
- 1android studio构建项目报错Could not create an instance of type com.android.build.api.variant.impl.Applicat
- 2论文精读|ResNet网络详解
- 3Qt5.9.8在Ubuntu16.04下的配置(二)—Xshell,VNC远程打开Qt问题_qtcteator远程加载 failed to initialize xrandr 已放弃 (核心已
- 4Unity2021接入讯飞语音听写(Android)_unity 语音听写 (流式版)
- 5LLM参数高效微调(LORA,QLORA)
- 6C 语言编程 — 程序汇编原理_汇编b c_main_secondary
- 7k8s与pod概念_宿主机 节点 pod
- 8VS2022 的 MFC 安装之 Hello World ---- IT笔记之1_vs2022 mfc
- 9阿里云DataWorks数据治理实践
- 10gradle插件与gradle版本对应表_com.android.tools.build:gradle:4.0.1选什么版本号
【NLP系列2】基于TF-IDF、TextRank的关键词提取_基于textrank算法的文本摘要抽取与关键词抽取,基于tfidf算法的关键词抽取。
赞
踩
对于文本的关键词提取方式:
1、基于 TF-IDF 算法的关键词抽取
(1)基本思想:
用更合理的方式体现词在文本中的权重(缺点:词在文档中的顺序没有体现)。
TF-IDF = TF*IDF
词频(term frequency,TF)指的是某一个给定的词语在该文件中出现的频率。这个数字是对词数的归一化,以防止它偏向长的文件。(同一个词语在长文件里可能会比短文件有更高的词数,而不管该词语重要与否。)
 上式分子是该词在文件中的出现次数,而分母则是在文件中所有字词的出现次数之和。
上式分子是该词在文件中的出现次数,而分母则是在文件中所有字词的出现次数之和。
逆向文件频率(inverse document frequency,IDF)是一个词语普遍重要性的度量。是指总文件数目除以包含该词语之文件的数目,再将得到的商取加上有1,取10为底的对数得到: N表示文档的总数量;nt表示含有词t的文档数。
N表示文档的总数量;nt表示含有词t的文档数。
(2)参数
import jieba.analyse
jieba.analyse.extract_tags(sentence, topK=20, withWeight=False, allowPOS=())
sentence 为待提取的文本
topK 为返回几个 TF/IDF 权重最大的关键词,默认值为 20
withWeight 为是否一并返回关键词权重值,默认值为 False
allowPOS 仅包括指定词性的词,默认值为空,即不筛选
- 1
- 2
- 3
- 4
- 5
- 6
(3)案例:
df =pd.read_csv('data/technology_news.csv',encoding='utf-8') #导入数据,window系统ecoding参数默认为utf-8,可以不写。
df = df.dropna() #去掉所有的空值
lines = df.content.values.tolist() #以列表的形式存入每行数据
content = ''.join(lines) #拼接每一行,生成文本
print(' '.join(analyse.extract_tags(content,topK=30,withWeight=False,allowPOS=()))) #使用空格拼接每一行
- 1
- 2
- 3
- 4
- 5

2、基于 TextRank 算法的关键词抽取
(1)基本思想:
a.将待抽取关键词的文本进行分词
b.以固定窗口大小(默认为5,通过span属性调整),词之间的共现关系,构建图
c.计算图中节点的PageRank,注意是无向带权图。
TextRank的灵感来源于大名鼎鼎的PageRank算法,这是一个用作网页重要度排序的算法。并且,这个算法也是基于图的,每个网页可以看作是一个图中的结点,如果网页A能够跳转到网页B,那么则有一条A->B的有向边。这样,我们就可以构造出一个有向图了。
然后,利用公式:
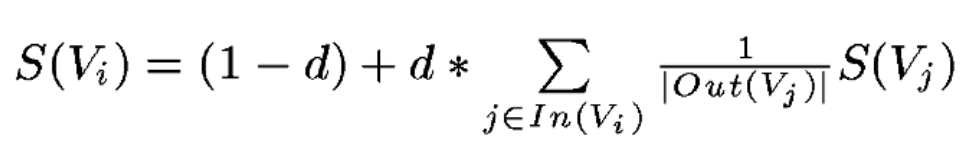
经过多次迭代就可以获得每个网页对应的权重。下面解释公式每个元素的含义: 可以发现,这个方法只要构造好图,对应关系自然就有了,这实际上是一个比较通用的算法。那么对于文本来说,也是同样的,只要我们能够构造出一个图,图中的结点是单词or句子,只要我们通过某种方法定义这些结点存在某种关系,那么我们就可以使用上面的算法,得到一篇文章中的关键词or摘要。
可以发现,这个方法只要构造好图,对应关系自然就有了,这实际上是一个比较通用的算法。那么对于文本来说,也是同样的,只要我们能够构造出一个图,图中的结点是单词or句子,只要我们通过某种方法定义这些结点存在某种关系,那么我们就可以使用上面的算法,得到一篇文章中的关键词or摘要。
提取关键词,和网页中选哪个网页比较重要其实是异曲同工的,我们只需要想办法把图构建出来就好了。
图的结点其实比较好定义,就是单词。把文章拆成句子,每个句子再拆成单词,以单词为结点。
那么边如何定义呢?这里就可以利用n-gram的思路,简单来说,某个单词,只与它附近的n个单词有关,即与它附近的n个词对应的结点连一条无向边(两个有向边)。
另外,还可以做一些操作,比如把某类词性的词删掉,一些自定义词删掉,只保留一部分单词,只有这些词之间能够连边。
下面是论文中给出的例子:


当构图成功以后,就可以利用上面的公式进行迭代求解了。(注:TextRank基本思想部分参考:https://blog.csdn.net/qian99/article/details/83713872)
(2)参数:
import jieba.analyse
jieba.analyse.textrank(sentence, topK=20, withWeight=False, allowPOS=('ns', 'n', 'vn', 'v')) 直接使用,接口相同,注意默认过滤词性。
- 1
- 2
(3)案例:
df =pd.read_csv('data/military_news.csv',encoding='utf-8')
df = df.dropna() #去掉所有的空值
lines = df.content.values.tolist() #以列表的形式读入每行数据
content = ''.join(lines) #拼接每一行,生成文本
print(' '.join(analyse.textrank(content,topK=20,withWeight=False,allowPOS=('ns', 'n', 'vn', 'v')))) #只选取指定词性的单词
print('-------------------------我是分割线----------------------')
print(' '.join(analyse.extract_tags(content,topK=20,withWeight=False,allowPOS=('ns', 'n', 'vn', 'v'))))
- 1
- 2
- 3
- 4
- 5
- 6
- 7


