
- 1Java 变量常见面试题总结_java 变量作用域 面试题
- 2部署运行ai智障写作记录【ChatRWKV】
- 3HBase高并发机制
- 4不知道AIGC是什么?近屿智能OJAC第六期AIGC深度训练营,带您从入门到精通!
- 5Prometheus接入AlterManager配置企业微信告警(基于K8S环境部署)_prometheus微信告警
- 6jdk更换ssl证书jssecacerts
- 7自然语言处理NLP之自然语言生成、文本相似性、看图说话、说话生图、语音合成、自然语言可视化_nlp技术可以输出图片吗
- 8Java 第十一届 蓝桥杯 省模拟赛 户户通电(图算法)_2015年,全中国实现了户户通电。作为-名电力建设者,小明正在帮助一带- -路 上的国
- 9基于hadoop的商品推荐系统_顶会综述基于图模型的推荐系统
- 10Java常见注解_untracked files prevent merge
resnet预训练模型_23个系列分类网络,10万分类预训练模型,这是飞桨PaddleClas百宝箱...
赞
踩
如何训练出优秀的图像分类模型?飞桨图像分类套件 PaddleClas 来助力。
今天咱们来聊聊计算机视觉领域最核心的技术之一——图像分类。顾名思义图像分类是指根据图像信息把不同类别的图像自动区分开来,并能指出图像类别信息。如图 1 所示,当前图像分类技术有着非常广泛的应用场景。

图 1 图像分类技术应用
此外图像分类技术在计算机视觉各类任务中堪称「基石」,这和人类的视觉方面的技能树点亮顺序很像。婴儿在能看清周围事物后,父母除了教他认识爸爸妈妈之外,还会通过画本告诉他,这是花,这是草,这是车,这是飞机等等,这其实就是训练图像分类的过程。可以说图像分类是人类最先学到的一门本领。而在此基础之上,才会继续学会指出什么物体在什么位置(目标检测),以及如何去接触物体(图像分割)等等。如果您仔细分析下计算机视觉的其它技术,您会发现,也确实是如此。
对于其它视觉任务,像图像目标检测、图像分割、图像检索、自然场景文字检测和识别、人脸检测和识别等等,常常将图像分类的网络结构作为骨干网络。例如使用基于 ImageNet1K 分类数据集训练的模型作为特征提取器,来提升目标任务的组网效率和效果。如果把某个视觉任务看成是建造一栋大楼,图像分类的网络结构和预训练模型则可以看成是这栋大楼牢固的地基和稳定的骨架。
图像分类如此重要,可想而知训练出优秀的图像分类模型也是一个很有挑战的任务,其最大的困难点就在于训练图像的复杂性!什么?想知道有多复杂?那咱们拿狗狗举例子吧,有人会说:狗狗嘛,很好分辨啊!你以为你的模型只会用于推理这种一寸免冠照片式的图像吗?

错!你的模型可能面临的是这样的、这样的和这样的!

怎么样?有什么想说的吗?
