
- 1百度世界2020再曝语义理解领域新进展:文心ERNIE全景图亮相
- 2C#_模拟鼠标操作_c#模拟鼠标左键点击
- 3【粉丝福利社】区块链与金融科技(文末送书-进行中)
- 4树莓派4安装Ubuntu20.10桌面版记录(64位系统arm架构desktop版)_pi 4b unable to connect to vnc server using your c
- 5遇到问题:validateOptions is not a function_originvalidatorfunc is not a function
- 6AT短信命令与离线短信应用获取异常_at+cpms
- 7【开源技术随笔】005 - Android编译报错:check_vintf.cpp For kernel requirements at matrix level 6_android文件系统修改
- 8Zabbix 实现监控windows主机网卡
- 9Android Studio快速导入Project的正确方法_android studio引入project
- 10Vue前置必会知识点_vue前置知识
Vitis AI 工具概述
赞
踩
深度学习处理器
深度学习处理器 (DPU) 是一个专为深度神经网络而优化的可编程引擎。它由一组可参数化的 IP 核组成,这些 IP 核在硬件上预实现,且无需布局布线。其设计主旨是为了帮助各种计算机视觉应用中广泛采用的深度学习推断算法实现计算工作负载加速,适合的应用包括图像/视频分类、语义分段以及目标检测/追踪。DPU 随 Vitis AI 专用指令集一起发布,从而促进深度学习网络的有效实现。 高效的张量层指令集旨在支持并加速各种常用的卷积神经网络,例如,VGG、ResNet、GoogLeNet、YOLO、SSD 和 MobileNet 等。DPU 可轻松扩展以适应从边缘到云端的各种赛灵思、Zynq UltraScale+ MPSoC、赛灵思 Kria KV260、Versal 卡和 Alveo 开发板,满足多种多样应用的不同需求。 Vitis 流程中会生成配置文件 arch.json。arch.json 文件可供 Vitis AI 编译器用于模型编译。一旦 DPU 配置发生修改,就必须生成新的 arch.json。并且必须使用新的 arch.json 文件重新生成模型。在 DPU-TRD 中,arch.json 文件位于 $TRD_HOME/prj/Vitis/binary_container_1/link/vivado/vpl/prj/prj.gen/sources_1/bd/xilinx_zcu102_base/ip/xilinx_zcu102_base_DPUCZDX8G_1_0/arch.json。 Vitis AI 能够为赛灵思、 Zynq® UltraScale+™ MPSoC、Kria KV260、Versal 卡等嵌入式器件以及 Alveo 卡(如 U50LV、U200、U250 和 U55C)提供一系列不同的 DPU,从而在吞吐量、时延、可扩展性以及功耗方面实现独特的差异性和灵活性。
