
- 1仿百度文库方案[openoffice.org 3+swftools+flexpaper](七) 之 使用iText将jpg、jpeg、png转换为pdf...
- 2第八讲_ArkTS装饰器(五)_arkts 装饰器
- 3深度学习新星:GAN的基本原理、应用和走向_fsrcnn和gan
- 4docker小白采坑---启动失败---空间不足
- 5【使用 BERT 的问答系统】第 5 章 :BERT模型应用:问答系统_faq问答系统bert模型
- 6区块链达摩院落地 国研政情·经信研究:夜总会走出来阿里先锋
- 7【STM32学习笔记】(5)—— STM32工程添加源文件和头文件_stm32怎么添加头文件
- 8高效实用|ChatGPT指令/提示词/prompt/AI指令大全,基础版_让chatgpt修改文章的prompt
- 9MATLAB 自定义均值滤波 (53)
- 10西南科技大学数字电子技术实验二(SSI逻辑器件设计组合逻辑电路及FPGA实现 )FPGA部分_ssi组合逻辑电路实验
每日学术速递1.30_gligen
赞
踩
CV - 计算机视觉 | ML - 机器学习 | RL - 强化学习 | NLP 自然语言处理
更多Ai资讯:

今天带来的arXiv上最新发表的3篇文本图像的生成论文。
Subjects: cs.LG、cs.Cv、cs.AI、cs.CL
1.StyleGAN-T: Unlocking the Power of GANs for Fast Large-Scale Text-to-Image Synthesis

标题:StyleGAN-T:释放GANs的力量,实现快速的大规模文本到图像的合成
作者: Axel Sauer, Tero Karras, Samuli Laine, Andreas Geiger, Timo Aila
文章链接:https://arxiv.org/abs/2301.09515v1
项目代码:https://github.com/autonomousvision/stylegan-t
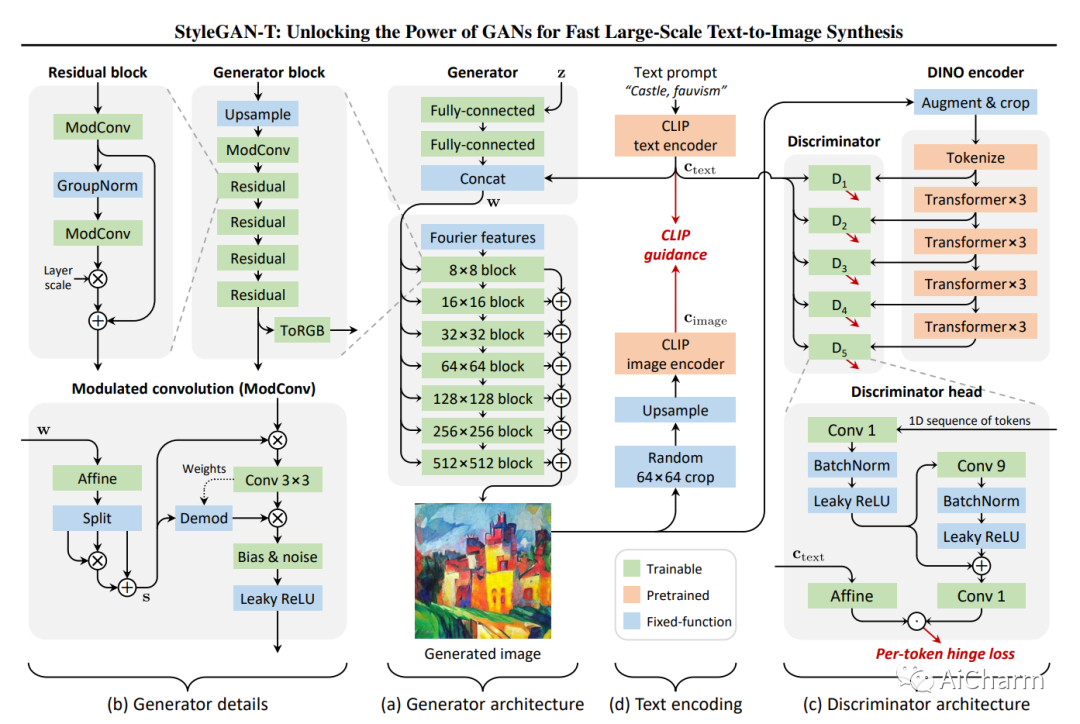
摘要:
由于大型的预训练语言模型、大规模的训练数据以及可扩展的模型系列(如扩散和自回归模型)的引入,文本-图像合成最近取得了重大进展。然而,表现最好的模型需要迭代评估以生成单一样本。相比之下,生成式对抗网络(GANs)只需要一次前向传递。因此,它们的速度要快得多,但目前在大规模文本到图像合成方面仍然远远落后于最先进的水平。本文旨在确定重新获得竞争力的必要步骤。我们提出的模型StyleGAN-T解决了大规模文本-图像合成的具体要求,如大容量、在不同数据集上的稳定训练、强文本对齐和可控的变化与文本对齐的权衡。StyleGAN-T在样本质量和速度方面明显优于以前的GANs,并且优于蒸馏扩散模型--以前快速文本到图像合成的最先进技术。
Text-to-image synthesis has recently seen significant progress thanks to large pretrained language models, large-scale training data, and the introduction of scalable model families such as diffusion and autoregressive models. However, the