
- 1Could not initialize class org.gradle.internal.classloader.FilteringClassLoader求助
- 22022牛客多校3补题_e.pushu_back({a,b})
- 3AnimateDiff搭配Stable diffution制作AI视频_animatediff csdn
- 4计算机系统基础 第二章_计算机系统基础逻辑运算
- 5linux mount命令_mount remount
- 6解决CUDA driver version is insufficient for CUDA runtime version
- 7Hive SQL必刷练习题:连续问题 & 间断连续(*****)
- 8Android Gradle 7.x新版本的依赖结构变化_android gradle7 工程下的allprojects选项已经被移植到settings.gr
- 9EMQX+PolarDB-X构建一站式物联网数据解决方案_emqx 怎么做物联
- 10GAN及其衍生网络中生成器和判别器常见的十大激活函数(2024最新整理)
【AIGC】Animate Anyone阿里全民舞王背后的科技,基于图片高可控动画生成
赞
踩
在11月底,阿里巴巴集团智能计算研究院发布了一款AI动画项目:Animate Anyone。只需要一张人物静态图片,结合人物的骨骼动画(姿势控制),就能生成一段人物动画视频。
我们先通过官网放出的动画效果直观感受一下。


一. Animate Anyone简介
Animate Anyone: Consistent and Controllable Image-to-Video Synthesis for Character Animation,翻译中文就是"角色动画的一致且可控的图像到视频合成"。
角色动画旨在通过驱动信号从静止图像生成角色视频。目前,扩散模型因其强大的生成能力已成为视觉生成研究的主流。然而,图像到视频领域仍然存在挑战,特别是在角色动画中,暂时保持与角色详细信息的一致性仍然是一个艰巨的问题。
