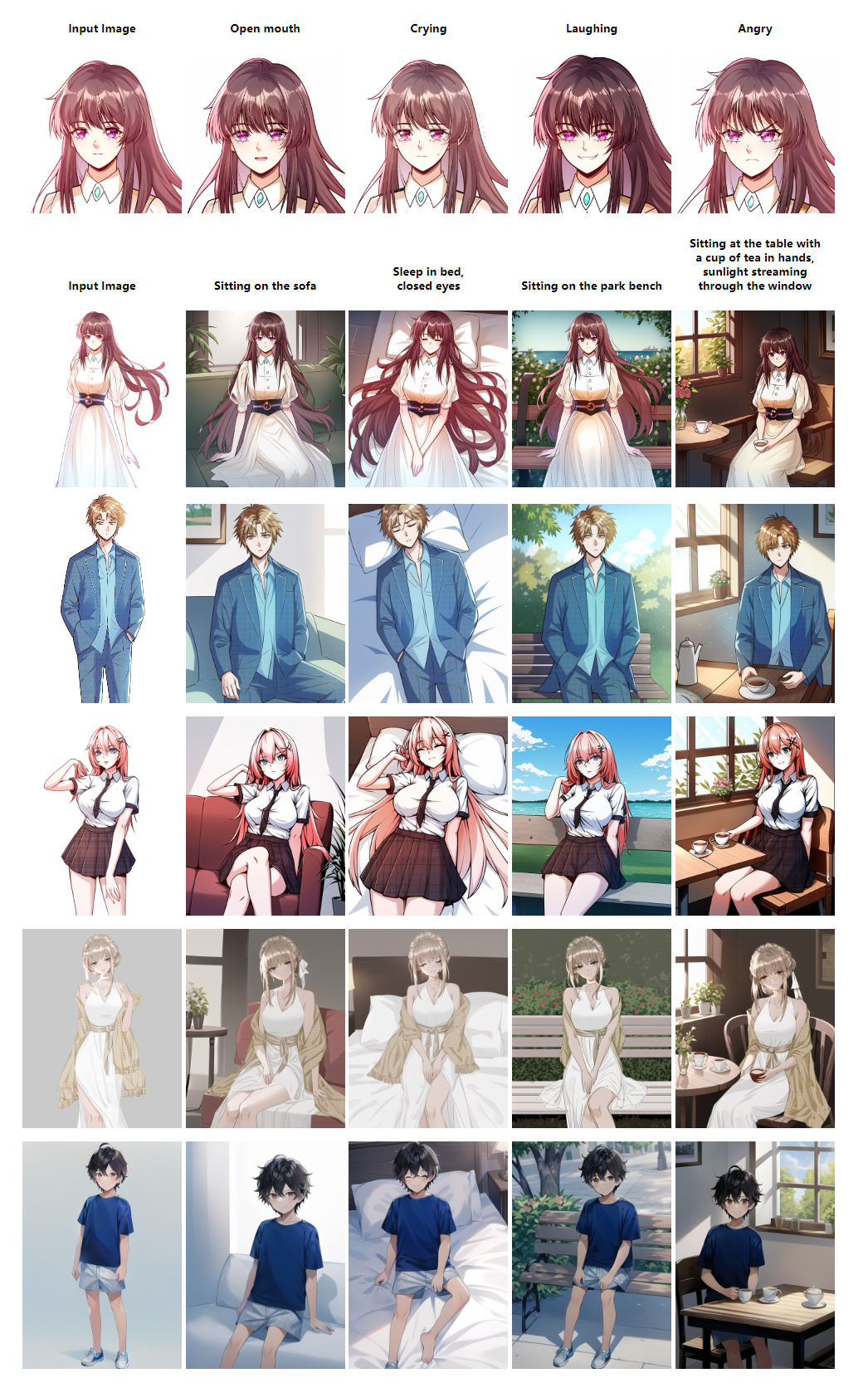
结果显示了文本控制的主题驱动的图像生成的输出,重点是动画角色。既进行了局部编辑(如第一行的表情编辑),也进行了全局编辑(包括随后五行的场景和动作编辑),即使输入复杂的文本,也能获得非常详细的图像。值得注意的是,图像准确地保持了参考图像的细节。
文本控制自然图像驱动图像生成的结果
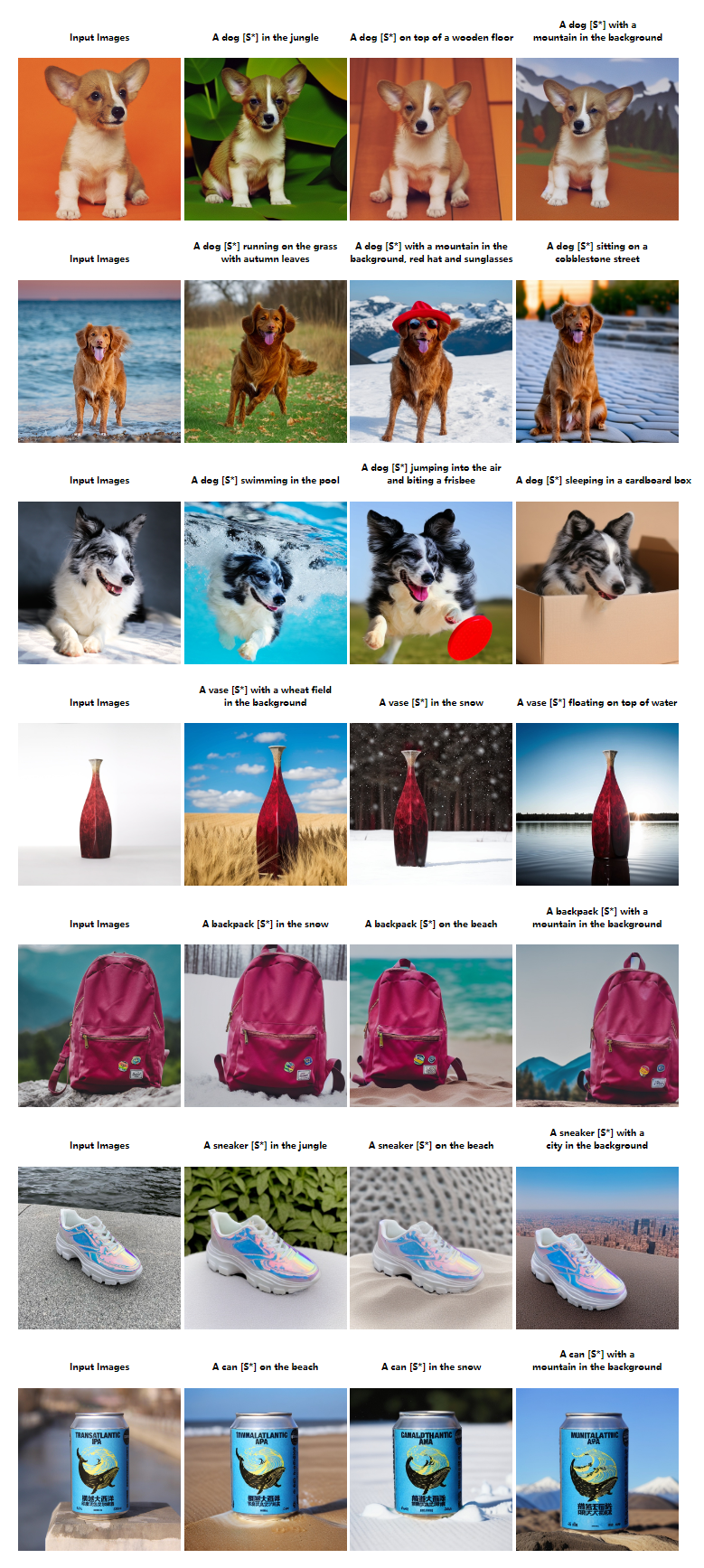
方法是在DreamBooth数据集上进行评估的,其中每个主题的一张图像被用作参考图像。通过使用主体编码器和自我主体注意,生成了一个精细的参考,这使得DreamTuner能够成功地产生与文本输入一致的高保真图像,同时还保留了关键的主题细节,包括但不限于,小狗头上的白色条纹,袋子上的标志,图案和罐头上的文字。
姿态控制驱动图像生成的结果

可以与ControlNet相结合,以扩大其对姿态等各种条件的适用性。在下面的例子中,只使用一张图像进行DreamTuner微调,并使用参考图像的姿态作为参考条件。为了保证帧间的一致性,参考图像和生成图像的前一帧都被用于自主体注意,参考权重分别为10和1。

