
- 1【Sql Server】C#通过拼接代码的方式组合添加sql语句,会出现那些情况,参数化的作用
- 2Markdown语法之数学公式【总结】_markdown数学公式 点乘
- 3牛客_将链表m到n节点间的元素进行反转_c++反转链表中m位置到n位置的元素
- 4nginx作为tcp的负载均衡
- 5Xcode6模拟器路径的变更&应用沙盒地址的变更_xcode 沙盒路径 变化
- 6DELL PowerEdge R720XD 磁盘RAID及Hot Spare热备盘配置_dellr720配置raid
- 7Linux运维工程师面试题全面汇总(2023)_linux运维面试
- 8压缩qcow2虚拟机镜像文件_pve qcow2 压缩
- 9第二节HarmonyOS DevEco Studio创建项目以及界面认识_deveco studio 创建harmony项目
- 10Hadoop从入门到入土(第十天)_如果某个datanode的节点上的空闲空间低于特定的临界点,按照均衡策略,系统就
学习笔记:深度学习(3)——卷积神经网络(CNN)理论篇_cnn理论
赞
踩
学习时间:2022.04.10~2022.04.12
文章目录
3. 卷积神经网络CNN
CNN(Convolutional Neural Networks, ConvNets, 卷积神经网络)是神经网络的一种,是理解图像内容的最佳学习算法之一,并且在图像分割、分类、检测和检索相关任务中表现出色。
3.1 卷积神经网络的概念
3.1.1 什么是CNN?
CNN是一种带有卷积结构的前馈神经网络,卷积结构可以减少深层网络占用的内存量,其中三个关键操作——局部感受野、权值共享、池化层,有效的减少了网络的参数个数,缓解了模型的过拟合问题。
卷积层和池化层一般会取若干个,采用卷积层和池化层交替设置,即一个卷积层连接一个池化层,池化层后再连接一个卷积层,依此类推。由于卷积层中输出特征图的每个神经元与其输入进行局部连接,并通过对应的连接权值与局部输入进行加权求和再加上偏置值,得到该神经元输入值,该过程等同于卷积过程,CNN也由此而得名1。
**与ANN(Artificial Neural Networks,人工神经网络)的区别:**上一节所学习的MLP、BP,就是ANN。ANN通过调整内部神经元与神经元之间的权重关系,从而达到处理信息的目的。而在CNN中,其全连接层就是就是MLP,只不过在前面加入了卷积层和池化层。
CNN主要应用于图像识别(计算机视觉,CV),应用有:图像分类和检索、目标定位检测、目标分割、人脸识别、骨骼识别和追踪,具体可见MNIST手写数据识别、猫狗大战、ImageNet LSVRC等,还可应用于自然语言处理和语音识别。
3.1.2 为什么要用CNN?
总的来说,是为了解决两个难题:① 图像需要处理的数据量太大,导致成本很高,效率很低;② 图像在数字化的过程中很难保留原有的特征,导致图像处理的准确率不高。
- 原因1:图像很大(全连接BP神经网络的缺点)
补充:图像的数据结构
首先了解:计算机存储图片,实际是存储了一个 W × H × D W×H×D W×H×D的数组( W , H , D W, H, D W,H,D分别表示宽、高、维数,彩色图片包含RGB三维<红、绿、蓝三种颜色通道>)。每一个数字对应一个像素的亮度。
在黑白图像中,我们只需要一个矩阵。每个矩阵都存储0到255之间的值。这个范围是存储图像信息的效率(256之内的值正好可以用一个字节表达)和人眼的敏感度(我们区分有限数量的相同颜色灰度值)之间的折衷。
目前用于计算机视觉问题的图像通常为224x224甚至更大,而如果处理彩色图片则又需加入3个颜色通道(RGB),即224x224x3。
如果构建一个BP神经网络,其要处理的像素点就有224x224x3=150528个,也就是需要处理150528个输入权重,而如果这个网络的隐藏层有1024个节点(这种网络中的典型隐藏层可能有1024个节点),那么,仅第一层隐含层我们就必须训练150528x1024=15亿个权重。这几乎是不可能完成训练的,更别说还有更大的图片了。
- 原因2:位置可变
如果你训练了一个网络来检测狗,那么无论图像出现在哪张照片中,你都希望它能够检测到狗。
如果构建一个BP神经网络,则需要把输入的图片“展平”(即把这个数组变成一列,然后输入神经网络进行训练)。但这破坏了图片的空间信息。想象一下,训练一个在某个狗图像上运行良好的网络,然后为它提供相同图像的略微移位版本,此时的网络可能就会有完全不同的反应。
并且,有相关研究表明,人类大脑在理解图片信息的过程中,并不是同时观察整个图片,而是更倾向于观察部分特征,然后根据特征匹配、组合,最后得出整图信息。CNN用类似视觉的方式保留了图像的特征,当图像做翻转,旋转或者变换位置时,它也能有效的识别出来是类似的图像。
换句话说,在BP全连接神经网络中,隐含层每一个神经元,都对输入图片 每个像素点 做出反应。这种机制包含了太多冗余连接。为了减少这些冗余,只需要每个隐含神经元,对图片的一小部分区域,做出反应就好了。而卷积神经网络,正是基于这种想法而实现的。
3.1.3 人类的视觉原理
深度学习的许多研究成果,离不开对大脑认知原理的研究,尤其是视觉原理的研究。
人类的视觉原理如下:从原始信号摄入开始(瞳孔摄入像素 Pixels),接着做初步处理(大脑皮层某些细胞发现边缘和方向),然后抽象(大脑判定,眼前的物体的形状,是圆形的),然后进一步抽象(大脑进一步判定该物体是只气球)。
对于不同的物体,人类视觉也是通过这样逐层分级,来进行认知的:

我们可以看到,在最底层特征基本上是类似的,就是各种边缘,越往上,越能提取出此类物体的一些特征(轮子、眼睛、躯干等),到最上层,不同的高级特征最终组合成相应的图像,从而能够让人类准确的区分不同的物体。
那么我们可以很自然的想到:可以不可以模仿人类大脑的这个特点,构造多层的神经网络,较低层的识别初级的图像特征,若干底层特征组成更上一层特征,最终通过多个层级的组合,最终在顶层做出分类呢?
