
- 1理解Android编译命令_msm8916系统编译
- 2java中String xx xx_Java中常用String方法
- 3TCP原理和三次握手和四次挥手过程_tcpip的三次握手的原理和过程
- 4android通过包名打开指定应用程序,android 通过包名启动其他app并打开指定的页面...
- 5YOLO Nano:一种高度紧凑的只看一次的卷积神经网络用于目标检测
- 6软件开发技术文档编写规范_软件使用手册编写规范
- 7Python实现学生信息管理系统_利用python语言中的组合数据类型对学号和姓名进行存储,并实现利用学号访问姓名和
- 8Linux进程间通信有哪些方式,优缺点如何_比较linux系统中pipe、clone、shm和msg四种高级通讯方法的优缺点以及各自适应的环
- 9全球最大的 ChatGPT 开源替代品来了,支持 35 种语言,网友:不用费心买 ChatGPT Plus了!_海外openai chatgpt的替代品
- 10C实现WebSocket服务端与订阅端以及HTML5的WebSocket_ccgi websocket
百度EMNLP 2020精选论文解读_dusql 数据集、
赞
踩

欢迎关注【百度NLP】官方公众号,及时获取自然语言处理领域核心技术干货!!
阅读原文:https://mp.weixin.qq.com/s/rBEk6A2B96pDFBHQcJ6wyg
EMNLP是自然语言处理领域的顶级会议之一,2020年的EMNLP会议已于11月16日至20日召开。百度精选了7篇录取的论文为大家进行介绍。
论文一:
句法和语义驱动的开放域信息抽取
Syntactic and Semantic-driven Learning for Open Information Extraction
论文链接:
https://www.aclweb.org/anthology/2020.findings-emnlp.69.pdf
开放域信息抽取(Open IE)旨在从大规模自由文本中提取开放的多元组。相比传统的信息抽取,此任务的特点是与领域无关而且不需要预先设定关系模板。虽然此任务受到越来越多的关注,但是由于难以获取大规模人工标注数据,构建准确且高覆盖的开放域信息抽取系统依然困难重重。
