
- 1Zookeeper 3.7.0 zookeeper not connected解决方案(低版本也适用)
- 2Evita Full-Medium-Light与SHE差异_medium evita
- 3使用 Spring Native 毫秒级启动 SpringBoot 项目,并且大量减少占用的内存_maven package spring native
- 4C语言:编译和链接
- 5人类语言与人工智能:自然语言处理的挑战与进展
- 6Python入门实例:获取旅游景点的真实评价_旅游网站景点评论数据爬取代码
- 7c++之set插入自定义类型的数据-重载小于运算符_set重载<
- 8AI 助力垃圾分类(百度云API接口+摄像头实现)_百度ai垃圾识别接口
- 9带数字显示的自定义SeekBar_android 中seekbar拖动显示数字
- 10CentOS上升级glibc2.17至glibc2.31_centos7 glibc2.17升级
大模型 Dalle2 学习三部曲(二)clip学习_clip结构
赞
踩
clip论文比较长48页,但是clip模型本身又比较简单,效果又奇好,正所谓大道至简,我们来学习一下clip论文中的一些技巧,可以让我们快速加深对clip模型的理解,以及大模型对推荐带来革命性的变化。
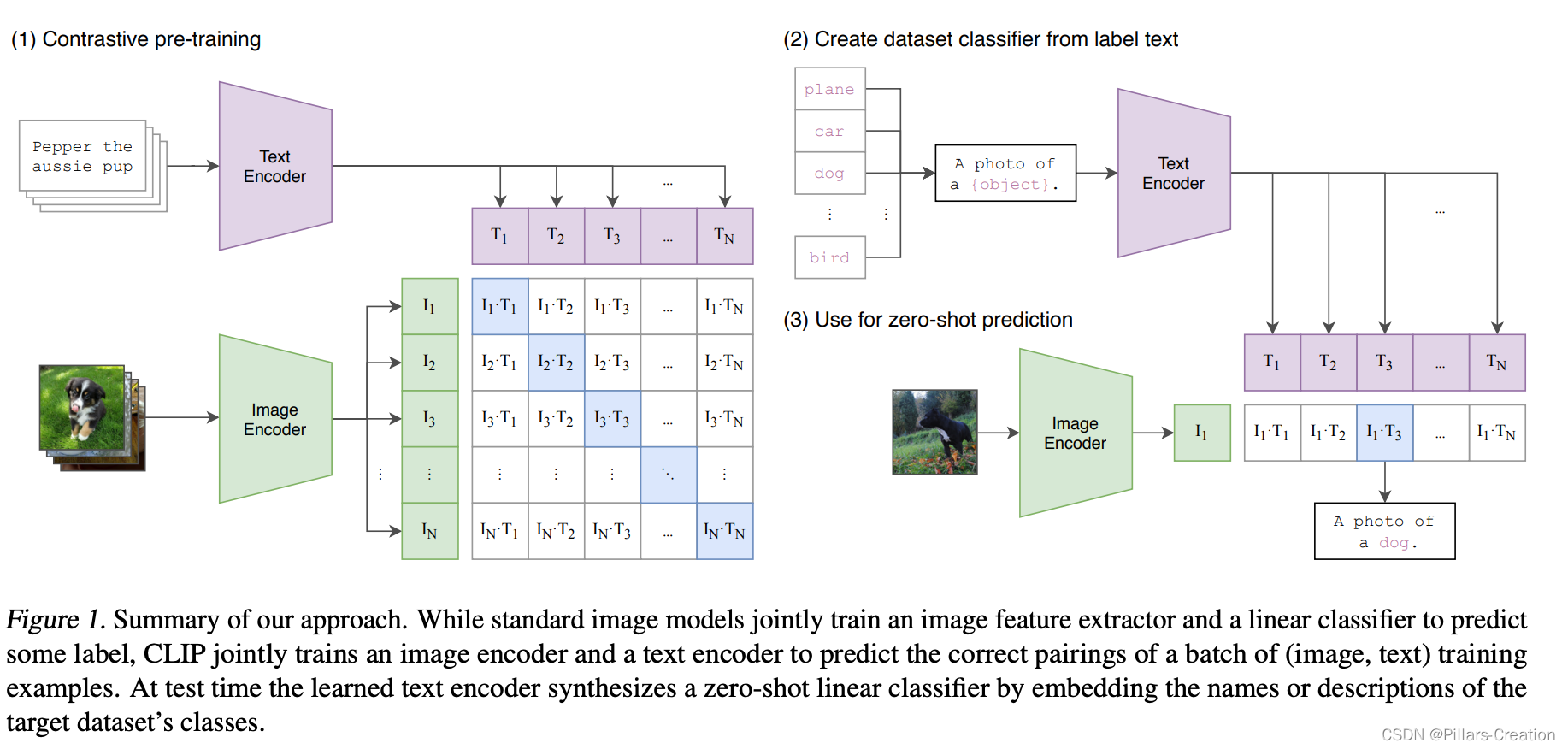
clip结构
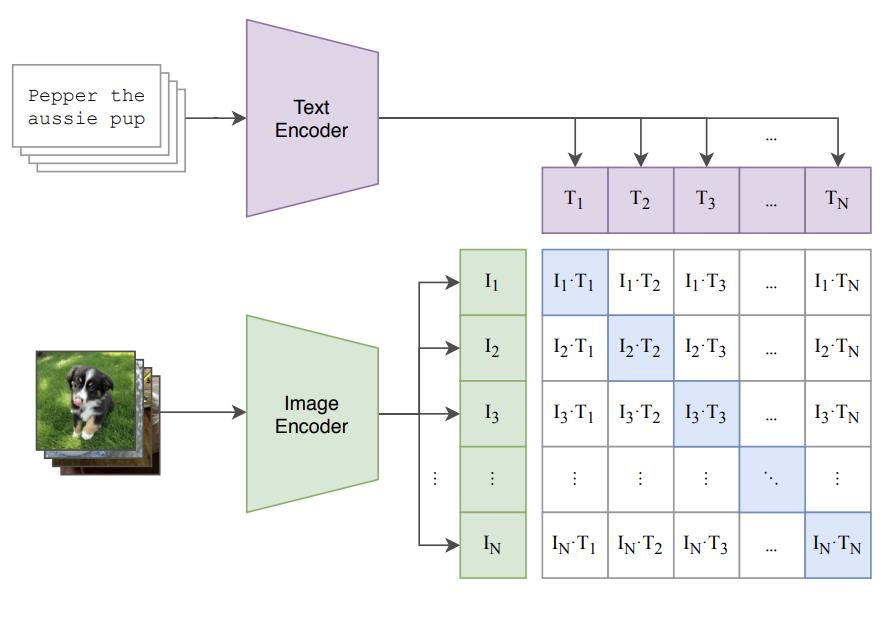
首选我们来看看clip的结构,如图clip结构比较直观,训练的时候把文本描述和图像分别过一个encoder。生成对应的向量,然后向量两两组对,对角线上的都为正样本,不在对角线上的为负样本。然后用个对比学习loss进行训练。
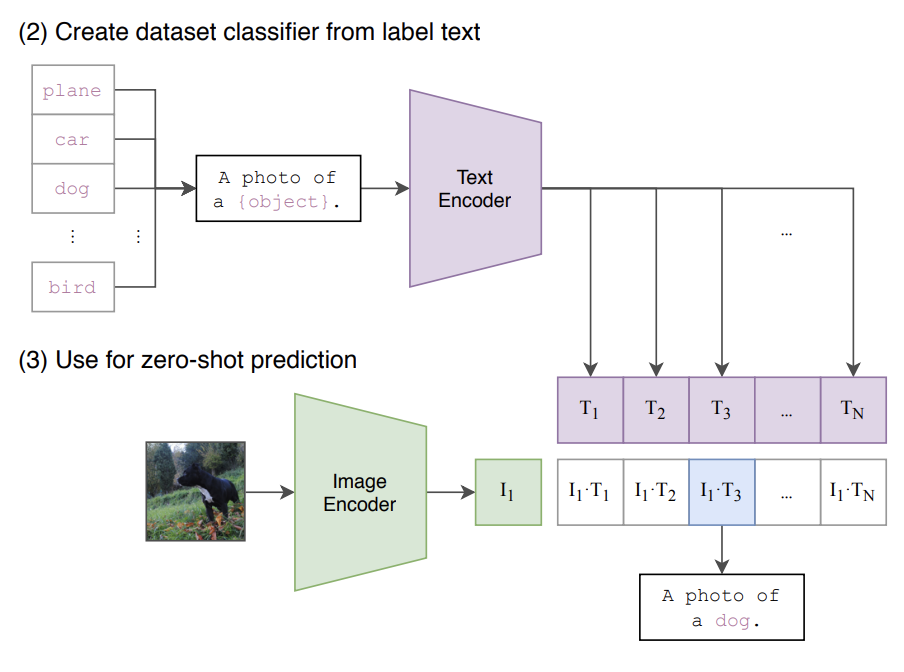
预测:
预测和训练的不同之处,把每个分类结合promote组成句子,然后和训练一样分别过encode,再求出图像和分类相似度最高的一个。后面我们再介绍一下promote 是如何制作的。
