
简介
记录一个项目的技术实现,主要谈这个项目的大请求的高并发处理这一块。这个项目最终通过多种技术组合,达到削峰填谷地秒级分布式计算大请求的能力,且各服务/接口间的熔断和自动恢复避免了某1个挂起的服务使得其他服务挂起的单点故障。这个项目申请了多份专利
背景
其实项目整体的技术选型本身是一次很有意思的经历,里面有太多的故事(技术访谈、技术调研、多套方案的POC、小组讨论、确认技术选型、异地出差做项目调研、跨部门确认技术选型、向各技术部门领导通报技术可行性研究、协助兄弟部门技术提升等),最有意思的是兄弟部门架构师(已离职)的一席话:这个项目已经好多波人找我调研了,其实有方案一直不能落地,希望你们能搞定!当时,我的头顶有几只乌鸦飞过……。几百人IT团队的架构师都推不动,我们能量有那么大吗。最后生产实践证明:相比之下,我们的方案更加轻快、更加流程化、更加既见既所得、且一处配置处处一致
为了控制文章的篇幅,此文只说明大请求高并发的技术实现方案
业务场景
- 在1次业务请求里:需要处理1~10+个对象。这1~10+个对象在被处理时,会共同使用同1张300~700K的图片
- 请求里的1个对象被处理的步骤:
1)获取对应的Html模板,每份模板大概70K左右
2)Html模板的velocity引擎参数替换
3)Html转PDF
4)向第三方上传PDF和图片,作电子签名
5)将签名的PDF上传到云存储平台,得到fileid
6)将签名的fileid + 由业务同事配置的印章信息,调用第三方接口,作电子印章 - 业务同事会在页面上新增、修改Html模板。换言之,模板不能是工程里的资源文件
技术说明
- 如果需要使用MQ,必须使用集团基于RocketMq封装的MQ,消息体最大支持128K
- 业务高峰时300+tps。后面测试同事反馈:压测时他们更狠,用了1w+的瞬时并发压测4台机器,依然ok
- 1次业务请求需在5秒内处理完毕并返回结果。生产数据表明:1个对象被处理的总时间基本落在300毫秒~1.5秒之间,而由于是分布式计算,因此1次请求的总耗时≈1个对象的总耗时(木桶效应:请求中最耗时的那1个对象)
- 当时这个项目所属的系统没有跑在微服务,而是跑在云主机上
换言之,这个系统的集群会run其他的业务功能
再换言之,不能因为这个高并发的项目让集群里的机器瘫痪,影响到其它同样重要的业务逻辑的运行
方案
服务 = 请求持久化 + 分布式计算 + MQ异步通知实现
请求持久化
示意图
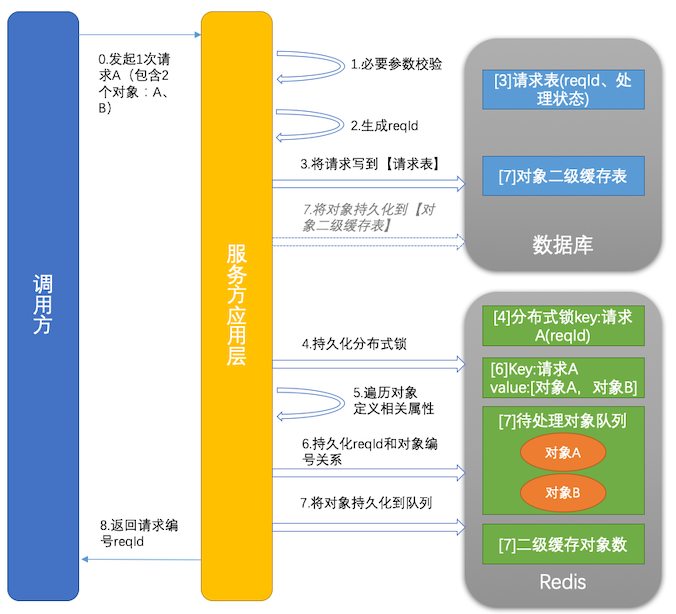
说明
- 流程说明(为避免并发因素,下文的执行顺序不能调换):
- 对请求A里的对象A、B做必要性的参数检查。检验失败立马返回错误信息
- 在分布式环境下生成唯一的请求编号reqId。参见之前写的一篇文章: 分布式UUID的生成
- 将当前请求信息(主要是reqId、请求的初始处理状态)写入Oracle
