
- 1java实现spectrogram函数_梅尔频谱(mel-spectrogram)提取,griffin_lim声码器【python代码分析】...
- 2c语言 统计素数并求和_统计素数并求和c语言
- 3gateway配置动态路由的两种方式_gateway动态修改路由
- 4聊聊几款文件同步备份工具,你更喜欢哪一款呢?_rsync和syncthing
- 5IPA包企业证书签名手动替换_ipa包烧签名好能不能更换文件
- 6CentOS各版本区别(DVD/Everything/Minimal/NetInstall等)_centos7dvd和minimal有什么区别
- 7人工智能最全学习路线_人工智能学习路线
- 8idea配置gradle
- 9使用springboot和vue3以及EasyExcel做导出数据(复用)
- 10unity接入facebook SDK时 警告:“OpenSSL not found. Make sure that OpenSSL is installed_openssl not found make sure
代码智能化应用的通用框架_代码智能助手 产品架构
赞
踩
本文摘自《软件研发效能权威指南》章节内容

魏昭
腾讯研发效能技术专家,代码智能化团队负责人
多年华为、联想智能化工具研发经验,带领团队围绕代码搜索、提交、合并、开源治理等领域孵化多项智能化服务并规模化落地应用,在国内外知名会议、期刊发表学术论文15篇,申请发明专利16项,其中授权9项。
北京航空航天大学计算机学院博士,联想集团和中科院计算所联合培养博士后。
主笔章节:《代码智能化工具》