论文摘要,引言 要点
1,利用自然语言作为监督来源,提升了模型的通用性和可用性。
clip认为目前需要额外标记数据的监督形式限制了它们的通用性和可用性,因此直接从关于图像的原始文本中学习是一种有前途的替代方法。clip证明,预测标题与哪个图像相配的简单预训练任务是一种高效且可扩展的方式。
2,该模型在大多数任务上都能进行高效的迁移,clip在预训练之后,用于对下游任务的零样本迁移。clip通过在30多个不同的计算机视觉数据集上进行基准测试来研究对比这种方法的性能,涵盖了OCR、视频中的动作识别、地理定位和许多类型的细粒度对象分类等任务。发现通常无需进行任何特定数据集的训练,就能与完全监督的基准模型竞争
3,强调数据的规模的重要性。
clip指出弱监督模型与最近直接从自然语言中学习图像表示的探索之间的关键区别在于规模。在这项工作中,clip弥合了过去模型数据量不足的差距,通过利用互联网上大量可用的这种形式的数据,创建了一个包含4亿(图像,文本)对的新数据集。从而达到了一个从所未有的效果高度。
4, 发现数据规模和迁移能力成平滑正比
clip还通过训练一系列8个模型来验证CLIP的可扩展性,跨越近2个数量级的计算和观察,发现迁移能力和规模成平滑正比
这点非常重要,从而我们可以根据自己模型的大小大致判断迁移后的效果,而不是在等待模型能力的涌现
clip方法和技巧
2.1. 自然语言监督,zero-shot 带来的能力提升
clip方法的核心理念是从自然语言中获得的监督中学习感知。与其他训练方法相比,从自然语言中学习具有几个潜在优势。与标准的基于众包的图像分类标签相比,扩展自然语言监督要容易得多,因为它不需要将精力放在“机器学习兼容格式”中,如规范的1-of-N多数投票“标签”。相反,可以在互联网上大量存在的文本中被动地学习使用自然语言的方法。从自然语言中学习还具有一个重要的优势,即它不仅可以学习表示,而且还可以将该表示与语言联系起来,从而实现灵活的零样本迁移。
2.2. 创建足够大的数据集