为了缓解对人工标注数据的依赖,本文提出一种句法和语义驱动的学习算法,通过利用句法和语义作为监督信号,实现无监督的开放域信息抽取。图1展示了我们方法的整体流程。首先,我们利用句法模板作为标注函数,自动挖掘三元组并构建标注语料,从而训练基础的开放域信息抽取模型。其次,由于自动构建的标注语料通常带有噪声而且覆盖不足,导致基础模型的覆盖能力有限,因此有必要对基础模型进行优化并提升泛化能力。为此,我们进一步提出基于句法和语义的增强学习。我们利用句法规则的约束以及预训练的语义模型,对自动抽取结果的质量进行衡量,然后通过增强学习不断训练优化基础模型的效果,从而获得的覆盖率和准确率更好的模型。
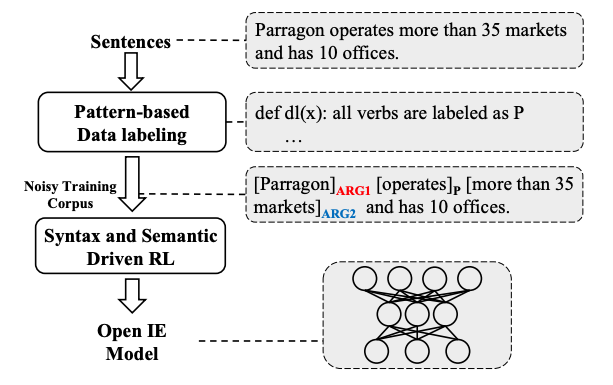
图1 句法与语义驱动的OpenIE方法示意图
我们在三个公开数据集上进行对比实验,包括 OIE 2016、WEB和NYT。表1展示了主要的实验结果。从表格中可以发现,在使用相同的抽取模型时,我们提出的无监督训练方法 RnnOIE-Full比有监督方法RnnOIE-Supervised(BERT)效果更好。并且,RnnOIE-Full与SOTA的有监督方法RankAware相当。同时,基于句法和语义的增强学习能有效的提升基础模型的效果(RnnOIE-Full vs. RnnOIE-Base),充分说明我们提出方法的有效性。
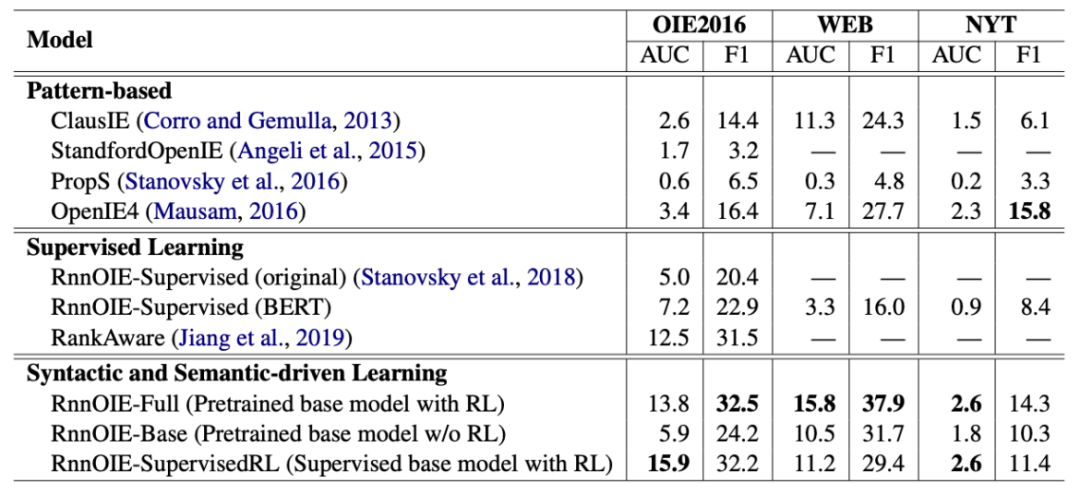
表1 主要实验结果
论文二:
同声翻译的自适应分割策略
Learning Adaptive Segmentation Policy for Simultaneous Translation
论文链接:
https://www.aclweb.org/anthology/2020.emnlp-main.178.pdf
近年来,同声传译越来越受到研究界和业界的关注。它的目标是实时翻译,要求翻译质量高,且语音和翻译输出之间的延迟尽可能短。平衡准确度和延迟是同声翻译的一大挑战。为了获得较高的准确率,模型通常会等待收到较长的流式文本才开始翻译,这就会导致延迟增加。可是反之,要追求较低延时,就可能会损害翻译结果的准确性。因此,系统需要定义一个策略来决定,当收到一定长度的语音识别结果后,是进行翻译,还是继续等待。
已有工作可分为两种方法。一种是固定策略,如每收到个字就进行一次翻译,但这种方法不考虑上下文信息,容易造成翻译效果下降。另一种自适应策略根据上下文确定是否将当前内容送去翻译,但已有自适应方法需要将策略和翻译模型联合训练,训练过程复杂。
本研究在人工翻译的启发下,提出通过考虑翻译模型可能产生的翻译来学习对源文本进行分割,保持分割和翻译之间的一致性。同传系统整体流程如下图所示。
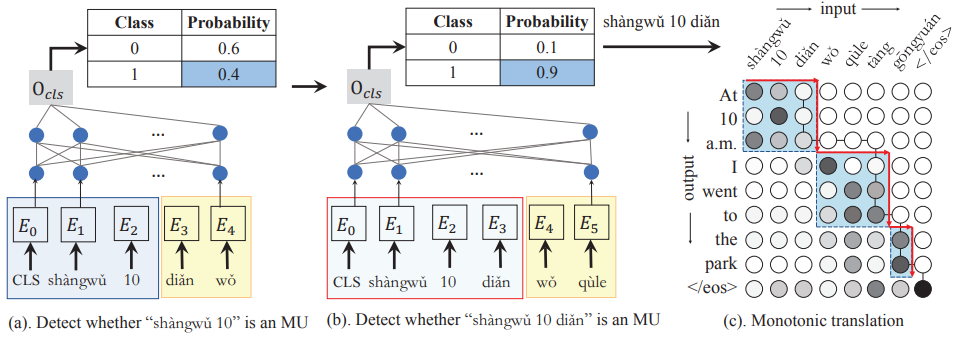