解决问题的第一步就要认识问题,因此经过科研人员的研究,如图 2 所示,图像的辨识困难点主要有以下几点:
- occlusion:识别目标被遮挡
- scale:识别目标的尺度变化
- deformation:识别目标变形
- clutter:识别目标所处的背景嘈杂
- illumination:识别目标所处环境的光照变化
- viewpoint:拍摄识别目标的视角变化
- object pose:识别目标的姿态变化

图 2 图像分类困难点(来源于:KristenGrauman,BastianLeibe,Visual Object Recognition)
为了解决上述这些困难,研究人员从数据增广、骨干网络设计、损失定义、优化器设计、模型压缩裁剪量化、模型可解释性、特征迁移学习等不同的角度对图像分类问题进行深入探索。飞桨图像分类套件 PaddleClas 是飞桨为工业界和学术界所准备的一个图像分类任务的工具集,助力使用者训练出更好的视觉模型和应用落地。PaddleClas 具备以下 4 大特色,丰富的模型库、高阶优化支持、特色拓展应用、以及工业级部署工具。下面将为大家详细分解。

丰富的模型库
由于学习率、学习率下降策略、batch_size、权重衰减、标签平滑、数据增广等超参选择和设定对分类效果影响很大,复现对齐一种分类网络结构往往非常具有挑战性。基于 ImageNet1k 分类数据集,PaddleClas 提供 ResNet、ResNet_vd、Res2Net、HRNet、MobileNetV3 等 23 个系列的分类网络结构的简单介绍、论文指标复现配置以及在复现过程中积累的训练技巧。同时,PaddleClas 还提供了与 23 个系列网络结构相对应的 117 个预训练模型,以及推理效果和性能评估。
先说服务器端的预训练模型,如图 3 所示,图中记录了在 V100,FP32 和 TensorRT 环境下一些最新的面向服务器端应用场景的模型的效果和性能对比图,通过该图用户可以直观的快速选择出需要的网络结构。
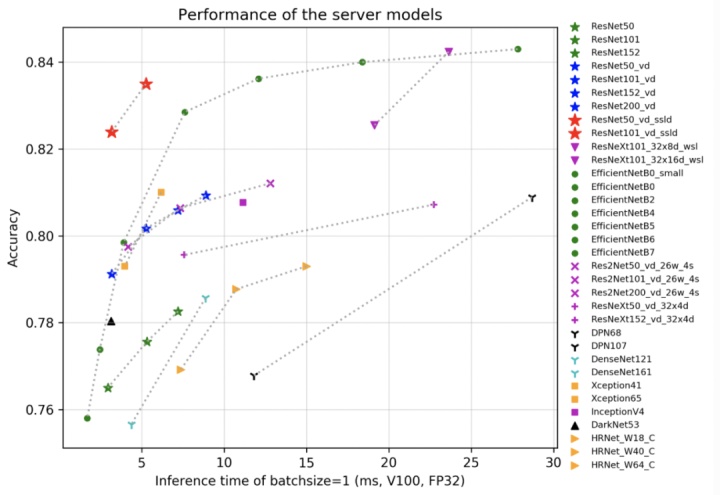
图 3 服务器端预训练模型效果和性能评估
在这些模型中,优先推荐使用 ResNet_vd 系列模型,这是因为 ResNet 系列模型是业界较为成熟且应用广泛的一种模型,其不仅应用于图像分类任务,还可以用于目标检测等其它任务类型。而 ResNet_vd 是 ResNet 的改进版,在尽可能减少推理耗时增加的前提下,识别准确率大幅提升 2.5% 左右,并且在采用知识蒸馏方案 SSLD 的加强后,PaddleClas 可以提供该系列当前最有竞争力的预训练模型,82.4% 的 ResNet50_vd_ssld 和 83.7% 的 ResNet101_vd_ssld,如今这些模型的性能还在持续提升中。
再看移动端场景,图 4 根据在骁龙 855(SD855)上预测一张图像所需的时间和准确率,记录比对了一些最新的面向移动端应用场景的模型。包括 MobileNetV1 系列、MobileNetV2 系列、MobileNetV3 系列和 ShuffleNetV2 系列。
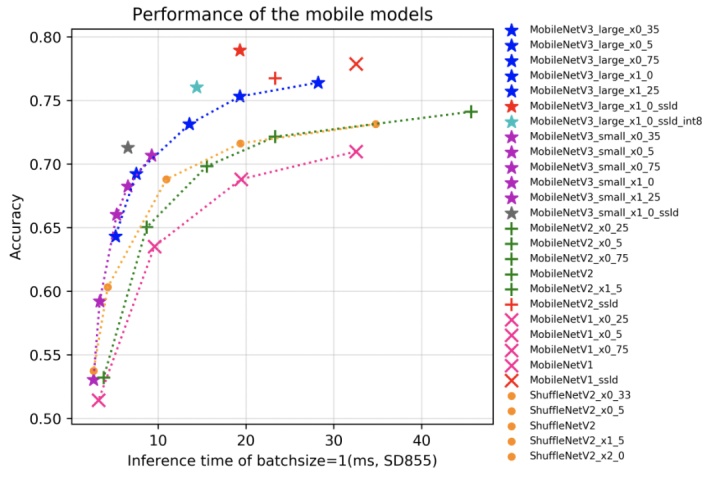
图 4 移动端预训练模型效果和性能评估