代码智能化工具主要采用了代码静态分析、编译器的前端技术,并与AI结合,它是一种AI辅助的代码智能化分析工具。
代码智能化应用不同于计算机视觉、自然语言处理等领域中的AI应用,它需要考虑代码特有的语法和语义特征,包括AST、定义-引用关系、函数调用关系、控制流、数据流等。
代码智能化工具在代码开发、提交和同步入库等研发的各个环节都有重要价值。
智能语言服务通用框架SLSCF是在实践的基础上提出的,通过前端、中端、后端三部分的协作完成代码智能化实现。
1代码智能化工具概述
智能化研发是当前研发效能领域的前沿话题。它贯穿了代码开发、代码提交和代码同步入库等各个环节,我们探索了各个环节可落地的代码智能化工具,总结了一些较为通用的代码智能化实践方法,并进一步提出了代码智能化应用的通用框架,即智能语言服务通用框架SLSCF(Smart Language Service Common Framework),其包含SLS-font end、SLS-middle end和SLS-back end。从当前代码智能化落地应用的实践来看,智能化工具主要采用了代码静态分析、编译器的前端技术,基于启发式规则和AI模型,而不是纯AI技术,因此它是一种AI辅助的代码智能化分析工具。
2代码智能化工具的价值
代码智能化工具在研发的各个环节都发挥了很大的价值。在代码开发环节,代码补全和生成增强开发的生产率,代码搜索和导航可以辅助开发人员快速检索代码范例,并帮忙他们深度理解代码,从而提高代码开发的效率;在代码提交环节,提交消息的自动生成节约了开发人员撰写的时间,且自动生成的规范化、语义清晰地提交消息更有利于后期的代码评审和维护;在代码同步入库环节,自动、智能的冲突消解代替人工消解大大提高了消解的准确性和效率。下面针对以上三个开发环节和场景,分别阐述智能化工具的价值和意义。
在代码开发环节,代码搜索是开发人员使用频率较高的一项活动,大部分开发人员都使用代码搜索检索API的使用范例。例如,开发人员查找JDT中ASTVisitor类的visit函数的调用。另外,在阅读代码的过程中,开发人员也需要代码导航来及时找到函数、变量的定义与其引用的位置,类的定义、初始化、使用和销毁的位置,并在这些位置之间来回切换,从而更好地掌握源代码的运行规律,进而熟悉项目的整体结构。当然,符号的定义和引用的查找对评审人评审代码也很有价值,因此代码导航也常用于代码评审环节。
而传统的通用搜索引擎因没有考虑代码特征而不能满足以上需求,亟须智能化的代码搜索和导航辅助开发人员和评审人员精准地检索代码,深入地理解代码结构,并最大限度地复用高质量的代码,从而提升代码开发、评审的效率。
在代码提交环节,开发人员写完代码后,需要为本次代码撰写提交消息(Commit Message)。从用户调研的结果来看,很多开发人员对撰写提交消息感到苦恼,甚至抓耳挠腮,不知道如何描述此次提交,费时费力。而且大多数开发人员撰写的提交消息不规范,语义含混不清,不能正确表达此次代码变更的行为和目的,不利于代码的评审,也不利于维护阶段的回归测试和代码拣选等操作。因此,亟须智能化的提交消息生成辅助工具,以帮助用户撰写高质量的提交消息,解决开发人员因撰写提交信息而感到苦恼的问题,也为后期的代码评审和维护带来了方便。
在代码提交环节,开发人员需要将代码从本地合入远程仓库。当前的软件开发大多数都是协同式的多人开发,在协同开发场景下,开发人员经常采用基于Git的分支管理模式。例如,企业内部开发常常将分支划分为个人分支、特性分支、修复分支、发布分支和主干分支等,特性分支会根据版本节奏定期合入主干分支,若特性分支演进的周期较长,其和主干分支的差异将会较大,合入主干分支时常常会产生大量的冲突。
另外,针对开源的定制化开发,产品在发版之前常常需要同步外部开源社区的主干分支,由于内部定制化的开发和外部开源分支都在往前演进,演进周期越长,其差异越大,长周期后的合并常常会带来大量的冲突。例如,Android的定制化开发版本和社区Android版本的同步往往产生大量的冲突。
这是因为当前基于Git的版本管理采用的是基于文本的合并方式,其合并单位是代码行或者字符。在Git的合并过程中,因不能理解代码变更双方的行为语义,导致Git的合并产生了大量冲突。
开发人员常常采用KDiff3、Beyond Compare等Diff工具来查看代码变更双方的差异,进而理解代码变更的意图,最终决定消解的方法。因人工方式消解代码费时费力,且代码意图理解过程常常因代码位置调换、格式变换、代码重构等导致出现误差,因此亟须智能化的代码版本合并、冲突消解工具来辅助解决人工消解的不准确性和效率低下的问题。
3代码智能化工具的实现与案例
代码开发环节
在代码的补全和生成领域中,如IDE自带的基于语法上下文的补全,微软和OpenAI联合推出的基于自然语言描述生成代码的GitHub Copilot工具。GitHub Copilot在生成工具类函数、日志、配置文件、有规律的表达式方面有较好的表现效果,但缺点是没有规律,或稍微复杂的业务逻辑代码生成效果不太好,验证这些代码耗时且会带来认知负担。但总体来讲,GitHub Copilot在一定程度上都能辅助提高开发效率。
在代码搜索和导航领域中,Google在2015FSE上发表了代码搜索用户调研报告,该报告主要调研了Google内部的开发人员使用代码搜索的目的和意图,总结起来主要是检索代码范例、浏览并阅读代码、获取错误信息的解决方法等。本节主要阐述在开发环节中的代码智能搜索和导航应用。
Google代码搜索除提供传统的代码字符串的检索功能外,也提供了代码精细化的检索功能,包括基于函数、类、注释,基于用法(排除代码中的注释和字面量),基于文件、大小写敏感等,还提供了“与、或”组合符来组合这些特征达到精细化检索的目的。例如,开发人员想要检索"name"函数的实现,若采用传统的字符串检索方式,其结果如图10.8.1所示,存在包名、变量等符号,这些对开发人员有很大的干扰。
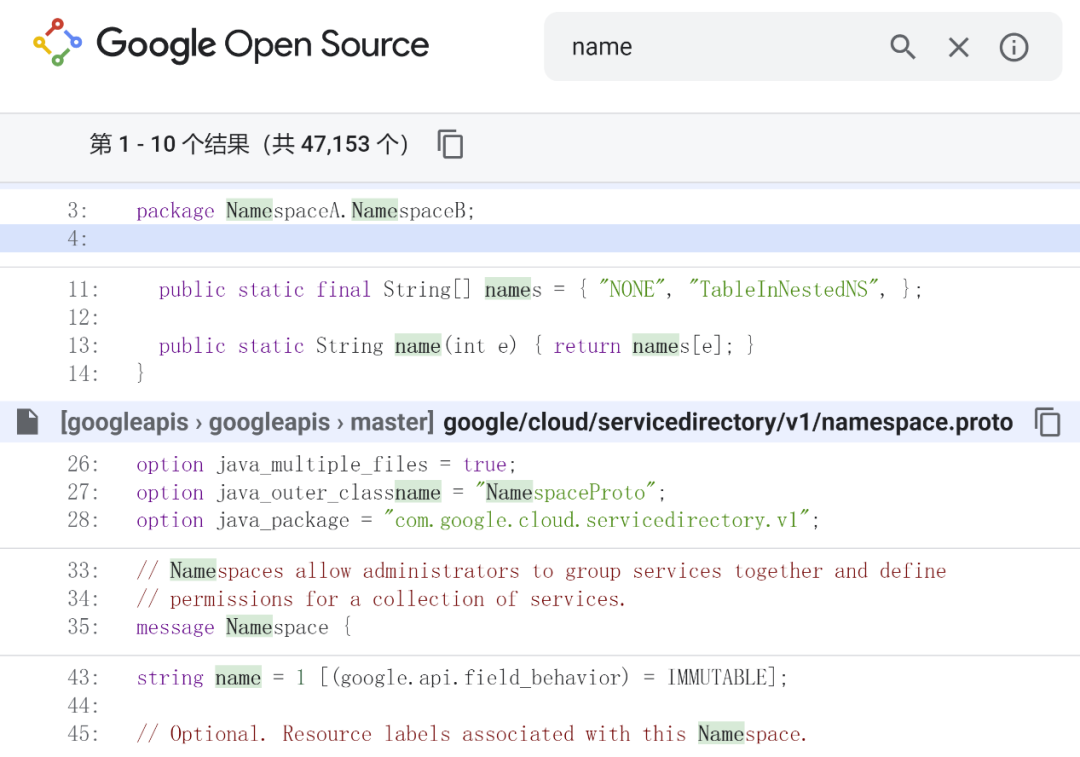
图10.8.1 传统的代码字符串检索
而采用精细化检索,限定只检索符号为"name"的函数,且是Java语言,如图10.8.2所示,其检索结果仅仅包含函数。因此,代码精细化检索能极大地提高开发人员检索的效率。

