
- 1鸿蒙开发实战项目:录音变声应用
- 2问答机器人三种实现方式_智能问答机器人实现方案有哪些
- 3linux中函数使用,Linux中likely 函数的使用分析
- 4毕设项目分享 深度学习垃圾分类
- 5Python_机器学习_算法_第3章_3.逻辑回归_python逻辑回归
- 6android databinding 之自定义控件_andatabinding 自定义组合控件
- 7迅为RK3399开发板瑞芯微国产安卓工控核心板边缘计算AI人工智能_buzzer1 klj-5018
- 8MATLAB高光谱图像处理基础_matlab展示三波段
- 9深度学习6. 多层感知机及PyTorch实现_利用 pytorch 编写一个有三个层的多层感知机模型及其训练过程,要求输入 单元有 78
- 10Mysql常用show命令,show variables like xxx 详解,mysql运行时参数
中文语音克隆现阶段总结_valueerror: cannot take a larger sample than popul
赞
踩
模型
gmw:
ge2e_pretrained.pt: 作为encoder(声音编码器)
用的是已经训练好的模型
模型的主要功能是:接受到说话人音频,然后转成一个向量作为speaker embedding;
同时利用了ge2e loss,参考这篇论文:Generalized End-to-End Loss for Speaker Verification,实现了speaker verification,将每个人说的所有话能够聚类到一起,而又和其他人说的话分隔的足够远

mellotron.kuangdd-rtvc.pt: (语音合成器)
waveglow.kuangdd.pt: Vocoder(声码器)
训练
问题:
训练到怎样可以停止?
训练loss等如何可视化?
训练数据准备
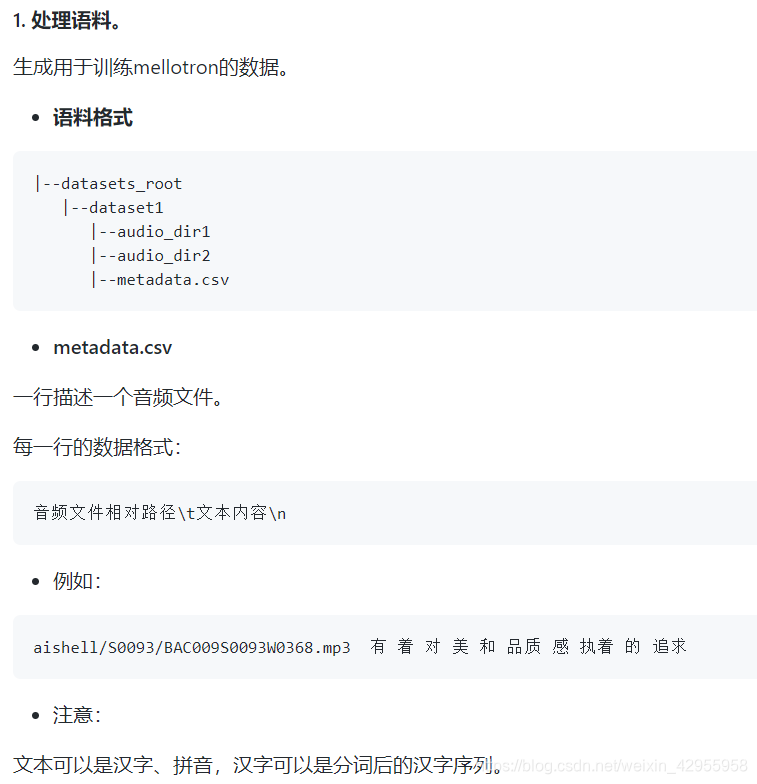
照这个意思是只需要准备:音频+对应文本就可
看代码发现,这里会自动补充speaker
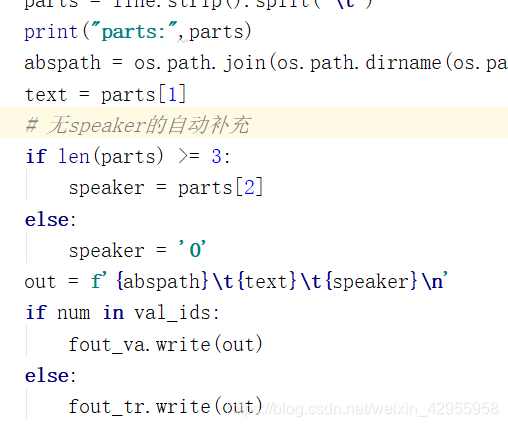
更改数据时出现如下问题:
ValueError: Cannot take a larger sample than population when ‘replace=False’
mellotron/train.py:

简言之,就是数据量不够,这个random是随机取,但是要取的数量大于有的数量,同时replace=False,设置了不能重复取,就导致了报错
解决方案(参见上面博客):
- 增加数据集
- replace=True
克隆声音构想:
方案一:
- 直接使用作者提供的训练好的模型,虽然效果偏低,但勉强凑合