利用扩散模型的力量,团队提出了一个为角色动画量身定制的新颖框架。为了保持参考图像中复杂外观特征的一致性,设计了 ReferenceNet 通过空间注意力来合并细节特征。为了确保可控性和连续性,引入了有效的姿势引导器来指导角色的运动,并采用有效的时间建模方法来确保视频帧之间平滑的帧间过渡。
通过扩展训练数据,该方法可以对任意角色进行动画处理,与其他图像到视频方法相比,在角色动画方面产生更好的结果。此外,项目团队在时尚视频合成方面,可以将时尚照片转换为真实的动画视频,还可以根据时尚视频和人类舞蹈的结合,取得了不错的效果。
官网地址:https://humanaigc.github.io/animate-anyone/
论文:https://arxiv.org/pdf/2311.17117.pdf
二. 实现机制
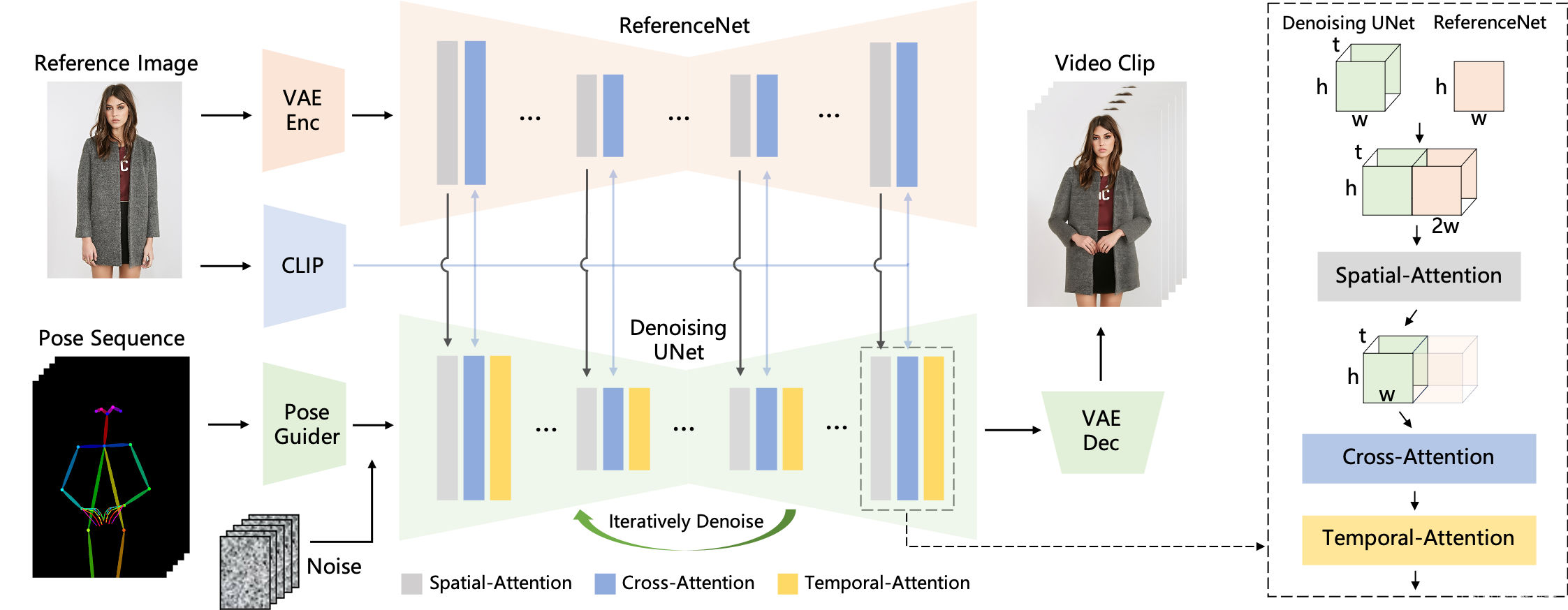