答案是肯定的,这也是许多深度学习算法(包括CNN)的灵感来源。
通过学习,卷积层可以学习到边缘(颜色变化的分界线)、斑块(局部的块状区域)及其他“高级”信息;随着层次加深,提取的信息(正确地讲,是反映强烈的神经元)也越来越抽象,神经元从简单的形状向“高级”信息变化。
3.2 CNN的基本原理
3.2.1 主要结构
CNN主要包括以下结构:
- 输入层(Input layer):输入数据;
- 卷积层(Convolution layer,CONV):使用卷积核进行特征提取和特征映射;
- 激活层:非线性映射(ReLU)
- 池化层(Pooling layer,POOL):进行下采样降维;
- 光栅化(Rasterization):展开像素,与全连接层全连接,某些情况下这一层可以省去;
- 全连接层(Affine layer / Fully Connected layer,FC):在尾部进行拟合,减少特征信息的损失;
- 激活层:非线性映射(ReLU)
- 输出层(Output layer):输出结果。
其中,卷积层、激活层和池化层可叠加重复使用,这是CNN的核心结构。
在经过数次卷积和池化之后,最后会先将多维的数据进行“扁平化”,也就是把(height,width,channel)的数据压缩成长度为height × width × channel的一维数组,然后再与FC层连接,这之后就跟普通的神经网络无异了。
3.2.2 卷积层(Convolution layer)
卷积层由一组滤波器组成,滤波器为三维结构,其深度由输入数据的深度决定,一个滤波器可以看作由多个卷积核堆叠形成。这些滤波器在输入数据上滑动做卷积运算,从输入数据中提取特征。在训练时,滤波器上的权重使用随机值进行初始化,并根据训练集进行学习,逐步优化。
1. 卷积运算
-
卷积核(Kernel)
-
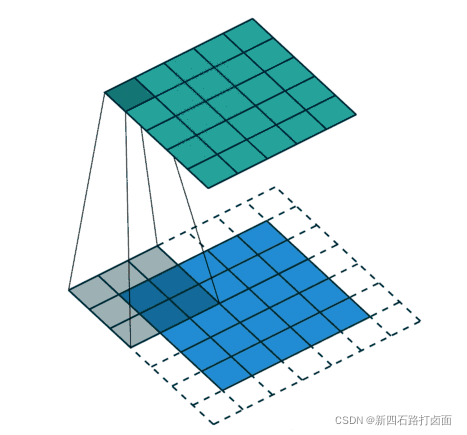
卷积运算是指以一定间隔滑动卷积核的窗口,将各个位置上卷积核的元素和输入的对应元素相乘,然后再求和(有时将这个计算称为乘积累加运算),将这个结果保存到输出的对应位置。卷积运算如下所示:
对于一张图像,卷积核从图像最始端,从左往右、从上往下,以一个像素或指定个像素的间距依次滑过图像的每一个区域。
-

-
卷积核大小( f × f f×f f×f)也可以变化,比如 1 × 1 、 5 × 5 1×1、5×5 1×1、5×5等,此时需要根据卷积核的大小来调节填充尺寸(Padding Size)。一般来说,卷积核尺寸取奇数(因为我们希望卷积核有一个中心,便于处理输出)。卷积核尺寸为奇数时,填充尺寸可以根据以下公式确定: P a d d i n g S i z e = f − 1 2 Padding Size = \frac{f-1}{2} PaddingSize=2f−1。
可以把卷积核理解为权重。每一个卷积核都可以当做一个“特征提取算子”,把一个算子在原图上不断滑动,得出的滤波结果就被叫做“特征图”(Feature Map),这些算子被称为“卷积核”(Convolution Kernel)。我们不必人工设计这些算子,而是使用随机初始化,来得到很多卷积核,然后通过反向传播优化这些卷积核,以期望得到更好的识别结果。
-
填充/填白(Padding)
-
在进行卷积层的处理之前,有时要向输入数据的周围填入固定的数据(比如0等),使用填充的目的是调整输出的尺寸,使输出维度和输入维度一致;
如果不调整尺寸,经过很多层卷积之后,输出尺寸会变的很小。所以,为了减少卷积操作导致的,边缘信息丢失,我们就需要进行填充(Padding)。
-
-
步幅/步长(Stride)
- 即卷积核每次滑动几个像素。前面我们默认卷积核每次滑动一个像素,其实也可以每次滑动2个像素。其中,每次滑动的像素数称为“步长”,步长为2的卷积核计算过程如下;

-
若希望输出尺寸比输入尺寸小很多,可以采取增大步幅的措施。但是不能频繁使用步长为2,因为如果输出尺寸变得过小的话,即使卷积核参数优化的再好,也会必可避免地丢失大量信息;
-
如果用 f f f表示卷积核大小, s s s表示步长, w w w表示图片宽度, h h h表示图片高度,那么输出尺寸可以表示为:
w o u t = w + 2 × P a d d i n g S i z e − f s + 1 h o u t = h + 2 × P a d d i n g S i z e − f s + 1 w_{out} = \frac{w+2×Padding\ Size - f}{s} + 1\\ h_{out} = \frac{h+2×Padding\ Size - f}{s} + 1 wout=sw+2×Padding Size−f+1hout=sh+2×Padding Size−f+1 -
滤波器(Filter)
-
卷积核(算子)是二维的权重矩阵;而滤波器(Filter)是多个卷积核堆叠而成的三维矩阵。
在只有一个通道(二维)的情况下,“卷积核”就相当于“filter”,这两个概念是可以互换的
-
上面的卷积过程,没有考虑彩色图片有RGB三维通道(Channel),如果考虑RGB通道,那么每个通道都需要一个卷积核,只不过计算的时候,卷积核的每个通道在对应通道滑动,三个通道的计算结果相加得到输出。即:每个滤波器有且只有一个输出通道。
当滤波器中的各个卷积核在输入数据上滑动时,它们会输出不同的处理结果,其中一些卷积核的权重可能更高,而它相应通道的数据也会被更加重视,滤波器会更关注这个通道的特征差异。
-
-
偏置
- 最后,偏置项和滤波器一起作用产生最终的输出通道。

多个filter也是一样的工作原理:如果存在多个filter,这时我们可以把这些最终的单通道输出组合成一个总输出,它的通道数就等于filter数。这个总输出经过非线性处理后,继续被作为输入馈送进下一个卷积层,然后重复上述过程。
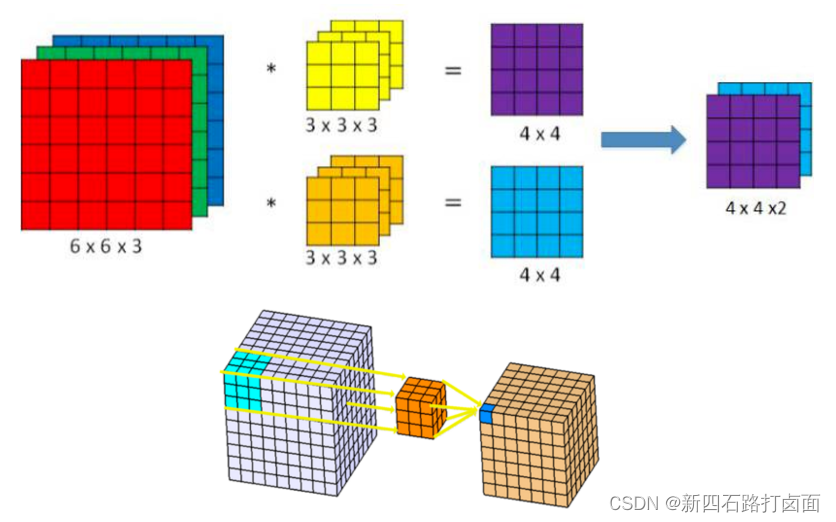
因此,这部分一共4个超参数:滤波器数量 K K K,滤波器大小 F F F,步长 S S S,零填充大小 P P P。
2. 卷积的三种模式
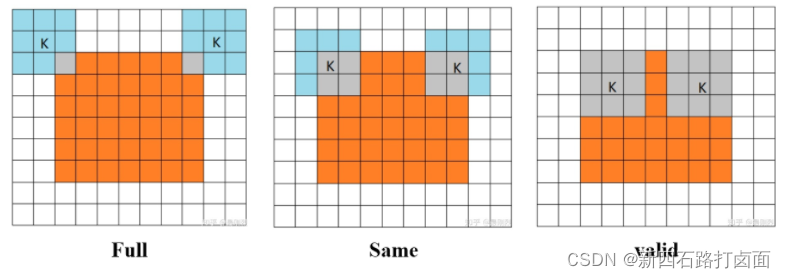
其实这三种不同模式是对卷积核移动范围的不同限制。
-
**Full Mode:**从卷积核和图像刚相交时开始做卷积,白色部分填0。
-
**Same Mode:**当卷积核中心(K)与图像的边角重合时,开始做卷积运算,白色部分填0。可见其运动范围比Full模式小了一圈。
注意:这里的same还有一个意思,卷积之后输出的feature map尺寸保持不变(相对于输入图片)。当然,same模式不代表完全输入输出尺寸一样,也跟卷积核的步长有关系。same模式也是最常见的模式,因为这种模式可以在前向传播的过程中让特征图的大小保持不变,调参师不需要精准计算其尺寸变化(因为尺寸根本就没变化)。
-
**Valid Mode:**当卷积核全部在图像里面时,进行卷积运算,可见其移动范围较Same更小了。
3. 卷积的本质