方案二:
- 首先实现语音识别,并按片段语音识别,保存音频和对应文本(因为给的模型是用来训练短文本的,无法确定训练长文本不会出错,同时训练需要大量时间,成本较大,稳妥点好)
- 将以上输出作为克隆模型的数据集
- 重新训练模型
- 检查效果
这里需要注意的是,我之前按照已有的一些数据来训练,训练出的结果并不能接受,连最基本的tts的要求都没达到
推测原因:
- 训练不够充分
我对训练并不十分理解,不知道怎样算是训练好了的,不知何时结束,且前期训练时,因为种种原因导致训练中断,再次开始时就是重头开始了,最近才知道可以紧接上次的模型继续训练,因此浪费了大量时间。 - 中间某个步骤出错,但是未能发现
训练mellotron
报错1:
AttributeError: Can't pickle local object 'TacotronSTFT.griffin_lim.<locals>.<lambda>'
- 1
在这个文件的validate函数下,改了这个
num_workers=1 --》num_workers=0
pytorch DataLoader num_workers 出现的问题
不知道这么改以后会不会有什么影响
# 因为train在10次epoch后会报错,所以自己改了下
val_loader = DataLoader(valset, sampler=val_sampler, num_workers=0,
shuffle=True, batch_size=batch_size,
pin_memory=False, collate_fn=collate_fn) # shuffle=False,
# val_loader = DataLoader(valset, sampler=val_sampler, num_workers=1,
# shuffle=True, batch_size=batch_size,
# pin_memory=False, collate_fn=collate_fn) # shuffle=False,
- 1
- 2
- 3
- 4
- 5
- 6
- 7
训练:
mellotron_train.py文件下:
# 按需求来,如果是从头开始训练,可以默认这个,如果是接着上次训练,可以相应更改
parser.add_argument('-c', '--checkpoint_path', type=str, default=r"../models/mellotron/samples/checkpoint/mellotron-000000.pt",
help='checkpoint path')
- 1
- 2
- 3
模型保存在此:
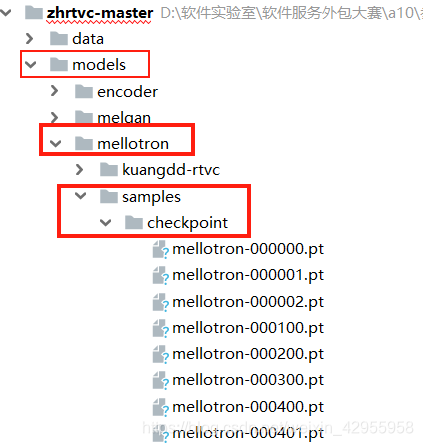
比如,我想用最近的已经训练了一些的模型,就将其改为