在这些模型中,优先推荐使用 MobileNetV3 系列模型。MobileNetV3 是一种基于 NAS 的新的轻量级网络,与其他网络相比,在相同的预测速度下,MobileNetV3 系列网络的精度更有竞争力。同时,采用知识蒸馏方案 SSLD,PaddleClas 也提供了该系列当前最有竞争力的预训练模型,准确率达到 79% 的 MobileNetV3_large_x1_0_ssld 和 71.3% 的 MobileNetV3_small_x1_0_ssld。此外,PaddleClas 还提供了在内存占用上非常有优势的 MobileNetV1 和 MobileNetV2 的蒸馏模型,这两类模型可以仅占用较少的内存资源,即可以达到不错的性能效果。
不同模型的简介、训练技巧、FLOPS、Parameters、GPU 预测时间、CPU 预测时间和存储大小请参考教程中的模型库章节:
https://paddleclas.readthedocs.io/zh_CN/latest/models/index.html
高阶优化支持之SSLD 知识蒸馏方案
前面多次提到 SSLD 知识蒸馏方案,那它究竟是什么呢?知识蒸馏是指使用教师模型 (teacher model) 去指导学生模型 (student model) 学习特定任务,保证小模型在参数量不变的情况下,得到比较大的效果提升,甚至获得与大模型相似的精度指标。此外该方案的最大的特点是可以帮助用户利用没有标注的数据对模型进行训练,提升模型效果。
那么图像分类模型与知识蒸馏技术携手,会有什么样的威力呢?PaddleClas 提供了一种简单的半监督标签知识蒸馏方案(SSLD,Simple Semi-supervised Label Distillation)。如图 5 所示,使用该方案模型效果普遍提升 3% 以上。
详细的 SSLD 知识蒸馏方案介绍、核心关键点、实验细节以及方案使用请参考教程中高阶使用的知识蒸馏章节:
https://paddleclas.readthedocs.io/zh_CN/latest/advanced_tutorials/distillation/index.html
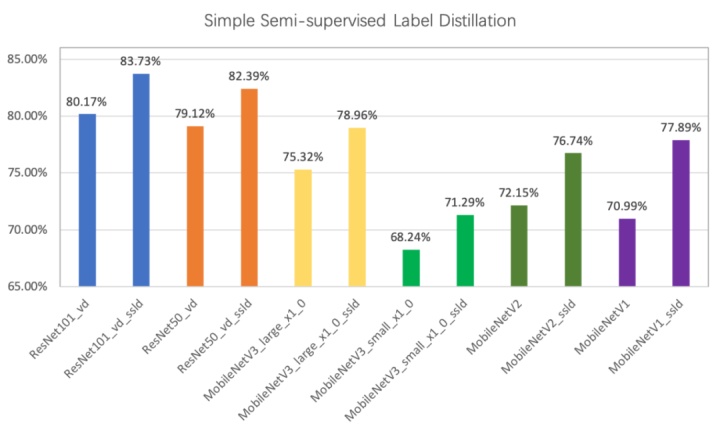
图 5 蒸馏模型提升效果图
高阶优化支持之 八种数据增广方法
在图像分类任务中,图像数据的增广是一种常用的正则化方法,可以有效提升图像分类的效果,尤其对于数据量不足或者模型网络较大的场景。常用的数据增广可以分为 3 类,图像变换类、图像裁剪类和图像混叠类:
- 图像变换类是指对全图进行一些变换,包括 AutoAugment、RandAugment。
- 图像裁剪类是指对图像以一定的方式遮挡部分区域的变换,包括 CutOut、RandErasing、HideAndSeek、GridMask。
- 图像混叠类是指多张图进行混叠一张新图的变换,包括 Mixup、Cutmix。

图 6 数据增广方法
PaddleClas 提供了上述 8 种数据增广算法的复现,以及在统一实验环境下的效果评估,如图 7 所示。该图展示了不同数据增广方式在 ResNet50 上的表现, 与标准变换相比,采用数据增广的识别准确率最高可以提升 1%。不要小看这 1%,如果应用到实际业务中,这可能就是多识别出几千几万张图片呢!