本部分主要来源:CNN常用卷积方法一览 。
追本溯源,我们先回到数学教科书中来看卷积。在泛函分析中,卷积也叫旋积或者褶积,是一种通过两个函数
x
(
t
)
x(t)
x(t)和
h
(
t
)
h(t)
h(t)生成的数学算子。其计算公式如下:
连
续
形
式
:
x
(
t
)
h
(
t
)
(
τ
)
=
∫
−
∞
+
∞
x
(
τ
)
h
(
τ
−
t
)
d
t
离
散
形
式
:
x
(
t
)
h
(
t
)
(
τ
)
=
∑
τ
=
−
∞
∞
x
(
τ
)
h
(
τ
−
t
)
连续形式:x(t)h(t)(τ) = \int^{+∞}_{-∞}x(τ)h(τ-t)dt\\ 离散形式:x(t)h(t)(τ) = \sum^{∞}_{τ=-∞}x(τ)h(τ-t)
连续形式:x(t)h(t)(τ)=∫−∞+∞x(τ)h(τ−t)dt离散形式:x(t)h(t)(τ)=τ=−∞∑∞x(τ)h(τ−t)
两个函数的卷积就是先将一个函数进行翻转(Reverse),然后再做一个平移(Shift),这便是"卷"的含义。而"积"就是将平移后的两个函数对应元素相乘求和。所以卷积本质上就是一个Reverse-Shift-Weighted Summation的操作。
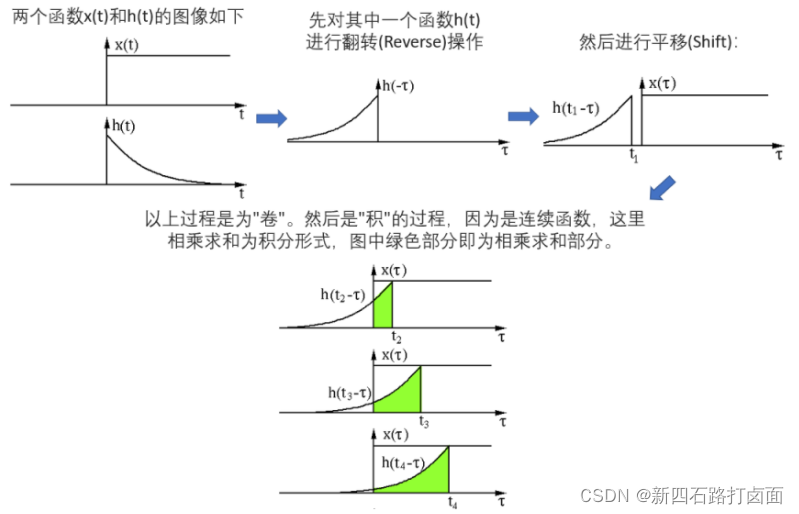
卷积能够更好提取区域特征,使用不同大小的卷积算子能够提取图像各个尺度的特征。卷积在信号处理、图像处理等领域有着广泛的应用。
3.2.3 池化层(Pooling layer)
池化(Pooling),有的地方也称汇聚,实际是一个下采样(Down-sample)过程,用来缩小高、长方向的尺寸,减小模型规模,提高运算速度,同时提高所提取特征的鲁棒性。简单来说,就是为了提取一定区域的主要特征,并减少参数数量,防止模型过拟合。
池化层通常出现在卷积层之后,二者相互交替出现,并且每个卷积层都与一个池化层一一对应。
常用的池化函数有:平均池化(Average Pooling / Mean Pooling)、最大池化(Max Pooling)、最小池化(Min Pooling)和随机池化(Stochastic Pooling)等,其中3种池化方式展示如下。
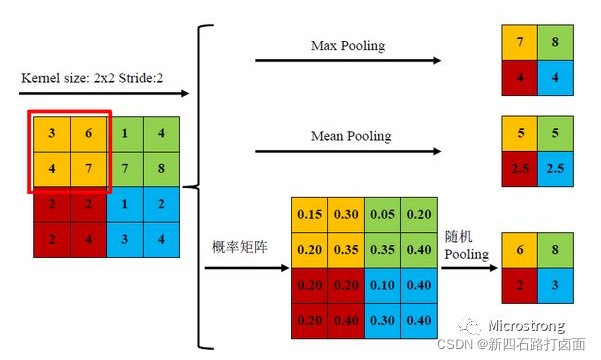
三种池化方式各有优缺点,均值池化是对所有特征点求平均值,而最大值池化是对特征点的求最大值。而随机池化则介于两者之间,通过对像素点按数值大小赋予概率,再按照概率进行亚采样,在平均意义上,与均值采样近似,在局部意义上,则服从最大值采样的准则。
根据Boureau理论2可以得出结论,在进行特征提取的过程中,均值池化可以减少邻域大小受限造成的估计值方差,但更多保留的是图像背景信息;而最大值池化能减少卷积层参数误差造成估计均值误差的偏移,能更多的保留纹理信息。随机池化虽然可以保留均值池化的信息,但是随机概率值确是人为添加的,随机概率的设置对结果影响较大,不可估计。
池化操作也有一个类似卷积核一样东西在特征图上移动,书中叫它池化窗口3,所以这个池化窗口也有大小,移动的时候有步长,池化前也有填充操作。因此,池化操作也有核大小 f f f、步长 s s s和填充 p p p参数,参数意义和卷积相同。Max池化的具体操作如下(池化窗口为 2 × 2 2×2 2×2,无填充,步长为 2 2 2):
一般来说,池化的窗口大小会和步长设定相同的值。
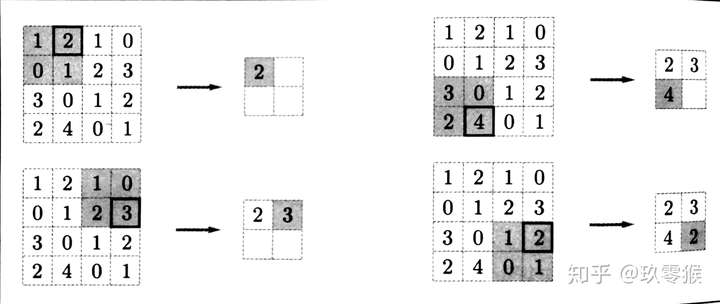
池化层有三个特征:
- 没有要学习的参数,这和池化层不同。池化只是从目标区域中取最大值或者平均值,所以没有必要有学习的参数。
- 通道数不发生改变,即不改变Feature Map的数量。
- 它是利用图像局部相关性的原理,对图像进行子抽样,这样对微小的位置变化具有鲁棒性——输入数据发生微小偏差时,池化仍会返回相同的结果。
3.2.4 激活层
即使用激活函数,在模型中引入非线性。具体的函数介绍,可以看第一篇:学习笔记:深度学习(1)——基础概念和激活函数。
3.2.5 光栅化
光栅化(Rasterization):为了与传统的多层感知器MLP全连接,把上一层的所有Feature Map的每个像素依次展开,排成一列。某些情况下这一层可以省去。
光栅化是把顶点数据转换为片元的过程,具有将图转化为一个个栅格组成的图象的作用,特点是每个元素对应帧缓冲区中的一像素。
3.2.6 全连接层
即接上传统的神经网络,可以看第二篇:学习笔记:深度学习(2)——BP神经网络。
3.2.7 反向传播
任何尝试过从头编写自己的神经网络代码的人都知道,完成正向传播还没有完成整个算法流程的一半。真正的乐趣在于你想要进行反向传播得到时候。
反向传播的BP算法原理同样可以看第二篇:学习笔记:深度学习(2)——BP神经网络。
多层感知机反向传播的数学推导,主要是用数学公式来进行表示的,在全连接神经网络中,它们并不复杂,即使是纯数学公式也比较好理解,而卷积神经网络的反向传播相对比较复杂。
- 池化层的反向传播
池化层的反向传播比较容易理解,我们以最大池化举例:
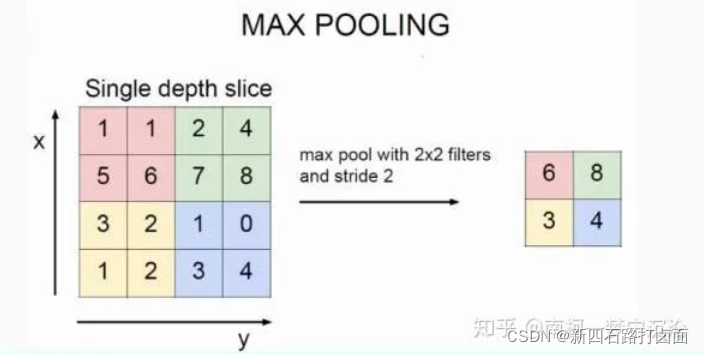
上图中,池化后的数字6对应于池化前的红色区域,实际上只有红色区域中最大值数字6对池化后的结果有影响,权重为1,而其它的数字对池化后的结果影响都为0。假设池化后数字6位置的误差为 δ δ δ,反向传播回去时,红色区域中最大值对应的位置误差即等于 δ δ δ,而其它3个位置对应的误差为0。
因此,在卷积神经网络最大池化前向传播时,不仅要记录区域的最大值,同时也要记录下来区域最大值的位置,方便误差的反向传播。
而平均池化就更简单了,由于平均池化时,区域中每个值对池化后结果贡献的权重都为区域大小的倒数,所以反向传播回来时,在区域每个位置的误差都为池化后误差除以区域的大小。
- 卷积层的反向传播
虽然卷积神经网络的卷积运算是一个三维张量的图片和一个四维张量的卷积核进行卷积运算,但最核心的计算只涉及二维卷积,因此我们先从二维的卷积运算来进行分析:
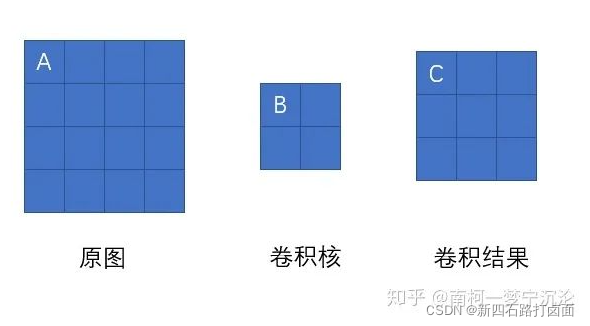
如上图所示,我们求原图A处的误差,就先分析,它在前向传播中影响了下一层的哪些结点。显然,它只对结点C有一个权重为B的影响,对卷积结果中的其它结点没有任何影响。因此A的误差应该等于C点的误差乘上权重B。

我们现在将原图A点位置移动一下,则A点以权重C影响了卷积结果的D点,以权重B影响了卷积结果的E点。那它的误差就等于D点误差乘上C加上E点的误差乘上B。大家可以尝试用相同的方法去分析原图中其它结点的误差,结果会发现,原图的误差,等于卷积结果的delta误差经过零填充后,与卷积核旋转180度后的卷积。
目前的结论还只是基于二维卷积,我们还需要把它推广到我们卷积神经网络中张量的卷积中去。再回顾一下张量的卷积,后一层的每个通道都是由前一层的各个通道经过卷积再求和得到的。第 Ⅰ Ⅰ Ⅰ层的通道1通过卷积影响了第 Ⅰ + 1 Ⅰ+1 Ⅰ+1层的通道1和通道2,那么求第 Ⅰ Ⅰ Ⅰ层通道1的误差时,就应该根据求得的二维卷积的误差传播方式,将第 Ⅰ + 1 Ⅰ+1 Ⅰ+1层通道1和通道2的误差传播到第 Ⅰ Ⅰ Ⅰ层的误差进行简单求和即可。
