
- 1鸿蒙系统评论简单分析(nlp)_nlp评论分类
- 2基于Pytorch和Beam Search的中文聊天机器人_beam search原理与实现聊天机器人
- 3大象机器人人工智能套装2023版深度学习协作机器人、先进机器视觉与应用场景_大象 人工智能
- 4字节跳动招聘启动!校招全职补录 &; 实习生岗位同步上新!_字节跳动2024春招内推码
- 5用手机给随身WiFi刷openwrt和debian教程_手机刷openwrt
- 6python+opencv+yolov5+算能 中的一些疑问
- 7基础课【9】_国产xx
- 8程序访问一个地址时候报400错误,浏览器访问正常怎么解决_url浏览器可以打开 link地址报错
- 92024肥晨赠书活动第二期:《深入浅出React开发指南》
- 10【云端风云:云计算全局解密】一篇文章读懂云计算技术及其未来发展趋势(一万八千字)_iaas、paas 和saas融合发展趋势
【C++】迭代器、反向迭代器详解_c++反向迭代器
赞
踩
参考:
一、迭代器
1. 概述
要访问顺序容器和关联容器中的元素,需要通过“迭代器(iterator)”进行。迭代器是一个变量,相当于容器和操纵容器的算法之间的中介。迭代器可以指向容器中的某个元素,通过迭代器就可以读写它指向的元素。从这一点上看,迭代器和指针类似。
迭代器按照定义方式分成以下四种:
- 正向迭代器,定义方法如下:
容器类名::iterator 迭代器名;
- 1
- 常量正向迭代器,定义方法如下:
容器类名::const_iterator 迭代器名;
- 1
- 反向迭代器,定义方法如下:
容器类名::reverse_iterator 迭代器名;
- 1
- 常量反向迭代器,定义方法如下:
容器类名::const_reverse_iterator 迭代器名;
- 1
2. 迭代器用法示例
通过迭代器可以读取它指向的元素,*迭代器名就表示迭代器指向的元素。通过非常量迭代器还能修改其指向的元素。迭代器都可以进行++操作。
反向迭代器和正向迭代器的区别在于:对正向迭代器进行++操作时,迭代器会指向容器中的后一个元素;而对反向迭代器进行++操作时,迭代器会指向容器中的前一个元素。
下面的程序演示了如何通过迭代器遍历一个 vector 容器中的所有元素:
#include <iostream> #include <vector> using namespace std; int main() { vector<int> v; //v是存放int类型变量的可变长数组,开始时没有元素 for (int n = 0; n<5; ++n) v.push_back(n); //push_back成员函数在vector容器尾部添加一个元素 vector<int>::iterator i; //定义正向迭代器 for (i = v.begin(); i != v.end(); ++i) { //用迭代器遍历容器 cout << *i << " "; //*i 就是迭代器i指向的元素 *i *= 2; //每个元素变为原来的2倍 } cout << endl; //用反向迭代器遍历容器 for (vector<int>::reverse_iterator j = v.rbegin(); j != v.rend(); ++j) cout << *j << " "; return 0; } // 程序的输出结果是: 0 1 2 3 4 8 6 4 2 0

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
-
第 6 行:
vector容器有多个构造函数,如果用无参构造函数初始化,则容器一开始是空的。 -
第 10 行:
begin成员函数返回指向容器中第一个元素的迭代器。++i使得i指向容器中的下一个元素。end成员函数返回的不是指向最后一个元素的迭代器,而是指向最后一个元素后面的位置的迭代器,因此循环的终止条件是i != v.end()。 -
第 16 行:定义了反向迭代器用以遍历容器。反向迭代器进行
++操作后,会指向容器中的上一个元素。rbegin成员函数返回指向容器中最后一个元素的迭代器,rend成员函数返回指向容器中第一个元素前面的位置的迭代器,因此本循环实际上是从后往前遍历整个数组。
注意:如果迭代器指向了容器中最后一个元素的后面或第一个元素的前面,再通过该迭代器访问元素,就有可能导致程序崩溃,这和访问 NULL 或未初始化的指针指向的地方类似。 -
第 10 行和第 16 行:写
++i、++j相比于写i++、j++,程序的执行速度更快。回顾++被重载成前置和后置运算符的例子如下:
CDemo CDemo::operator++ ()
{ //前置++
++n;
return *this;
}
CDemo CDemo::operator ++(int k)
{ //后置++
CDemo tmp(*this); //记录修改前的对象
n++;
return tmp; //返回修改前的对象