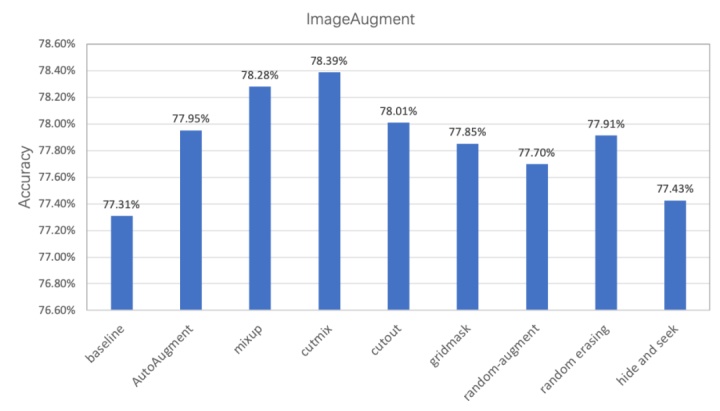
图 7 数据增广算法对比图
每种数据增广方法的详细介绍、对比的实验环境以及使用请参考教程中高阶使用图像增广章节:
https://paddleclas.readthedocs.io/zh_CN/latest/advanced_tutorials/image_augmentation/index.html
工业级部署工具
飞桨提供了一系列实用工具,便于工业应用部署 PaddleClas,包括 TensorRT 部署推理、移动端部署推理、模型服务化部署等等。而这些工具大都以图像分类为例,提供示例教程和进行优化。因此如果用户使用 PaddleClas 训练的模型,通过参考文档教程中的实用工具章节,就可以很方便的把模型集成到自己的服务中,完成相应的图像分类任务。
教程中的实用工具章节请参见:
https://paddleclas.readthedocs.io/zh_CN/latest/extension/index.html
实际应用案例
1. 10 万类图像分类预训练模型
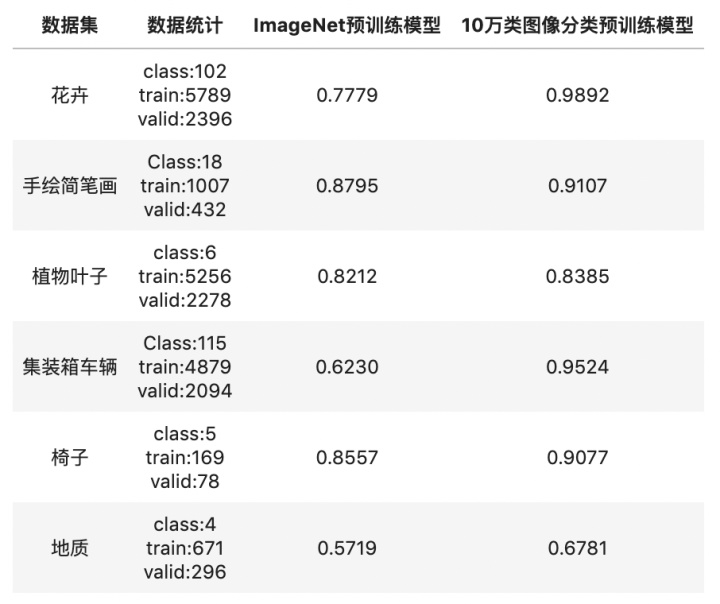
在实际应用中,由于训练数据匮乏,往往将 ImageNet1K 数据集训练的分类模型作为预训练模型,然后进行图像分类的迁移学习。然而 ImageNet1K 数据集的类别只有 1000 种,预训练模型的特征迁移能力有限。因此百度自研了一个有语义体系的、粒度有粗有细的 10W 级别的 Tag 体系。通过使用人工或半监督方式,至今收集到 5500w+ 图片训练数据;该系统是国内甚至世界范围内最大规模的图片分类体系和训练集合。
百度的小伙伴基于 PaddleClas 提供的 ResNet_vd 系列网络结构的训练方法和预训练模型,训练了一批大规模图像分类预训练模型,并应用到实际图像分类相关业务中。下表显示了一些实际应用场景中,基于 ResNet50_vd,使用 ImageNet 预训练模型和 10 万类图像分类预训练模型的效果比对,使用 10 万类图像分类预训练模型,识别准确率最高可以提升 30%。最最重要的是,上述预训练模型都已经在 PaddleClas 上开源了!心动的小伙伴们不要错过啊!