总结卷积神经网络的训练过程:
-
对神经网络进行初始化,定义好网络结构,设定好激活函数,对卷积层的卷积核 W W W、偏置 b b b进行随机初试化,对全连接层的权重矩阵 W W W和偏置 b b b进行随机初始化。
设置好训练的最大迭代次数,每个训练 b a t c h batch batch的大小,学习率 η η η。 -
从训练数据中取出一个 b a t c h batch batch的数据,然后从该 b a t c h batch batch数据中取出一个数据,包括输入 x x x以及对应的正确标注 y y y。
-
将输入 x x x送入神经网络的输入端,得到神经网络各层输出参数 z l z^l zl和 a l a^l al。
-
根据神经网络的输出和标注值 y y y计算神经网络的损失函数 L o s s Loss Loss。
-
计算损失函数 L o s s Loss Loss对输出层的误差 δ L δ^L δL。
-
利用相邻层之间误差的递推公式求得每一层的误差:
- 如果是全连接层: δ l = σ ′ ⋅ z l = ( W l + 1 ) T ⋅ δ l + 1 δ^l = σ'·z^l = (W^{l+1})^T·δ^{l+1} δl=σ′⋅zl=(Wl+1)T⋅δl+1;
- 如果是卷积层: δ l = σ ′ ⋅ z l = δ l + 1 ⋅ R O T 180 ( w l + 1 ) δ^l = σ'·z^l = δ^{l+1}·ROT180(w^{l+1}) δl=σ′⋅zl=δl+1⋅ROT180(wl+1);
- 如果是池化层: δ l = σ ′ ⋅ z l = u p s a m p l e ( δ l + 1 ) δ^l = σ'·z^l = upsample(δ^{l+1}) δl=σ′⋅zl=upsample(δl+1)。
-
利用每一层的delta误差求出损失函数对该层参数的导数:
- 如果是全连接层: ∂ C ∂ W l = δ l ( a l − 1 ) T , ∂ C ∂ b l = δ l \frac{∂C}{∂W^l} = δ^l(a^{l-1})^T, \ \frac{∂C}{∂b^l} = δ^l ∂Wl∂C=δl(al−1)T, ∂bl∂C=δl;
- 如果是卷积层: ∂ C ∂ w l = δ l ⋅ σ ( z l − 1 ) , ∂ C ∂ b l = ∑ x ∑ y δ l \frac{∂C}{∂w^l} = δ^l·σ(z^{l-1}), \ \frac{∂C}{∂b^l} = \sum_x\sum_yδ^l ∂wl∂C=δl⋅σ(zl−1), ∂bl∂C=∑x∑yδl。
-
将求得的导数加到该 b a t c h batch batch数据求得的导数之和上(初始化为0),跳转到步骤3,直到该 b a t c h batch batch数据都训练完毕。
-
利用一个 b a t c h batch batch数据求得的导数之和,根据梯度下降法对参数进行更新:
W l = W l − η b a t c h _ s i z e ∑ ∂ C ∂ W l W^l = W^l - \frac{η}{batch\_size}\sum\frac{∂C}{∂W^l} Wl=Wl−batch_sizeη∑∂Wl∂C, b l = b l − η b a t c h _ s i z e ∑ ∂ C ∂ b l b^l = b^l - \frac{η}{batch\_size}\sum\frac{∂C}{∂b^l} bl=bl−batch_sizeη∑∂bl∂C。
-
跳转到步骤2,直到达到指定的迭代次数。
3.2.8 CNN的特点
卷积神经网络相比于其他传统神经网络的特殊性主要在于权值共享与局部连接两个方面。
补充:卷积仍是线性变换(来源:什么是深度学习的卷积?):
尽管上文已经讲解了卷积层的机制,但我们还无法解释为什么卷积可以进行缩放,以及它在图像数据上的处理效果为什么会那么好。假设我们有一个4×4的输入,目标是把它转换成2×2的输出。
这时,如果我们用的是前馈网络,我们会把这个4×4的输入重新转换成一个长度为16的向量,然后把这16个值输入一个有4个输出的密集连接层中。下面是这个层的权重矩阵W:

虽然卷积的卷积核操作看起来很奇怪,但它仍然是一个带有等效变换矩阵的线性变换。如果我们在重构的4×4输入上使用一个大小为3的卷积核K,那么这个等效矩阵会变成:
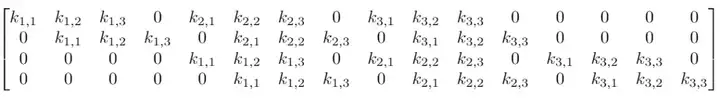
可以发现,整个卷积仍然是线性变换,但与此同时,它也是一种截然不同的变换。相比前馈网络的64个参数,卷积得到的9个参数可以多次重复使用。由于权重矩阵中包含大量0权重,我们只会在每个输出节点看到选定数量的输入(卷积核的输入)。
而更高效的是,卷积的预定义参数可以被视为权重矩阵的先验。当我们使用预训练模型进行图像分类时,我们可以把预先训练的网络参数作为当前的网络参数,并在此基础上训练自己的特征提取器。这会大大节省时间。
从这个意义上讲,虽然同为线性变换,卷积相比前馈网络的优势就可以被解释了。和随机初始化不同,使用预训练的参数允许我们只需要优化最终全连接层的参数,这意味着更好的性能。而大大削减参数数量则意味着更高的效率。
1. 局部连接/连接剪枝/稀疏连接(Sparse Connectivity)
1962年,Hubel和Wiesel4研究生物神经学里面的视觉分层结构而提出感受野的概念,大脑皮层的视觉神经元就是基于局部区域刺激来感知信息的。局部区域连接的思想就是受启发于视觉神经元的结构。
在传统的神经网络结构中,神经元之间的连接是全连接的,即n-1层的神经元与n层的所有神经元全部连接,所以输出的任何一个单元,都要受输入的所有的单元的影响,这样无形中会对图像的识别效果大打折扣;但是在卷积神经网络中,输出图像中的任何一个单元,只跟输入图像的一部分有关系,连接数成倍的减少,相应的参数也会减少。
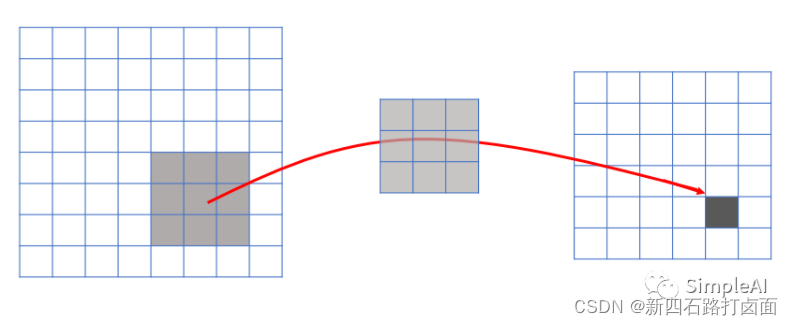
2. 权值共享/参数共享(Parameters Sharing)
本部分主要来源:卷积神经网络综述。
1998年,LeCun5发布了LeNet-5网络架构,权值共享这个词最开始是由LeNet-5模型提出来的。虽然现在大多数人认为,2012年的AlexNet网络6是深度学习的开端,但是CNN的开端可以追溯到LeNet-5模型。LeNet-5模型的几个特性在2010年初的卷积神经网络研究中被广泛的使用,其中一个就是权值共享。
在卷积神经网络中,卷积层中的卷积核(或称之为滤波器)类似于一个滑动窗口,在整个输入图像中以特定的步长来回滑动,经过卷积运算之后,从而得到输入图像的特征图,这个特征图就是卷积层提取出来的局部特征,而这个卷积核是共享参数的。在整个网络的训练过程中,包含权值的卷积核也会随之更新,直到训练完成。
- 什么是权值共享?