图 2
图2(a)随着系统收到语音识别后的文本,参考两个未来词(黄色框),通过一个分类模型来检测,当前片段(蓝色框)是否构成一个语义单元。类1表示是语义单元。
如果类1的概率大于一个阈值(如图2(b)所示),则将这个片段切分出来并送入翻译模型产生翻译结果(如图2(c)所示)。只要一个片段被检测为语义单元并进行翻译,其翻译结果就不再变动,而在后文的翻译中,采用强制解码策略生成已有语义单元的翻译结果。
本研究提出基于语义单元的同声传译,并根据同传的两个目标:①准确翻译 ②低延时,定义语义单元为翻译结果不会随后文而变化的最短片段, 据此提出了两种自动从源语言单语语料库中抽取语义单元训练数据的方法。一旦有了训练数据,我们便可以通过训练一个分类模型进行语义单元的实时检测。
我们首先提出一个基本方法,根据一个机器翻译模型来抽取语义单元。根据其定义,我们从左到右依次判断一个源语言句子的前个字的翻译结果是否是整句翻译的一个前缀。如果是,则将的前个字作为一个语义单元。这是因为,如果是的前缀,说明的翻译结果不会随后文而变化;而从左到右地筛选,可以保证筛选出来的语义单元最短。
此外,针对某些样本的翻译结果存在长距离调序(如下图中的“基本方法”),导致抽取出来的语义单元过长的问题,我们提出了一个优化方法(如下图“优化方法”),通过产生顺序翻译结果,尽量避免长距离调序,从而得到较短的语义单元。
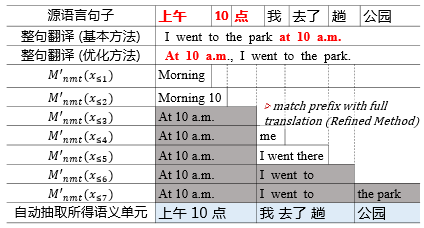
图 3
为了产生顺序翻译结果,本研究提出了一个前缀注意力机制。通过自动判断前缀翻译的注意力是否落在当前前缀的源端边缘来判断当前产生的目标词是否可信。如果当前词可信,便将该生成词予以保留并不断尝试用最少的源语言句子前缀生成下一个目标词。为保证翻译质量,本文中保留那些高置信度的顺序翻译样本,以训练一个顺句翻译的机器翻译模型。最终,我们用这个机器翻译模型来抽取语义单元。
实验结果表明,我们的方法在延迟和翻译效果的平衡方面取得了更好的效果。如下图所示,MU和MU++分别表示本文提出的基于语义单元的基本方法和优化方法。在相同的平均延迟(Average lagging)下,我们的方法可以达到更好的翻译效果(BLEU)。
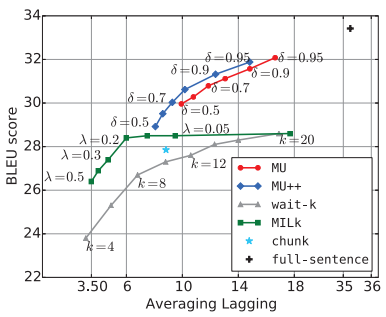
图 4
论文三:
DuSQL:实用的大规模中文文本转结构化查询语句数据集
DuSQL: A Large-Scale and Pragmatic Chinese Text-to-SQL Dataset
