
- 1NLP-信息抽取:概述【Information Extraction, 从纯文本中进行:①实体抽取与链指(命名实体识别)、②关系抽取、③事件抽取】_实体抽取和命名实体识别
- 2让人失望透顶的 CSDN 博客改版
- 3利用ROS做机器人手眼标定和Qt+rviz+图片话题显示的UI设计_ros手眼标定
- 4watermark java_GitHub - 272130525/BlindWatermark: Java 盲水印
- 5esp8266搭建智能家居系统_esp8266智能家居
- 6哲理故事三百篇(1-50)
- 7ubuntu20.04安装mongoDB
- 8python编程人工智能小例子,python人工智能有趣例子_python编程ai
- 9【Redis】哨兵
- 10鸿蒙入门11-DataPanel组件
【深度学习】前向传播和反向传播(四)_例子展示前项传播与反向传播计算过程
赞
踩
写在最前面的话:今天要梳理的知识点是深度学习中的前/反向传播的计算,所需要的知识点涉及高等数学中的导数运算。
在深度学习中,一个神经网络其实就是多个复合函数组成。函数的本质就是将输入x映射到输出y中,即 f ( x ) = y f(x)=y f(x)=y,而函数中的系数就是我们通过训练确定下来的,那么如何训练这些函数从而确定参数呢?这就涉及网络中的两个计算:前向传播和反向传播。
前向传播
前向传播(Forward Propagation)的理解较为简单,从输入经过一层层隐层计算得到输出的过程即为前向过程,也称前向传播。举个栗子,假设网络中只有一个神经元,
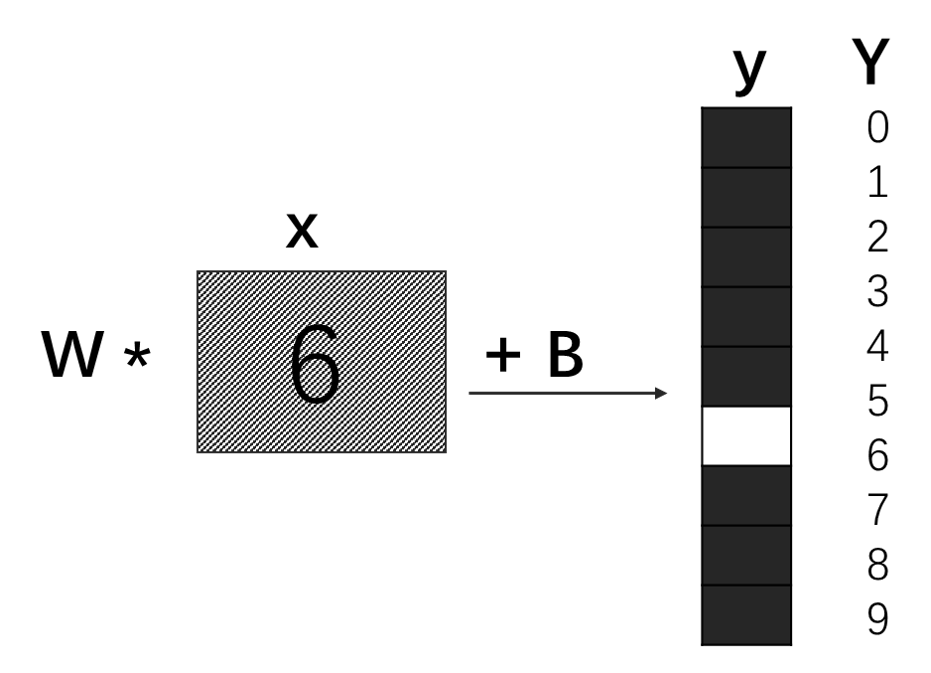
单个神经元网络中,正向传播是:(公式1)
y
=
W
∗
x
+
B
y=W*x+B
y=W∗x+B
而反向传播则是根据(标签值Y-预测值y),来调整W和B。
反向传播
反向传播(Backward Propagation)则是与前向传播的计算方向相反,它是通过输出值与真实值之间的误差,来更新训练参数,具体来说反向传播是根据损失函数,通过网络反向流动来计算每一层参数的梯度(偏导数),从而更新参数。反向传播解决了神经网络中训练模型时参数的更新问题,所以理解反向传播较为重要!对于上面单个神经元网络的栗子,它的损失函数假设为(标签值Y-预测值y)不考虑正则化问题,即:
L
=
Y
−
(
W
∗
x
+
B
)
L=Y-(W*x+B)
L=Y−(W∗x+B)
如果我们想要知道参数W和B对y做了多少贡献(即当W和B改变时,y如何变化),分别对(公式1)中W和B求导。可得到W的贡献为x,而B的贡献为1,因此,我们可以得到
△
W
=
ϑ
L
ϑ
W
=
x
\bigtriangleup W=\frac{\vartheta L}{\vartheta W}=x
△W=ϑWϑL=x,
△
B
=
ϑ
L
ϑ
B
=
1
\bigtriangleup B=\frac{\vartheta L}{\vartheta B}=1
△B=ϑBϑL=1,因此可得更新参数
W
′
=
W
+
△
W
,
B
′
=
B
+
△
B
W'=W+\bigtriangleup W, B'=B+\bigtriangleup B