图10.8.2 针对函数的代码精细化检索
另外,Google代码搜索还提供了代码定义、引用的跳转功能辅助开发人员理解代码,该功能也被称为代码导航,也是专业级代码搜索公司SourceGraph关注的焦点。SourceGraph因其代码导航能力的强大,在业界被称为代码界的Google。代码导航是当鼠标悬停在代码中的程序单位时,比如函数、类、接口、变量等,能及时地引导用户在代码的定义和代码的引用位置进行快速切换和跳转,包括代码仓内和仓外。
基于业界的实现工具,以及我们在代码智能搜索方面的落地实践经验,其代码精细化检索的通用实现方法为首先对代码进行语法分析构建AST(Abstract Syntax Tree),然后提取代码中的类、接口、函数、变量、注释等代码特征,最后建立这些代码特征的索引并进行存储,供前端调用。
代码智能导航的通用实现方法为首先对代码进行语法分析、语义分析(可采用编译器的前端技术或者Antlr、Tree-Sitter等Parser实现),提取代码特征,包括类、接口、函数、变量等,并进行调用者符号类型推断,构建整个项目中较为精准的定义、引用关系图,该图可采用与代码结构无关的语言表达,如SourceGraph在微软LSP(Language Server Protocol)的基础上提出的LSIF(Language Server Index Format)、Google提出的Kythe等。然后提取图中的定义、引用关系,建立索引并进行存储,供前端调用。索引的建立和存储推荐使用ES(Elasticsearch),因为其分片机制提供了很好的分布式特性、良好的可扩展性和高可用性,以及在工业界优良的表现。
图10.8.3是来自开源流处理框架Apache Flink中函数跨仓调用的代码导航实例。
图的左边是DeveloperZJQ/learning-flink仓在14行调用了右边apache/flink仓StreamExecution Environment类中的函数:publicDataStreamSource<String>socketTextStream(Stringhostname, intport)。当鼠标放置在socketTextStream函数时,会自动检索后台预先建立的引用、定义索引,点击弹出的定义片段即可快速跳转到该函数定义的位置。

