
- 1做软件测试,就得去大厂!
- 2Rasa中文聊天机器人开发指南(2):NLU篇_rasa中文文档
- 3《基于音频和文本的多模态语音情感识别的TensorFlow实现》的项目(写的很人性化的哦!)_基于tensorflow的语音情绪分析与运用的研究意义
- 4B端界面设计:页面分类设计_页面结构设计,功能划分
- 5介绍一下gpt模型的原理_gpt原理
- 6芒果YOLOv8改进10:特征融合Neck篇:改进特征融合网络 BiFPN 结构,融合更多有效特征_concat_bifpn yolov8
- 7深入解析《企业级数据架构》:HDFS、Yarn、Hive、HBase与Spark的核心应用_数据仓库 hive hdfs
- 8ShuffleNet: An Extremely Efficient Convolutional Neural Network for Mobile Devices论文学习
- 9mxnet学习笔记(二)——训练器Trainer()函数详解_gluon.trainer
- 10可视化模型:深度学习中的 Grad-CAM 指南_gcn grad-cam
自然语言处理入门理论知识
赞
踩
一、什么是自然语言处理
自然语言处理(Natural Language Processing,NLP)
是人工智能领域的主要内容,研究用电子计算机模拟人的语言交际过程,使计算机能理解和运用人类社会的自然语言,实现人机之间的自然语言通信,以代替人的部分脑力劳动,包括查询资料、解答问题、摘录文献、汇编资料以及一切有关自然语言信息的加工处理。
1.1 自然语言处理的过程
目录
9.1.1 短语结构( Phrase structure / Constituency )
9.1.2 依存结构( Dependency structure )
自然语言处理的基础:词法分析,语法分析,语义分析
第一步:分析源语言(文本理解)
通过词法分析,语法分析,语义分析来对源语言进行分析理解
获得句子的语义
第二步:生成目标语言(文本生成)

