
- 1Android开发板串口(SerialPort)通信_android serialport
- 2网络安全自学路线(超详细)_网络安全零基础学习路线
- 3微信小程序如何实现页面之间的数据传递_微信小程序怎样把一个页面收到的消息同步到另一个页面
- 4后端web开发框架(六):application.properties文件常见配置_application.properties配置
- 5pcl::filter::GaussianKernal_pcl::gaussiankernel
- 6CVPR 2020 论文大盘点-图像修复Inpainting篇
- 727岁到来之际,我在阿里实现了年薪30W+的小目标
- 8Python显示循环代码的进度条_python循环显示进度
- 9[Linux]shell中的变量_linux变量中的变量
- 10请不要嘲笑有梦想的罗永浩_老罗的梦想
自然语言处理4——TF-IDF及特征提取_(tfidf_features.toarray()是啥意思
赞
踩
1. TF-IDF原理
TF-IDF是Term Frequency - Inverse Document Frequency的缩写,即“词频——逆文本频率”。它由两部分组成,TF和IDF,也就是这两部分的乘积。
TF指的就是常用的词频。
IDF,即“逆文本频率”。其实,不考虑停用词的话,一些词在所有文本都会出现,其词频虽然高,但是重要性却应该比词频低的一些关键词要低。IDF就是用来反应词的重要性的,进而修正仅仅用词频表示的词特征值。
概括来讲, IDF反应了一个词在所有文本中出现的频率,如果一个词在很多的文本中出现,那么它的IDF值应该低,。反过来如果一个词在比较少的文本中出现,那么它的IDF值应该高。。这样的词IDF值应该高。一个极端的情况,如果一个词在所有的文本中都出现,那么它的IDF值应该为0。
下面对IMDB数据集(英文)训练集neg部分用sklearn进行TF-IDF计算(主要代码如下):
from sklearn.feature_extraction.text import CountVectorizer
from sklearn.feature_extraction.text import TfidfTransformer
def tf_idf(vectorizer, sentlist):
vectorizer = CountVectorizer(min_df=1)
transformer = TfidfTransformer(stop_words=stopwords)