- 在Redis中记录基于reqId的分布式锁,控制后面多实例间的并发。hset-->reqId(key):1(value)
- 分别给对象A、B定义3个核心属性:
1)当前对象所属请求的reqId
2)分布式环境下唯一的对象编号。生成编号的方法和生成reqId的一致
3)对象持久化的时间(当前时间) - 通过上一步,得到reqId和所有对象编号的对应关系,将对应关系持久化到Redis中。hset-->reqId(key):List(value)
- 将对象A、B(含图片)持久化到Redis队列中,或则数据库中。说明:
- 配置Redis的Queue深度为2000(可动态调整)
- 若发现队列满了,则将当前对象持久化到Oracle中作二级缓存,并在Redis中累加二级缓存的对象数: redis.incrby("SL_CACHE_CNT",1);
- 若Redis记录的二级缓存对象数大于0:后续请求的对象直接写Oracle,确保Redis队列和Oracle二级缓存队列保持顺序的一致性
- 若发现队列未满且二级缓存对象数等于0或为空,则将当前对象持久化到Redis的Queue中
- 给调用方返回reqId
其他说明:
Redis读的速度是11万次/s,写的速度是8.1万次/s。每1次写的速度小于0.0125毫秒,如果把应用层和Redis之间的网络消耗算在内,最大应该是1个毫秒级。如果1次请求有10个对象的持久化,最大也就是10个毫秒左右。加上Oracle的1次请求(不是请求里的对象)的持久化时间,整个持久化时间大概20~50ms左右,调用方可以快速得到reqId
分布式计算、MQ通知
示意图
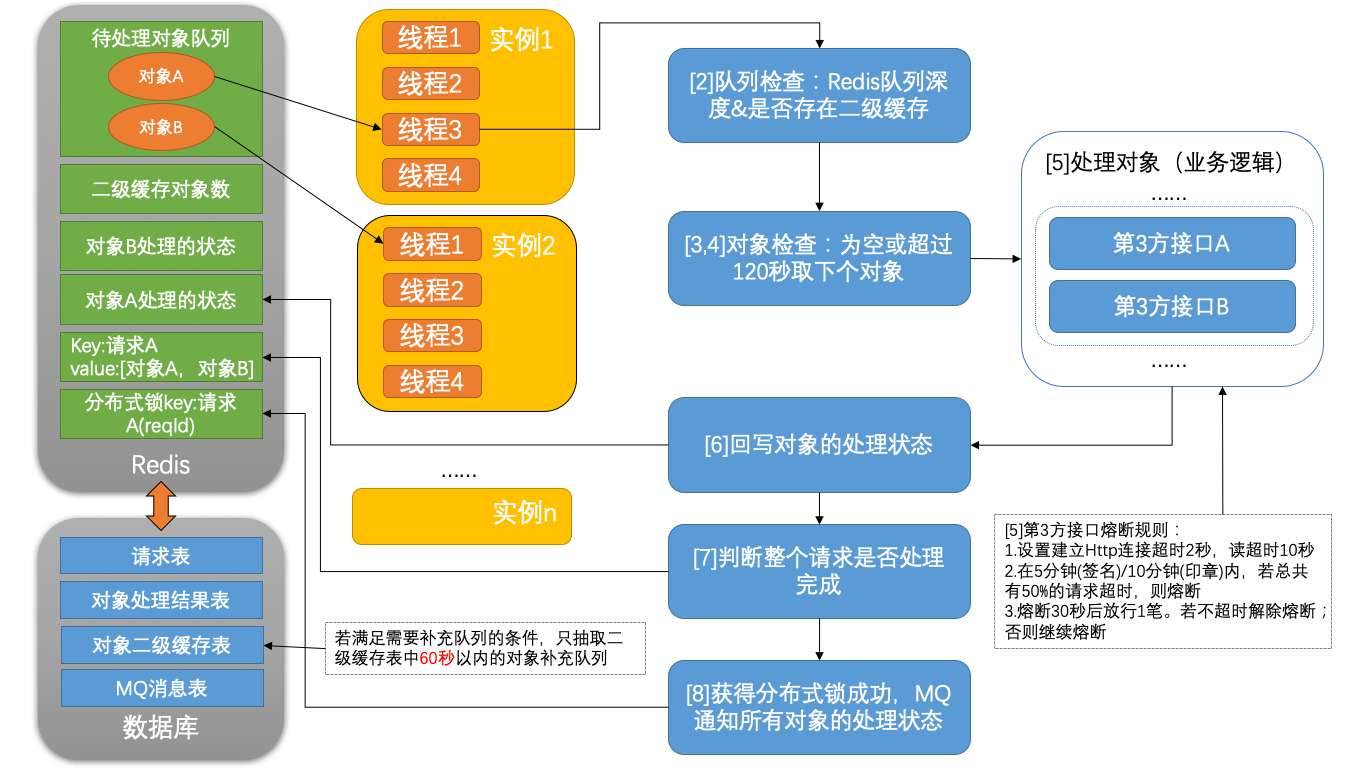
说明
- 流程说明:
- 集群里的每台实例开启4个无限循环的线程。下面的步骤都是在其中1个线程中执行
- 当前线程判断是否需要将二级缓存的对象补充到Redis队列(补充队列时,需控制并发,避免重复载入二级缓存)。判断依据:
1) 队列深度小于50%
2) 二级缓存对象数大于0 - 从Redis队列中pop的对象若为空,睡300毫秒后,再继续从第2步开始
- 和当前时间比较,若pop出来的当前对象的对象持久化的时间已经超过120秒了,则立马跳到第2步开始
- 处理对象(执行上文提到的业务逻辑,每家公司业务逻辑不一样,不赘述业务逻辑实现)。这一步涉及熔断,在标准web应用中通过AOP实现了一版,切换到微服务后,利用Hystrix组件实现了熔断。这两版虽然是不同的实现,但是控制逻辑一致,示意图中对熔断逻辑做了说明
- 将当前对象的处理结果(Map),回写到Redis中。hset-->对象编号(key):处理结果(value)
- 通过当前对象绑定的reqId,从Redis中取得reqId和所有对象编号的对应关系,在Redis中陆续查询每个对象编号的处理结果(Map)。若某个对象编号没有处理结果,表示该对象处理中或则没有处理,则跳到第2步开始