任何一个NLP系统都离不开文本理解和文本生成。
通过应用到不同方面,形成了不同的领域。
1.2 自然语言处理遇到的困难
1.2.1 歧义
词法层面:
例1: I made her duck.
her:宾格 or 所有格?
例2:“打”的词性是什么?
动词:打电话
介词:打今天起
量词:一打铅笔
句法层面:
Put the block in the box on the table. 把盒子里的积木放到桌子上
Put the block in the box on the table. 把积木放到桌子上的盒子里
语义方面:
她这个人真有意思。 有趣
我根本没有那个意思。 想法
语用层面(程度):
女孩给男朋友打电话:如果你到了,我还没到,你就等着吧;
如果我到了,你还没到,你就等着吧。
语音层面:
I:eye 相同发音。
1.2.2 未知语言现象
(1)意想不到的情况:如未知词汇、未知结构等
(2)语言也是不断发展变化的
新的词汇
新的词义
新的词汇用法
1.3 自然语言处理系统vs. 程序设计语言的编译系统
| 程序设计语言 | 自然语言 |
| 通常采用CFG描述(上下文无关文法) | 远远超出CFG的表达能力 |
| 语言中不存在歧义 | 语言中存在复杂的歧义 |
| 人服从机器 | 机器服从人 |
| 无限集→有限集 映射过程 | 有限集→无限集 推演过程 |
1.4 NLP的基本方法及其发展
1.4.1 理性主义方法(基于规则的方法、符号派)
建立符号处理系统:知识表示体系(规则)+推理程序
希望通过手工编码大量的先验知识和推理机制,得以复制人类大脑中的语言能力
理论基础:乔姆斯基(Chomsky)的语言理论
1.4.2 经验主义方法(基于统计的方法、随机派)
建立数学模型
利用统计学、模式识别和机器学习等方法训练模型参数
语料库:收集一些文本作为统计模型建立的基础
理论基础:香农(Shannon)的信息论
二、语料库
2.1 基本概念
语料库(Corpus):
存放语言材料的数据库(文本集合)。库中的文本通常经过整理,具有既定的格式与标记,特指计算机存储的数字化语料库
Corpora: 语料库集合
关于语料库的三点基本认识:
(1)语料库中存放的是在语言的实际使用中真实出现过的语言材料
(2)语料库是以电子计算机为载体、承载语言知识的基础资源
(3)真实语料需要经过加工(分析和处理),才能成为有用的资源
2.2 语料库类型
(1)专用语料库&通用语料库
专用语料库:
是为了某种专门的目的,只采集某一特定的领域,特定的地区,特定的时间,特定的语体类型的语料构成的语料库。
通用语料库:
抽样时从各个角度考虑了平衡问题的语料库。
按照事先确定好的某种标准,把每个子类的文本按照一定比例收集到一起的语料库。
(2)单语语料库&多语语料库
单语语料库:只含有单一语言文本的语料库
多语语料库:不只有一种语言的语料库
平行语料库
比较语料库
(3)共时语料库&历时语料库
共时语料库:为了对语言进行共时研究而建立的语料库。
历时语料库:对语言文字的使用进行动态追踪、对语言的发展变化进行监测的语料库。
特点: 语料的动态性:语料是不断动态补充的
具有量化属性“流通度”
(4)生语料库&熟语料库
生语料库:没有经过任何加工处理的原始语料数据
熟语料库:经过了加工处理、标注了特定信息的语料库
2.3 语料库加工的三种主要方式
人工:非常昂贵,需要大量的人力资源
自动:不完全准确
半自动(人机结合): 兼顾两者的优点
先由计算机对待加工的语料进行自动加工,然后由人工校对
由计算机自动选择语料库中需要人干预的自动加工不能解决的部分,从而减少人的工作
三、语言模型
3.1 n元语法模型
马尔可夫假设:
直觉上讲,下一个词的出现仅依赖于它前面的一个或几个词。 受离它较近的词的影响较大。
二元语法模型(Bigram model):
假设下一个词的出现只依赖它前面的一个词。
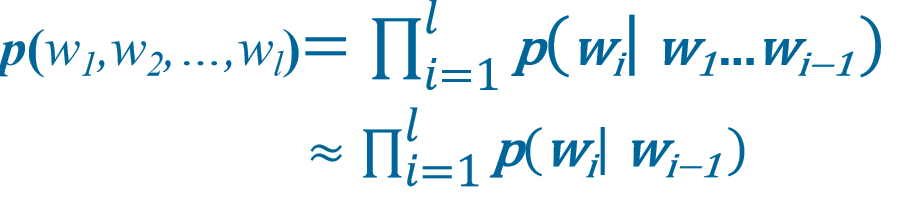
由此我们可以推广
三元语法模型(Trigram model):
假设下一个词的出现依赖它前面的两个词。
n元语法模型(n-gram model):
假设下一个词的出现依赖它前面的n-1个词。
n的选择:
更大的n:对下一个词出现的约束信息更多,具有更大的辨别力
更小的n:在训练语料库中出现的次数更多,具有更可靠的统计信息,具有更高的可靠性
理论上,n越大越好
实践中,由于n的增加,计算量大量增加,bigram和trigram用的较多
二元语法模型下的最大似然估计计算:
假设训练语料由下面3个句子构成
Mother reads S C
Father reads a text book
She reads a book by friends
问题1:用最大似然估计的方法计算概率 p (Father reads a book)
解题思路:把每个词出现的概率相乘。
p(Father|)=1/3
p(reads|Father)=1
p(a|reads)=2/3
p(book|a)=1/2
p(|book)=1/2
在nlp中BOS表示开始符号,EOS表示结束符号。
p (Father reads a book)
=p(Father|)*p(reads|Father)*p(a|reads)*p(book|a)*p(|book)
=1/3*1*2/3*1/2*1/2
问题2:用最大似然估计的方法计算概率 p (He reads a book)
在已有的语料库中没有出现过He reads,所以
p(reads|He)=0
出现了0概率问题。
零概率产生的原因:
映了语言的规律性,即本来就不该出现
数据稀疏(Data Sparseness) :
由于语言模型的训练文本T的规模及其分布存在着一定的局限性和片面性,许多合理的语言搭配现象没有出现在T中。
仅靠增大语料库的规模,不能从根本上解决数据稀疏问题
解决办法:
数据平滑技术
为了产生更准确的概率来调整最大似然估计的技术
基本思想:“劫富济贫”
3.2 数据平滑技术
3.2.1 Laplace法则、Lidstone法则
最简单的平滑技术—Laplace法则
首先我们要获得词汇表的容量。
在上题中:算上BOS EOS ,一共有13个词,所以容量V = 13
在最大似然计算中,分子+1,分母+v
问题一:
=p(Father|)*p(reads|Father)*p(a|reads)*p(book|a)*p(|book)
=1/3 *1 *2/3 *1/2 *1/2
=2/16 *2/14 *3/16 *2/15 *2/15
问题2:
=p(He|)*p(reads|He)*p(a|reads)*p(book|a)*p(|book)
=1/16 *1/14 *3/16 *2/15 *2/15
3.2.2 Good-Turing估计
基本思想: 对于任何一个发生r次的事件(n元语法),都假设它发生r*次
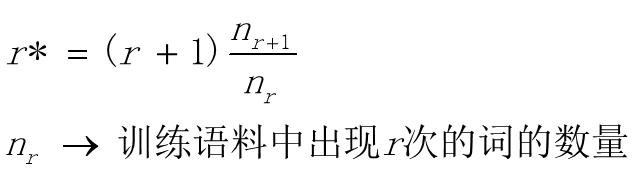
举例说明:
| r | nr | r* |
| 0 | 60 | 60/50*1 |
| 1 | 50 | 50/40*2 |
| 2 | 40 | 40/30*3 |
| ... | ... | ... |
3.2.3 线性折扣

