
- 1基于微信小程序的校园代送跑腿小程序(源码+文档+包运行)_校园跑腿小程序源码 java
- 2鸿蒙HDC的使用
- 3【PHP代码注入】PHP语言常见可注入函数以及PHP代码注入漏洞的利用实例
- 4pycharm中添加pytorch解释器_pycharm怎么pytorch
- 5AI文档解析软件大PK:准确度、速度、多样性对比一览_ai文件对比
- 6华为鸿蒙的攻与守,华为鸿蒙的攻与守
- 7Linux VPU驱动
- 8yolov5模型(.pt)在RK3588(S)上的部署(实时摄像头检测)_rk3588摄像头实时推理显示
- 9VMware ESXi 8.0集成网卡驱动_esxi8.0下载
- 10Python_编写一个程序,输入一个正整数n,输出前n个自然数之和。
NLP | word2vec图文详解及代码_word2vec代码实现
赞
踩
在一个常规的 one-hot 编码向量中,所有单词之间的距离都相同,即使它们的含义完全不同,丢了编码中的位置信息。使用 Word2Vec 等词嵌入方法,生成的向量可以更好地维护上下文。例如,猫和狗比鱼和鲨鱼更相似。
Word2vec 是一个两层神经网络,通过“向量化”单词来处理文本。它的输入是一个文本语料库,它的输出是一组向量:表示该语料库中单词的特征向量。虽然 Word2vec 不是深度神经网络,但它将文本转换为深度神经网络可以理解的数字形式。
1.词嵌入(word Embeding)
词嵌入是一种将单个词转换为词的数字表示(向量)的技术。每个单词都映射到一个向量,然后以类似于神经网络的方式学习该向量。向量试图捕捉该词相对于整个文本的各种特征。这些特征可以包括单词的语义关系、定义、上下文等。通过这些数字表示,你可以做很多事情,比如识别单词之间的相似性或不相似性。
显然,这些作为机器学习各个方面的输入是不可或缺的。机器无法处理原始形式的文本,因此将文本转换为嵌入将允许用户将嵌入提供给经典的机器学习模型。最简单的嵌入是文本数据的一次热编码,其中每个向量都将映射到一个类别。例如:
have = [1, 0, 0, 0, 0, 0, ... 0]
a = [0, 1, 0, 0, 0, 0, ... 0]
good = [0, 0, 1, 0, 0, 0, ... 0]
day = [0, 0, 0, 1, 0, 0, ... 0]
像这样的简单嵌入有很多问题,因为它们不能捕捉单词的特征,而且根据语料库的大小,它们可能会很大。
2.Word2Vec 架构
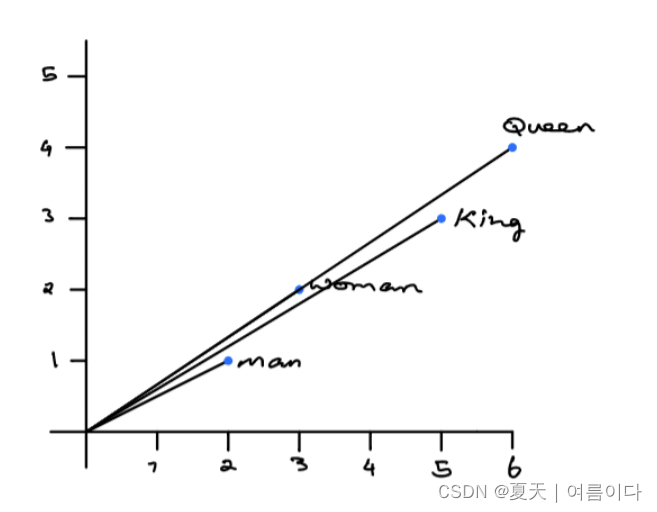
Word2Vec 的有效性来自于它能够将相似词的向量组合在一起。给定足够大的数据集,Word2Vec 可以根据单词在文本中的出现次数对单词的含义做出强有力的估计。这些估计产生了与语料库中其他单词的单词关联。例如,像“King”和“Queen”这样的词会非常相似。在对词嵌入进行代数运算时,您可以找到词相似度的近似值。例如,“king”的二维嵌入向量——“man”的二维嵌入向量+“woman”的二维嵌入向量,产生了一个与“queen”的嵌入向量非常接近的向量。请注意,以下值是任意选择的。
word2vec 主要有两种架构:CBOW 和Skip-gram 。
CBOW - 根据上下文预测词语,SkipGram - 根据词语预测上下文。
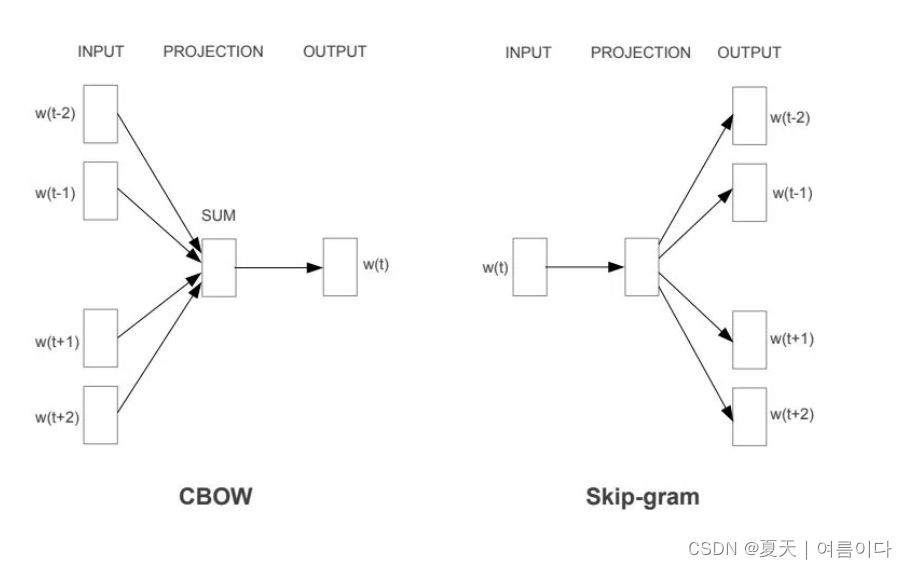
在表示输入和输出的方式上,它们本质上是相反的。
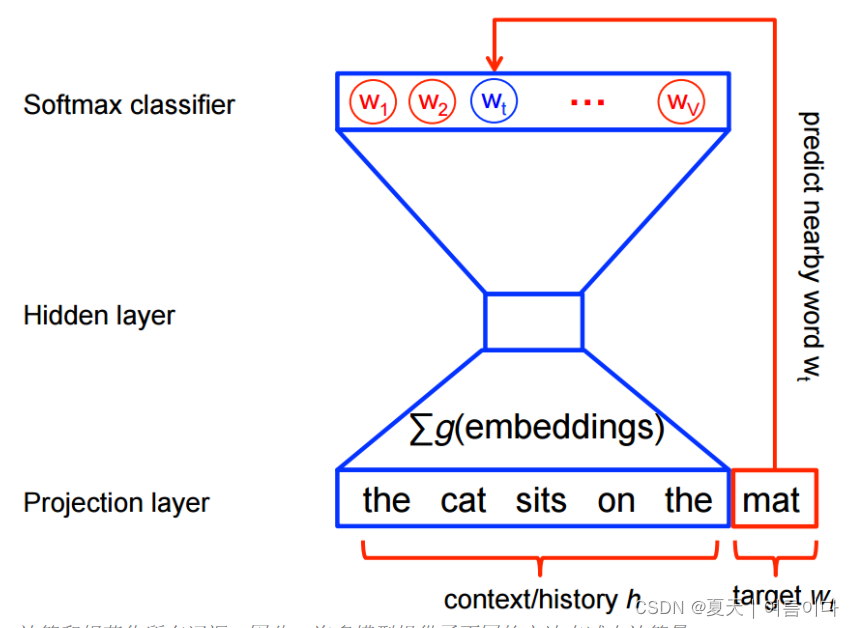
3.CBOW(连续词袋)
这种架构非常类似于前馈神经网络。这种模型架构本质上试图从上下文词列表中预测目标词。这个模型背后的直觉很简单:给定一句话"Have a great day",我们将选择目标词为“a”,上下文词为[“have”、“great”、“day”]。该模型将做的是采用上下文词的分布式表示来尝试和预测目标词。CBOW 从周围的上下文词(“猫坐在上面”)预测目标词(例如“垫子”)。 从统计上讲,它具有使 CBOW 平滑许多分布信息的效果(通过将整个上下文视为一个观察结果)。在大多数情况下,用于较小的数据集。