best-performing models require iterative evaluation to generate a single sample. In contrast, generative adversarial networks (GANs) only need a single forward pass. They are thus much faster, but they currently remain far behind the state-of-the-art in large-scale text-to-image synthesis. This paper aims to identify the necessary steps to regain competitiveness. Our proposed model, StyleGAN-T, addresses the specific requirements of large-scale text-to-image synthesis, such as large capacity, stable training on diverse datasets, strong text alignment, and controllable variation vs. text alignment tradeoff. StyleGAN-T significantly improves over previous GANs and outperforms distilled diffusion models - the previous state-of-the-art in fast text-to-image synthesis - in terms of sample quality and speed.
2.GLIGEN: Open-Set Grounded Text-to-Image Generation

标题:GLIGEN: 开放式基础文本到图像的生成
作者: Yuheng Li, Haotian Liu, Qingyang Wu, Fangzhou Mu, Jianwei Yang, Jianfeng Gao, Chunyuan Li, Yong Jae Lee
文章链接:https://arxiv.org/abs/2301.07093v1
项目代码:https://github.com/gligen/GLIGEN
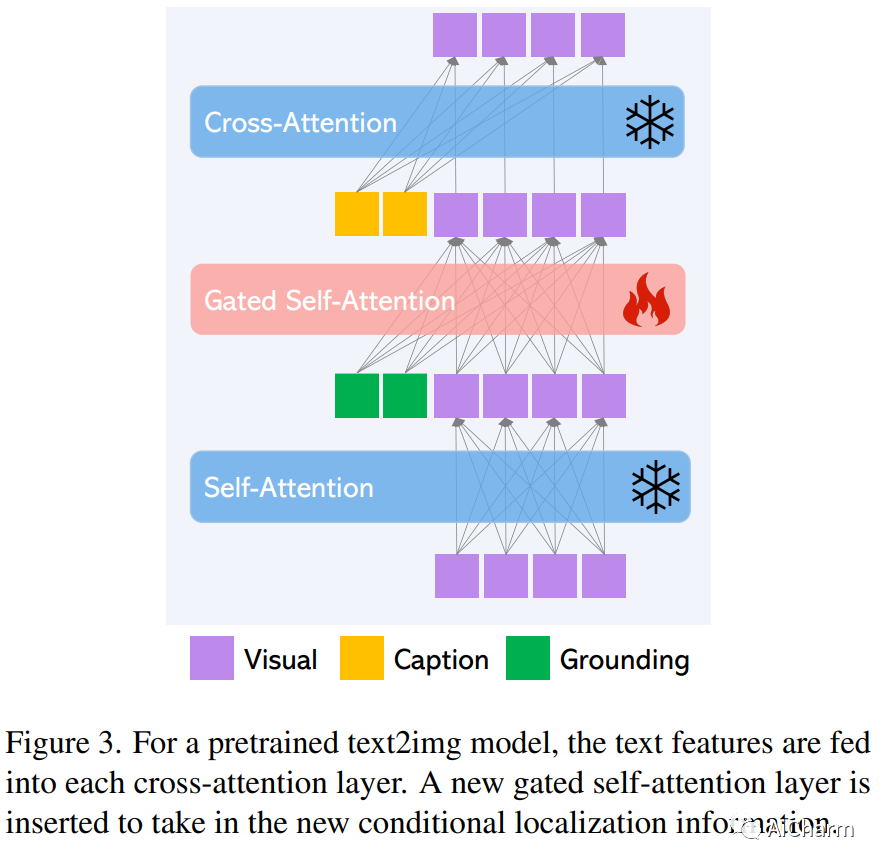
摘要:
大规模的文字到图像的扩散模型已经取得了惊人的进展。然而,现状是只使用文本输入,这可能会阻碍可控性。在这项工作中,我们提出了GLIGEN,即接地语言到图像的生成,这是一种新颖的方法,它建立在现有的预训练的文本到图像扩散模型的基础上,并通过使它们也能以接地输入为条件而扩展其功能。为了保留预训练模型的大量概念知识,我们冻结了它的所有权重,并通过一个门控机制将接地信息注入新的可训练层中。我们的模型在标题和边界框条件输入的情况下实现了开放世界接地的text2img生成,并且接地能力可以很好地推广到新的空间配置和概念。GLIGEN在COCO和LVIS上的0-shot性能大大超过了现有的监督布局-图像基线。
