
热门标签
热门文章
- 1【THM】Protocols and Servers(协议和服务器)-初级渗透测试
- 2深度学习中文本处理4种方式_深度学习文本处理的方法
- 3TfidfVectorizer与CountVectorizer的对比_countvectorizer vectorizer.fit_transform
- 4深入理解CSS过渡transition
- 5接口测试|HttpRunner模拟发送GET请求&;自动生成测_成都 卓胜微 加班
- 6Linux环境使用VSCode调试简单C++代码_linux vscode c++
- 7【吴恩达】prompt engineering(原则 迭代 文本概括 推断、订餐机器人)
- 8小米商城(HTML5+CSS3版)_html js css小米商城
- 9pytorch基本语法
- 10用 Python 实现英文单词纠错功能
当前位置: article > 正文
sentence_transformers 教程_sentence transformer loss
作者:我家小花儿 | 2024-04-05 19:41:21
赞
踩
sentence transformer loss
文档:Search — Sentence-Transformers documentation
用途:
该模主要用来做句子嵌入,下游常用来做语意匹配
ContrastiveLoss
别名:
pairwise ranking loss
pairwise loss
公式:
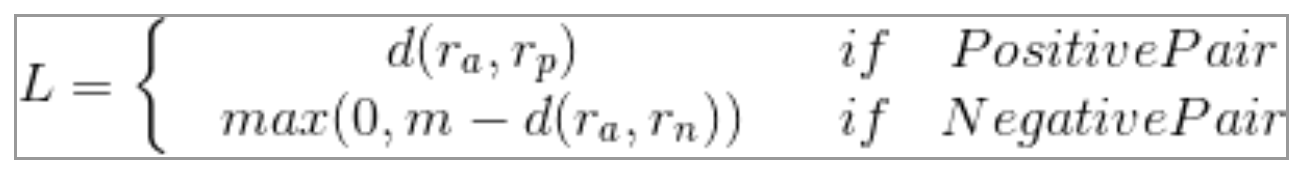
loss = y*||anchor - positive|| +(1-y)*max(margin-||anchor - negative||, 0).
- # 损失函数代码表示,摘自 sentence transformers
- losses = 0.5 * (labels.float() * distances.pow(2) + (1 - labels).float() * F.relu(self.margin - distances).pow(2))
- from sentence_transformers import SentenceTransformer, LoggingHandler, losses, InputExample
- from torch.utils.data import DataLoader
-
- model = SentenceTransformer('all-MiniLM-L6-v2')
- train_examples = [
- InputExample(texts=['This is a positive pair', 'Where the distance will be minimized'], label=1),
- InputExample(texts=['This is a negative pair', 'Their distance will be increased'], label=0)]
-
- train_dataloader = DataLoader(train_examples, shuffle=True, batch_size=2)
- train_loss = losses.ContrastiveLoss(model=model)
-
- model.fit([(train_dataloader, train_loss)], show_progress_bar=True)
CosineSimilarityLoss
计算出样本的余弦相似度,和label做MSE损失
- from sentence_transformers import SentenceTransformer, InputExample, losses
- from torch.utils.data import DataLoader
-
- #Define the model. Either from scratch of by loading a pre-trained model
- model = SentenceTransformer('distilbert-base-nli-mean-tokens')
-
- #Define your train examples. You need more than just two examples...
- train_examples = [InputExample(texts=['My first sentence', 'My second sentence'], label=0.8),
- InputExample(texts=['Another pair', 'Unrelated sentence'], label=0.3)]
-
- #Define your train dataset, the dataloader and the train loss
- train_dataloader = DataLoader(train_examples, shuffle=True, batch_size=16)
- train_loss = losses.CosineSimilarityLoss(model)
-
- #Tune the model
- model.fit(train_objectives=[(train_dataloader, train_loss)], epochs=1, warmup_steps=100)

MultipleNegativesRankingLoss
对比损失,同一批次的,其它样本视为负样本,分别两两求余弦相似度,最后做交叉熵损失,正样本的得分应该最高
- train_examples = [InputExample(texts=['Anchor 1', 'Positive 1']),
- InputExample(texts=['Anchor 2', 'Positive 2'])]
- train_dataloader = DataLoader(train_examples, shuffle=True, batch_size=32)
- train_loss = losses.MultipleNegativesRankingLoss(model=model)
TripletLoss
loss = max(||anchor - positive|| - ||anchor - negative|| + margin, 0).
- from sentence_transformers import SentenceTransformer, SentencesDataset, LoggingHandler, losses
- from sentence_transformers.readers import InputExample
-
- model = SentenceTransformer('distilbert-base-nli-mean-tokens')
- train_examples = [InputExample(texts=['Anchor 1', 'Positive 1', 'Negative 1']),
- InputExample(texts=['Anchor 2', 'Positive 2', 'Negative 2'])]
- train_dataset = SentencesDataset(train_examples, model)
- train_dataloader = DataLoader(train_dataset, shuffle=True, batch_size=train_batch_size)
- train_loss = losses.TripletLoss(model=model)
本文内容由网友自发贡献,转载请注明出处:【wpsshop博客】
推荐阅读
相关标签