(1)姿势序列最初使用 Pose Guider 进行编码,并与多帧噪声融合,
(2)由 Denoising UNet 进行视频生成的去噪过程。Denoising UNet 的计算模块由 Spatial-Attention、Cross-Attention 和 Temporal-Attention 组成,如右侧虚线框所示。参考图像的集成涉及两个方面。
-
首先,通过ReferenceNet提取详细特征并用于空间注意力。
-
其次,通过CLIP图像编码器提取语义特征进行交叉注意力。时间注意力在时间维度上运作。
(3)最后,VAE解码器将结果解码为视频剪辑。
三. 为各种角色定制动画
人物
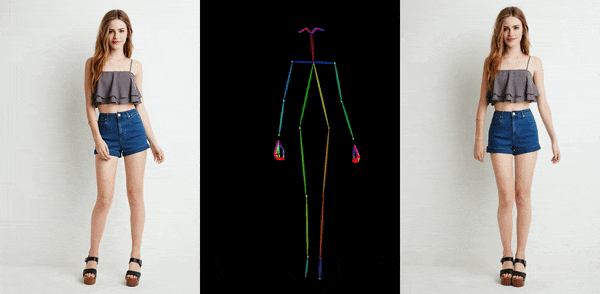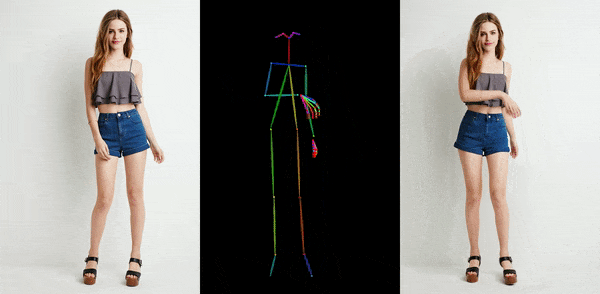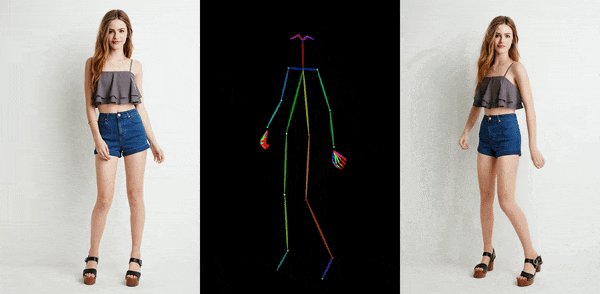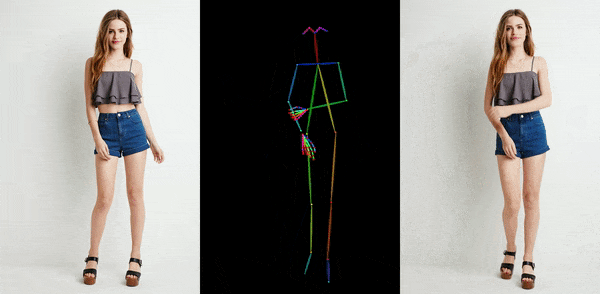