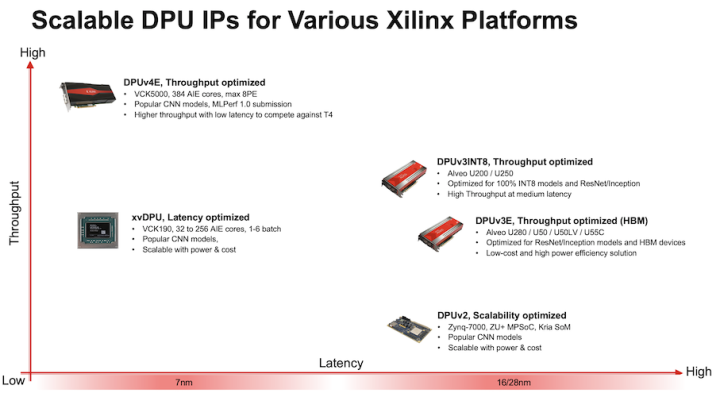
图 1. DPU 选项
DPU 命名
DPU 名称的不同字段用于表示不同的特征或作用,命名方案如下图所示:
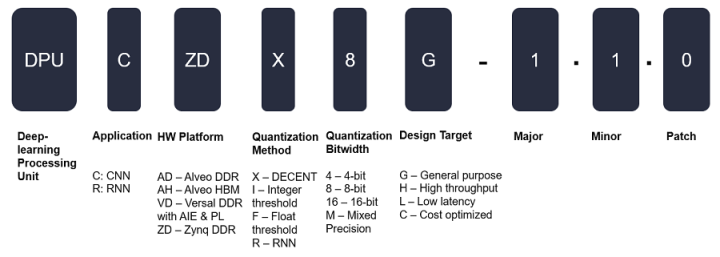
图 2. DPU 命名方案
Zynq UltraScale+ MPSoC:DPUCZDX8G
DPUCZDX8G IP 针对 Zynq UltraScale+ MPSoC 进行了最优化。您可将此 IP 作为块集成到选定的 Zynq UltraScale+ MPSoC 的可编程逻辑 (PL) 中,并直接连接到处理器系统 (PS)。DPU 可由用户配置且包含多个参数,用户可通过指定这些参数来对 PL 资源进行最优化,或者也可以自定义启用的功能。如要在自定义的 AI 工程或产品中集成 DPU,请访问 Vitis-AI/dsa/DPU-TRD at master · Xilinx/Vitis-AI · GitHub。
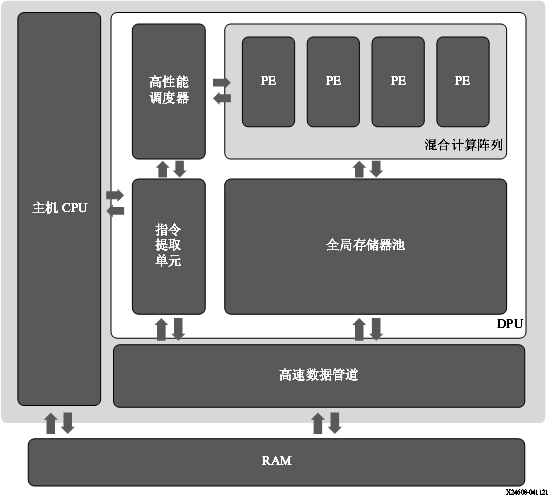
图 3. DPUCZDX8G 架构
Alveo U50LV/U55C 卡:DPUCAHX8H
赛灵思 DPUCAHX8H DPU 是专为卷积神经网络最优化的可编程引擎,主要适用于高吞吐量应用。本单元包含高性能调度器模块、混合计算阵列模块、指令提取单元模块和全局存储器池模块。DPU 使用专用指令集,从而支持诸多卷积神经网络的有效实现。其中部署的一些卷积神经网络示例包括 VGG、ResNet、GoogLeNet、YOLO、SSD、MobileNet 和 FPN。 DPU IP 可实现到选定的 Alveo 开发板的 PL 中。DPU 需要通过指令才能为输入图像、临时数据和输出数据实现神经网络和可访问的存储器位置。PL 上运行的用户定义单元也需要执行必要的配置、注入指令、服务中断和协调数据传输。 DPU 的顶层模块框图如下图所示。
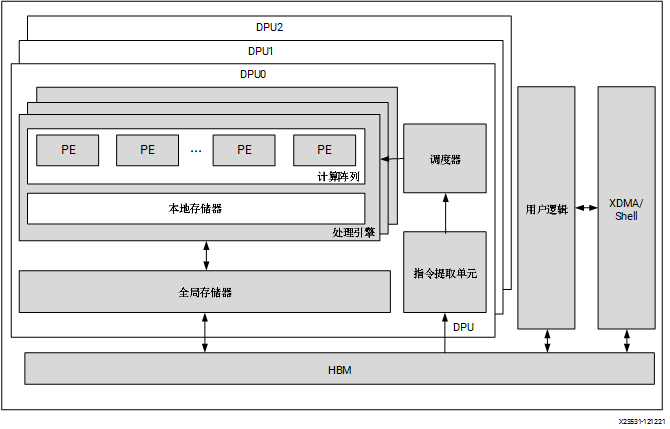
图 4. DPUCAHX8H 顶层模块框图
Alveo U200/U250 卡:DPUCADF8H
DPUCADF8H 是专为 Alveo U200/U250 卡最优化的 DPU,适用于高吞吐量应用。DPUCADF8H 的关键特征如下:
-
以吞吐量为导向的高效计算引擎:根据不同工作负载,吞吐量可改善达 1.5~2.0 倍
-
广泛的卷积神经网络支持
-
对剪枝卷积神经网络友好
-
专为高分辨率图像而最优化
顶层模块框图如下图所示:
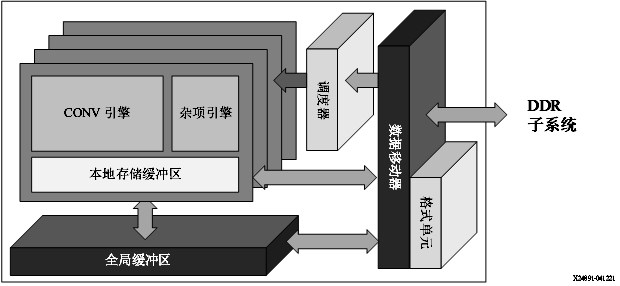