四、隐马尔可夫模型
4.1 马尔科夫模型
随机过程 :又称“随机函数”,是随时间而随机变化的过程
马尔科夫模型描述了一类重要的随机过程

一阶马尔可夫过程:
如果系统在时间t的状态只与其在时间t-1的状态相关,则该随机过程称为一阶马尔可夫过程 马尔可夫模型: 独立于时间t的随机过程
马尔科夫模型的形式化定义:

4.2 隐马尔可夫模型
HMM的形式化定义

HMM涉及的三个基本问题:
(1) 给定模型μ=(A,B,π),如何有效地计算某个观察序列O=o1o2 …… oT出现的概率?
前向(Forward Algorithm )算法
(2) 给定模型μ=(A,B,π)和观察序列O=o1o2 …… oT ,如何有效地确定一个状态序列Q=q1q2 …… qT ,以便最好地解释观察序列?
维特比(Viterbi)算法
(3) 给定一个观察序列O=o1o2 …… oT ,如何找到一个能够最好地解释这个观察序列的模型,即如何调节模型参数μ=(A,B,π),使得P(O| μ)最大化?
Baum-Welch算法
五、字频统计
5.1 字频统计的意义
传统语言学 :运用统计数据对语言现象作定量描写
计算语言学 :也运用统计数据
支持语言的自动分析
字频和词频
语言现象(事件)的概率无法直接观察到,需要根据频率来估计
5.2 单字字频统计
单字字频统计 :
给定一批语料,统计出其中有多少个不同的汉字,每个汉字各出现多少次
求汉字的频率
如果语料规模充分大并且分布均匀,就可以根据字频来估计每个汉字的出现概率

字表的结构:
方法一 :字表中必须有单字和字频两个域
数组的元素是一个结构 Struct zf { CString z; int f; }
方法二 :通过汉字的ASCII码跟数组元素下标建立对应关系 int HZFreq[HZ_NUM]
把第一个汉字的字频放在HZFreq[0]中,把第二个汉字的字频放在HZFreq[1]中,……,把最后一个汉字的字频放在HZFreq[HZ_NUM-1]中
不必在数组中存放汉字本身,元素下标就代表着特定的汉字,节约了空间
根据ASCII码可以确定汉字在数组中的位置,无须进行查找,节约了时间
5.3 双字字频统计
任务: 统计给定语料中有多少个不同的字对,每个字对各出现多少次
例如:“发展中国家的” “发展”、“展中”、“中国”、“国家”、“家的”
字对不一定是双字词 “展中”、“中国”、 “家的”
作用: 单字出现的条件概率 例如:P(国|中)=P(中, 国)/P(中) 。计算中必然要用到单字出现的概率,因此做双字字频统计往往同时做单字字频统计,除非单字字频已经统计过
双字的相关性