- 其实权值共享就是整张图片在使用同一个卷积核内的参数。比如一个331的卷积核,这个卷积核内9个的参数被整张图片共享,而不会因为图像内位置的不同而改变卷积核内的权系数。说的再通俗一点,就是用一个卷积核不改变其内权系数的情况下卷积处理整张图片。
- 当然,CNN中每一个卷积层不会只有一个卷积核的,这样说只是为了方便解释。
- 权值共享的优点?
- 权值共享的卷积操作保证了每一个像素都有一个权重系数,只是这些系数被整个图片共享,因此大大减少了卷积核中参数量,降低了网络的复杂度;
- 传统的神经网络和机器学习方法需要对图像进行复杂的预处理提取特征,将得到特征再输入到神经网络中。而加入卷积操作就可以利用图片空间上的局部相关性,自动的提取特征;
- 同样,由于filter的参数共享,即使图片进行了一定的平移操作,我们照样可以识别出特征,这叫做 “平移不变性”。因此,模型就更加稳健了。
- 为什么卷积层会有多个卷积核?
- 因为权值共享意味着每一个卷积核只能提取到一种特征,为了增加CNN的表达能力,需要设置多个卷积核。但是,每个卷积层中卷积核/滤波器的个数是一个超参数。
3. 感受野(Receptive Field)——CNN的可视化
无论是什么CNN架构,它们的基本设计就是不断压缩图像的高和宽,同时增加通道数量,也就是深度。局部性影响的是临近层的输入输出观察区域,而感受野决定的则是整个网络原始输入的观察区域。
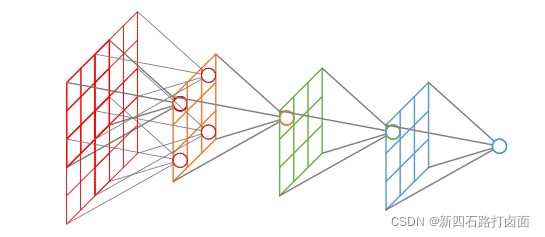
**感受野(Receptive Field)**的定义是卷积神经网络每一层输出的特征图(feature map)上的像素点在输入图片上映射的区域大小。即:神经网络中神经元“看到的”输入区域,在卷积神经网络中,feature map上某个元素的计算受输入图像上某个区域的影响,这个区域即该元素的感受野。再通俗点的解释是,特征图上的一个点对应输入图上的区域,如图所示。
把stride调整为2后,卷积得到的输出大大缩小。这时,如果我们在这个输出的基础上做非线性激活,然后再上面再加一个卷积层,有趣的事就发生了。相比正常卷积得到的输出,3×3卷积核在这个步幅卷积输出上的感受野更大。如下图所示:
这是因为它的原始输入区域就比正常卷积的输入区域大,这种感受野的扩大允许卷积层将低级特征(线条、边缘)组合成更高级别的特征(曲线、纹理),正如我们在mixed3a层中看到的那样。而随着我们添加更多Stride层,网络会显示出更多高级特征,如mixed4a、mixed5a。

通过检测低级特征,并使用它们来检测更高级别的特征,使其在视觉层次结构中向前发展,最终能够检测到整个视觉概念,如面部,鸟类,树木等。这就是卷积在图像数据上如此强大、高效的一个原因。
感受野的具体计算可以参考:[彻底搞懂感受野的含义与计算](https://www.cnblogs.com/shine-lee/p/12069176.html#:~:text=感受野(Receptive,Field),指的是神经网络中神经元“看到的”输入区域,在卷积神经网络中,feature map上某个元素的计算受输入图像上某个区域的影响,这个区域即该元素的感受野。)。
3.2.9 CNN泛化能力提高技巧
-
增加神经网络深度;
-
修改激活函数,使用较多的是ReLU激活函数;
-
调整权重初始化技术,一般来说,均匀分布初始化效果较好;
-
调整batch大小(数据集大小);
-
扩展数据集(data augmentation),可以通过平移、旋转图像等方式扩展数据集,使学习效果更好;
-
采取正则化;
-
采取Dropout方法避免过拟合。
3.3 CNN的类型综述
本综述将最近的 CNN 架构创新分为七个不同的类别,分别基于空间利用、深度、多路径、宽度、特征图利用、通道提升和注意力[^12]。
通过 1989 年 LeCun 处理网格状拓扑数据(图像和时间系列数据)的研究,CNN 首次受到关注。CNN 被视为理解图像内容的最好技术之一,并且在图像识别、分割、检测和检索相关任务上表现出了当前最佳性能。CNN 的成功引起了学界外的注意。在产业界,如谷歌、微软、AT&T、NEC 和 Facebook 这样的公司都设立了研究团队来探索 CNN 的新架构。目前,图像处理竞赛中的大多数领跑者都会采用基于深度 CNN 的模型。
自 2012 年以来,关于 CNN 架构的不同创新被提出来。这些创新可分为参数优化、正则化、结构重组等。但是据观察,CNN 网络的性能提升应主要归功于处理单元的重构和新模块的设计。
自 AlexNet 在 ImageNet 数据集上展现出了非凡的性能后,基于 CNN 的应用变得越来越普及。类似地,Zeiler 和 Fergus 介绍了特征分层可视化的概念,这改变了用深度架构(如 VGG)在简单的低空间分辨率中提取特征的趋势。如今,大多数新架构都是基于 VGG 引入的简单原则和同质化拓扑构建的。
另一方面,谷歌团队引入了一个非常著名的关于拆分、转换和合并的概念,称为 Inception 模块。初始块第一次使用了层内分支的概念,允许在不同空间尺度上提取特征。2015 年,为了训练深度 CNN,Resnet 引入的残差连接概念变得很有名,并且,后来的大多数网络像 Inception-ResNet,WideResNet,ResNext 等都在使用它。与此类似,一些像 WideResnet、Pyramidal Nets、Xception 这样的架构都引入了多层转换的概念,通过额外的基数和增加的宽度来实现。因此,研究的重点从参数优化和连接再次调整,转向了网络架构设计(层结构)。这引发了许多像通道提升、空间和通道利用、基于注意力的信息处理等新的架构概念。
自 1989 年至今,CNN 架构已经有了很多不同的改进。CNN 中的所有创新都是通过深度和空间相结合实现的。根据架构修改的类型,CNN 可以大致分为 7 类:基于空间利用、深度、多路径、宽度、通道提升、特征图利用和注意力的CNN。深度 CNN 架构的分类如图所示。
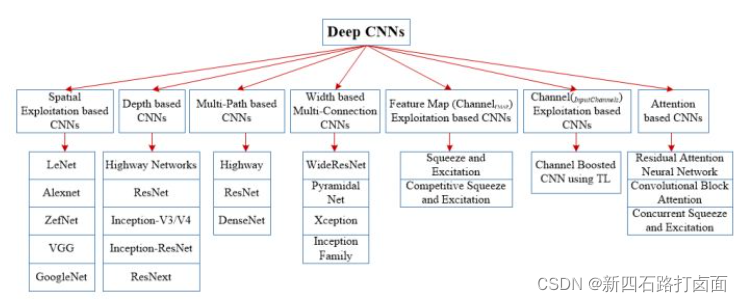
3.3.1 基于空间利用的CNN
CNN 有大量参数,如处理单元数量(神经元)、层数、滤波器大小、步幅、学习率和激活函数等。由于 CNN 考虑输入像素的邻域(局部性),可以使用不同大小的滤波器来探索不同级别的相关性。因此,在 2000 年初,研究人员利用空间变换来提升性能,此外,还评估了不同大小的滤波器对网络学习率的影响。不同大小的滤波器封装不同级别的粒度;通常,较小的滤波器提取细粒度信息,而较大的滤波器提取粗粒度信息。这样,通过调整滤波器大小,CNN 可以在粗粒度和细粒度的细节上都表现很好。
基于空间利用(Spatial Exploitation based)的CNN有:LeNet、Alenet、ZefNet、VGG、GoogleNet等。
1. LeNet-5(20c90s)