图10.8.3 跨仓代码导航
代码提交环节
在代码提交环节,需要撰写提交消息(Commit Message)。基于2019年Google工程实践文档对规范化的提交消息的解释,一个高质量的提交消息需要描述本次提交变更的内容和原因,包含摘要、详细描述和外部资源。
摘要包含类别和总结语句两部分。类别包含补丁修复(Fix)、新特性(Feature)、特性优化(Optimization)、重构(Refactor)、格式化(Reformat)、测试(Test)、其他(Chore);总结语句需要保持简短、清晰、切题,格式上一般放在第一行,不超过80个字符,紧接着空一行。
详细描述包含问题、已实现的方案、本次提交的方案、本方案可能带来的影响。已实现的方案和本次提交的方案由具体的详细实现内容和目的组成,可以表示成Do…For…的格式。
外部资源表示本次提交关联的其他资源,一般要求提供需求管理系统中的需求单号或者缺陷管理系统中的问题单号,目的是为将来的开发者或者评审人员提供详细的上下文信息,保障Commit的追本溯源。
提交消息的自动生成需要理解代码的变更行为和意图,学术界提出了基于Seq2Seq的Commit摘要生成方法,一般是将代码当作文本处理或者考虑代码变更的AST信息,但生成的提交消息存在难以阅读或理解的情况,离工业落地还有一段距离。
ChangeScribe是工业落地的一个提交消息自动生成工具,是Eclipse的插件,基于模板和Chage Distiller提取的细粒度代码变更行为来生成消息描述,但缺点是不能明确地得到提交消息的类别,也不能识别重构类的变更行为。
基于业界的工具,以及我们在提交消息自动生成的落地实践方案,一般较为可行的通用方法是定制化的提交消息模板和自动化生成相结合的方式。例如,将上文所表述的高质量提交消息包含的摘要、详细描述、外部资源作为模板。针对摘要部分,其自动化的生成方法的描述如下:
针对摘要中的类别自动识别,首先提取本次提交的代码变更行为特征,并基于启发式的规则识别类别是否是格式的变换(Reformat)、代码的重构(Refactor)、测试(Test)、补丁修复(Fix)、新特性(Feature)和其他(Chore)等。当启发式规则不能覆盖以上类别时,再考虑基于AI预测的方式来识别类别。
基于AI的类别识别,首先选择符合Angular提交规范的开源仓进行学习;然后进行代码特征提取,该过程将提取代码变更的行为特征,代码变更的文件数、变更代码块、代码行数等的统计特征,以及变更前后的代码Token特征,基于以上三类特征训练类别预测器。
摘要中的总结语句将汇总代码变更行为中包、类、函数、变量等的代码行为变化,输出描述信息。而详细描述部分直接采用类、函数、语句等细粒度的变更行为描述。
以开源流处理框架Apache Flink中的某个提交“44fc8c”为例,其部分代码变更片段如图10.8.4所示,移动了类SlotProfile中的一些函数,并将其提炼到类SlotProfileTestingUtils中,如图10.8.5所示。