六、英文词法分析
6.1 英文断词
6.1.1 句点引起的歧义
句点的作用 :(1)句子结束(2)小数点 (3)缩写 (4)缩略
歧义现象:缩写中的句点位于单词的后面,同句号产生冲突
解决方法:通常采用基于规则的方法
(1)不借助词表
单个字母后接一个句点 如 M. H. Thatcher
连续的“字母-句点”序列 如 U. S.
一个大写字母后接若干辅音小写字母及句点 如 Mr.
(2)借助词表(通用词表、缩略词表)
将待判定的字符串记为S,字符串及后面的句点记为S’
S在通用词表中存在,则S’不是缩写
S’在缩写词表中存在,则S’是缩写
S’后是小写字母、数字、逗号、分号、叹号或问号, 则S’是缩写
S’后的单词首字母大写,则S’不是缩写
当S及S’在词表中均不存在时,或以上几条规则有冲突时,利用篇章信息
S在篇章中其他地方出现过,而S’未出现,则S’不是缩写
S’在篇章中其他地方出现过,而S未出现,则S’是缩写
6.1.2 撇号引起的歧义
撇号的作用 :主要用于构成英文的动词缩写式和名词所有格。
歧义现象:两种方式不好区分。
解决方法:分成两个单元。
6.1.3 连字符引起的歧义
连字符的功能 :
构成合成词
固定成词,如:e-mail,co-operate
根据特定用法或语言环境生成的词,如four-year,1983-1987,All-In-One
在排版时调整格式 ,此时需去掉连字符
歧义现象 :第一类功能的连字符恰好处于行尾
解决方案:主要通过词表解决
6.1.4 断句
歧义现象:多个句末点号 例如:!!
解决方法:找到句末标点时,不能认为这一句已结束,应该再往后搜索,直到不是句末点号为止。
歧义现象:句末点号之后还有右侧标号
例子:“这是你的课本吗?”“不是,是小张的。”他微笑着回答。
解决方法:发现(若干个连续的)句末点号之后,如果遇到右侧标号,还应该搜索完所有连续的右侧标号。
6.2 英文形态还原
英语形态还原(:去除屈折型语言的词尾形态变化,将其还原为词的原形,即词元(lemma)。
基于规则的形态还原方法:
动词:-ed -ing -s
名词: -s -’s
形容词: -er -est -ly
七、汉语自动分词
什么是汉语自动分词 :
用空格或其它标记把词跟词分开
词是语言中能自由运用的基本单位
中文信息处理中必不可少的第一道工序
汉语分词的实现途径 :
人工分词 :工作量大、难以处理大规模语料
计算机自动分词 :速度快、一致性好、一般来说正确率比人工分词低
7.1 汉语自动分词中的基本问题
7.1.1 分词标准
7.1.2 切分歧义
(1)交集型歧义切分
定义 :一个汉字串包含A、B、C三个子串,AB和BC都是词,到底应该切成AB/C还是切成A/BC
例子:“乒乓球拍卖完了”
乒乓球/拍卖/完/了
乒乓球拍/卖/完/了
(2)组合型歧义切分
定义 :包含至少两个汉字的汉字串,它本身是词,切开来也分别是词
例子 :个人
屋子/里/只/有/一/个/人
这/是/我/个人/的/意见
“真歧义”和“伪歧义”:
真歧义 :存在两种或两种以上的可实现的切分形式
伪歧义 :一般只有一种正确的切分形式
7.1.3 未登录词
汉语未登录词的种类 :
专有名词 实体名词 衍生词 新词(普通词汇或专业术语)
歧义场景:
专有名词的首词和尾词可能与上下文中的其它词汇存在交集型歧义切分
例子:南京市长江大桥。
7.2 基本分词方法
(1)最大匹配法
匹配: 分词过程中用文本中的候选词去跟词表中的词匹配
匹配成功,则认为候选词是词,予以切分。否则就认为不是词
最大匹配: 尽可能地用最长的词来匹配句子中的汉字串,例如 “社会”和“社会主义”
切出来的词尽可能长,词数尽可能少
(2)最少分词法(最短路径法)
基本思想 :分词结果中含词数最少
等价于在有向图中搜索最短路径问题
(3)最大概率法(最短加权路径法)
基本思想:根据信源-信道模型,认为词串经过信道传送,由于噪声干扰而丢失了词界标记,到输出端便成了一个汉字串
自动分词就是已知一个汉字串,求跟它对应的、有最大概率的词串
概率最大的词串,便是最佳的词串
(4)与词性标注相结合的分词方法
基本思想 :将自动分词和基于Markov链的词性自动标注技术结合起来,利用从人工标注语料库中提取出的词性二元统计规律来消解切分歧义
将分词和词类标注结合起来,利用丰富的词类信息对分词决策提供帮助,并且在标注过程中又反过来对分词结果进行检验、调整,从而极大地提高切分的准确率
(5)基于互现信息的分词方法
基本思想: 从形式上看,词是稳定的字的组合。因此,相邻的字同时出现的次数越多,就越有可能构成一个词
(6)基于字分类的分词方法
基本思想: 将分词过程看作是字的分类问题
每个字有4种词位 词首(B) 词中(M) 词尾(E) 单独成词(S)
(7)基于实例的汉语分词方法
基本思想 :在训练语料中已经存在的事先切分好的汉字串为以后输入的待切分句子提供可靠的实例
八、词性标注
词性标注 :根据一个词在某个特定句子中的上下文,为这个词标注正确的词性
8.1 基于规则的词性标注方法
基本思想: 按照兼类词搭配关系和上下文语境建立词性消歧规则
步骤: Step1:使用一部词典给每个单词指派一个潜在词性表
Step2:使用歧义消解规则表来筛选原来的潜在词性表,使每个单词得到一个单独的词性标记
8.2 基于统计的词性标注方法
(1)基于马尔科夫模型的词性标注
(2)基于HMM的词性标注
已知一个词串(观察值序列),求跟它对应的、有最大概率的词性标记串(隐状态序列)
(3)分词与词性标注一体化模型
已知一个字串,求跟它对应的、有最大概率的词及词性串
8.3 统计与规则相结合的方法
基于转换的错误驱动学习
它是机器学习中基于转换的学习方法的一个实例
从基于规则的方法和基于统计的方法中得到了启示
与基于规则的方法相似:TBL是基于规则的
与基于统计的方法相似:TBL是一种机器学习技术,其中的规则是从数据自动推导出来的。TBL是一种有指导的学习技术,在标注之前需要有一个训练语料库。

