
热门标签
热门文章
- 1余承东回应高通对华为恢复 5G 芯片供应;ChatGPT 发布重要更新;微软推出免费 AI 入门课|极客头条...
- 2圣诞将至:python3几行代码教你写出圣诞树。_pycharm圣诞树代码
- 3Matlab怎么计算信号的能量,Matlab小波包分解后如何求各频带信号的能量值? [转]...
- 4php rabbitmq公用类库,RabbitMQ(消息队列)的PHP类库php-amqplib详解
- 5python小波变换绘制频谱图和等线图_python小波分析绘图
- 6如何使用各种工具和命令来检查 Ubuntu 中的 CPU 使用情况?_ubuntu查看cpu占用率
- 7前端多语言开发,如何中英文切换_前端中英文切换方案
- 8java基于opencv图片灰度处理小工具_在java中使用opencv处理网络图片
- 9关于如何理解Glibc堆管理器(Ⅹ——完结、补充、注释——Arena、heap_info、malloc_*)_glibc arena
- 10小程序面试题100问
当前位置: article > 正文
LLM探索:GPT类模型的几个常用参数 Top-k, Top-p, Temperature_llm微调 top-p
作者:你好赵伟 | 2024-04-07 01:42:42
赞
踩
llm微调 top-p
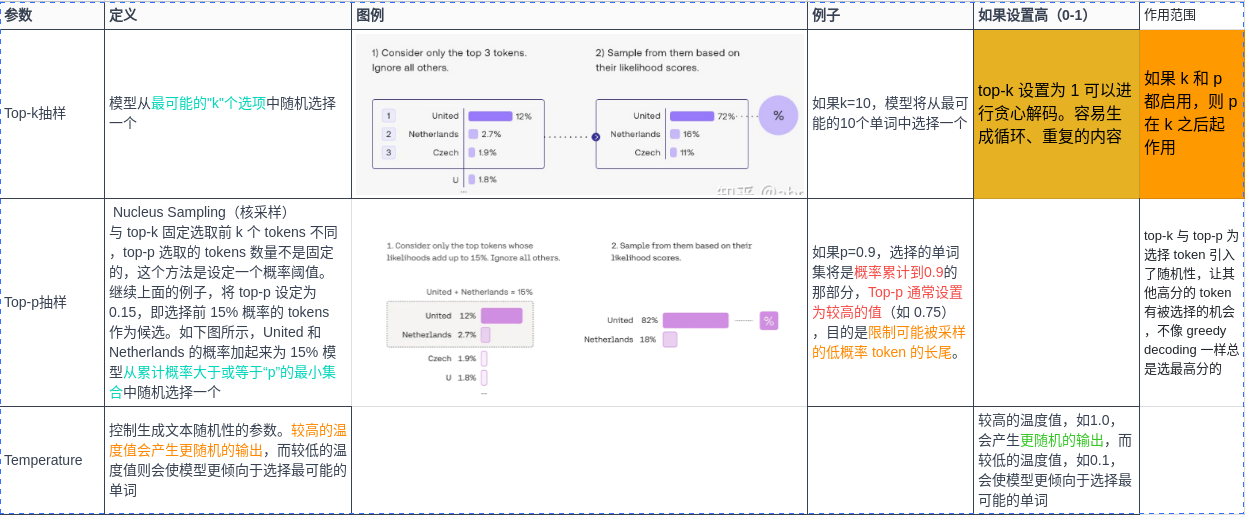
| Top-k抽样 | 模型从最可能的"k"个选项中随机选择一个 | 如果k=10,模型将从最可能的10个单词中选择一个 |
| Top-p抽样 | 模型从累计概率大于或等于“p”的最小集合中随机选择一个 | 如果p=0.9,选择的单词集将是概率累计到0.9的那部分 |
| Temperature | 控制生成文本随机性的参数。较高的温度值会产生更随机的输出,而较低的温度值则会使模型更倾向于选择最可能的单词 | 较高的温度值,如1.0,会产生更随机的输出,而较低的温度值,如0.1,会使模型更倾向于选择最可能的单词 |
前言
上一篇文章介绍了几个开源LLM的环境搭建和本地部署,在使用ChatGPT接口或者自己本地部署的LLM大模型的时候,经常会遇到这几个参数,本文简单介绍一下~
- temperature
- top_p
- top_k
关于LLM
上一篇也有介绍过,这次看到一个不错的图
A recent breakthrough in artificial intelligence (AI) is the introduction of language processing technologies that enable us to build more intelligent systems with a richer understanding of language than ever before. Large pre-trained Transformer language models, or simply large language models, vastly extend the capabilities of what systems are able to do with text.

LLM看似很神奇,但本质还是一个概率问题,神经网络根据输入的文本,从预训练的模型里面生成一堆候选词,选择概率高的作为输出,上面这三个参数,都是跟采样有关(也就是要如何从候选词里选择输出)。
temperature
用于控制模型输出的结果的随机性,这个值越大随机性越大。一般我们多次输入相同的prompt之后,模型的每次输出都不一样。
- 设置为 0,对每个prompt都生成固定的输出
- 较低的值,输出更集中,更有确定性
- 较高的值,输出更随机(更有创意声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/你好赵伟/article/detail/375596
推荐阅读
相关标签
Copyright © 2003-2013 www.wpsshop.cn 版权所有,并保留所有权利。