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
后置++要多生成一个局部对象 tmp,因此执行速度比前置的慢。同理,迭代器是一个对象,STL 在重载迭代器的++运算符时,后置形式也比前置形式慢。在次数很多的循环中,++i和i++可能就会造成运行时间上可观的差别了。因此,本教程在前面特别提到,对循环控制变量i,要养成写++i、不写i++的习惯。
注意:容器适配器 stack、queue 和 priority_queue 没有迭代器。容器适配器有一些成员函数,可以用来对元素进行访问。
3. 迭代器的功能分类
不同容器的迭代器,其功能强弱有所不同。容器的迭代器的功能强弱,决定了该容器是否支持 STL 中的某种算法。例如,排序算法需要通过随机访问迭代器来访问容器中的元素,因此有的容器就不支持排序算法。
常用的迭代器按功能强弱分为:输入、输出、正向、双向、随机访问五种,这里只介绍常用的三种:
-
正向迭代器。假设
p是一个正向迭代器,则p支持以下操作:++p,p++,*p。此外,两个正向迭代器可以互相赋值,还可以用==和!=运算符进行比较。 -
双向迭代器。双向迭代器具有正向迭代器的全部功能。除此之外,若
p是一个双向迭代器,则--p和p--都是有定义的。--p使得p朝和++p相反的方向移动。 -
随机访问迭代器。随机访问迭代器具有双向迭代器的全部功能。若
p是一个随机访问迭代器,i是一个整型变量或常量,则p还支持以下操作:
p+=i:使得p往后移动i个元素。
p-=i:使得p往前移动i个元素。
p+i:返回p后面第i个元素的迭代器。
p-i:返回p前面第i个元素的迭代器。
p[i]:返回p后面第i个元素的引用。此外,两个随机访问迭代器
p1、p2还可以用<、>、<=、>=运算符进行比较。p1<p2的含义是:p1经过若干次(至少一次)++操作后,就会等于p2。其他比较方式的含义与此类似。对于两个随机访问迭代器
p1、p2,表达式p2-p1也是有定义的,其返回值是p2所指向元素和p1所指向元素的序号之差(也可以说是p2和p1之间的元素个数减一)。
下表所示为不同容器的迭代器的功能:
| 容器 | 迭代器功能 |
|---|---|
| vector | 随机访问 |
| deque | 随机访问 |
| list | 双向 |
| set / multiset | 双向 |
| map / multimap | 双向 |
| stack | 不支持迭代器 |
| queue | 不支持迭代器 |
| priority_queue | 不支持迭代器 |
例如,vector 的迭代器是随机迭代器,因此遍历 vector 容器有以下几种做法。下面的程序中,每个循环演示了一种做法。
【实例】遍历 vector 容器:
#include <iostream> #include <vector> using namespace std; int main() { vector<int> v(100); //v被初始化成有100个元素 for(int i = 0;i < v.size() ; ++i) //size返回元素个数 cout << v[i]; //像普通数组一样使用vector容器 vector<int>::iterator i; for(i = v.begin(); i != v.end (); ++i) //用 != 比较两个迭代器 cout << * i; for(i = v.begin(); i < v.end ();++i) //用 < 比较两个迭代器 cout << * i; i = v.begin(); while(i < v.end()) { //间隔一个输出 cout << * i; i += 2; // 随机访问迭代器支持 "+= 整数" 的操作 } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
list 容器的迭代器是双向迭代器。假设 v 和 i 的定义如下:
list<int> v;
list<int>::const_iterator i;
- 1
- 2
则以下代码是合法的:
for(i=v.begin(); i!=v.end(); ++i)
cout << *i;
- 1
- 2
以下代码则不合法:
for(i=v.begin(); i<v.end(); ++i)
cout << *i;
- 1
- 2
因为双向迭代器不支持用“<”进行比较。以下代码也不合法:
for(int i=0; i<v.size(); ++i)
cout << v[i];
- 1
- 2
因为 list 不支持随机访问迭代器的容器,也不支持用下标随机访问其元素。
在 C++ 中,数组也是容器。数组的迭代器就是指针,而且是随机访问迭代器。例如,对于数组 int a[10],int * 类型的指针就是其迭代器。则 a、a+1、a+2 都是 a 的迭代器。
4. 迭代器的辅助函数
STL 中有用于操作迭代器的三个函数模板,它们是:
advance(p, n):使迭代器 p 向前或向后移动 n 个元素。distance(p, q):计算两个迭代器之间的距离,即迭代器 p 经过多少次 + + 操作后和迭代器 q 相等。如果调用时 p 已经指向 q 的后面,则这个函数会陷入死循环。iter_swap(p, q):用于交换两个迭代器 p、q 指向的值。
要使用上述模板,需要包含头文件 algorithm。下面的程序演示了这三个函数模板的用法:
#include <list> #include <iostream> #include <algorithm> //要使用操作迭代器的函数模板,需要包含此文件 using namespace std; int main() { int a[5] = { 1, 2, 3, 4, 5 }; list <int> lst(a, a+5); list <int>::iterator p = lst.begin(); advance(p, 2); //p向后移动两个元素,指向3 cout << "1)" << *p << endl; //输出 1)3 advance(p, -1); //p向前移动一个元素,指向2 cout << "2)" << *p << endl; //输出 2)2 list<int>::iterator q = lst.end(); q--; //q 指向 5 cout << "3)" << distance(p, q) << endl; //输出 3)3 iter_swap(p, q); //交换 2 和 5 cout << "4)"; for (p = lst.begin(); p != lst.end(); ++p) cout << *p << " "; return 0; } // 程序的输出结果是: 1) 3 2) 2 3) 3 4) 1 5 3 4 2
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
二、反向迭代器
1. 概述
反向迭代器是一种反向遍历容器的迭代器。也就是,从最后一个元素到第一个元素遍历容器。反向迭代器将自增(和自减)的含义反过来了:对于反向迭代器,++ 运算将访问前一个元素,而 -- 运算则访问下一个元素。
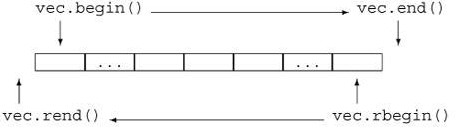
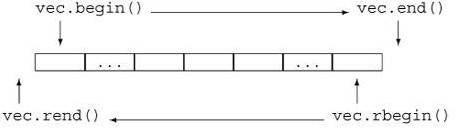
回想一下,所有容器都定义了 begin 和 end 成员,分别返回指向容器首元素和尾元素下一位置的迭代器。这两个迭代器通常用于标记包含容器中所有元素的迭代范围。容器还定义了 rbegin 和 rend 成员,分别返回指向容器尾元素和首元素前一位置的反向迭代器。与普通迭代器一样,反向迭代器也有常量(const)和非常量(nonconst)类型。
-
c.begin()返回一个迭代器,它指向容器c的第一个元素; -
c.end()返回一个迭代器,它指向容器c的最后一个元素的下一个位置; -
c.rbegin()返回一个逆序迭代器,它指向容器c的最后一个元素; -
c.rend()返回一个逆序迭代器,它指向容器c的第一个元素前面的位置;上述每个操作都有两个不同的版本:一个是
const成员,另一个是非const成员。这些操作返回什么类型取决于容器是否为const。如果容器不是const,则这些操作返回iterator或reverse_iterator类型。如果容器是const,则其返回类型要加上const_前缀,也就是const_iterator和const_reverse_iterator类型。
2. 反向迭代器示例
假设有一个 vector 容器对象,存储 0-9 这 10 个以升序排列的数字:
vector<int> vec;
for (vector<int>::size_type i = 0; i != 10; ++i)
vec.push_back(i); // elements are 0,1,2,...9
- 1
- 2
- 3
下面的 for 循环将以逆序输出这些元素:
// reverse iterator of vector from back to front
vector<int>::reverse_iterator r_iter;
for (r_iter = vec.rbegin(); // binds r_iter to last element
r_iter != vec.rend(); // rend refers 1 before 1st element
++r_iter) // decrements iterator one element
cout << *r_iter << endl; // prints 9,8,7,...0
- 1
- 2
- 3
- 4
- 5
- 6
虽然颠倒自增和自减这两个操作符的意义似乎容易使人迷惑,但是它让程序员可以透明地向前或向后处理容器。例如,为了以降序排列 vector,只需向 sort传递一对反向迭代器:
// sorts vec in "normal" order
sort(vec.begin(), vec.end());
// sorts in reverse: puts smallest element at the end of vec
sort(vec.rbegin(), vec.rend());
- 1
- 2
- 3
- 4
-
反向迭代器需要使用自减操作符
从一个既支持
--也支持++的迭代器就可以定义反向迭代器,这不用感到吃惊。毕竟,反向迭代器的目的是移动迭代器反向遍历序列。标准容器上的迭代器既支持自增运算,也支持自减运算。但是,流迭代器却不然,由于不能反向遍历流,因此流迭代器不能创建反向迭代器。
3. 反向迭代器与其他迭代器之间的关系
假设有一个名为 line 的 string 对象,存储以逗号分隔的单词列表。我们希望输出 line 中的第一个单词。使用 find 可很简单地实现这个任务:
// find first element in a comma-separated list
string::iterator comma = find(line.begin(), line.end(), ',');
cout << string(line.begin(), comma) << endl;
- 1
- 2
- 3
如果在 line 中有一个逗号,则 comma 指向这个逗号;否则,comma 的值为 line.end()。在输出 string 对象中从 line.begin() 到 comma 的内容时,从头开始输出字符直到遇到逗号为止。如果该 string 对象中没有逗号,则输出整个 string 字符串。
如果要输出列表中最后一个单词,可使用反向迭代器:
// find last element in a comma-separated list
string::reverse_iterator rcomma = find(line.rbegin(), line.rend(), ',');
- 1
- 2
因为此时传递的是 rbegin() 和 rend(),这个函数调用从 line 的最后一个字符开始往回搜索。当 find 完成时,如果列表中有逗号,那么 rcomma 指向其最后一个逗号,即指向反向搜索找到的第一个逗号。如果没有逗号,则 rcomma 的值为 line.rend()。
在尝试输出所找到的单词时,有趣的事情发生了。直接尝试:
// wrong: will generate the word in reverse order
cout << string(line.rbegin(), rcomma) << endl;
- 1
- 2
会产生假的输出。例如,如果输入是:FIRST,MIDDLE,LAST,则将输出 TSAL!
分析:使用反向迭代器时,以逆序从后向前处理 string对象。为了得到正确的输出,必须将反向迭代器 line.rbegin() 和 rcomma 转换为从前向后移动的普通迭代器。其实没必要转换 line.rbegin(),因为我们知道转换的结果必定是 line.end()。只需调用所有反向迭代器类型都提供的成员函数 base 转换 rcomma 即可:
// ok: get a forward iterator and read to end of line
cout << string(rcomma.base(), line.end()) << endl;
- 1
- 2
假设还是前面给出的输入,该语句将如愿输出: LAST。
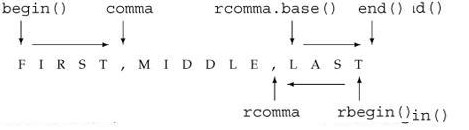
上图直观地解释了普通迭代器与反向迭代器之间的关系。例如,正如 line_rbegin() 和 line.end() 一样,rcomma 和 rcomma.base() 也指向不同的元素。为了确保正向和反向处理元素的范围相同,这些区别是必要的。从技术上来说,设计普通迭代器与反向迭代器之间的关系是为了适应左闭合范围这个性质,所以,[line.rbegin(), rcomma) 和[rcomma.base(), line.end()) 标记的是 line 中的相同元素。
反向迭代器用于表示范围,而所表示的范围是不对称的,这个事实可推导出一个重要的结论:使用普通的迭代器对反向迭代器进行初始化或赋值时,所得到的迭代器并不是指向原迭代器所指向的元素。
三、reverse_iterator的base()函数
1. 示例:
举个例子,看一下这段代码,我们首先把从数字1-5放进一个vector中,然后产生一个指向3的reverse_iterator,并且通过reverse_iterator的base初始化一个iterator:
vector<int> v;
v.reserve(5);
for(int i = 1;i <= 5; ++ i) { // 向vector插入1到5
v.push_back(i);
}