Large-scale text-to-image diffusion models have made amazing advances. However, the status quo is to use text input alone, which can impede controllability. In this work, we propose GLIGEN, Grounded-Language-to-Image Generation, a novel approach that builds upon and extends the functionality of existing pre-trained text-to-image diffusion models by enabling them to also be conditioned on grounding inputs. To preserve the vast concept knowledge of the pre-trained model, we freeze all of its weights and inject the grounding information into new trainable layers via a gated mechanism. Our model achieves open-world grounded text2img generation with caption and bounding box condition inputs, and the grounding ability generalizes well to novel spatial configuration and concepts. GLIGEN's zero-shot performance on COCO and LVIS outperforms that of existing supervised layout-to-image baselines by a large margin
3.Muse: Text-To-Image Generation via Masked Generative Transformers

标题:Muse:通过遮蔽的生成性变换器进行文本到图像的生成
作者: Huiwen Chang, Han Zhang, Jarred Barber, AJ Maschinot, Jose Lezama, Lu Jiang, Ming-Hsuan Yang, Kevin Murphy, William T. Freeman, Michael Rubinstein, Yuanzhen Li, Dilip Krishnan
文章链接:https://arxiv.org/abs/2301.00704v1
项目代码:https://muse-model.github.io
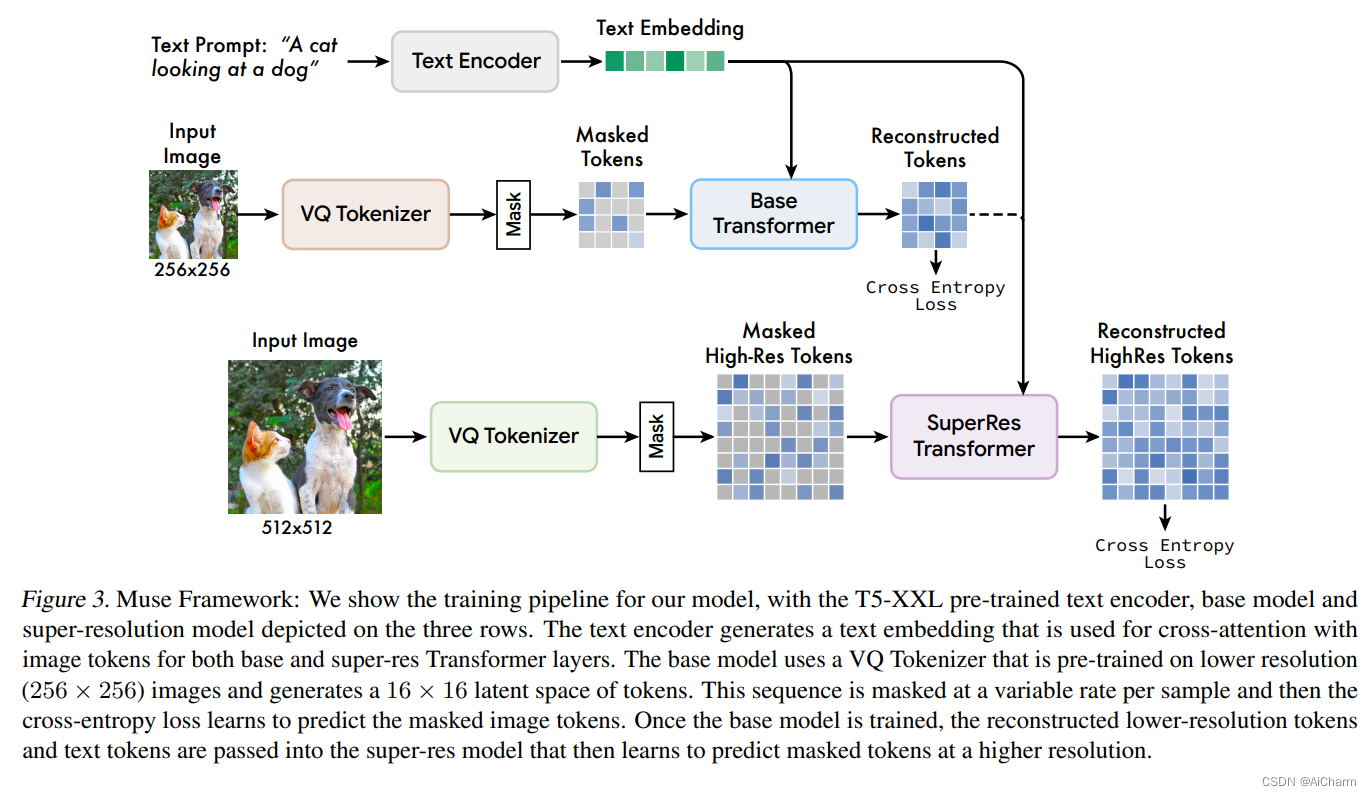
摘要:
我们提出了Muse,一个文本到图像的转化器模型,实现了最先进的图像生成性能,同时比扩散或自回归模型的效率高得多。Muse是在离散标记空间的遮蔽建模任务上训练的:给定从预先训练的大型语言模型(LLM)中提取的文本嵌入,Muse被训练来预测随机遮蔽的图像标记。与像素空间的扩散模型(如Imagen和DALL-E 2)相比,由于使用了离散的标记并需要较少的采样迭代,Muse的效率明显更高;与自回归模型(如Parti)相比,由于使用了并行解码,Muse的效率更高。使用预先训练好的LLM可以实现细粒度的语言理解,转化为高保真的图像生成和对视觉概念的理解,如物体、它们的空间关系、姿态、cardinality等。我们的900M参数模型在CC3M上取得了新的SOTA,FID分数为6.06。Muse 3B参数模型在零次COCO评估中实现了7.88的FID,同时还有0.32的CLIP得分。Muse还直接实现了一些图像编辑应用,而不需要对模型进行微调或反转:内画、外画和无遮挡编辑。
We present Muse, a text-to-image Transformer model that achieves state-of-the-art image generation performance while being significantly more efficient than diffusion or autoregressive models. Muse is trained on a masked modeling task in discrete token space: given the text embedding extracted from a pre-trained large language model (LLM), Muse is trained to predict randomly masked image tokens. Compared to pixel-space diffusion models, such as Imagen and DALL-E 2, Muse is significantly more efficient due to the use of discrete tokens and requiring fewer sampling iterations; compared to autoregressive models, such as Parti, Muse is more efficient due to the use of parallel decoding. The use of a pre-trained LLM enables fine-grained language understanding, translating to high-fidelity image generation and the understanding of visual concepts such as objects, their spatial relationships, pose, cardinality etc. Our 900M parameter model achieves a new SOTA on CC3M, with an FID score of 6.06. The Muse 3B parameter model achieves an FID of 7.88 on zero-shot COCO evaluation, along with a CLIP score of 0.32. Muse also directly enables a number of image editing applications without the need to fine-tune or invert the model: inpainting, outpainting, and mask-free editing.