对C个上下文的词语每个词用C组不同的权重W全连接映射到一个N维的隐层上,得到C个N维隐层值,取平均,再对这个平均的N维隐层用权重W'的全连接+softmax对V个词语赋予概率值,V即vocabulary_sizee。W和W'分别是V×N和N×V的矩阵(全连接↔左乘权重矩阵的转置),假设某词word是Vocabulary的第j个词,那么W的第j行称为word的输入词向量,W'的第j列向量为word的输出词向量。点此查看原论文,不过我没看懂所谓的word embedding最终输出的到底是哪个向量,输入、输出、还是隐层。
4.Skip-gram
sskip-gram 模型是一个简单的神经网络,具有一个经过训练的隐藏层,以便在输入单词出现时预给定单词出现的概率。在这个架构中,它将当前单词作为输入,并试图准确地预测当前单词之前和之后的单词。该模型本质上是尝试学习和预测指定输入词周围的上下文词。基于评估该模型准确性的实验,发现在给定大范围的词向量的情况下预测质量有所提高,但它也增加了计算复杂度。
首先,我们不能将单词作为字符串输入神经网络。
相反,我们将单词作为 one-hot 向量提供,它基本上是一个与词汇表长度相同的向量,除了表示我们要表示的单词的索引处被分配为“1”之外,都用零填充。
隐藏层是标准的全连接(密集)层,其权重是词嵌入。
输出层从词汇表中输出目标词的概率。
* 在 Skip-Gram 学习模型中,输入是 one-hot 编码的单词,输出是单词的上下文。
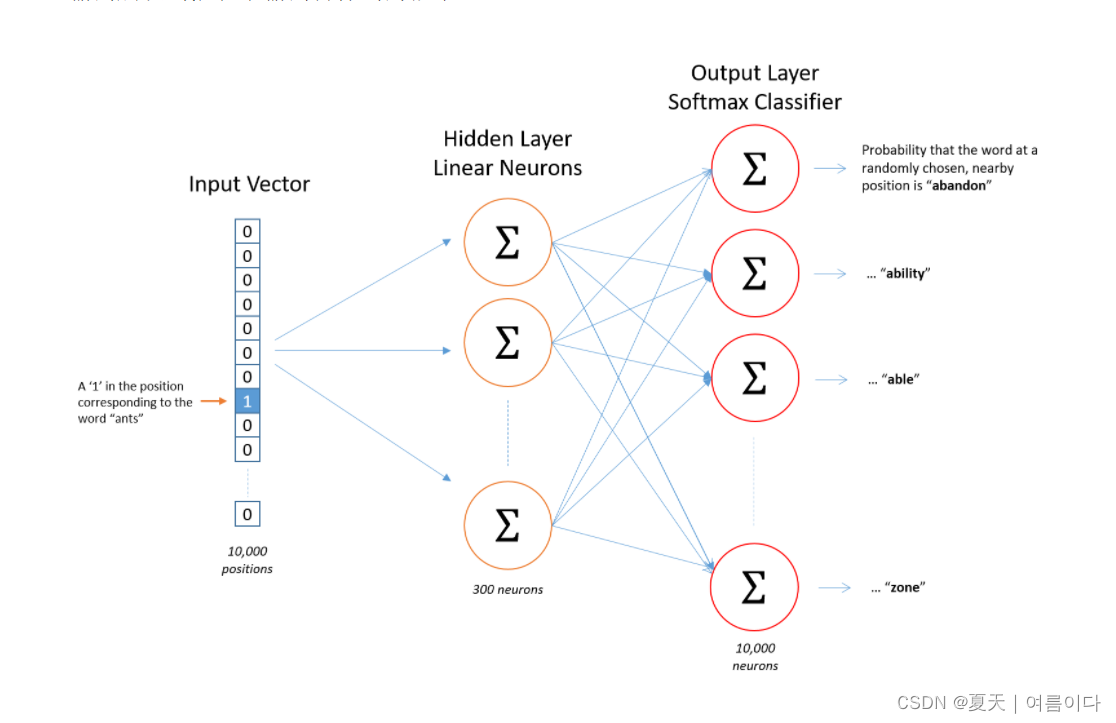
这个网络的输入是表示输入词的one-hot向量,标签也是表示目标词的one-hot向量,但是网络的输出是目标词的概率分布,不一定是one-hot矢量像标签。
隐藏层权重矩阵的行(),其实就是我们想要的词向量(词嵌入)!
