- 1HSTL/off-chip termination FP_VTT_50
- 2LTSPICE使用教程:参数变量和参数扫描_ltspice参数扫描
- 3算法与数据结构 单链表_1.随机产生10个100以内的整数建立一个单链表,显示该单链表中的数据元素; 2.随机产
- 4基于GitHub搭建个人网站_利用github搭建网站
- 5PostgreSQL数据库目录文件详解_pgsql lib路径
- 6【MySQL高级】MySQL锁机制介绍
- 7TinyEngine 开源低代码引擎首次直播答疑Q&A合集_开源在线答疑
- 8孩子都能学会的FPGA:第十三课——利用ROM缓存实现DDS发送器_fpga rom dds
- 9Vue - axios 添加拦截器,配置请求头,添加 token 验证_axios 设置是否需要token
- 10Day95:云上攻防-云原生篇&Docker安全&权限环境检测&容器逃逸&特权模式&危险挂载
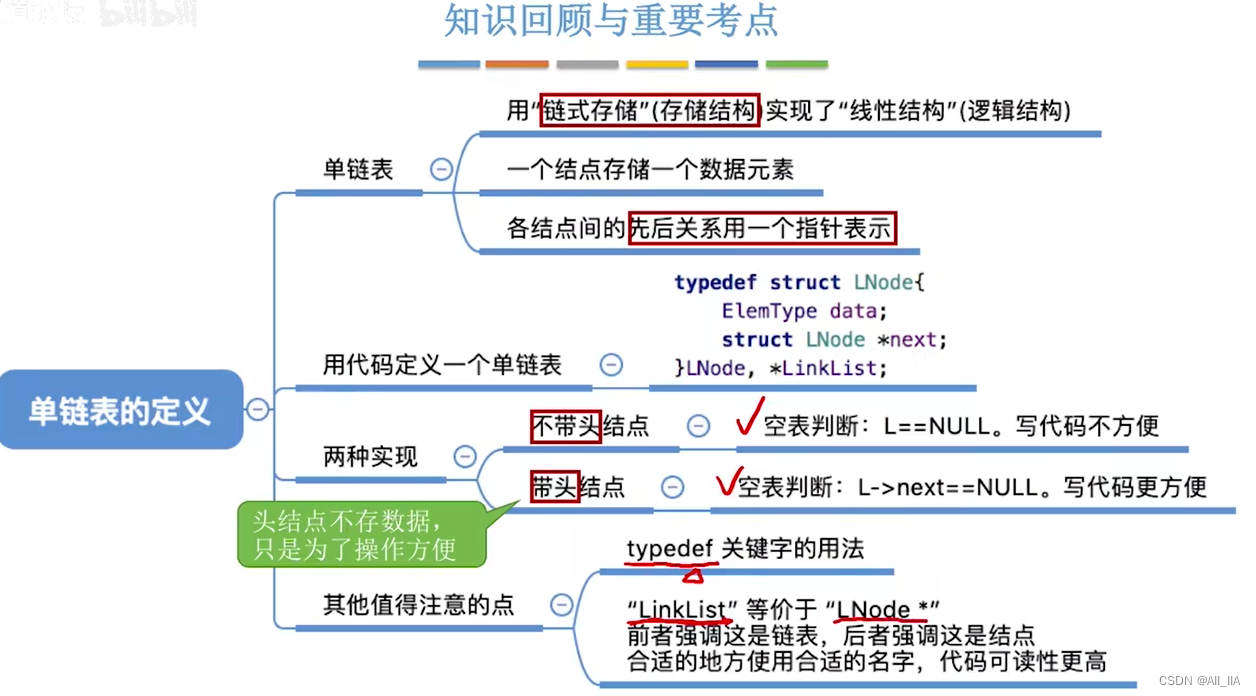
单链表的定义(数据结构与算法)_单链表的定义指针
赞
踩
单链表的定义