上述图像分类方案的详细介绍和使用请参考教程中应用拓展的图像分类迁移学习章节:
https://paddleclas.readthedocs.io/zh_CN/latest/application/transfer_learning.html
2. PSS-DET 实用目标检测算法
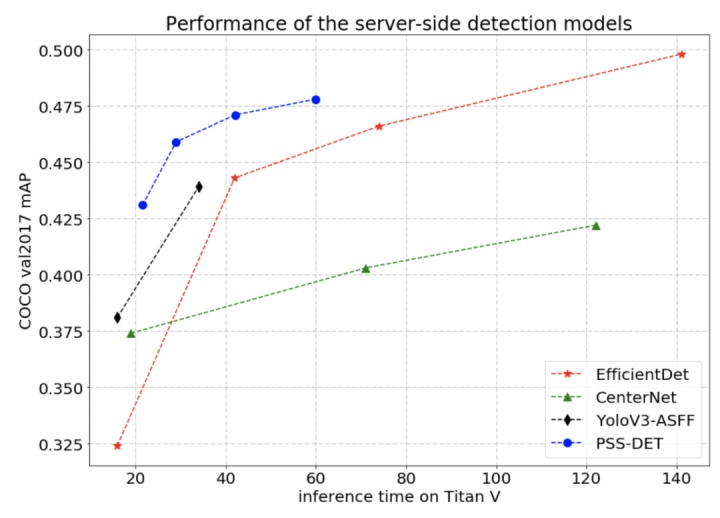
近年来,学术界和工业界广泛关注图像中目标检测任务,而图像分类的网络结构以及预训练模型效果直接影响目标检测的效果。PaddleDetection 使用 PaddleClas 的 ResNet50_vd_ssld 预训练模型作为骨干网,结合丰富的检测算子,提供了一种面向服务器端应用的目标检测方案,PSS-DET (Practical Server Side Detection)。
该方案融合了多种不增加计算量,可以有效提升两阶段 Faster RCNN 目标检测效果的策略,包括检测模型剪裁、使用分类效果更优的预训练模型、DCNv2、Cascade RCNN、auto augment、libra sampling 以及多尺度训练。其中基于 82.39% 的 ResNet50_vd_ssld 预训练模型,与 79.12% 的 R50_vd 的预训练模型相比,检测效果可以提升 1.5%。在 COCO 目标检测数据集上测试 PSS-DET,当 V100 单卡预测速度为 61FPS 时,mAP 是 41.6%,预测速度为 20FPS 时,mAP 是 47.8%。相同的预测速度下,检测效果优于最近业内较为火热的 EfficientDet 模型。
上述检测方案的详细介绍和使用请参考文档教程中应用拓展的通用目标检测章节:
https://paddleclas.readthedocs.io/zh_CN/latest/application/object_detection.html
如果您加入官方 QQ 群,您将遇上大批志同道合的深度学习同学。官方 QQ 群:703252161。
如果您想详细了解更多飞桨的相关内容,请参阅以下文档。
官网地址:https://www.paddlepaddle.org.cn
飞桨 PaddleClas 项目地址:
GitHub: https://github.com/PaddlePaddle/PaddleClas
Gitee: https://gitee.com/paddlepaddle/PaddleClas
飞桨 PaddleClas 文档教程地址:
https://paddleclas.readthedocs.io/zh_CN/latest/
飞桨开源框架项目地址:
GitHub: https://github.com/PaddlePaddle/Paddle
Gitee: https://gitee.com/paddlepaddle/Paddle