LeNet是最早推动深度学习领域发展的卷积神经网络之一。这项由Yann LeCun7完成的开创性工作自1988年以来多次成功迭代之后被命名为LeNet-5。(该模型基本同上述介绍)
卷积层块里的基本单位是卷积层后接平均池化层。每个卷积层都使用5×5的窗口,并在输出上使用Sigmoid激活函数,用来识别图像里的空间模式,如线条和物体局部(第一个卷积层输出通道数为6,第二个卷积层输出通道数则增加到16);平均池化层则用来降低卷积层对位置的敏感性,对卷积层输出的结果进行采样,压缩图像尺寸大小。卷积层由两个这样的基本单位重复堆叠构成。
全连接层块含3个全连接层。其中的向量全部展开成一维向量,一维向量与权重向量进行点积运算,在加上一个偏置,通过激活函数后输出,得到新的神经元输出。它们的神经元个数分别是120、84和10,其中10为输出的类别个数,也是输出层。
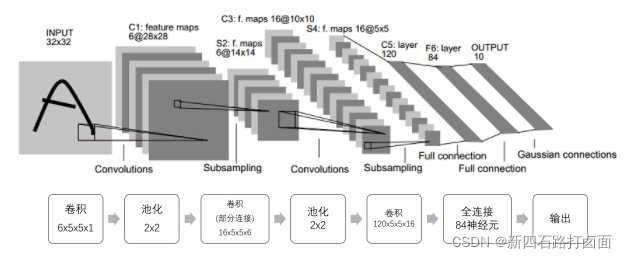
2. AlexNet(2012)
2012年,Alex Krizhevsky等6发布了 AlexNet,它是提升了深度和广度版本的LeNet,并在2012年以巨大优势赢得了ImageNet大规模视觉识别挑战赛(ILSVRC)。这是基于之前方法的重大突破,目前 CNN 的广泛应用都要归功于AlexNet。
AlexNet首次证明了学习到的特征可以超越⼿⼯设计的特征,它有以下四点特征:
- 8层变换,其中有5层卷积和2层全连接隐藏层,以及1个全连接输出层;
- 将sigmoid激活函数改成了更加简单的ReLU激活函数,降低了模型的计算复杂度,模型的训练速度也提升了几倍;
- Max池化,避免平均池化的模糊化效果。同时采用重叠池化,提升特征的丰富性;
- 用Dropout来控制全连接层的模型复杂度:通过Dropout技术在训练过程中将中间层的一些神经元随机置为0,使模型更具有鲁棒性,也减少了全连接层的过拟合;
- 引入数据增强(Data Augmentation),如图像平移、镜像、翻转、裁剪、改变灰度和颜色变化,从而进一步扩大数据集来缓解过拟合。
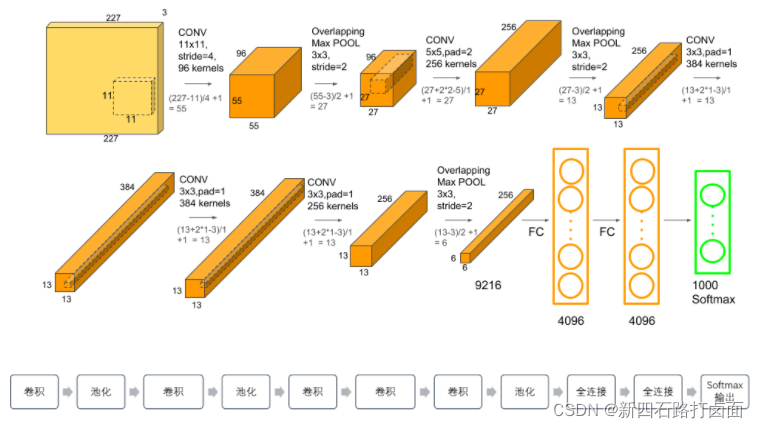
3. GoogLeNet(2014)
2014年 ILSVRC 获奖者是 Google 的 Szegedy 等8人的卷积网络。其主要贡献是开发了一个初始模块(Inception),该模块大大减少了网络中的参数数量(4M,而AlexNet有60M)。
LeNet、AlexNet和VGG都是先以由卷积层构成的模块充分抽取空间特征,再以由全连接层构成的模块来输出分类结果。与它们三种模型不同,GoogLeNet模型由如下的Inception基础块组成,Inception块相当于⼀个有4条线路的子网络,该结构将CNN中常用的卷积( 1 × 1 , 3 × 3 , 5 × 5 1×1,\ 3×3,\ 5×5 1×1, 3×3, 5×5)、池化操作(3x3)堆叠在一起,一方面增加了网络的宽度,另一方面也增加了网络对尺度的适应性。它通过不同窗口形状的卷积层和最⼤池化层来并行抽取信息,并使用 1 × 1 1×1 1×1卷积层减少通道数从而降低模型复杂度。它的参数比AlexNet少了12倍,而且GoogleNet的准确率更高。
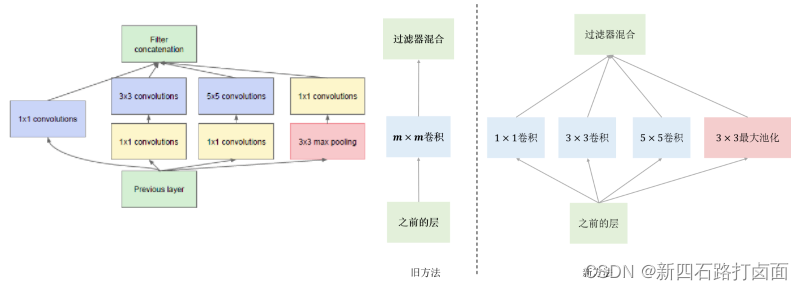
4. VGGNet(2014)
2014年ILSVRC亚军是名为VGGNet的网络,由Simonyan等人9开发。其主要贡献在于证明了网络深度(层数)是影响性能的关键因素。它使用了小卷积核,用卷积深度替代了卷积核大小。
VGG模型用具有小卷积核的多个卷积层替换一个具有较大卷积核的卷积层,如用大小均为 3 × 3 3×3 3×3卷积核的3层卷积层代替一层具有 7 × 7 7×7 7×7卷积核的卷积层,这种替换方式减少了参数的数量,而且也能够使决策函数更具有判别性。接上一个步幅为 2 2 2、窗口形状为 2 × 2 2×2 2×2的最大池化层,使得卷积层保持输入的高和宽不变,而池化层则对其减半。
- 2个 3 × 3 3×3 3×3相当于1个 5 × 5 5×5 5×5 ;
- 3个 3 × 3 3×3 3×3相当于1个 7 × 7 7×7 7×7;
- 1 × 1 1×1 1×1的卷积层可视为非线性变换。
实验结果表明,当权值层数达到16-19层时,模型的性能能够得到有效的提升。最常见的是VGG16和VGG19模型。其中VGG16网络结构如下:
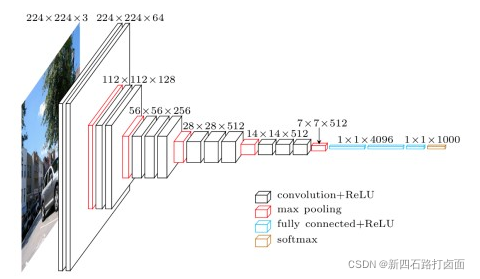
VGG模型通过增加层数,提高模型的深度明显提高了模型的性能,但也同时存在着梯度爆炸和梯度消失的现象无法解决;另外,模型也存在着退化问题,即模型的深度达到20层后,在增加深度模型的能力反而下降。
3.3.2 基于深度的CNN
深度 CNN 架构基于这样一种假设:随着深度的增加,网络可以通过大量非线性映射和改进的特征表示更好地逼近目标函数。网络深度在监督学习的成功中起了重要作用。理论研究已表明,深度网络能够以指数方式比浅层网络更有效地表示特定的 20 个函数类型。2001 年,Csáji 表示了通用近似定理,指出单个隐藏层足够逼近任何函数,但这需要指数级的神经元,因而通常导致计算上行不通。在这方面,Bengio 和 elalleau 认为更深的网络有潜力在更少的成本下保持网络的表现能力。2013 年,Bengio 等人通过 实证表明,对于复杂的任务,深度网络在计算和统计上都更有效。在 2014-ILSVR 竞赛中表现最佳的 Inception 和 VGG 则进一步说明,深度是调节网络学习能力的重要维度。
一旦特征被提取,只要其相对于其他位置的近似位置被保留,其提取位置就变得没那么重要了。池化或下采样(如卷积)是一种有趣的局部操作。它总结了感受野附近的类似信息,并输出了该局部区域内的主要反应。作为卷积运算的输出结果,特征图案可能会出现在图像中的不同位置。
基于深度(Depth based)的CNN有:Highway Networks、ResNet、Inception V3/V4、Inception-ResNet、ResNext等。
ResNets(2015)
何凯明等10人开发的残差网络是2015年ILSVRC的冠军。ResNets是迄今为止最先进的卷积神经网络模型,并且是大家在实践中使用卷积神经网络的默认选择(截至2016年5月)。ResNets采用残差网络(Residual Networks,ResNet)来解决梯度消失的问题。
ResNet的主要特点是跨层连接,它通过引入捷径连接技术(shortcut connections)将输入跨层传递并与卷积的结果相加。在ResNet中只有一个池化层,它连接在最后一个卷积层后面。ResNet使得底层的网络能够得到充分训练,准确率也随着深度的加深而得到显著提升。将深度为152层的ResNet用于LSVRC-15的图像分类比赛中,它获得了第1名的成绩。在该文献中,还尝试将ResNet的深度设置为1000,并在CIFAR-10图像处理数据集中验证该模型。