论文链接:
https://www.aclweb.org/anthology/2020.emnlp-main.562.pdf
Text-to-SQL任务旨在将自然语言问题转成可在数据库上执行的SQL查询语句。该任务是面向数据库问答的核心技术,能够帮助用户从数据库中获取信息。由于缺乏标注数据,现有的文本转结构化查询语句(text-to-SQL)任务研究主要集中在英文上。代表性的英文数据集包括ATIS,WikiSQL,Spider等。
本文提出了一个实用的大规模中文跨领域text-to-SQL数据集DuSQL,其包含200个数据库,813个表格和23797个问句/SQL 对。DuSQL数据集有三个特点。
首先,经过对多个代表性应用场景中问题的人工分析,我们尝试给出现实需求中SQL的真实分布,见图5。
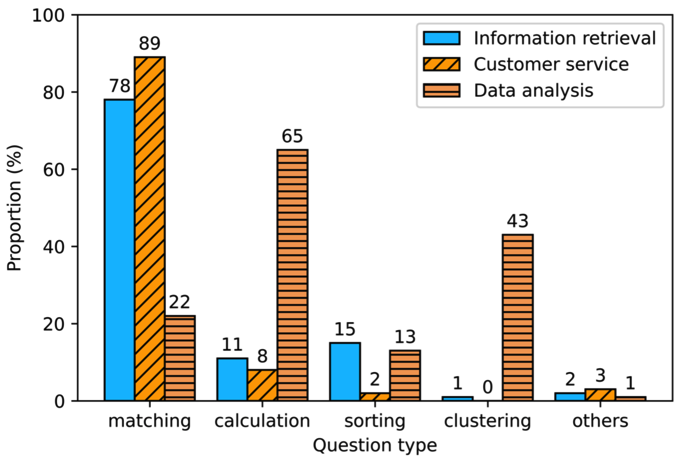
图 5
第二,基于得到的SQL分布,我们构建了 DuSQL数据集。该数据集的SQL查询语句分布贴近于真实应用中的SQL语句分布,其包含了大量涉及行列计算的SQL语句,是一个比较实用的数据集。
最后,我们采用了一种有效的人机协作数据构建框架。基本思想是基于SQL语法和给定的数据库自动生成SQL语句和对应的伪自然语言问题。由标注者对伪自然语言问题进行人工改写,过滤掉不自然及不可理解的问题。为了保证数据质量,我们采用两个自动评估指标对标注的数据进行评估,并对低质数据进行迭代标注。
最终,我们构建了DuSQL数据集,其与现有数据集对比见表2。
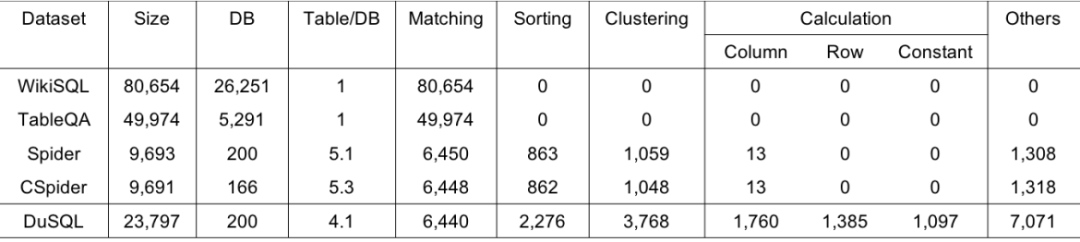
表 2
另外,我们对多个开源的text-to-SQL解析器进行了微小的修改以适应中文,其中包括基于IRNet对计算类问题简单而有效的扩展(IRNetExt)。各解析器结果表明DuSQL是一个很有挑战的数据集。同时,我们给出了各问题类型的准确率,见表3。计算类问题解析准确率偏低,主要是该类问题的解答依赖常识,如“生卒年龄=死亡日期-出生日期”,如何表示及将这些常识融入模型是一个难题。

表 3
论文四:
用于文档级多方面情感分类的多元化多实例学习
Diversified Multiple Instance Learning for Document-Level Multi-Aspect Sentiment Classification
论文链接:
https://www.aclweb.org/anthology/2020.emnlp-main.570.pdf