图 5. DPUCADF8H 架构
Versal AI Core 系列:DPUCVDX8G
DPUCVDX8G 是高性能通用 CNN 处理引擎,针对 Versal AI Core 系列进行了最优化。相比传统 FPGA、CPU 和 GPU,Versal 器件可提供卓越的性能/功耗比。DPUCVDX8G 由 AI 引擎 和 PL 电路组成。此 IP 可由用户配置且包含多个参数,用户可通过指定这些参数来对 AI 引擎和 PL 资源进行最优化,或者自定义功能。 DPUCVDX8G 的顶层模块框图如下图所示。
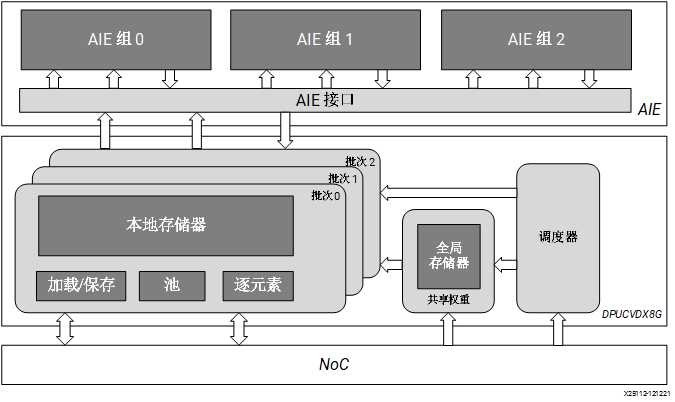
图 6. DPUCVDX8G 架构
Versal AI Core 系列:DPUCVDX8H
DPUCVDX8H 是高性能、高吞吐量通用 CNN 处理引擎,针对 Versal AI Core 系列进行了最优化。除了传统程序逻辑之外,Versal 器件还集成了高性能 AI 引擎阵列、高带宽 NoC、DDR/LPDDR 控制器和其它高速接口,与传统 FPGA、CPU 和 GPU 相比,可提供出色的性能功耗比。DPUCVDX8H 在 Versal 器件上实现,以便充分利用这些优势。您可通过配置参数来满足您的数据中心应用要求。 DPUCVDX8H 的顶层模块框图如下图所示。
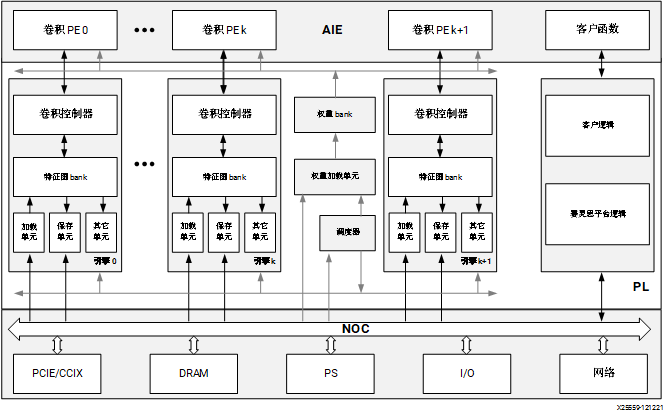
图 7. DPUCVDX8H 模块框图
Vitis AI Model Zoo
Vitis AI Model Zoo 包含经过最优化的深度学习模型,可在赛灵思平台上加速部署深度学习推断。这些模型涵盖了不同的应用,包括 ADAS/AD、视频监控机器人学和数据中心等。您可从这些经过预训练的模型开始着手,享受深度学习加速所带来的诸多利益。 如需了解更多信息,请参阅 GitHub 上的 Vitis AI Model Zoo。
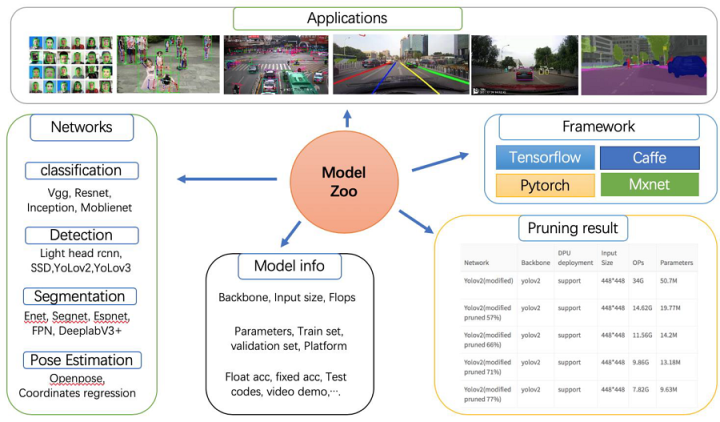
图 8. Vitis AI Model Zoo
Vitis AI 优化器
借助世界领先的模型压缩技术,您可在保证最低限度的精度降级的前提下,将模型复杂性降低 5 到 50 倍。如需了解有关 Vitis AI 优化器的信息,请参阅 Vitis AI 优化器用户指南(UG1333)。 Vitis AI 优化器需商用许可证方可运行。请与赛灵思销售代表联系以获取更多信息。
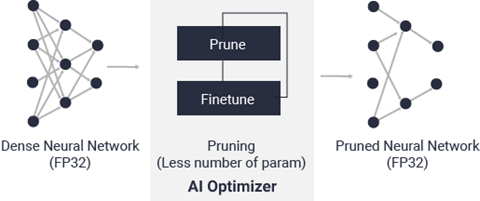
图 9. Vitis AI 优化器
Vitis AI 量化器
通过将 32 位浮点权重和激活转换为定点(如 INT8),Vitis AI 量化器可降低计算复杂性,而不会损失预测精度。定点网络模型所需存储器带宽较少,因此相比浮点模型,速度更快且能效更高。