vector<int>::reverse_iterator ri = find(v.rbegin(), v.rend(), 3);
vector<int>::iterator i(ri.base()); // 使i和ri的base一样
- 1
- 2
- 3
- 4
- 5
- 6
- 7
执行上述代码后,可以想到产生的结果就像这样:
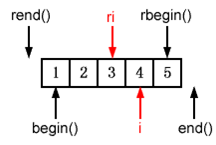
这张图很好地显示了reverse_iterator和它对应的base iterator之间特有的偏移量,就像rbegin()和rend()与相关的begin()和end()一样,但并没有说出了所有你需要知道的东西。特别是,它并没有解释怎样在ri上实现你在i上想要完成的操作。有些容器的成员函数只接受iterator类型的参数,所以如果你想要在ri所指的位置插入一个新元素,你不能直接这么做,因为vector的insert函数不接受reverse_iterator。如果你想要删除ri 所指位置上的元素也会有同样的问题。erase成员函数会拒绝reverse_iterator,坚持要求iterator。为了完成删除和一些形式的插入操作,你必须先通过base函数将reverse_iterator转换成iterator,然后用iterator来完成工作。
2. 插入元素:
先让我们假设你要在ri指出的位置上把一个新元素插入v。特别的,我们假设你要插入的值是99。记住ri在上图中遍历的顺序是自右向左,而且插入操作会将新元素插入到ri位置,并且将原先ri位置的元素移到遍历过程的"下一个"位置,我们认为3应该出现在99的左侧。插入操作之后,v看起来像这样:
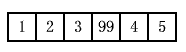
当然,我们不能用ri来指定插入的地方,因为它不是一个iterator。我们必须用i来代替。如上所述,当ri指向3时,i(就是ri.base())指向4。如果我们用ri来指定插入位置,那么用i指向插入位置,那个假设就是正确的。结论呢?
要实现在一个reverse_iterator ri指出的位置上插入新元素,在ri.base()指向的位置插入就行了。对于insert操作而言,ri和ri.base()是等价的,而且ri.base()真的是ri对应的iterator。
3. 删除元素:
现在再来考虑删除元素的情况。回顾一下最初的vector(也就是在插入99之前)ri与i的关系:
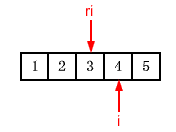
如果你要删除ri指向的元素,你不能直接使用i了,因为i与ri不是指向同一个元素。因此,你要删除的是i的前一个元素。要实现在一个reverse_iterator ri指出的位置上删除元素,就应该删除ri.base()的前一个元素。对于删除操作而言,ri和ri.base()并不等价,而且ri.base()不是ri对应的iterator。我们还是有必要看看删除操作的代码,因为它还挺令人惊讶的。
vector<int> v;
// 向v插入1到5,同上
vecot<int>::reverse_iterator ri =
find(v.rbegin(), v.rend(), 3); // 同上,ri指向3
v.erase(--ri.base()); // 尝试删除ri.base()前面的元素;对于vector,一般来说编译不通过
- 1
- 2
- 3
- 4
- 5
这个设计并不存在什么问题。表达式--ri.base()确实能够指出我们需要删除的元素。而且,它们能够处理除了vector和string之外的其他所有容器,它可能也能处理vector和string,但对于大多数vector和string的实现,它无法处理。在这样的实现下,iterator(和const_iterator)会采用内建的指针来实现,所以ri.base()的结果是一个指针。C和C++都规定了不能直接修改函数返回的指针,所以在string和vector的迭代器是指针的STL平台上,像--ri.base()这样的表达式无法通过编译。要移植从一个由reverse_iterator指出的位置删除元素时,你应该尽量避免修改base的返回值。没问题。如果你不能减少调用base的返回值,只需要先增加reverse_iterator的值,然后再调用base。
// 同上
v.erase((++ri).base()); // 删除ri指向的元素;
// 这下编译没问题了!
- 1
- 2
- 3
因为这个方法适用于所有的标准容器,这是删除一个由reverse_iterator指出的元素时首选的技巧。
现在已经很清楚了,reverse_iterator的base成员函数返回一个"对应的"iterator的说法并不准确。对于插入操作而言,的确如此;但是对于删除操作,并非如此。当需要把reverse_iterator转换成iterator的时候,有一点非常重要的是你必须知道你准备怎么处理返回的iterator,因为只有这样你才能决定你得到的iterator是否是你需要的。