以往基于神经网络的文档级多方面情感分类通常需要大量地人工标注方面级的情感标签,需要消耗较大的人力财力。而文档级的情感标签却可以从网络上大量的获取,比如来自购物网站等,因此使用这种免费的文档级情感标签来训练神经网络是很有价值的。为此,我们提出了一种多元化多实例学习网络(D-MILN),该网络能够仅通过文档级的弱监督实现方面级情感分析器的训练。
具体而言,我们通过多实例学习来连接方面级和文档级的情感,从而提供了一种从文档级监督的反向传播中学习方面级情感分类器的方法。
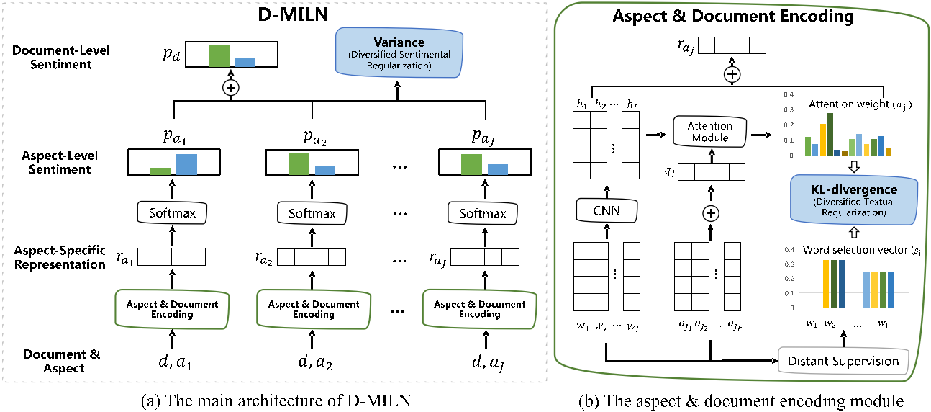
图 6
如图6 (a) 所示,对于一篇文档和文中涉及的多个方面,首先通过基于注意力机制的方面级情感分类器,得到每个方面的情感分布,然后将多个方面的情感分布加权得到文档的情感分布,通过优化文档级的情感分类损失,对方面级的情感分类器进行训练。
但是,通过这种方式得到的方面级情感分类器,会过度拟合文档级的情感,并且无法很好地感知给定方面的信息,最终导致以下两种过拟合现象:1)分类器无法定位到与给定方面相关的文字,2)对于不同的方面,分类器倾向于都预测为与文档一致的情感。以图7为例,无论给定的方面是哪个,分类器都倾向于关注“great”、“ordinary”、“small”、“minimum”、“expensive”等表达情感的词,并且预测出负向情感。

图 7
为了解决对文档情感的过拟合问题,本文同时提出了两种多样性正则。如图6(b)所示,文本多样性正则中,首先通过远监督获得与每个方面相关的文字,然后约束情感分类器计算得到的注意力向量更加关注于这些文字。如图6(a)所示,情感多样性正则作用于文档中方面的情感分布,通过最大化这些分布的方差,达到防止方面级的情感与文档情感过度一致的问题。
本文提出的方法在两个benchmark数据集上,超过了之前的弱监督方法以及一些基于多实例学习的模型,同时接近有监督方法在每个方面给定2000个情感标签时的效果。
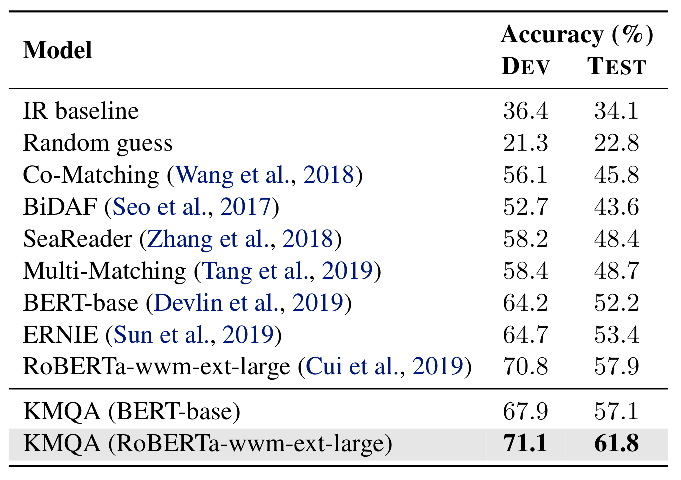
表 4
论文五:
一种面向开放领域信息表示的自然语言上的谓词-函数-参数标注方法
A Predicate-Function-Argument Annotation of Natural Language for Open-Domain Information eXpression
论文链接:
https://www.aclweb.org/anthology/2020.emnlp-main.167.pdf