tfidf = transformer.fit_transform(vectorizer.fit_transform(sentlist))
return tfidf
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
这里是我得到的部分TF-IDF结果:
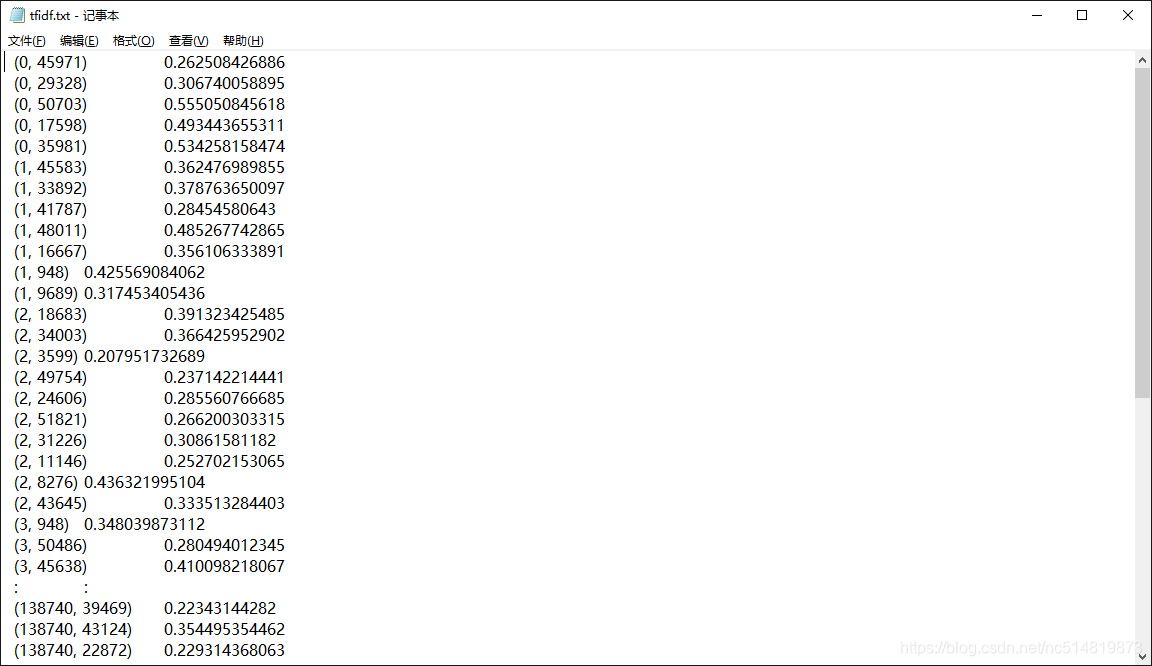
另外,还可以用 TfidfVectorizer,详细参考 https://blog.csdn.net/m0_37324740/article/details/79411651
2. 文本矩阵化
以TF-IDF特征值为权重,使TfidfTransformer,只需要将上边得到的TF-IDF结果转换为矩阵即可;
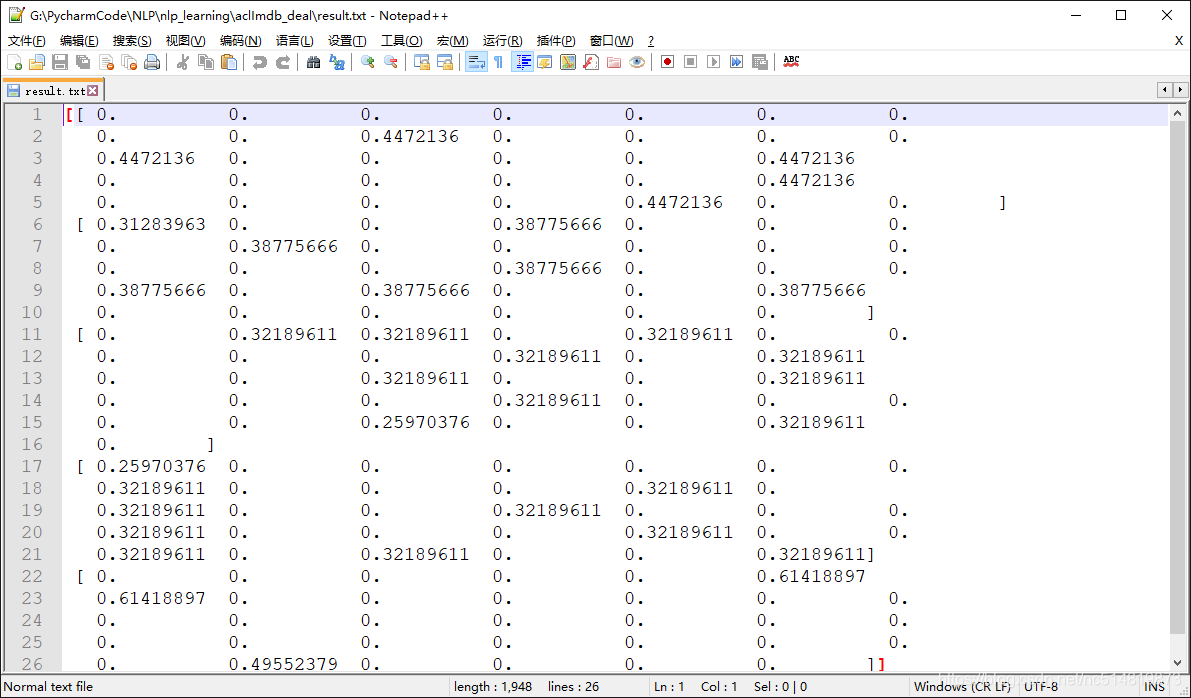
tfidf.toarray()
- 1
以下是我截取的部分结果(可能我代码没处理好,写文件时候内容太大了会发生内存溢出,先记录一下,后边想办法优化):
3. 互信息的原理
互信息(Mutual Information) 定义为:
∑
x
∈
X
∑
y
∈
Y
p
(
x
,
y
)
log
(
p
(
x
,
y
)
p
(
x
)
p
(
y
)
)
\sum_{x\in X}\sum_{y \in Y}p(x, y)\log(\frac{p(x, y)}{p(x)p(y)})
∑x∈X∑y∈Yp(x,y)log(p(x)p(y)p(x,y))
其衡量的是两个随机变量之间的相关性,即一个随机变量中包含的关于另一个随机变量的信息量。所谓的随机变量,即随机试验结
果的量的表示,可以简单理解为按照一个概率分布进行取值的变量,比如随机抽查的一个人的身高就是一个随机变量。
参考博文:https://blog.csdn.net/u013710265/article/details/72848755
4. 使用第二步生成的特征矩阵,利用互信息进行特征筛选
使用sklearn 计算x和label的互信息:
from sklearn import metrics as mr
mr.mutual_info_score(label,x)
- 1
- 2
这里由于时间有限,我上边只处理了IMDB数据集(英文)neg部分,暂时先不在这里进行实现,后边用其他案例补充。
参考
[1] https://blog.csdn.net/m0_37324740/article/details/79411651
[2] https://blog.csdn.net/u013710265/article/details/72848755