clip认为之前类似模型结构之所以没取得效果,主要是因为数据集的规模,所以clip构建了一个新的大数据集,包括从互联网上各种公开来源收集的4亿个(图像,文本)对。为了尝试尽可能涵盖广泛的视觉概念,在构建过程中搜索包含500,000个查询之一的文本的(图像,文本)对通过每个查询包含多达20,000个(图像,文本)对来平衡结果。生成的数据集与用于训练GPT-2的WebText数据集具有相似的总词数。clip将此数据集称为WIT,代表WebImageText。
2.3. 选择高效的预训练方法
- clip发现训练效率是成功扩展自然语言监督的关键。 为了解决训练效率,clip做了以下优化
- clip探索了仅预测哪个文本作为一个整体与哪个图像配对,而不是预测该文本的确切单词。效率提升了三倍
- chip将预测目标替换为对比目标,并观察到在零样本迁移到ImageNet的速率上进一步提高了4倍的效率。
- clip还删除了文本转换函数tu,该函数从文本中均匀抽取一个句子,因为CLIP的预训练数据集中的许多(图像,文本)对只有一个句子。
- clip还简化了图像变换函数tv。在训练期间使用的唯一数据增强是从调整大小的图像中随机裁剪一个正方形。
- 最后,控制softmax中logits范围的温度参数τ,作为对数参数化的乘法标量直接在训练过程中进行优化,以避免将其作为超参数调整。
下图是效率提升对比图(橙色为使用了整体文本,绿色为使用了对比学习loss)

prompt 工程
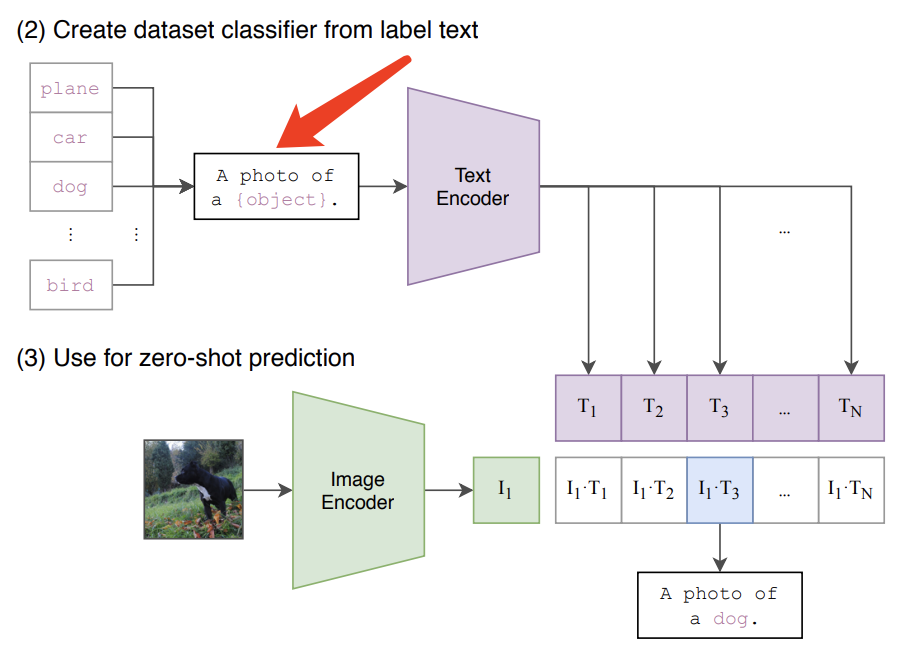
使用prompt的动机
1,解决问题多义性。
当类别的名称是提供给CLIP文本编码器的唯一信息时,由于缺乏上下文,它无法区分是指哪个词义。在某些情况下,同一个词的多个意义可能被包含在同一个数据集的不同类别中!比如在ImageNet数据集中,其中既包含建筑起重机,也包含飞行的鹤。另一个例子是在Oxford-IIIT Pet数据集的类别中,其中单词"boxer"从上下文来看,明显是指一种狗的品种,但对于缺乏上下文的文本编码器来说,它同样可能指的是一种运动员类型。