知识和推理是人工智能发展的下一个阶段。然而,知识的抽取和知识库的建立是一个经典的难题。语言是蕴含知识最丰富的载体,但是语言和知识的鸿沟非常的巨大。目前仅有极小的一部分文本所蕴含的知识被形式化的知识库所蕴含。开放信息抽取(Open Information Extraction, OIE)是建立语言和知识的桥梁的一种途径。但是在实践中,开放信息抽取系统均是各自针对不同应用独立构造的(如图8所示)。这导致:1)大量重复工作;2)抽取策略不可重用;3)无法迁移到新的应用场景。
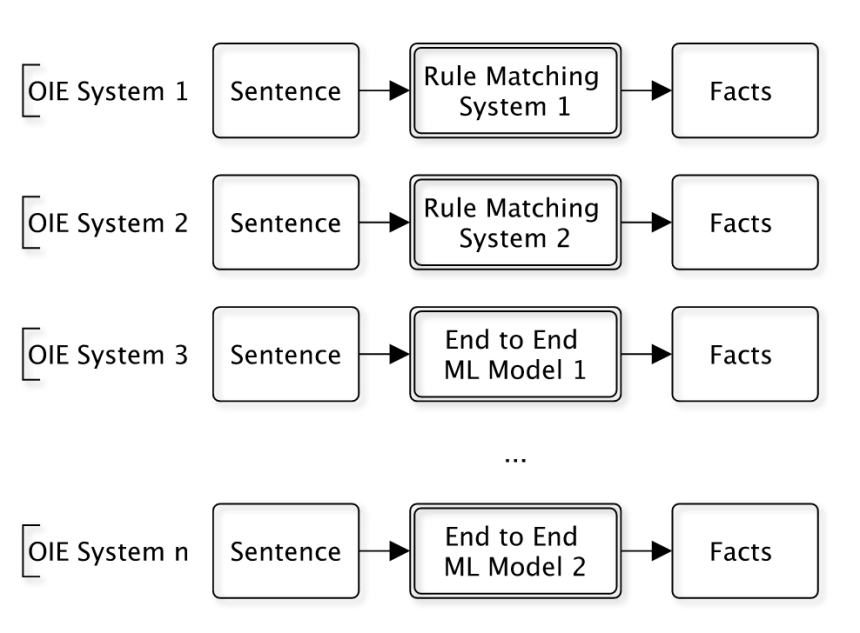
图 8
在该论文里,我们提出了一种通用可迁移的OIE系统构造方法论(如图9所示)。这种方法基于一个新的任务:开放信息表示(Open Information eXpression, OIX)。开放信息表示试图将自然语言句子的所有信息表示成为事实和事实之间的关系,而不是像OIE那样只关心部分感兴趣的事实。我们设计了一种OIX 的实现方式,一种称为开放信息标注(Open Information Annotation,OIA)的有向无环图(如图10所示)。OIA实现了OIE系统的基础公共操作。面向特定任务的OIE系统,可以在OIA上实现具体的策略。由于这些策略都是在OIA图上进行的,因此可以迁移到新的任务领域,通过组合策略便可得到一个新的OIE系统。
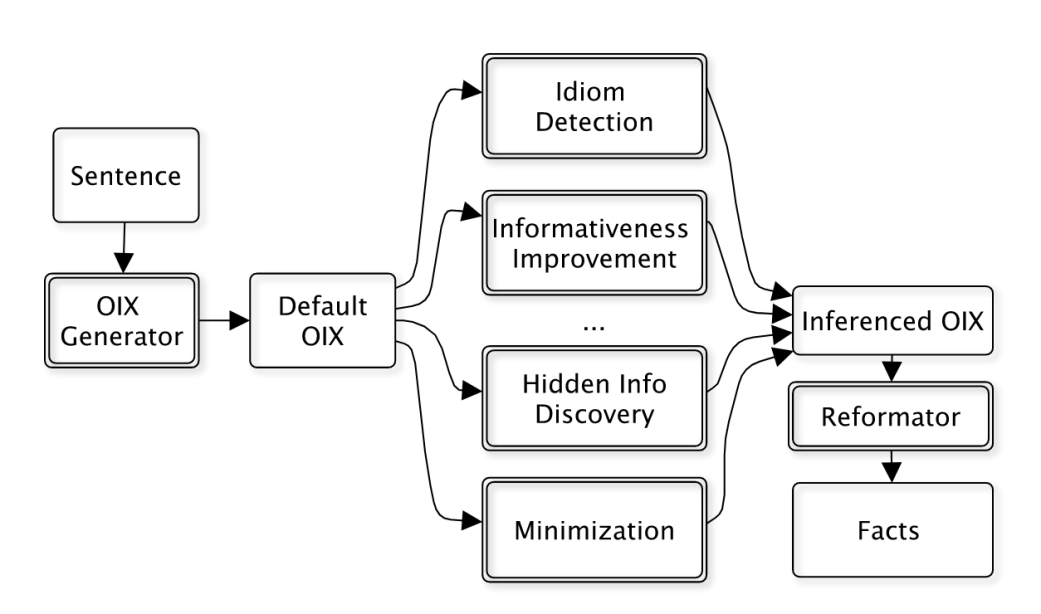
图 9
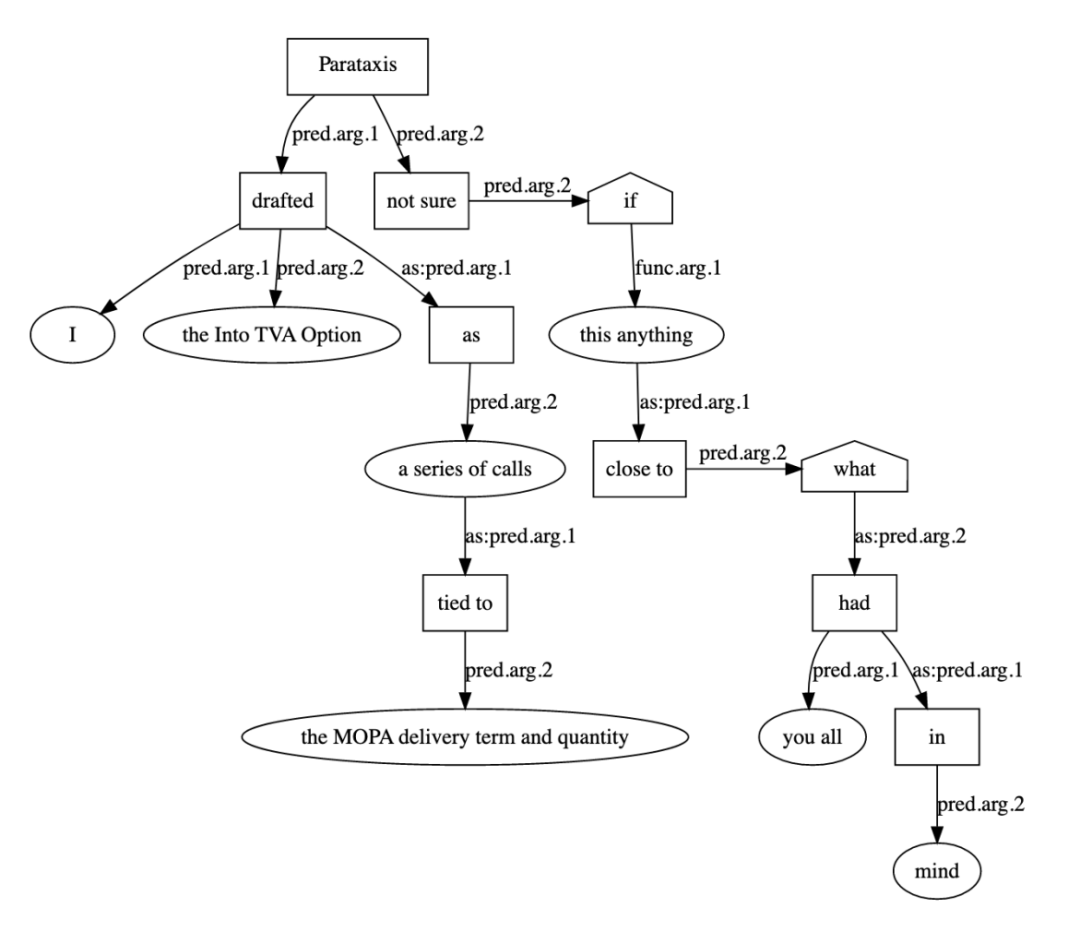
图 10
我们标注了一个句子和其OIA图的数据集,并构造了一个基础的将句子转换成为OIA图的转换器。数据集和转换器均已向开放社区公布。
OIE这个领域一直是一个自由而蛮荒的领域。该论文提出的OIX任务和OIA表示方式,将这个领域变成了一个目标明确,可以监督学习,可以公平评估的科学领域。对于持续不断地从语言文本中提取知识,是一个重要的基础贡献。
论文六:
融合结构化知识与文本的医学机器阅读理解
Towards Medical Machine Reading Comprehension with Structural Knowledge and Plain Text
论文链接:https://www.aclweb.org/anthology/2020.emnlp-main.111.pdf