九、语法分析
句法 :句子的构成方法。通常以规则的形式表示。
句法分析( Syntactic Parsing ) :根据句法规则,分析给定句子的结构。
例子:The boy put the tortoise on the rug
9.1 句子结构的两种观点
9.1.1 短语结构( Phrase structure / Constituency )

低级:冠词+名词=名词短语
中级:介词+名词短语=介词短语 动词+名词短语=动词短语,动词短语+介词短语=动词短语
高级:名词短语+动词短语=句子
9.1.2 依存结构( Dependency structure )
依存结构: “依存”是指词语词之间支配与被支配的关系
处于支配地位的成分称为支配者(head);
处于被支配地位的成分称为从属者(modifier,dependency)
箭头从支配者指向从属者
动词是句子的中心并支配别的成分,它本身不受任何其他成分支配。

动词支配一切
介词-->名词-->冠词
9.2 文法的描述

一条“产生式”就是一条句法规则。
不同类型的文法对规则的形式有不同的限制。
句法分析前首先要确定使用什么类型的文法
9.2.1 无约束短语结构文法
α→β
0型文法,对产生式没有任何限制
0型语言:由0型语法生成的语言
生成能力太强,无法设计一个程序来判别输入的符号串是不是0型语言中的一个句子
9.2.2 上下文有关文法
α→β ( |α|≤|β| )
1型文法,规则左部的符号个数少于或等于规则右部的符号个数
1型语言:由1型文法生成的语言
Example:xYz →xyz
9.2.3 上下文无关文法
A→β (A是非终结符,β是终结符和/或非终结符组合)
2型文法,产生式的左部是一个非终结符
2型语言:由2型文法生成的语言
Example: Y→y
9.2.4 正则文法
右线性文法
A→βB
A和B是非终结符,β是终结符组合
左线性文法
A→Bβ
A和B是非终结符,β是终结符组合
右线性文法和左线性文法都是正则文法,并且二者是等价的
9.2.5 四种文法类型的比较

0型文法生成能力太强
上下文有关文法(1型)的分析算法过于复杂
上下文无关文法(2型)的规则体系便于构造,是研究得最多的一种文法
正则文法(3型)通常用于词法分析
9.3 自底向上的句法分析
基本思想 :最左归约(归约是推导的逆过程)
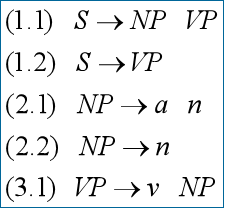
9.3.1 移进-归约算法
9.3.2 欧雷(Earley)分析法
9.3.3 线图分析法
9.3.4 CYK分析法
9.3.5 扩展CYK分析法