# 按需求来,如果是从头开始训练,可以默认这个,如果是接着上次训练,可以相应更改
parser.add_argument('-c', '--checkpoint_path', type=str, default=r"../models/mellotron/samples/checkpoint/mellotron-000401.pt",
help='checkpoint path')
- 1
- 2
- 3
inference:
训练以后我试过,直接在gmw_inference中使用该模型并不能行得通,好像还要经过mellotron_inference.py生成一个文件,生成这种文件:
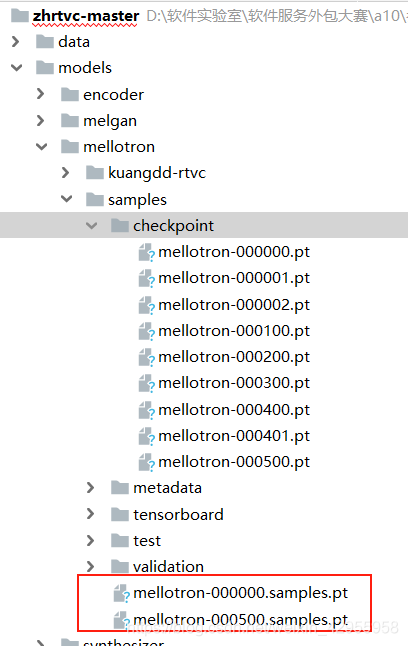
mellotron训练的记录:
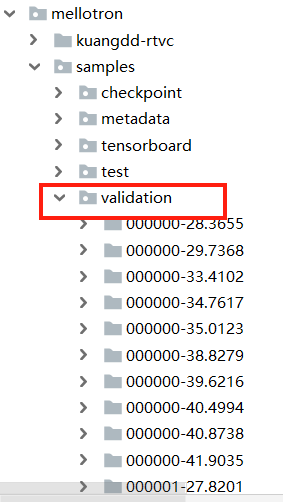
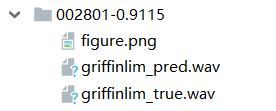
可以根据figure.png、griffinlim_pred和griffinlim_true来判断训练结果
这个loss: 0.9115还是比较大的
推测2800时要降低学习率了,就改了下代码,等待结果吧
训练waveglow
训练的是可以了,但是inference碰到了这个问题:

解决:

将librosa.load()路径变成str了,参考:python librosa.load函数解读
waveglow训练的记录:
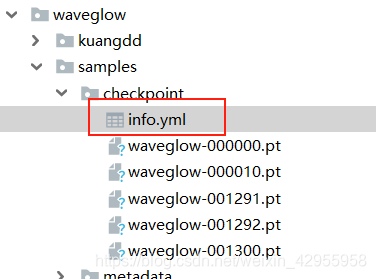
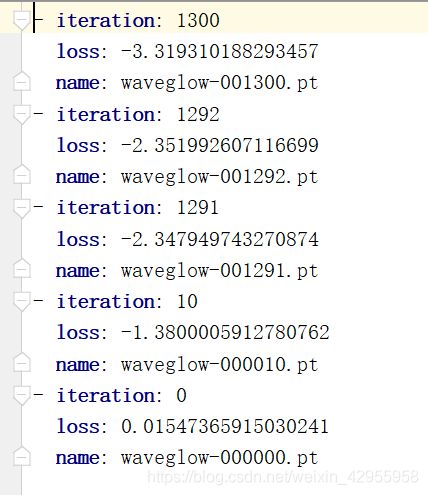
如此看来,这个也许可以接受,着重训练mellotron
gmw_inference
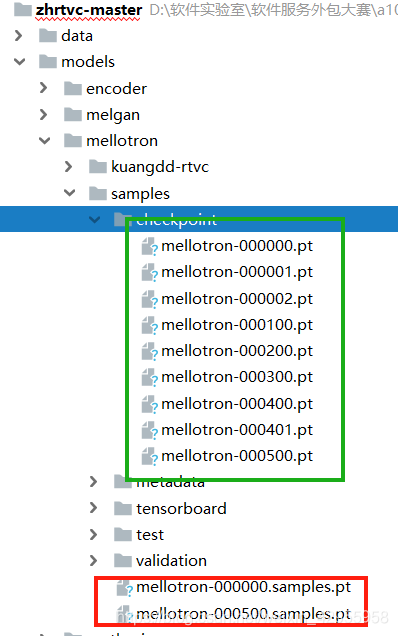
使用的是直接在smaples下的mellotron和waveglow的pt模型,而非是在checkpoint下的pt文件
就是用的是红色的模型文件
总结2
1、speaker为None的时候,就是没有声音的
2、不传speaker会导致模型运行三遍
加载音频的步骤
跟踪音频的变化处理(audio)
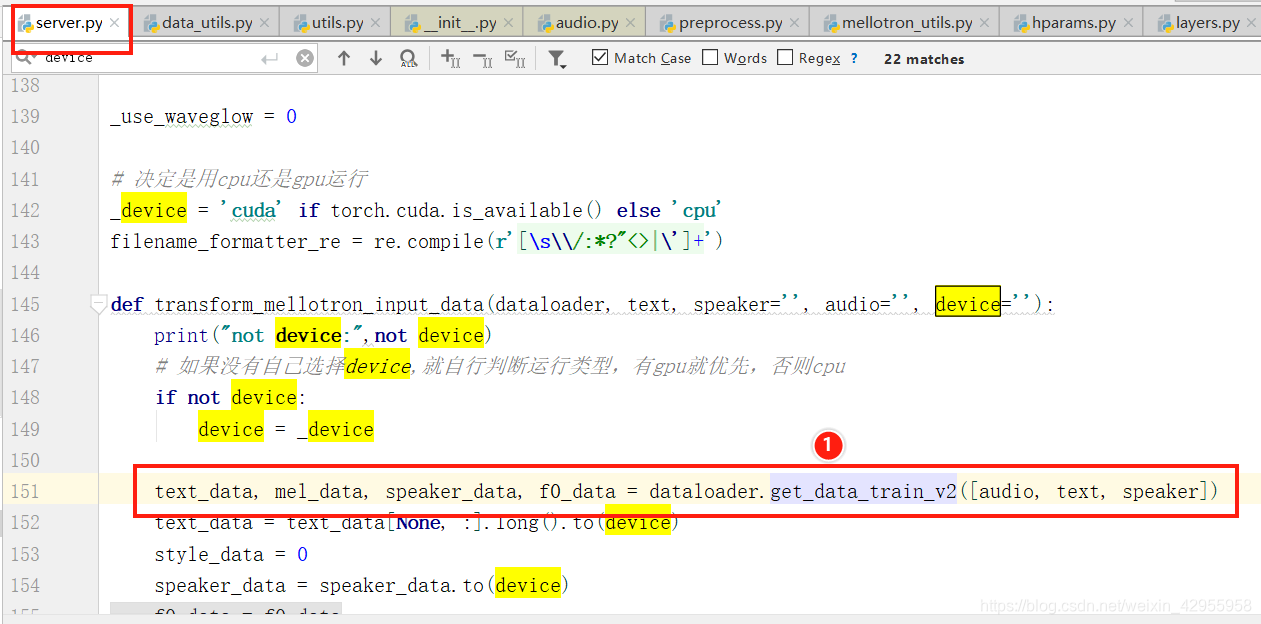
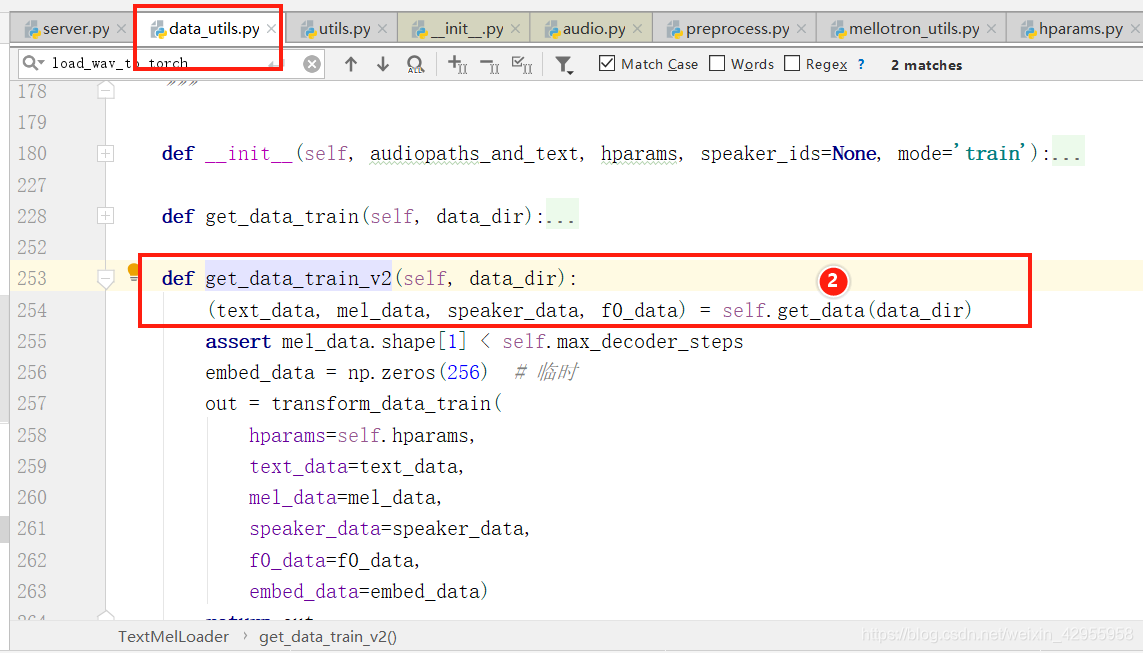
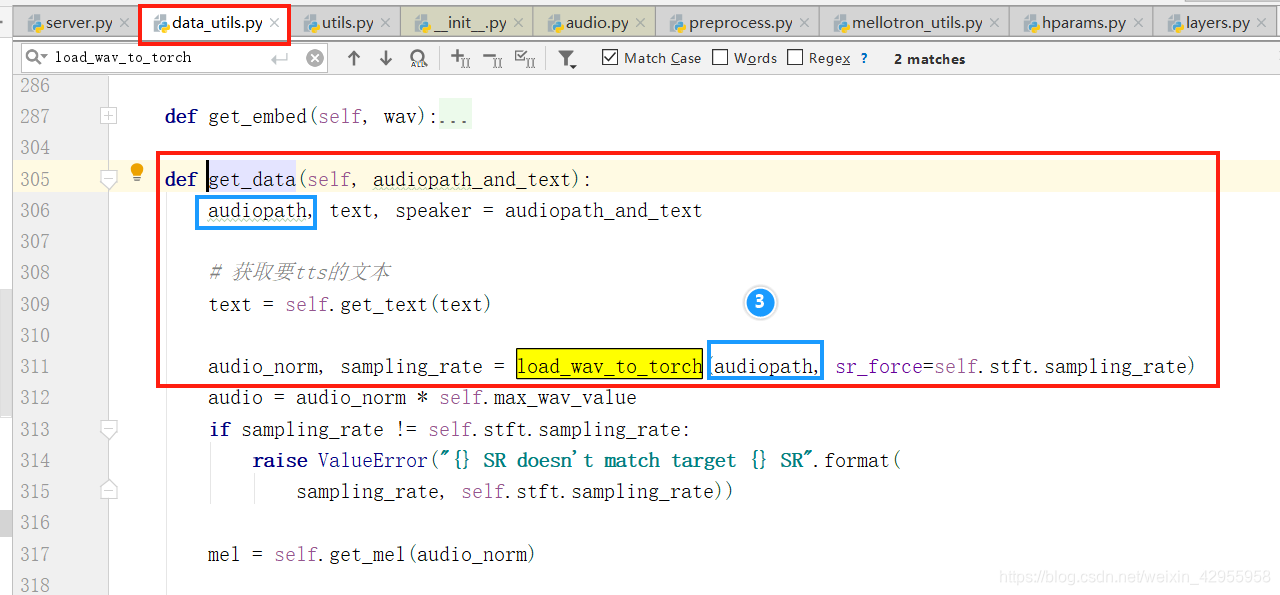
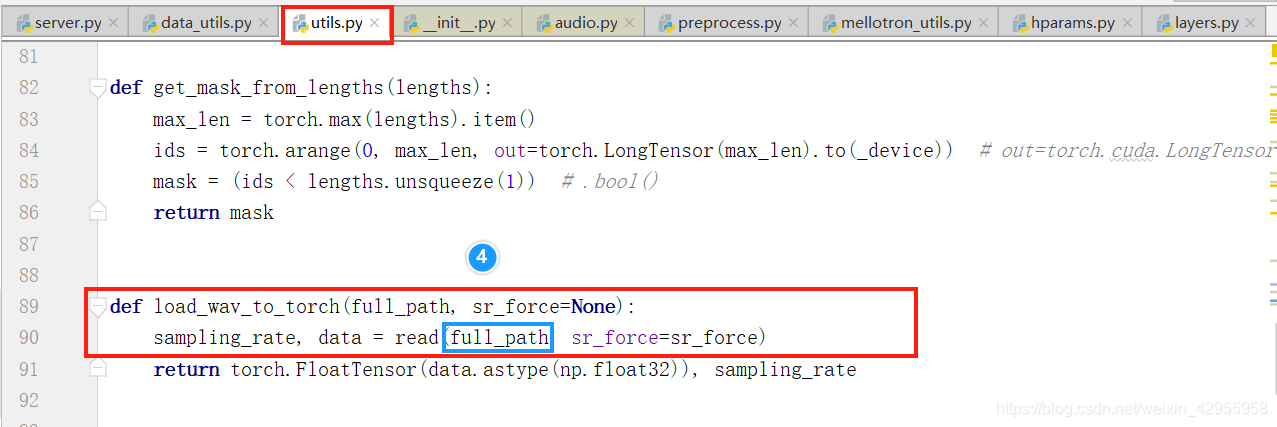
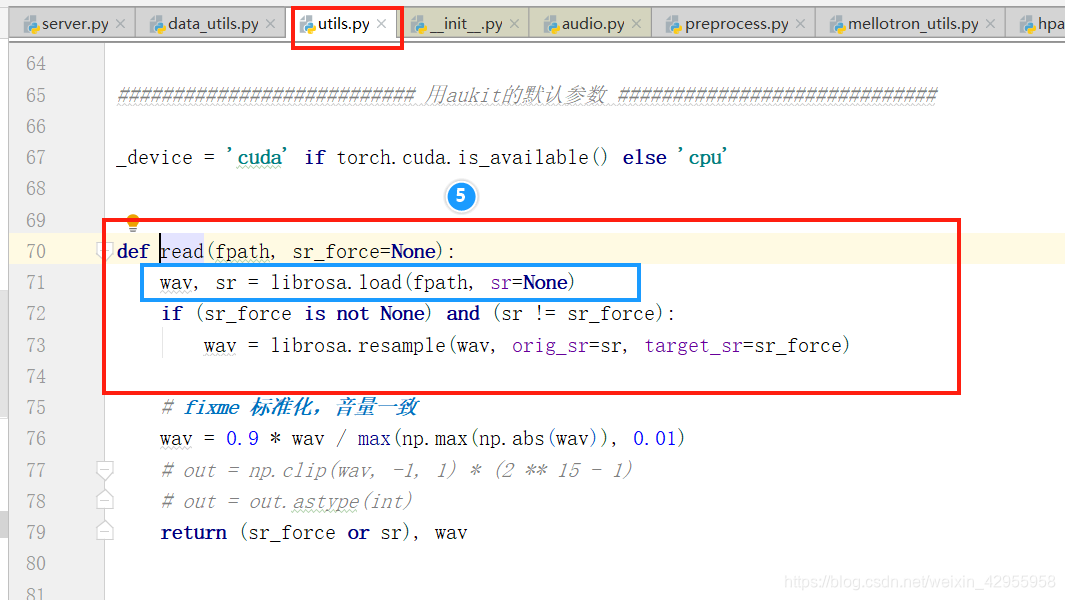
所以音频是在这里调用的
因为要提供接口,现考虑三种方式:
1、提供文件的网络地址(链接),是否可以提取到音频
2、提供文件,保存到本地以后,从本地中去(应该方便实现,但是存储会消耗空间)
3、提供文件,但不保存,直接使用(因为需要的本来就是一个文件,这里就要考虑格式问题,格式处理是也在这里的吗?)
仔细研究
librosa.load方法
python librosa.load函数解读
所以只能选择保存文件以后,然后调用该方法
最后修改:
同一方法分不同请求方式,get用地址去传文件,post直接传文件到接口,但是post最后还是要保存文件,因为底层调用librosa.load,这个方法只支持传地址路径,不支持传文件,且试过,传url地址也不可
主要代码如下:
@app.route('/synthesis', methods=["POST",'GET'])
def synthesis():
if request.method == 'POST':
audioFile = request.files['file']
basepath = r'../data/samples/upload'
if not os.path.exists(basepath):
os.makedirs(basepath)
audio = os.path.join(basepath, secure_filename(audioFile.filename))
audioFile.save(audio)
elif request.method == 'GET':
audio = request.args.get("file")
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
跟踪speaker的变化处理
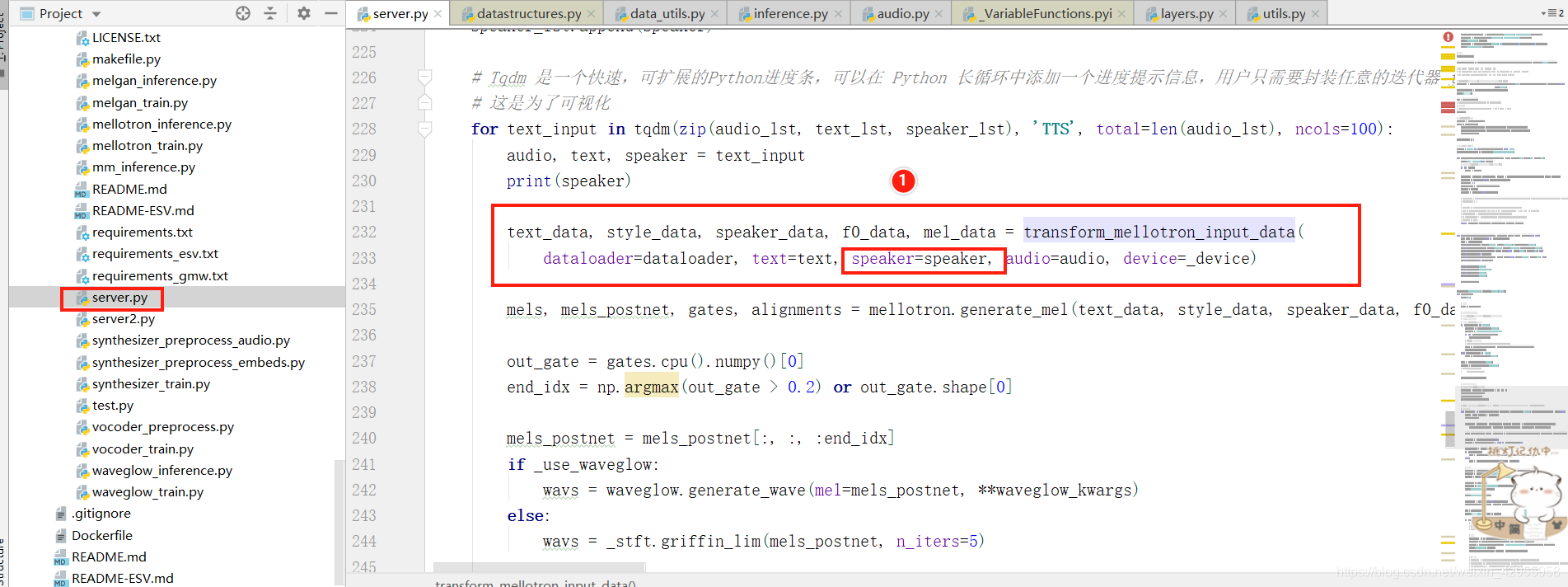
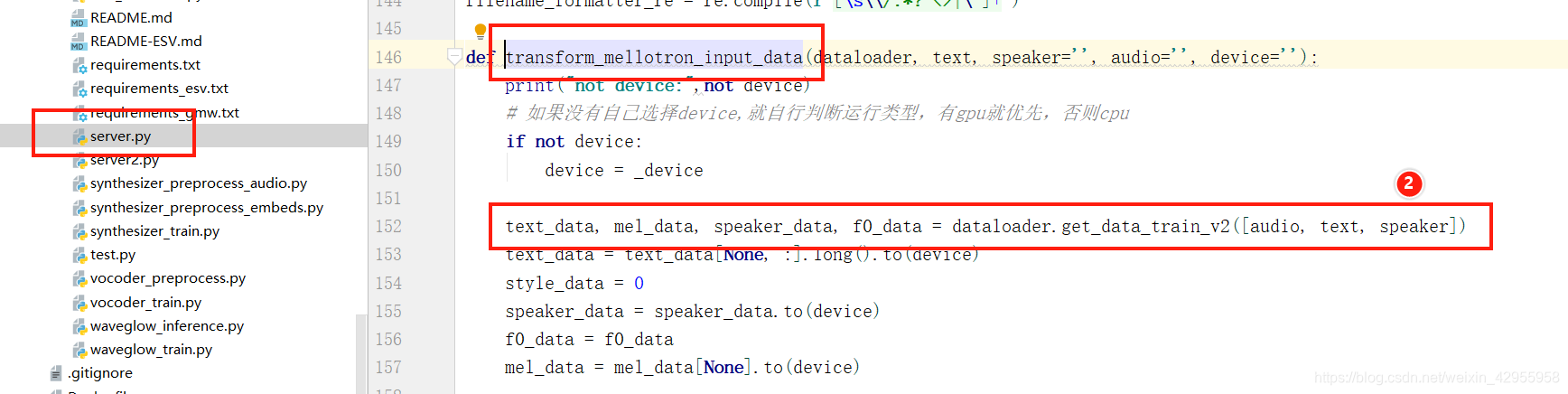
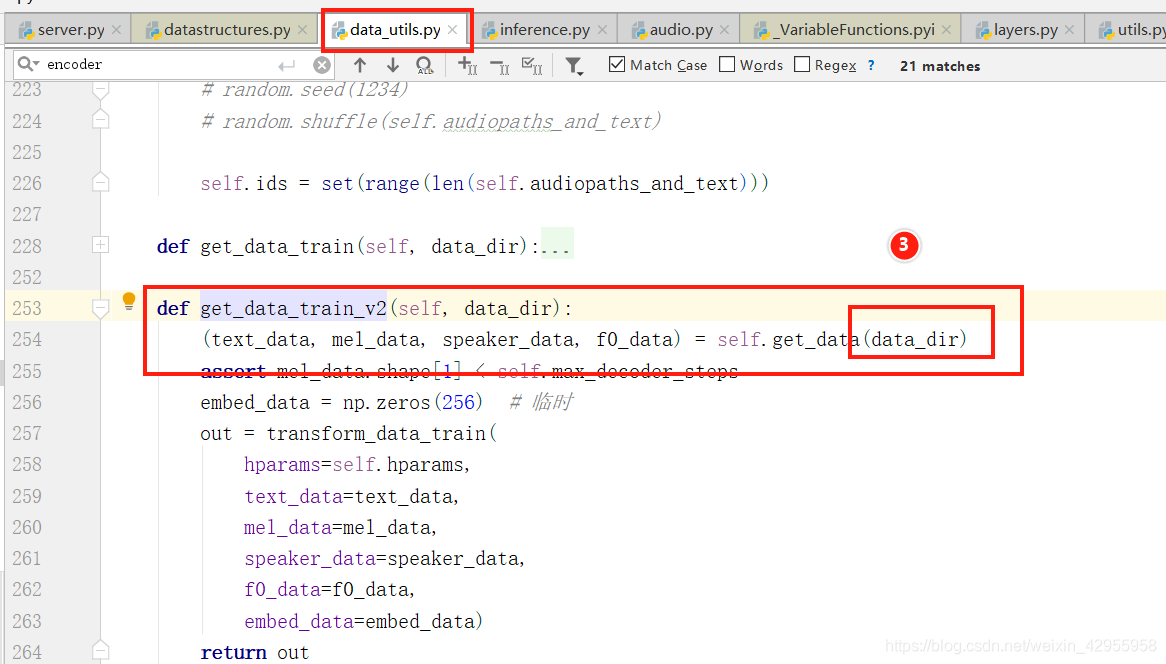
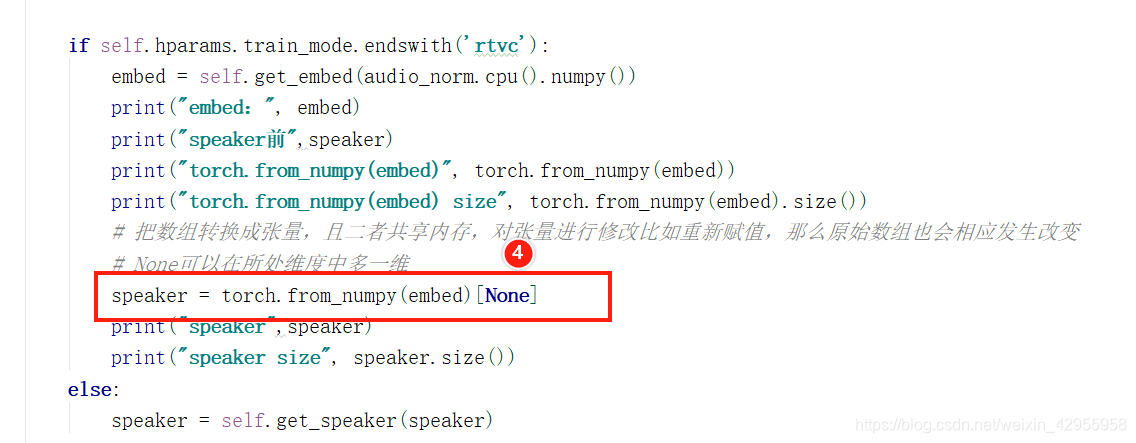
看代码是全程没有用到speaker,所以推测speaker可要可不要
参考:
torch.from_numpy()
pytorch | tensor维度中使用 None
输入不同的speaker,会导致torch.from_numpy(embed)发生变化:




但其实就算是相同的speaker,也是不一样的结果
发现
前期好像是通过gmw_inference合成的效果比自己创建的那个服务器生成的语音效果好一点,可以看看两个代码的差别
如果没安装ffmpeg,librosa就只能处理wav,对mp3没用
audioread.exceptions.NoBackendError in librosa