随着大规模预训练模型的兴起与发展,机器阅读理解方法近些年在开放域已经取得了显著的效果提升。然而,在面向特定领域(如医学领域),由于对领域知识理解的不足以及领域训练数据的匮乏,机器阅读理解方法的表现不尽如人意。
为了解决面向领域(医学领域)机器阅读理解方法效果欠佳的问题,我们研究如何利用专业知识来增强医学领域阅读理解方法能力,特别是医学复杂推理能力。同时,为了更好地推进这项研究,我们构建了近年来中国国家执业药师资格考试(2018年的通过率不到14.2%)中收集的多项选择问答数据集(2015年-2019年,五选项单选题)。该数据集在概念知识、数学判断和逻辑推理方面具有挑战性,并且具有广泛的实用价值。一个具有挑战性的例子(见图11):

图 11 一个执业药师考试选择题的例子
(√:正确答案选项)
我们看到解析里提到:临床用于抗乙型肝炎病毒的药物有哪些,并且还需要判断是否是首选药物。这涉及到依赖医学专业知识进行推理判断,而用传统的阅读理解模型是难以解决此类问题。
作为一种尝试,我们提出了一种基于预训练语言模型和协同注意力机制架构的模块化端到端阅读理解模型。为了更好地整合知识图谱中的信息,我们设计了一种知识获取算法来收集相关事实并将知识注入神经网络。在此基础上,我们提出了阅读理解模型KMQA(incorporates Knowledge graphs facts for Medical multi-choice Question Answering),该模型可以充分利用结构化医学知识(采用基于北大等单位发布的CMeKG作为中文医学知识图谱)和参考医学文本(即从药学参考书中检索到的文本片段)。
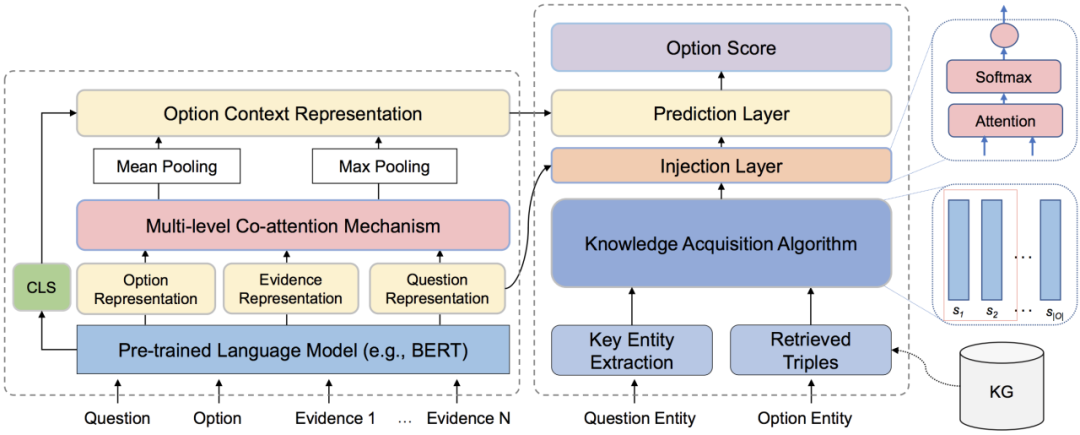
图 12 KMQA整体架构
多层协同注意力阅读器(左)和知识集成模块(右)
如图12所示,它主要由几个模块组成:(a)多层协同注意力阅读器,用于计算问题,选项和检索文本的上下文感知表示形式,并实现了丰富的交互。(b)知识获取,根据给定的问题和选择从 KG 中提取知识事实(见图13)。(c)将知识事实进一步整合到阅读器中的注入层,以及(d)输出最终答案的预测层。而且,我们利用问题到选项路径的关系结构来进一步增强KMQA的性能。

图 13 知识获取算法
实验结果表明,KMQA在性能上优于现有的竞争模型,在测试集上的正确率达到61.8%。
表 5 测试集结果对比
论文七:
提升双语字典生成中的低频词准确率
Improving Bilingual Lexicon Induction for Low Frequency Words
论文链接:
https://www.aclweb.org/anthology/2020.emnlp-main.100.pdf
“双语字典生成”(BLI)是一个从少量翻译词归纳出更多翻译词的过程,对于研究多语种词向量空间的表达,以及机器翻译有重要意义。图14演示了目前流行的做法:
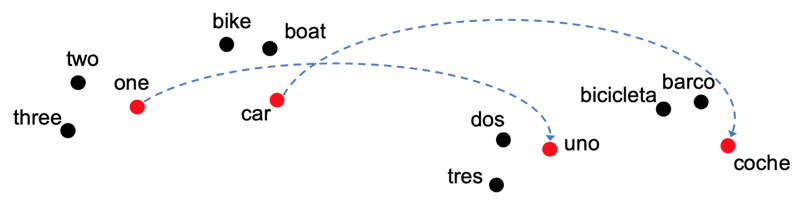
图 14 双语词向量空间和BLI的代表性方法
左边和右边的点分别代表英语和西班牙语词向量空间,箭头代表少量已知的翻译对。方法一般是两步:
-
从已知的翻译出发,解一个 procrustes 问题,得到一个旋转矩阵。该矩阵将左边的点旋转对齐到了右边;
-
两个空间对齐后,用最近邻搜索发掘更多的翻译对。
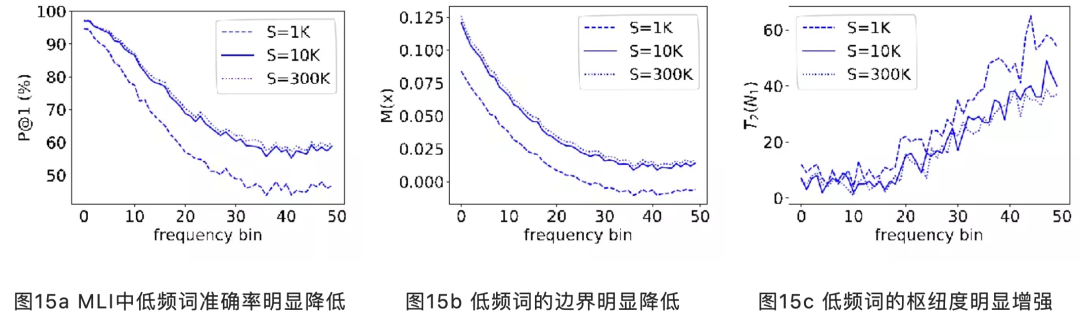
本文首先提出了一种全新的“单语词典生成”(MLI)的探针任务,该任务只涉及单一语言的两个词向量空间,目标是学出词到词本身的一一对应。MLI简化了BLI中的一到多或者多到一的问题,从而更能体现低频词的难点。对 MLI运行以上方法发现翻译准确率随词频降低而明显降低(图15a)。
对此,我们提出了两个统计量来解释该现象:边界度和枢纽度。边界度反映了正确和错误的翻译分的有多开,越大越好。枢纽度则是高维向量空间的固有特点,表现为某些点和其他所有点都很近,因此对最近邻搜索有害,越低越好。图15b、15c分别演示了这两个量在不同词频区间上的变化,它们在低频词区间都变差了。
基于以上发现,文章进一步提出了两种方法,来提升低频词典生成的准确率:
-
大边界度训练(得到更强的旋转矩阵);
-
低枢纽度最近邻搜索(通过正则化减少枢纽度,代码链接https://github.com/baidu-research/HNN)。
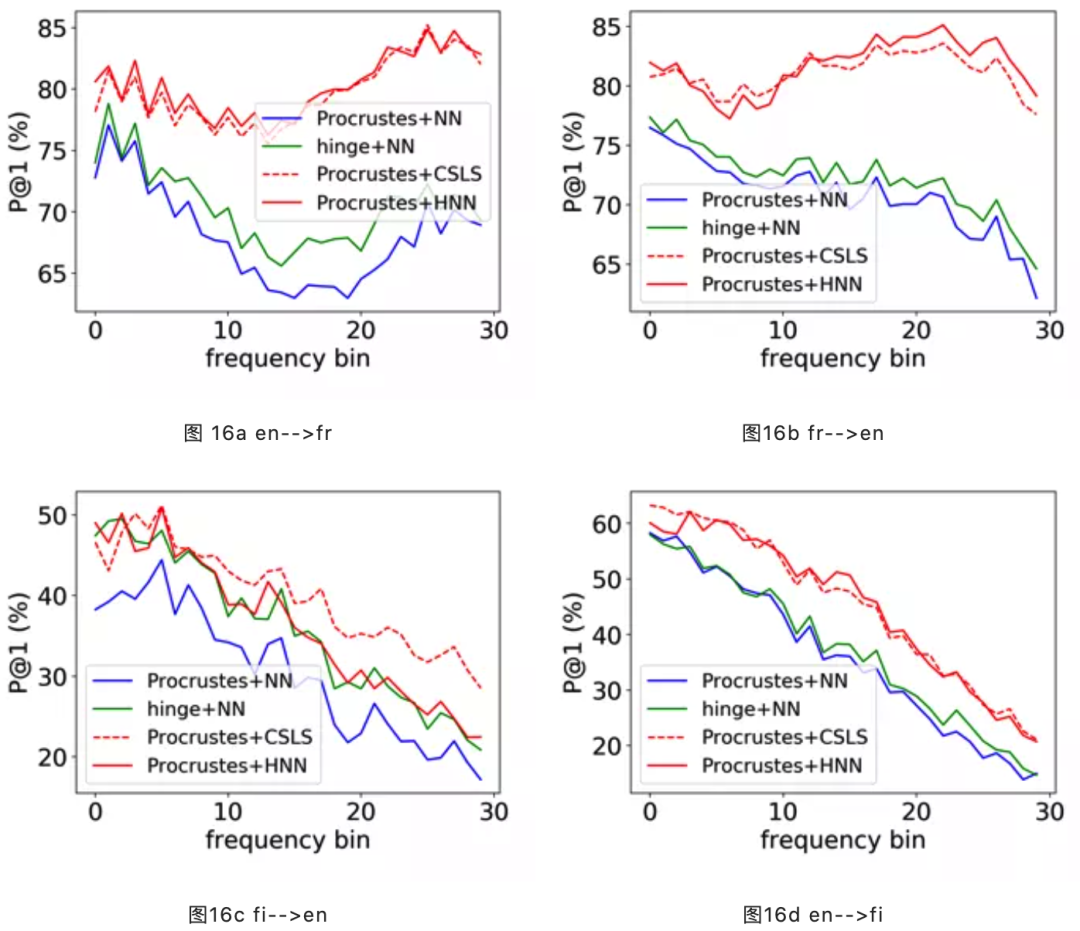
这两种方法对MUSE数据集中的若干语言对都有明显提升,见图16a~d。蓝色实线代表基线方法,绿色和红色实线分别代表方法1和2,红色虚线是facebook AI研究院提出的方法 CSLS。可以发现,方法1、2对比基线有明显提升,尤其是方法2,与CSLS相当甚至更好。
我们对EMNLP 2020中百度入选论文的解读至此结束。点击“阅读原文”,即可获取更多百度NLP学术论文资源!
百度自然语言处理(Natural Language Processing,NLP)以『理解语言,拥有智能,改变世界』为使命,研发自然语言处理核心技术,打造领先的技术平台和创新产品,服务全球用户,让复杂的世界更简单。