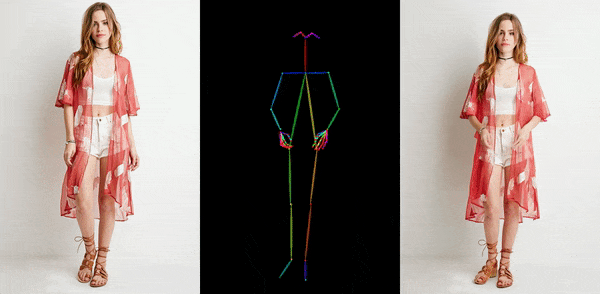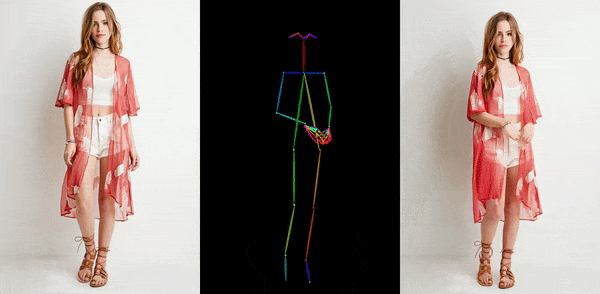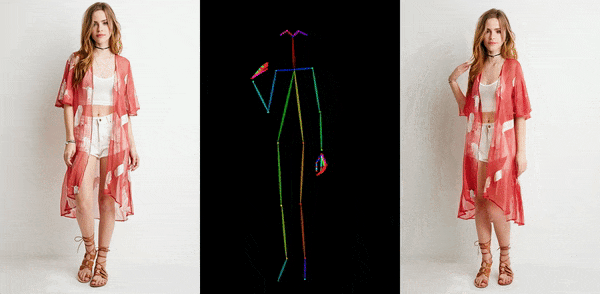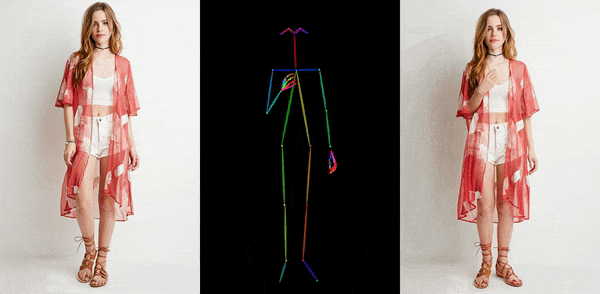
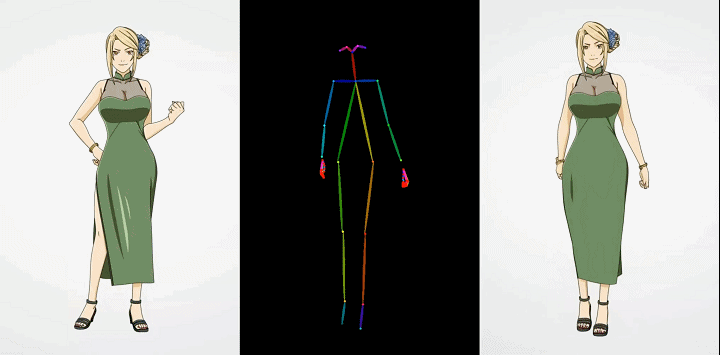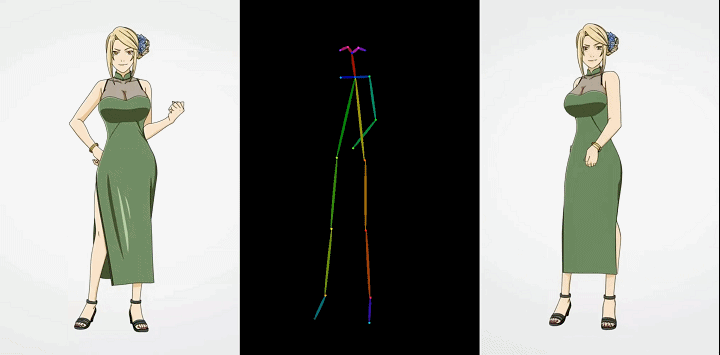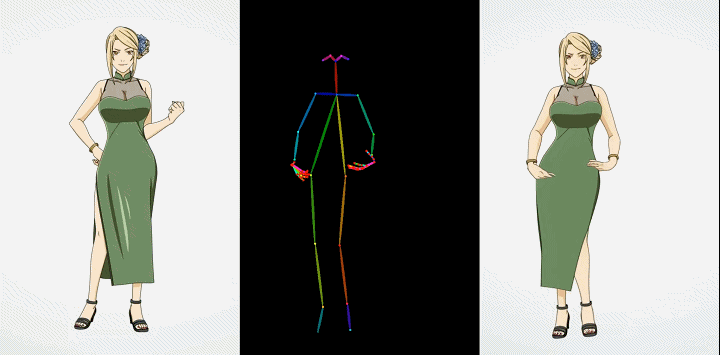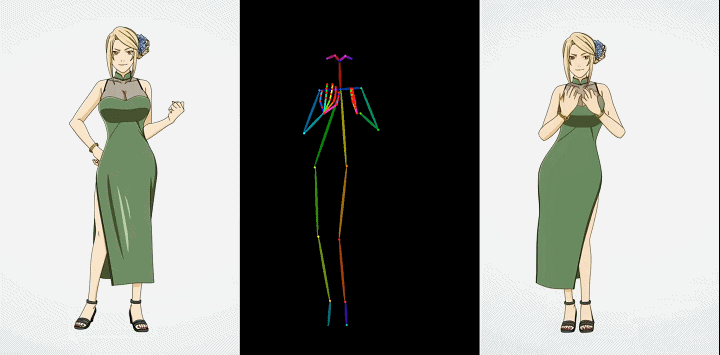
卡通动漫


人行
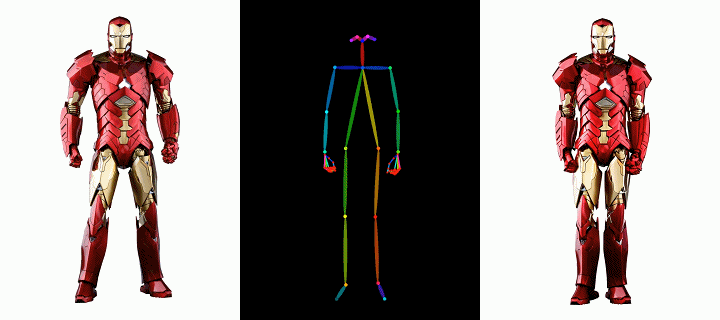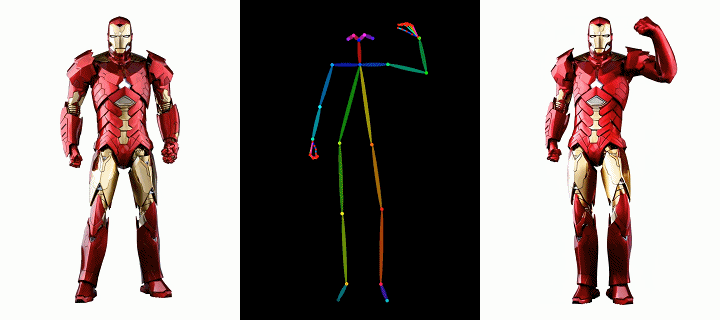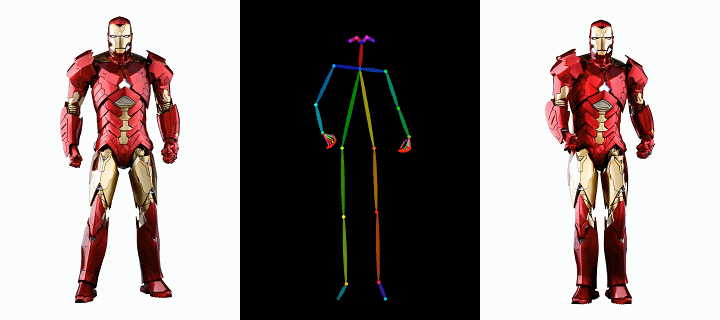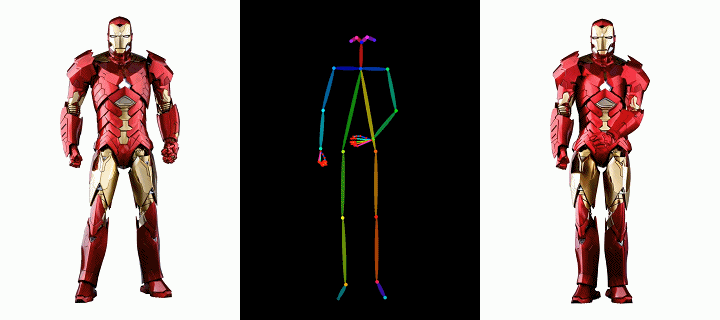