隐藏层用作查找表。隐藏层的输出只是输入词的“词向量”。如果将 a 乘以1 x 10,000 one-hot vector a 10,000 x 300 matrix,它将有效地选择与“1”对应的矩阵行。
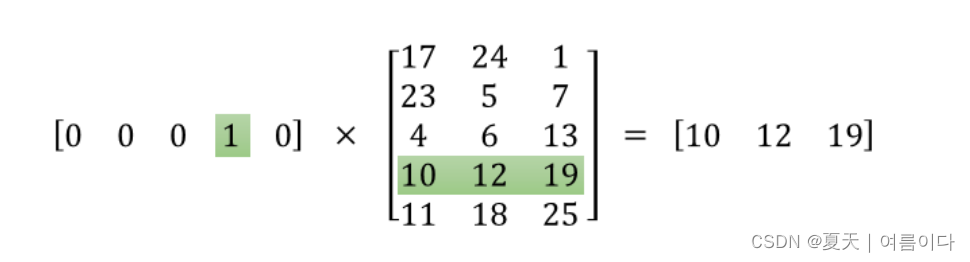
学习这个隐藏层的权重矩阵,然后进入输出层!
输出层只是一个 softmax 激活函数:
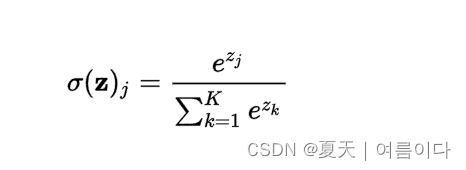
流程可表示为
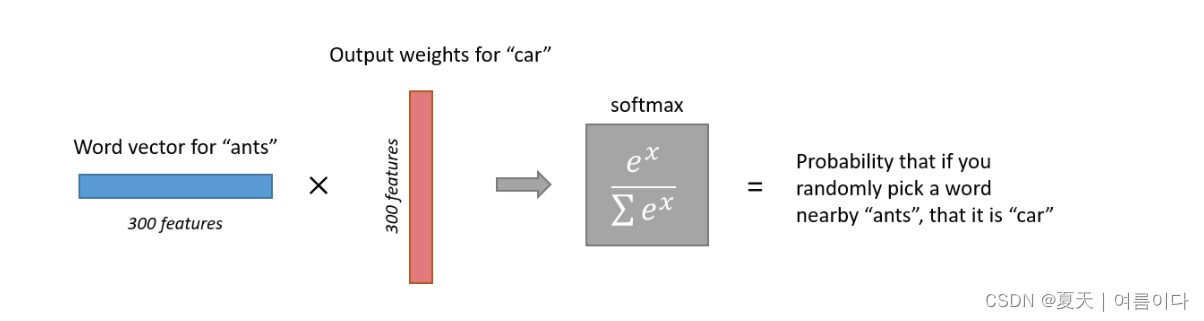
也可以表示为:

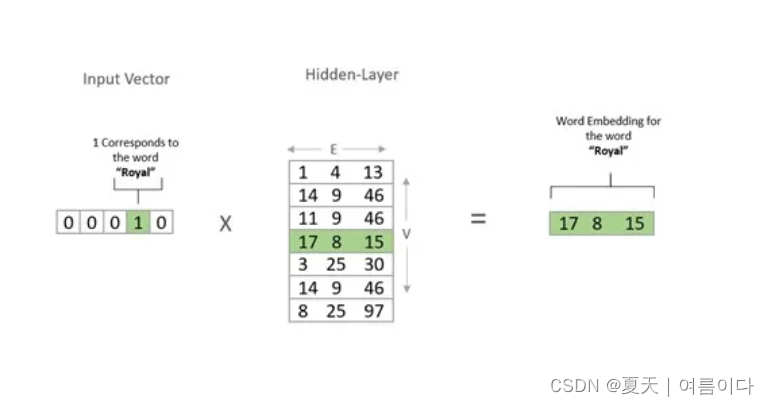
词嵌入是 Hidden-Layer 一个向量 (V x E)。
对于给定的单词,这个向量是一个 (1 x E) 向量。本质上,您可以将隐藏层视为查找表。当您将给定单词的一个热编码向量乘以隐藏层向量时,结果就是词嵌入。
5.语义和句法关系
Word2Vec 能够捕捉单词之间多种不同程度的相似性,这样语义和句法模式就可以使用向量算术来重现。可以通过对这些单词的向量表示进行代数运算来生成诸如“Man is to Woman as Brother is to Sister”之类的模式,使得“Brother”-“Man”+“Woman”的向量表示产生最接近的结果到模型中“姐姐”的向量表示。可以为一系列语义关系(例如国家-首都)以及句法关系(例如现在时-过去时)生成这样的关系。
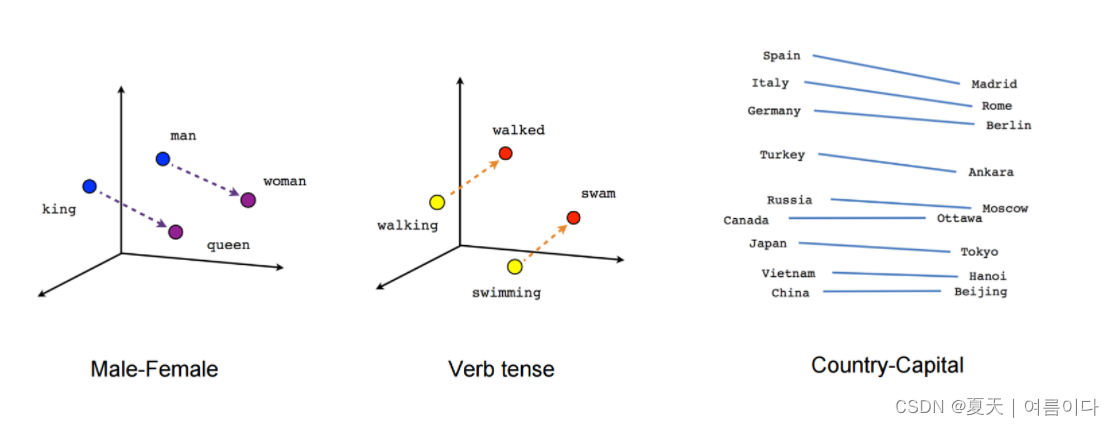
- 不同维度的词向量位置越近,代表越相似。
6.训练算法
Word2vec 模型可以使用分层 softmax 和/或负采样进行训练,通常只使用负采样。
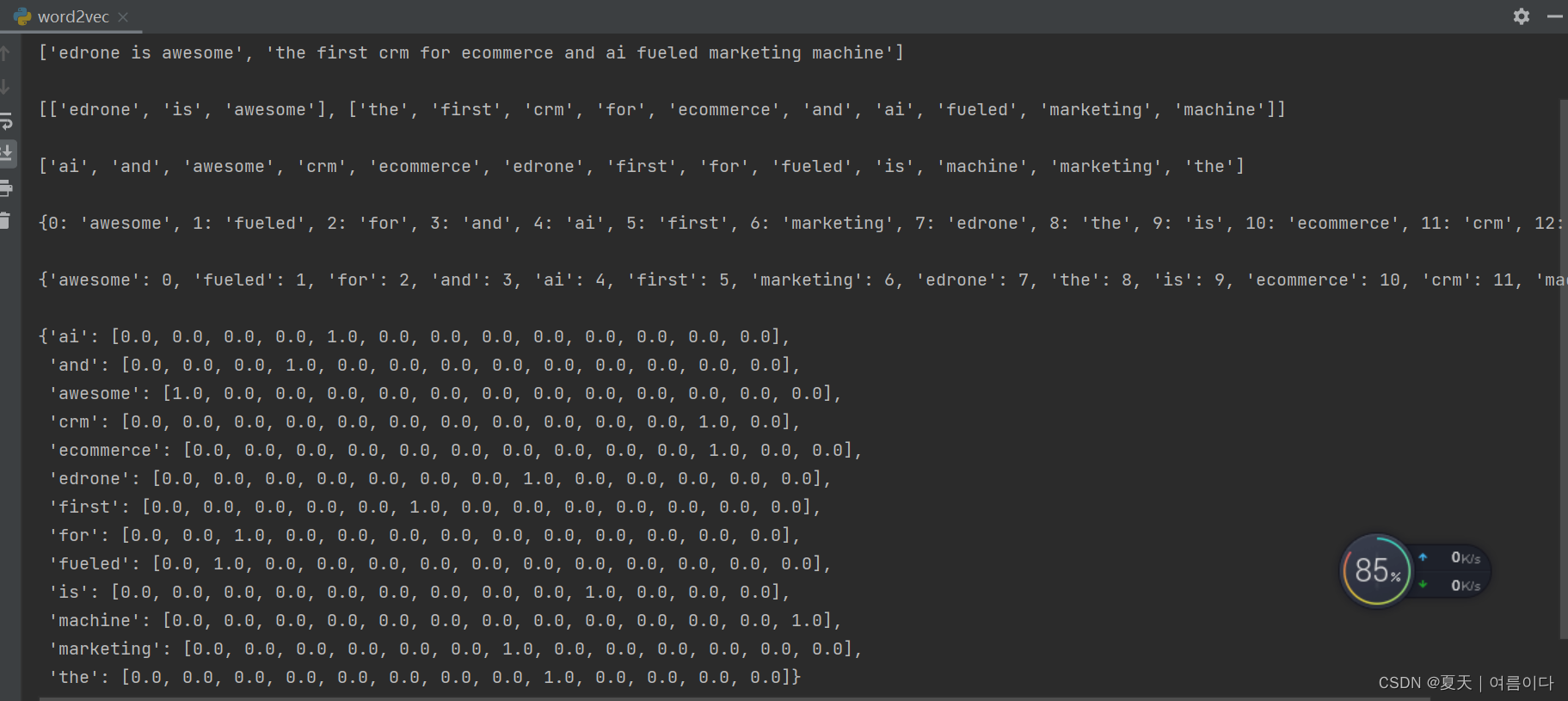
7.代码实现:
7.1.