- 当前请求的所有对象处理完成后,就可以将所有对象的处理结果(Map)封装成MQ,异步通知调用方。同1个请求的不同对象,可能会被不同实例的线程处理,因此只能让一个线程获得上文提到的基于reqId的分布式锁来发送MQ消息,方法:若某1个线程执行redis.del(reqId)的返回值大于0,则获取到分布式锁
其他说明:
1)上面流程除了Redis的操作以外,还有数据库数据的同步,这里没有细写,只是在图中将实体表名标了一下
2)上文提到的Html模板,需要缓存在内存中提高速度:通过业务唯一键缓存在ConcurrentHashMap中,基本上O(1)的时间复杂度就能获取到模板。实例的4G内存中的2G来存储模板,可以存储2w+份完全不同的模板,足矣项目性能方面可优化的方向
1)数据持久层的调整,避免高吞吐带来的数据库写性能下降
2)项目中有很多配置都缓存到了内存中,大多数都是增量式的更新缓存。但Html模板缓存的逻辑不是这样的,模板其实也可以做成增量式更新
FAQ
汇总一下之前小伙伴的疑问:
分别对1次业务请求的n个对象,发起n次请求?
不行。1次请求拆成n次Http请求调用,每次调用又带着300~700K的图片的话,在高并发下,千兆网卡可能吃不消(何况很多实例都是虚拟化的,多台实例共用同1台物理机器,多台实例共用同1张网卡,更会加重这种影响)。我的猜想没有错:有一次UIOC事件(其他兄弟的另1个项目)就是因为并发过高,网卡挂起,网卡间断性地发送网络请求
用MQ的方式通知集群处理业务请求?
不行。 集团的1条MQ消息,容量最大是128K,而请求中的图片就有300~600K
同步接口来处理业务请求?
不行。1个对象的处理时间若是1.5秒,1个请求的10个对象的处理时间会是15秒,超出了1次请求5秒内得到结果的要求
同步接口 + ExecutorService线程池并行处理业务请求里的各个对象?
不行。主要是两个方面:
1)由于涉及PDF流的运算,会消耗大量内存,为了不影响其他的业务逻辑的运行,必须限定线程池的个数和队列深度。若不限定,持续性的大量图片会存储在内存中,很快会OOM
2)在高并发下,线程数和队列深度如果一旦限定,有些请求因达到线程池的限制会被直接拒绝。同时,同1次请求的10+左右的对象,可能会分成m批被处理(m=10/线程数),若每批运行时间是1.5秒,会有超过整个请求的处理时间在5秒内的限制的可能这个项目为什么一定要用异步接口呢?
作为服务方,尽量不成为公司整个业务流程的性能瓶颈节点。 调用方与服务方的网络连接越快结束越好,避免服务方运算速度变慢(比如YGC、OGC、FGC、系统中其他耗性能的功能running中等),而导致调用方HTTP连接的等待,如果此时调用方没有配置超时时间,会发生灾难性的贯穿性的雪崩效应。同时鉴于单个对象的处理链条长,PDF流运算较耗性能,如果几千个对象同时以同步接口调用在服务方,服务方必然会资源耗尽。所以这个项目更适合通过异步队列的形式,削峰填谷
不考虑用MongoDB来替代Oracle的写操作?