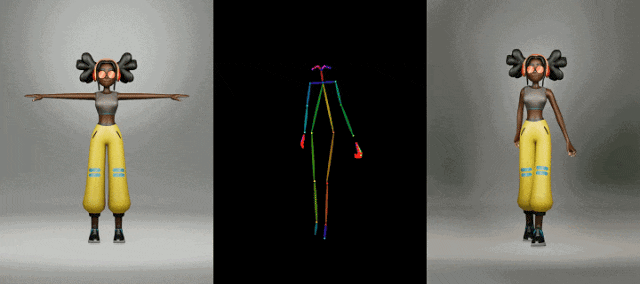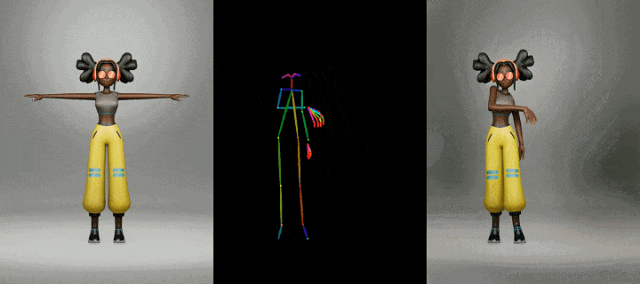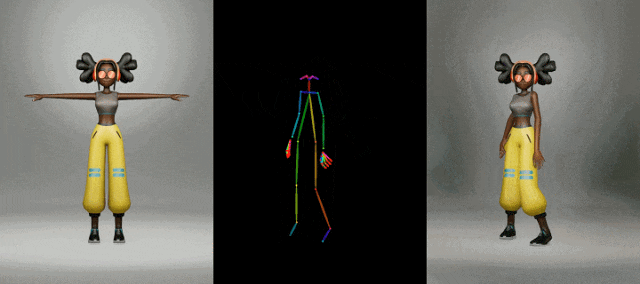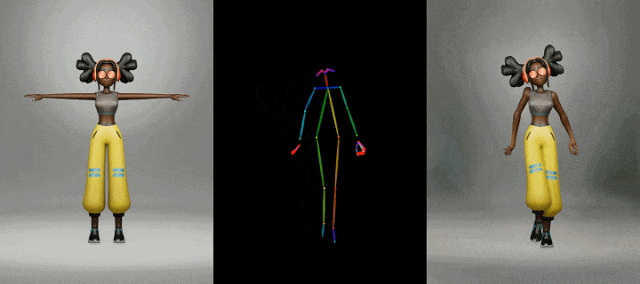
时尚视频合成
时尚视频合成旨在使用驾驶姿势序列将时尚照片变成逼真的动画视频。



人类舞蹈生成
人类舞蹈生成专注于在现实世界的舞蹈场景中制作动画图像。
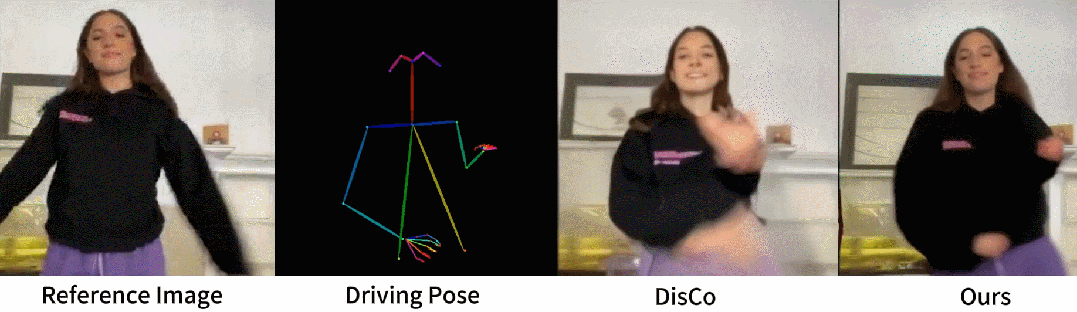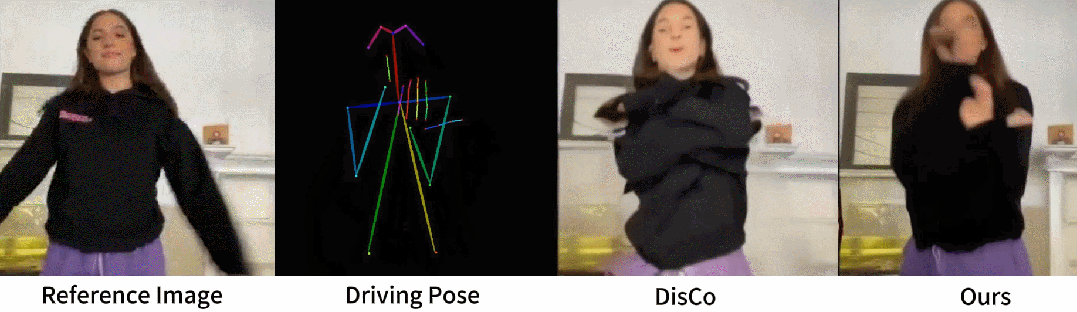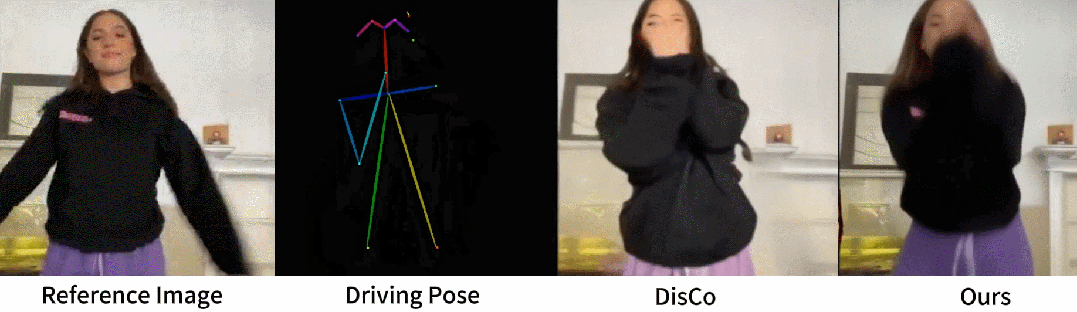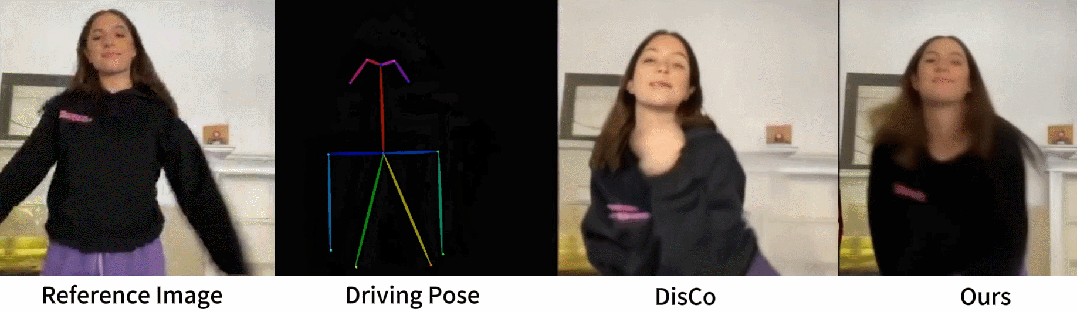