- #https://blog.edrone.me/en/word2vec/
- tiny_corpus = ['edrone is awesome',
- 'The first CRM for eCommerce and AI fueled marketing machine']
- print(tiny_corpus, '\n')
-
- # LOWER CASE
- tiny_corpus_lowered = [sentence.lower() for sentence in tiny_corpus]
- print(tiny_corpus_lowered, '\n')
-
- # TOKENIZATION
- tiny_corpus_lowered_tokenized = [sentence.split() for sentence in tiny_corpus_lowered]
- print(tiny_corpus_lowered_tokenized, '\n')
-
- # DICTIONARY
- words = [word for sentence in tiny_corpus_lowered_tokenized for word in sentence]
- print(sorted(words), '\n')
-
- unique_words = list(set(words))
-
- # ASIGN TO DICTIONARY
- id2word = {nr: word for nr, word in enumerate(unique_words)}
- print(id2word, '\n')
-
- word2id = {word: id for id, word in id2word.items()}
- print(word2id, '\n')
-
- # ONE HOT ENCODING
- from pprint import pprint
- import numpy as np
-
- num_word = len(unique_words)
- word2one_hot = dict()
-
- for i in range(num_word):
- zero_vec = np.zeros(num_word)
- zero_vec[i] = 1
- word2one_hot[id2word[i]] = list(zero_vec)
-
- # RESULT
- pprint(word2one_hot)

结果:
7.2.
- import gensim
- import gensim.downloader as api
-
- wv=api.load('word2vec-google-news-300')
-
- vec_king=wv['king']
- print(f"Embedding dimension is :{vec_king.shape}\n")
- print(f"Embedding Vector of 'king' is :\n\n{vec_king}")
结果:

参考文献
【1】https://towardsdatascience.com/word2vec-explained-49c52b4ccb71
【3】A Beginner's Guide to Word2Vec and Neural Word Embeddings | Pathmind
【4】Word2Vec Explained Easily - HackDeploy
【5】https://medium.com/analytics-vidhya/maths-behind-word2vec-explained-38d74f32726b
【6】Word2vec Explained - How to Make a Machine Understand Language