有考虑过,不过这个项目所属的系统没有MongoDB,需要预算审批。如果替代,会有好处:
1)减轻Oracle的写压力
2)由于MongoDB磁盘以bson存储,易于快速扩展字段
3)通过MongoDB优秀的写性能,可以减少单个对象的处理时间
由于1次请求整体响应时间在1秒左右,已经达到5秒内的要求,性能过得去,所以没有申请这笔预算为什么不直接将对象持久化到Redis中,而要用数据库做二级缓存呢?
主要是担心海量并发时,Redis的队列深度不控制,会将Redis撑爆。当时为了Redis的读速度,每个对象持久化到Redis时会带上这张300~700K的图片。如果1个请求有10个对象,则会存7M,48G的Redis总共存储7021个请求,若按照300tps且消费Redis队列过慢话,最快23秒就会将Redis爆掉。因此,队列深度是2000的话,最大占用Redis容量是1.3G=2000*700/1024/1024
为什么每台实例只开启4个线程?
当时测试环境压测的主要的环境指标:申请和生产环境同样的CPU和内存,每次压测时被处理对象是一样的。线程数从1配置到10,主要考核2个核心指标:每秒处理的对象数、每个对象处理的耗时。不难看出这2个指标是互为倒数关系,数学上分别是直线和双曲线,他们一定在第一象限有个交点,这个交点就是4,4个线程时这两个指标是最好的。其实也不难理解,在内存足够的情况下,影响线程性能的就是CPU,而服务器的CPU是四核的,每个核处理1个用户线程是最佳的
为什么Redis队列里的对象超过120秒后丢弃?二级缓存只取60秒内的数据?
1)文中提到的各种阈值,它们之间是有联系的,是通过计算得到的。比如:这里的60、120:队列深度(2000)低于50%时,取1000个对象补充等;由于每个对象120秒后会被丢弃,所以只用取60秒内的二级缓存数据;当然这些阈值和集群中的实例数有关。因每家公司集群环境不一样,阈值配置的具体值不深入讨论
2) 对象之所以要有过期时间而被丢弃,主要目的:当数据积压发生时(队列生产者的生产的速度比消费者消费的速度快),避免最新的请求迟迟得不到消费
3) 生产事件:截止到2019.06,第2)条的情况生产环境一共出现3次,第1次出现这个情况时没有这个特性,运维同事又迟迟没有生成环境的Redis操作权限,也不敢flush数据导致加重了业务影响----集群一直消费很早之前(半小时、1个小时之前)的请求。其实这个超时丢弃的特性早已规划并计划上线(项目分几期上线的),只不过计划赶不上变化。第2、3次出现这个情况时,因为有了这个特性,集群进行了自我修复,基本无感知。至于这3次情况产生的根源性原因各不相同,都不是因我们的服务自身而引起的,虽不是我们的锅,但毕竟我们可以做到更好,减轻别人黑锅对我们的影响,你说呢?丢弃的对象后面会补偿处理吗?
不会,业务上不需要。调用我们服务的属于App交互类的请求,接口上保持幂等性即可
扩展:如果你的项目是交易类的,需要保证最终的一致性,可以做一些变形:请求持久化入库时,将全量参数一起入库;如果当前请求的所有对象处理成功,当把请求的处理状态改成成功时,同时将之前保存的全量参数置空(减轻存储数据量的压力);如果请求中某个对象失败了,导致整体请求的处理状态失败,后面跑批取出失败状态的请求,只将那1个失败的对象重新补偿处理即可(可以再往Redis队列中扔,不过这个跑批尽量在晚间执行,避免正常业务请求的阻塞)1个线程做这么多事?为啥不把流程中每个功能节点做成独立的线程池管理?
这涉及到服务粒度划分的问题。主要是2个方面:
1)电子签名、电子印章不是必须的业务节点:有时只需要签名,不需要盖章。如果这样划分,线程会从无状态变成有状态。实例数是有限的,也就是说线程数是有限的,如果将部分线程划分给1个服务,不做当前业务流程的其他节点的功能,势必会出现“旱的旱死涝旳涝死”的情况-->资源得不到充分利用
2)此项目的业务流程节点之间,涉及到PDF流文件,如果拆成多个更细的服务,光文件流的上传下载就会消耗大量时间,性能损耗太过严重