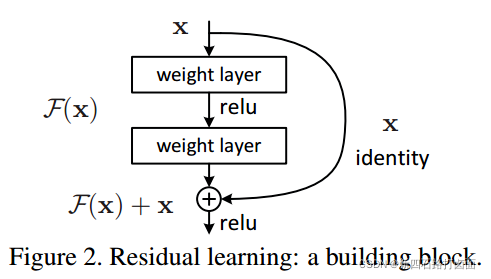
ResNe通过恒等映射的形式解决了VGGNet的退化问题:
残差的思想就是去掉相同的主体部分,从而突出微小的变化,改变后输出变化对权重的调整作用更大,所以效果更好。
若将输入设为X,将某一有参网络层设为H,那么以X为输入的此层的输出将为H(X)。一般的CNN网络如Alexnet/VGG等会直接通过训练学习出参数函数H的表达,从而直接学习X -> H(X)。而残差学习则是致力于使用多个有参网络层来学习输入、输出之间的参差即F(X) = H(X) - X,即学习X -> F(X)+ X。其中X这一部分为直接的identity mapping(恒等映射),而F(X) = H(X) - X 则为有参网络层要学习的输入与输出之间的残差。
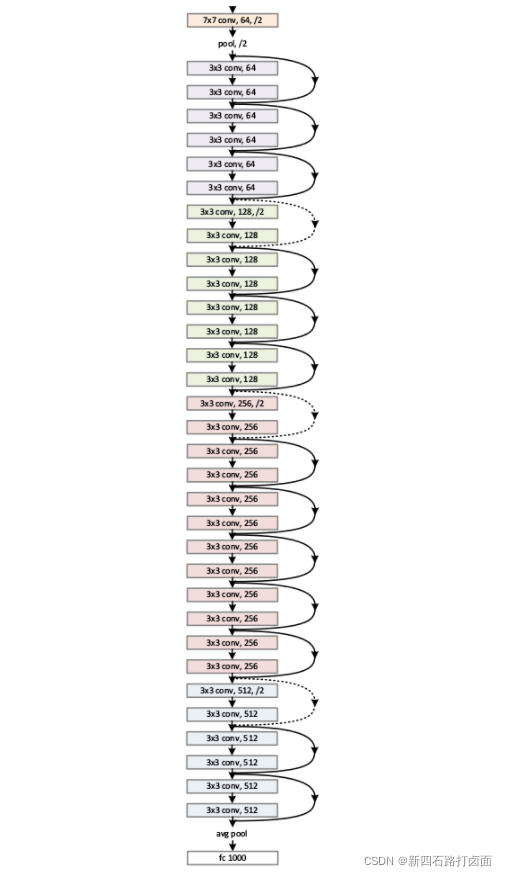
越深的网络的层数能够提取到输入图像越丰富的的特征表示。但是对于之前的非残差网络,简单地增加深度会导致梯度弥散或梯度爆炸的问题,而ResNet模型成功的解决了网络深度的问题,ResNet模型可以变得很深,目前已有的甚至超过1000层。研究和实验表明,加深的残差网络能够比简单叠加层生产的深度网络更容易优化,并且因为深度的增加,模型的效果也得到了明显提升。一种ResNet的网络结构如下图所示。
3.3.3 基于多路径的CNN
深度网络的训练颇具挑战性,这也是近来很多深度网络研究的主题。深度 CNN 为复杂任务提供了高效的计算和统计。但是,更深的网络可能会遭遇性能下降或梯度消失/爆炸的问题,而这通常是由增加深度而非过拟合造成的。梯度消失问题不仅会导致更高的测试误差,还会导致更高的训练误差。为了训练更深的网络,多路径或跨层连接的概念被提出。多路径或捷径连接可以通过跳过一些中间层,系统地将一层连接到另一层,以使特定的信息流跨过层。跨层连接将网络划分为几块。这些路径也尝试通过使较低层访问梯度来解决梯度消失问题。为此,使用了不同类型的捷径连接,如零填充、基于投影、dropout 和 1x1 连接等。
基于多路径(Multi-Path based)的CNN有:Highway、ResNet、DenseNet等。
3.3.4 基于宽度的多连接CNN
2012 至 2015 年,网络架构的重点是深度的力量,以及多通道监管连接在网络正则化中的重要性。然而,网络的宽度和深度一样重要。通过在一层之内并行使用多处理单元,多层感知机获得了在感知机上映射复杂函数的优势。这表明宽度和深度一样是定义学习原则的一个重要参数。Lu 等人和 Hanin & Sellke 最近表明,带有线性整流激活函数的神经网络要足够宽才能随着深度增加保持通用的近似特性。并且,如果网络的最大宽度不大于输入维度,紧致集上的连续函数类无法被任意深度的网络很好地近似。因此,多层堆叠(增加层)可能不会增加神经网络的表征能力。与深度架构相关的一个重要问题是,有些层或处理单元可能无法学习有用的特征。为了解决这一问题,研究的重点从深度和较窄的架构转移到了较浅和较宽的架构上。
基于宽度的多连接(Width based Multi-Connection)CNN有:WideResNet、Pyramidal Net、Xception、Inception Family等。
3.3.5 基于(通道)特征图开发的CNN
CNN 因其分层学习和自动特征提取能力而闻名于 MV 任务中。特征选择在决定分类、分割和检测模块的性能上起着重要作用。传统特征提取技术中分类模块的性能要受限于特征的单一性。相较于传统技术,CNN使用多阶段特征提取,根据分配的输入来提取不同类型的特征(CNN 中称之为特征图)。但是,一些特征图有很少或者几乎没有目标鉴别作用。巨大的特征集有噪声效应,会导致网络过拟合。这表明,除了网络工程外,特定类别特征图的选取对改进网络的泛化性能至关重要。在这一部分,特征图和通道会交替使用,因为很多研究者已经用通道这个词代替了特征图。
基于(通道)特征图(Feature Map Exploitation based)开发的CNN有:Squeeze and Excitation、Competitive Squeeze and Excitation等。
3.3.6 基于(输入)通道利用的CNN
图像表征在决定图像处理算法的性能方面起着重要作用。图像的良好表征可以定义来自紧凑代码的图像的突出特征。在不同的研究中,不同类型的传统滤波器被用来提取单一类型图像的不同级别信息。这些不同的表征被用作模型的输入,以提高性能。CNN 是一个很好的特征学习器,它能根据问题自动提取鉴别特征。但是,CNN 的学习依赖于输入表征。如果输入中缺乏多样性和类别定义信息,CNN 作为鉴别器的性能就会受到影响。为此,辅助学习器的概念被引入到 CNN 中来提升网络的输入表征。
基于(输入)通道利用(Channel Exploitation based)的CNN有:Channel Boosted CNN using TL等。
3.3.7 基于注意力的CNN
不同的抽象级别在定义神经网络的鉴别能力方面有着重要的作用。除此之外,选择与上下文相关的特征对于图像定位和识别也很重要。在人类的视觉系统中,这种现象叫做注意力。人类在一次又一次的匆匆一瞥中观察场景并注意与上下文相关的部分。在这个过程中,人类不仅注意选择的区域,而且推理出关于那个位置的物体的不同解释。因此,它有助于人类以更好的方式来抓取视觉结构。类似的解释能力被添加到像 RNN 和 LSTM 这样的神经网络中。上述网络利用注意力模块来生成序列数据,并且根据新样本在先前迭代中的出现来对其加权。不同的研究者把注意力概念加入到 CNN 中来改进表征和克服数据的计算限制问题。注意力概念有助于让 CNN 变得更加智能,使其在杂乱的背景和复杂的场景中也能识别物体。
基于注意力(Attention based)的CNN有:Residual Attention Neural Network、Convolutional Block Attention、Concurrent Squeeze and Excitation等。
3.3.8 补充:PyTorch-Networks
⭐对于各种CNN模型,已经有人将它们都进行了PyTorch实现:https://github.com/shanglianlm0525/PyTorch-Networks。此外,该项目也实现了12种CNN模型:https://github.com/BIGBALLON/CIFAR-ZOO。⭐
该系列的卷积神经网络实现包含了9大主题,有:典型网络、轻量级网络、目标检测网络、语义分割网络、实例分割网络、人脸检测和识别网络、人体姿态识别网络、注意力机制网络、人像分割网络。
1. 典型网络(Classical network)
- 典型的CNN包括:AlexNet、VGG、ResNet、InceptionV1、InceptionV2、InceptionV3、InceptionV4、Inception-ResNet。