W′=W+△W,B′=B+△B:
最后通过观察W,B与loss之间的关系:
- 如果正比关系,那么需要降低W/B值,来减少损失值loss
- 如果反比关系,那么需要增大W/B值,来减少损失值loss
以上就是简单的单个神经元网络中的反向传播。如果神经网络较为复杂,我们需要用到链式法则: ϑ L ϑ x = ϑ L ϑ y ϑ y ϑ x \frac{\vartheta L}{\vartheta x}=\frac{\vartheta L}{\vartheta y}\frac{\vartheta y}{\vartheta x } ϑxϑL=ϑyϑLϑxϑy。
太简单的例子相对比较好理解。为了加深上面的理解,我们再举一个多层神经网络,先借用一幅图:
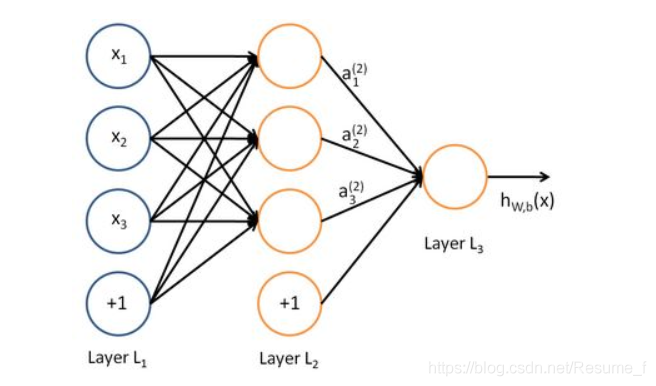
上图显示了多层网络中的L1、L2和L3层,经过L2层的输出为
a
i
(
2
)
a_i^{(2)}
ai(2),经过L3层后的输出为
h
W
,
b
h_{W,b}
hW,b,其中每一层对应的表达式为:
a
1
(
2
)
=
f
(
u
11
(
1
)
x
1
+
u
12
(
1
)
x
2
+
u
13
(
1
)
x
3
+
v
1
(
1
)
)
a_1^{(2)}=f(u_{11}^{(1)}x_1+u_{12}^{(1)}x_2+u_{13}^{(1)}x_3+v_1^{(1)})
a1(2)=f(u11(1)x1+u12(1)x2+u13(1)x3+v1(1))
a
2
(
2
)
=
f
(
u
21
(
1
)
x
1
+
u
22
(
1
)
x
2
+
u
23
(
1
)
x
3
+
v
2
(
1
)
)
a_2^{(2)}=f(u_{21}^{(1)}x_1+u_{22}^{(1)}x_2+u_{23}^{(1)}x_3+v_2^{(1)})
a2(2)=f(u21(1)x1+u22(1)x2+u23(1)x3+v2(1))
a
3
(
2
)
=
f
(
u
31
(
1
)
x
1
+
u
32
(
1
)
x
2
+
u
33
(
1
)
x
3
+
v
3
(
1
)
)
a_3^{(2)}=f(u_{31}^{(1)}x_1+u_{32}^{(1)}x_2+u_{33}^{(1)}x_3+v_3^{(1)})
a3(2)=f(u31(1)x1+u32(1)x2+u33(1)x3+v3(1))
h
W
,
b
(
x
)
=
f
(
W
11
(
2
)
a
1
(
2
)
+
W
12
(
2
)
a
2
(
2
)
+
W
13
(
2
)
a
3
(
2
)
+
b
1
(
2
)
)
h_{W,b}(x)=f(W_{11}^{(2)}a_1^{(2)}+W_{12}^{(2)}a_2^{(2)}+W_{13}^{(2)}a_3^{(2)}+b_1^{(2)})
hW,b(x)=f(W11(2)a1(2)+W12(2)a2(2)+W13(2)a3(2)+b1(2))
其中
W
i
,
j
W_{i,j}
Wi,j和
u
i
,
j
u_{i,j}
ui,j是相邻两层神经元之间的权重(对应图中的相邻两层之间的每一条连线),为深度学习中训练的参数。为了简化上面表达式,我们将上角标去掉,得到:
a
i
=
f
(
u
i
1
x
1
+
u
i
2
x
2
+
u
i
3
x
3
+
v
i
)
=
f
(
U
i
X
i
+
V
i
)
a_i=f(u_{i1}x_1+u_{i2}x_2+u_{i3}x_3+v_i)=f(U_iX_i+V_i)
ai=f(ui1x1+ui2x2+ui3x3+vi)=f(UiXi+Vi)
h
W
,
b
=
f
(
W
i
1
a
1
+
W
i
2
a
2
+
W
i
3
a
3
+
b
i
)
=
f
(
W
i
a
i
+
b
i
)
h_{W,b}=f(W_{i1}a_1+W_{i2}a_2+W_{i3}a_3+b_i)=f(W_ia_i+b_i)
hW,b=f(Wi1a1+Wi2a2+Wi3a3+bi)=f(Wiai+bi)
通常我们采用误差的平方来衡量损失,因此损失函数为:
E
r
r
o
r
=
(
h
−
y
)
,
C
o
s
t
=
(
E
r
r
o
r
)
2
=
(
h
−
y
)
2
Error=(h-y),Cost=(Error)^2=(h-y)^2
Error=(h−y),Cost=(Error)2=(h−y)2
根据链式法则,我们可以得到:
ϑ
C
o
s
t
ϑ
W
=
ϑ
C
ϑ
h
ϑ
h
ϑ
W
=
2
×
(
h
−
y
)
⋅
a
\frac{\vartheta Cost}{\vartheta W}=\frac{\vartheta C}{\vartheta h}\frac{\vartheta h}{\vartheta W}=2\times(h-y)\cdot a
ϑWϑCost=ϑhϑCϑWϑh=2×(h−y)⋅a
ϑ
C
o
s
t
ϑ
U
=
ϑ
C
ϑ
h
ϑ
h
ϑ
a
ϑ
a
ϑ
U
=
2
×
(
h
−
y
)
⋅
w
⋅
x
\frac{\vartheta Cost}{\vartheta U}=\frac{\vartheta C}{\vartheta h}\frac{\vartheta h}{\vartheta a}\frac{\vartheta a}{\vartheta U}=2\times(h-y)\cdot w\cdot x
ϑUϑCost=ϑhϑCϑaϑhϑUϑa=2×(h−y)⋅w⋅x
因此,可以得到参数更新的差值
△
W
=
ϑ
C
o
s
t
ϑ
W
\bigtriangleup W=\frac{\vartheta Cost}{\vartheta W}
△W=ϑWϑCost,
△
U
=
ϑ
C
o
s
t
ϑ
U
\bigtriangleup U=\frac{\vartheta Cost}{\vartheta U}
△U=ϑUϑCost。
总结
本文简单梳理了前向传播和反向传播,以及相关计算。梳理得有点简单,往后想到再继续补充吧~
参考文章:
https://www.cnblogs.com/cation/p/11664741.html
https://blog.csdn.net/qq_16137569/article/details/81449209
https://www.zhihu.com/question/27239198?rf=24827633