图 10. Vitis AI 量化器
Vitis AI 编译器
Vitis AI 编译器可将 AI 模型映射到高效的指令集和数据流模型。它还可尽可能执行复杂的最优化操作,例如,层融合、指令调度和复用片上存储器。
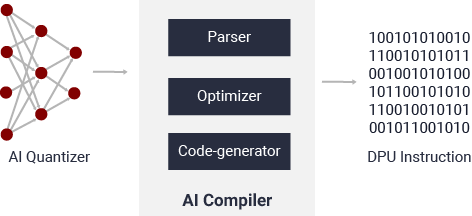
图 11. Vitis AI 编译器
Vitis AI Profiler
Vitis AI Profiler 可用于对 AI 应用进行性能剖析和可视化,以在不同器件之间查找瓶颈并分配计算资源。它使用方便且无需更改任何代码。它可追踪函数调用和运行时,也可收集硬件信息,包括 CPU、DPU 和存储器利用率。

图 12. Vitis AI Profiler
Vitis AI 库
Vitis AI 库是一组高层次库和 API,专为利用 DPU 高效执行 AI 推断而构建。它是基于 Vitis AI 运行时利用 Vitis 运行时统一 API 来构建的,能够为 XRT 提供完整支持。 Vitis AI 库通过封装诸多高效且高质量的神经网络,提供易用且统一的接口。由此可简化深度学习神经网络的使用,对于不具备深度学习或 FPGA 知识的用户也是如此。Vitis AI 库使您能够专注于开发自己的应用,而不是底层硬件。
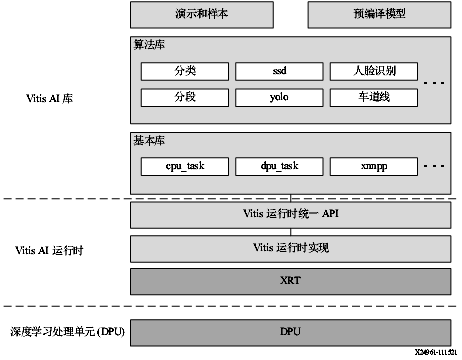
图 13. Vitis AI 库
Vitis AI 运行时
Vitis AI 运行时支持应用为云端和边缘器件使用统一的高层次运行时 API,实现无缝高效的云端到边缘部署。 AI 运行时 API 的功能如下所述:
-
向加速器异步提交作业
-
从加速器异步收集作业
-
C++ 和 Python 实现
-
支持多线程和多进程执行
Vitis AI 运行时 (VART) 是下一代运行时,适合基于 DPUCZDX8G、DPUCADF8H、DPUCAHX8H、DPUCVDX8G 和 DPUCVDX8H 的器件。
-
DPUCZDX8G 用于边缘器件,如 ZCU102 和 ZCU104 评估板以及 KV260 入门套件。
-
DPUCADX8G 和 DPUCADF8H 用于云端器件,例如 Alveo U200 和 U250 卡。
-
DPUCAHX8H 用于云端器件,例如 Alveo U50LV 和 U55C 卡。
-
DPUCVDX8G 用于 Versal 评估板,例如 VCK190 开发板。
-
DPUCVDX8H 用于 Versal ACAP VCK5000 开发板。
VART 框架如下图所示。对于此 Vitis AI 版本,VART 基于 XRT。XIR 对应赛灵思中间表示形式 (Xilinx Intermediate Representation)。
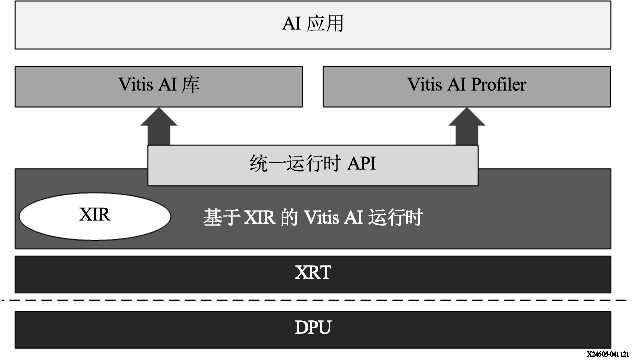
图 14. VART 栈