2. 轻量级网络(Light weight)
- 轻量级网络包括:GhostNet、MobileNets、MobileNetV2、MobileNetV3、ShuffleNet、ShuffleNet V2、SqueezeNet Xception MixNet GhostNet。
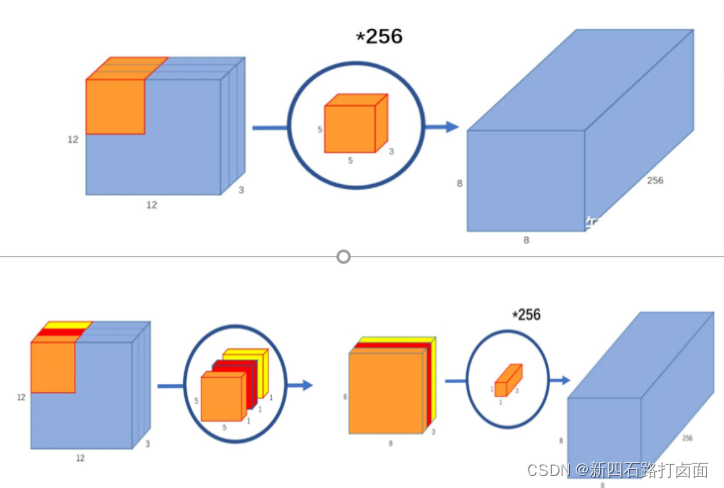
- MobileNet 由谷歌在 2017 年提出,是一款专注于在移动设备和嵌入式设备上的轻量级CNN神经网络,并迅速衍生出v1 v2 v3 三个版本;相比于传统CNN网络,在准确率小幅降低的前提下,大大减小模型参数和运算量。
- 其主要思想不再是提高模型的深度和宽度,而是改变卷积的方式,把标准卷积层换成深度可分离卷积,即把卷积分为深度卷积和逐点卷积两个步骤,在保证模型准确率的前提下,大大降低了模型的运算量。改进前、后的卷积过程对比如下:
3. 目标检测网络(Object Detection)
- 目标检测网络包括:SSD、YOLO、YOLOv2、YOLOv3、FCOS、FPN、RetinaNet Objects as Points、FSAF、CenterNet FoveaBox。
- 以 YOLO 系列为例,YOLO(You Only Look Once)是一种基于深度神经网络的对象识别和定位算法,其最大的特点是运行速度很快,可以用于实时系统。目前 YOLOv3 应用比较多。
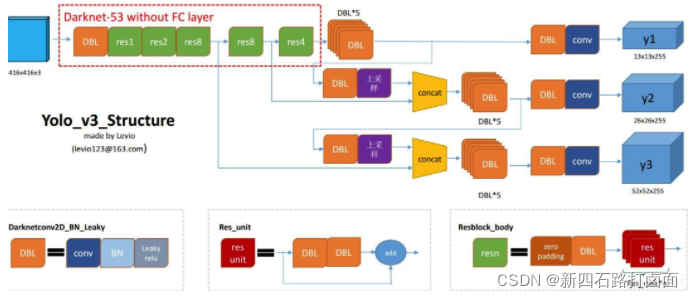
- 以 YOLO 系列为例,YOLO(You Only Look Once)是一种基于深度神经网络的对象识别和定位算法,其最大的特点是运行速度很快,可以用于实时系统。目前 YOLOv3 应用比较多。
4. 语义分割网络(Semantic Segmentation)
- 语义分割网络包括:FCN、Fast-SCNN、LEDNet、LRNNet、FisheyeMODNet。
- 以 FCN 为例,FCN 诞生于 2014 的语义分割模型先驱,主要贡献为在语义分割问题中推广使用端对端卷积神经网络,使用反卷积进行上采样。FCN 模型非常简单,里面全部是由卷积构成的,所以被称为全卷积网络,同时由于全卷积的特殊形式,因此可以接受任意大小的输入。
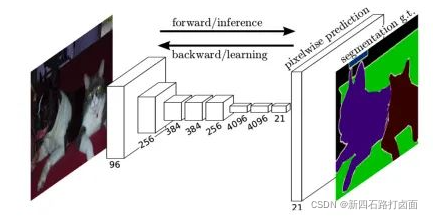
- 以 FCN 为例,FCN 诞生于 2014 的语义分割模型先驱,主要贡献为在语义分割问题中推广使用端对端卷积神经网络,使用反卷积进行上采样。FCN 模型非常简单,里面全部是由卷积构成的,所以被称为全卷积网络,同时由于全卷积的特殊形式,因此可以接受任意大小的输入。
5. 实例分割网络(Instance Segmentation)
- 实例分割网络包括:PolarMask。
6. 人脸检测和识别网络(commit VarGFaceNet)
- 人脸检测和识别网络包括:FaceBoxes、LFFD、VarGFaceNet。
7. 人体姿态识别网络(Human Pose Estimation)
- 人体姿态识别网络包括:Stacked Hourglass、Networks Simple Baselines、LPN。
8. 注意力机制网络(Attention)
- 注意力机制网络包括:SE Net、scSE、NL Net、GCNet、CBAM。
9. 人像分割网络(Portrait Segmentation)
- 人像分割网络包括:SINet。
3.4 CNN的局限
虽然CNN所具有的这些特点使其已被广泛应用于各种领域中,但其优势并不意味着目前存在的网络没有瑕疵。
如何有效地训练层级很深的深度网络模型仍旧是一个有待研究的问题。尽管图像分类任务能够受益于层级较深的卷积网络,但一些方法还是不能很好地处理遮挡或者运动模糊等问题。
周飞燕, 金林鹏, 董军. 卷积神经网络研究综述[J]. 计算机学报, 2017, 40(6): 1229-1251. ↩︎
Boureau Y L, Bach F, LeCun Y, et al. Learning mid-level features for recognition[J]. 2010. ↩︎
《深度学习入门基于Python的理论与实现》 ↩︎
Hubel D H, Wiesel T N. Receptive fields, binocular interaction and functional architecture in the cat’s visual cortex[J]. The Journal of physiology, 1962, 160(1): 106-154. ↩︎
LeCun Y, Bottou L, Bengio Y, et al. Gradient-based learning applied to document recognition[J]. Proceedings of the IEEE, 1998, 86(11): 2278-2324. ↩︎
Krizhevsky A, Sutskever I, Hinton G E. Imagenet classification with deep convolutional neural networks[C]//Advances in neural information processing systems. 2012: 1097-1105. https://www.aminer.cn/archive/imagenet-classification-with-deep-convolutional-neural-networks/53e9a281b7602d9702b88a98 ↩︎ ↩︎
https://arxiv.org/abs/1901.06032 ↩︎
Szegedy C, Liu W, Jia Y, et al. Going deeper with convolutions[C]//Proceedings of the IEEE conference on computer vision and pattern recognition. 2015: 1-9. ↩︎
Simonyan K, Zisserman A. Very deep convolutional networks for large-scale image recognition[J]. arXiv preprint arXiv:1409.1556, 2014. ↩︎
He K, Zhang X, Ren S, et al. Deep residual learning for image recognition[C]//Proceedings of the IEEE conference on computer vision and pattern recognition. 2016: 770-778. ↩︎