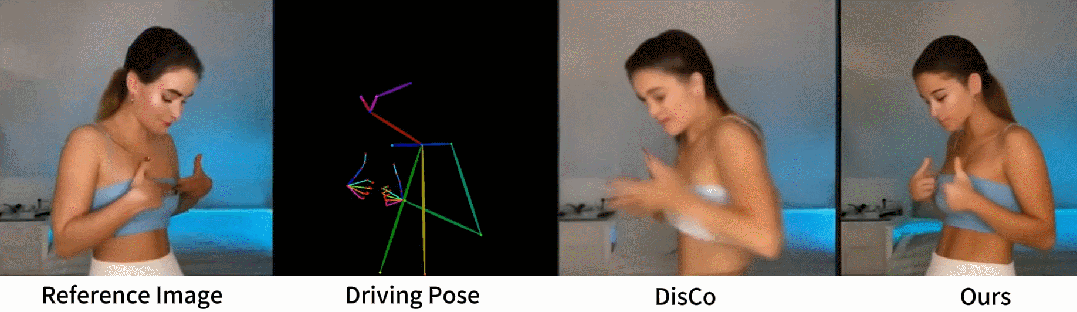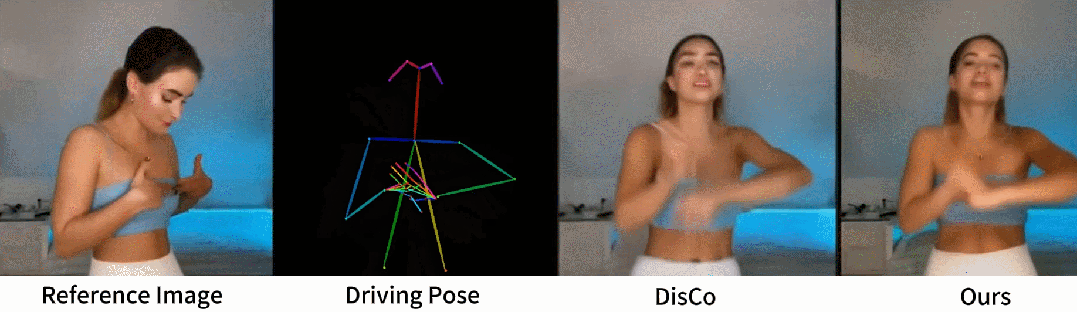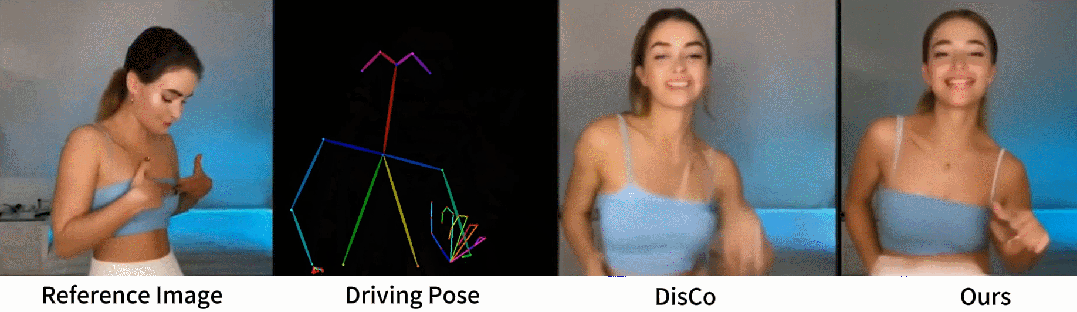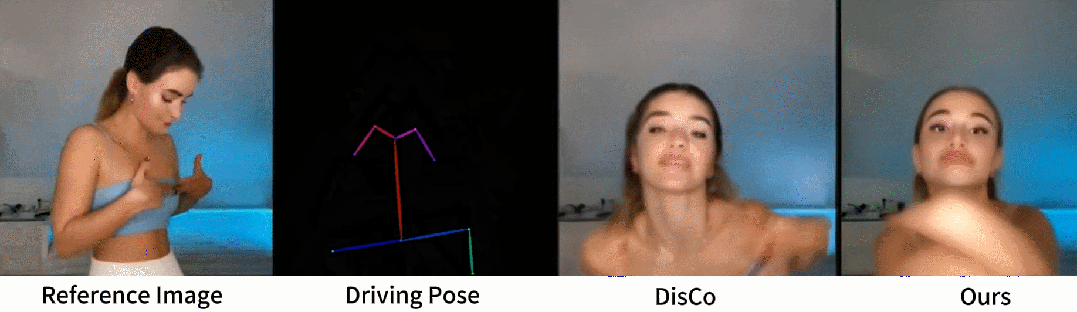

从官网提供的示例中,我们可以看到,不管是图片生成视频、时尚视频合成还是人类舞蹈,Animate Anyone生成的动画视频在人物的一致性和画面的稳定性上,都表现极佳,视频质量很高,也非常流畅!
四. 该模型的3个局限性
在提供的论文中,也提到了该模型的3个局限性。
(1)与许多视觉生成模型类似,该模型可能难以为手部运动生成高度稳定的效果,有时会导致扭曲和动态模糊。
(2)因为图像只提供了一个视觉的信息,在角色运动过程中产生看不见的部分
会遇到潜在不稳定性的问题。
(3)由于利用DDPM时,与非基于扩散模型的方法相比该模型显示出较低的运行效率,可能会影响动画的生成速度和实时性能。
五. 总结
Animate Anyone,一张人物静态照片加一个骨骼动画就可以生成可控并且一致的人物动画视频框架,在真正保留复杂的人物外观基础上,通过所需的姿势序列来控制动画,实现高效的姿势可控性和时间稳定性。
通过这种技术,可以在不需要复杂动画技能和昂贵的软件情况下,创造出流畅的动画视频,Animate Anyone提供了一种由图像到视频合成中角色动画创建的新方法和新思路,具有未来扩展到各种图像到视频应用的潜力。
之前阿里发布Animate Anyone的时候,没有提供项目的demo, 也没有提供源代码。让外界无法直接体验或评估这项技术的实际使用效果。时隔不到2个月,想不到阿里把它集成到通义千问APP里,只需要对着通义千问APP发送一句"全民舞王",就能进入"全民舞王"的页面,直接体验Animate Anyone技术带来的科技乐趣。
好了,今天的分享就到这里了,希望今天分享的内容对大家有所帮助。