2,训练和预测一致性,
训练和预测都是一个完整句子。clip遇到的另一个问题是,在clip的预训练数据集中,图像配对的文本通常不只是一个单词,而是一个描述图像的完整句子。为了弥补这种分布差异,clip发现使用提示模板"A photo of a {label}."作为默认值是一个很好的选择,它有助于指定文本与图像内容相关。这通常比仅使用标签文本的基准性能更好。例如,仅使用这个提示,在ImageNet上的准确率提高了1.3%。
使用prompt的一些技巧
1,指定分类。
clip发现,在几个细粒度图像分类数据集上,指定类别有助于提供上下文。例如,在Oxford-IIIT Pets数据集上,使用"A photo of a {label}, a type of pet."来提供上下文效果很好。同样,在Food101上指定一种食物,在FGVC Aircraft上指定一种飞机也有帮助。
2,添加引号。
对于OCR数据集,clip发现在要识别的文本或数字周围加上引号可以提高性能。最后,clip发现在卫星图像分类数据集上,指定图像的形式有所帮助,clip使用了类似于"a satellite photo of a {label}."的变体。
3,使用多个零样本分类器进行集成的方法来提高性能。
这些分类器使用不同的上下文提示,例如"A photo of a big {label}"和"A photo of a small {label}"。clip在嵌入空间而不是概率空间上构建集成。这样,clip可以缓存一组平均的文本嵌入,使得集成的计算成本与使用单个分类器时相同,当在许多预测上进行摊销时。clip观察到,通过对许多生成的零样本分类器进行集成,可以可靠地提高性能,并且在大多数数据集上使用这种方法。在ImageNet上,clip集成了80个不同的上下文提示,这使性能比上面讨论的单个默认提示额外提高了3.5%。综合考虑提示工程和集成,ImageNet的准确率提高了近5%。
添加prompt如下图示意