图10.8.4 重构前类SlotProfile中的代码片段

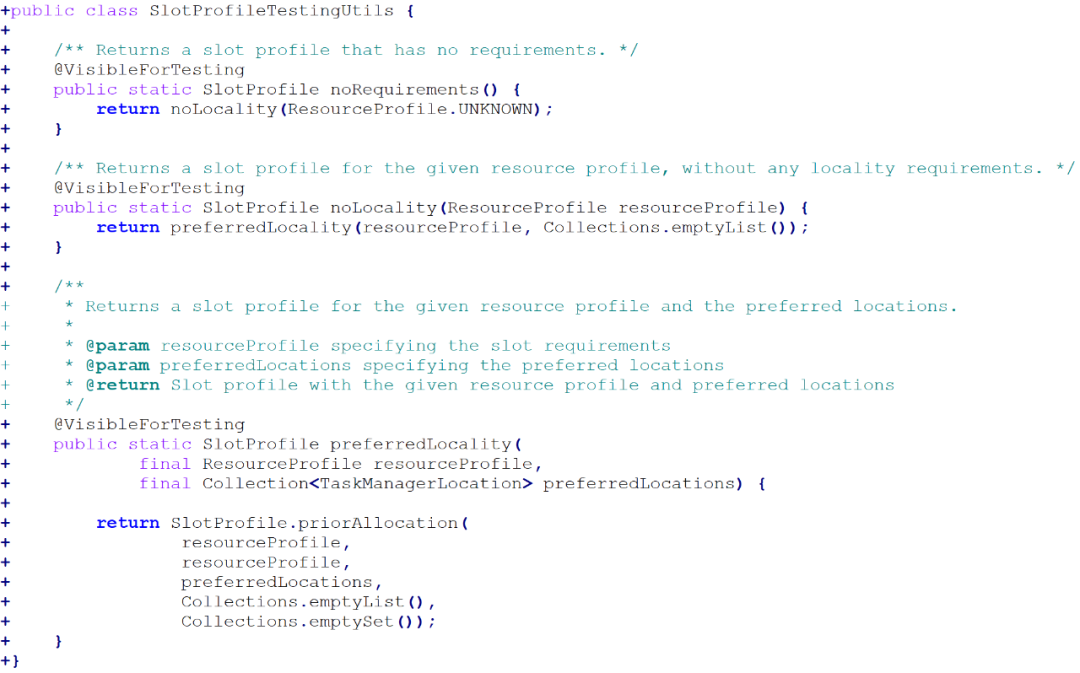
图10.8.5 重构后类SlotProfileTestingUtils中的代码片段
首先采用RefactorMinner重构检测工具,检测到该提交包含了重构动作,因此提交的类别为重构(Refactor);然后将RefactorMinner提取的代码变更行为作为提交的详细描述部分;最后汇总RefactoringMiner生成的重构行为,得出摘要中的总结语句为“Move Method and Extract Class”。以上Apache Flink中的提交“44fc8c”生成的提交消息如下所示:
Summary:(Refactor)Move Method and Extract Class
Detail:
Extract Class SlotProfileTestingUtils from SlotProfile;
Move Method public noRequirements()from class SlotProfile to class SlotProfileTestingUtils;
Move Method public noLocality(resourceProfile ResourceProfile)from class SlotProfile to class SlotProfileTestingUtils;
MoveMethod public preferredLocality(resourceProfile ResourceProfile, preferredLocations Collection<TaskManagerLocation>)from class SlotProfile to class SlotProfileTestingUtils;
External Resource: issue number/requirement number
代码同步入库环节
代码在同步入库环节会进行版本合并,当前一般采用主流的基于Git的版本合并工具。但该工具因采用了基于文本的合并策略,在合并的过程中不能理解代码变更双方的行为语义,导致Git的合并会产生大量冲突,这些冲突块如图10.8.6所示(图10.8.6、图10.8.7和图10.8.8的冲突块均来自于开源流处理框架Apache Flink,这些冲突块是在合入主干的过程中产生的,我们将其冲突现场进行了还原)。它包含冲突块的标识符“<<<<<<<*|||||||*======= *>>>>>>>”。我们将“<<<<<<<”到“|||||||”之间的代码块称为Ours版本,“|||||||”到“=======”之间的代码块称为Base版本,“=======”到“>>>>>>>”之间的代码块称为Theirs版本,所以一个冲突块包含三个版本的代码块。说明:使用命令git config --global merge.conflictstyle diff3才能看到合并的共同祖先,即Base版本。
因为图10.8.6中冲突块的三个版本包含三种测试方案,表示三种不同的行为语义,所以该冲突块是一个真实的语义冲突块,无法消解。但图10.8.7中的冲突块,Base为空,Ours基于Base增加了import语句*PactModule,Theirs基于Base增加了三个import语句*EvaluationContext、*Sink、*Source。图10.8.8中的冲突块,Ours基于Base/Theirs单方增加了变量schemaFactory的修饰符final,Theirs基于Base/Ours单方增加了变量packageLocations定义语句。从以上两个冲突块的行为语义分析可以得出它们是没有语义冲突的,所以图10.8.7和图10.8.8中的冲突块是完全可以消解的。

图10.8.6 冲突块

图10.8.7 Base为空的冲突块

图10.8.8 Field字段的冲突块
SemanticMerge是一款基于语义分析的代码合并工具。它能理解冲突块中三个版本的代码语义,特别是能识别类中函数移动这种重构场景的行为语义,但缺点是没有分析函数体内细粒度的变更行为语义。与Git Merge中基于文本的合并方式对比,其合并准确度提高很多,图10.8.9是SemanticMerge对import语句进行的语义合并。
基于业界的工具,以及我们在代码版本智能合并、冲突消解的落地实践方案,一般认为较为可行的代码版本合并、冲突消解的智能化通用方法描述如下:
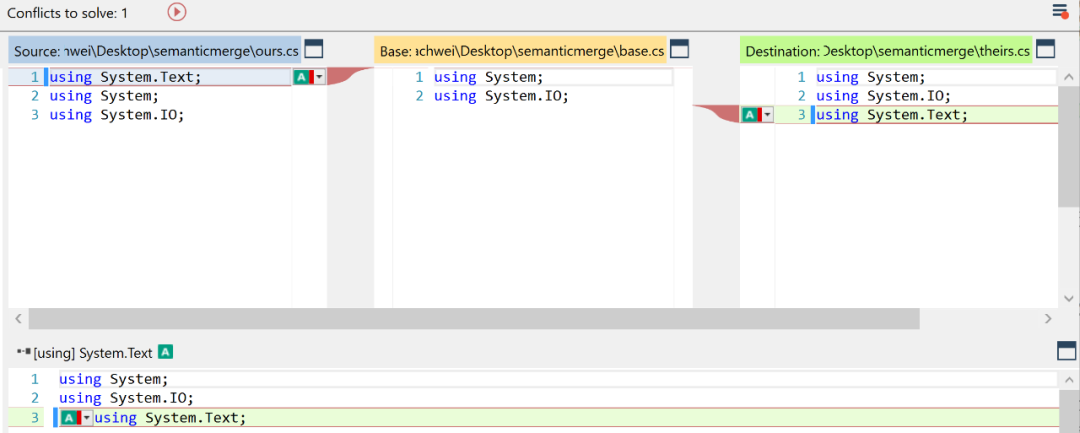
图10.8.9 SemanticMegre合并的import语句
首先是对冲突块的三个版本进行代码语义理解并提取其代码变更行为,然后基于启发式的语义消解规则进行冲突消解;在语义消解规则不能覆盖的情况下,再考虑基于AI的方式预测冲突消解策略。
基于AI的冲突消解策略预测,一般优选冲突较多的开源仓进行学习。首先找到开源仓主干分支上标识为Merge且是人工消解冲突的Commit,得到该Merge Commit的两个源Commit;然后通过再次合并两个源Commit来制造冲突现场;最后建立冲突块和人工消解结果之间的关系,形成冲突消解标注数据集;最终通过多分类模型的训练生成冲突消解策略预测器。
冲突消解的最终结果也需要人工确认,并对每种消解规则包括AI消解规则进行打分形成反馈,从而跟踪消解的准确性。
针对图10.8.7中的冲突块,经过代码语义理解后的代码变更行为为Base为空,Ours基于Base增加了import语句*PactModule,Theirs基于Base增加了三个import语句*EvaluationContext、*Sink、*Source,故最终将合并Ours和Theirs的变更行为。其自动消解结果如图10.8.10所示:

图10.8.10 Base为空的冲突消解结果
针对图10.8.8中的冲突块,经过代码语义理解后的代码变更行为为Ours基于Base/Theirs单方增加了变量schemaFactory的修饰符final,Theirs基于Base/Ours单方增加了变量packageLocations定义的语句,故最终将合并两个行为的变更。其消解结果如图10.8.11所示:

图10.8.11 Field字段冲突的消解结果
针对以上代码开发、提交、同步入库等各个环节中存在的痛点,结合我们的落地实践经验,分析了智能化如何应用在代码开发的各个环节并形成较为通用、可落地的代码智能化实践方法。基于这些实践方法,我们提出了代码智能化应用的通用框架,称为SLSCF(Smart Language Service Common Framework,智能语言服务通用框架),SLSCF包含SLS-font end(智能语言服务前端)、SLS-middle end(智能语言服务中端)和SLS-back end(智能语言服务后端),如图10.8.12所示:

图10.8.12 智能语言服务通用框架
SLS-font end:根据不同的智能化业务场景,打通前端(如Chrome、IDEA、VSCode等)和业务相关的服务,其交互过程遵循微软提出的LSP规范。
SLS-middle end:根据不同的智能化业务调用数据存储服务Data Server中的模型(基于AI的推断和预测)、ES索引、关系型和非关系型数据库中的规则或知识等,满足不同业务场景的需求。
SLS-back end:通过分析源代码,根据各种编程语言Compiler产生的符号表、AST、IR或者各种编程语言Parser构建的AST等(其中tree-sitter可以快速构建各种编程语言的AST),提取代码特征中的Def-Use依赖关系、CFG、DFG等,采用统一的与编程语言无关的通用结构化代码表达PLI-CSCR(Programming Language-Independent Common Structured Code Representation)来表示这些代码特征,并兼容已有的LSIF、Kythe等代码特征表示方法。最后基于代码的结构化表达,构造训练数据集进行模型训练,或者建立索引,生成规则或知识,并持久化存储在Data Server中。
会议介绍
CONFERENCE INTRODUCTION
QECon全球软件质量&效能大会自办会以来,始终将质量、效能与每一位软件从业人员紧密连接在一起,追寻“提质增效”的最佳实践,坚持“一线技术与工程实践输出”。面向5年以上丰富经验的“实践者”分享具有指导价值的前沿、落地案例,和更多的研发团队进行思想的碰撞与经验的交流。