单链表是一种常见的数据结构,用于存储元素的序列。它由一系列节点组成,每个节点包含一个数据元素和一个指向下一个节点的引用(指针)。单链表中的节点之间通过指针连接起来,形成一个线性结构。单链表是一种简单但灵活的数据结构,常用于实现队列、堆栈和图等其他高级数据结构。

单链表的特点是每个节点只有一个指针,指向下一个节点,而最后一个节点的指针指向空(null)。这意味着可以从链表的头节点开始,逐个访问每个节点,直到到达链表的末尾。
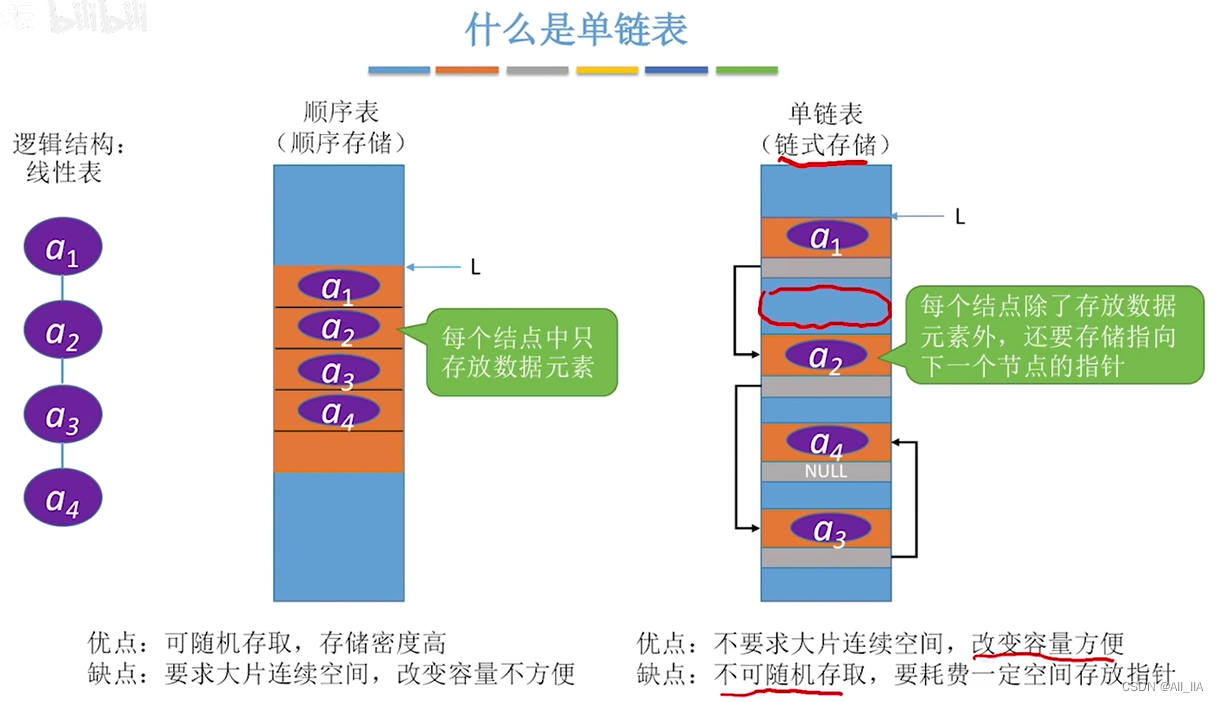
一个单链表包含一个头节点和一些后续的节点。头节点是链表的起点,它不存储任何实际的数据,只是用来标识链表的开始。头节点的指针指向链表中的第一个实际节点,而每个节点的指针则指向下一个节点。
通过这种指针链接,可以在链表中插入、删除和查找元素。插入元素时,只需要修改相应节点的指针,将新的节点插入到链表中的合适位置。删除元素时,需要修改前一个节点的指针,使其指向删除节点的下一个节点,然后将删除节点的内存空间释放。查找元素时,可以从头节点开始沿着指针依次访问链表,直到找到目标元素或到达链表的末尾。
单链表在某些场景下的操作效率较高,例如插入和删除操作,因为只需要修改指针而不需移动大量元素。然而,单链表的缺点是访问特定位置的元素较慢,需要从头节点开始遍历整个链表。此外,单链表不支持直接反向遍历,因为只有每个节点的下一个节点的指针,没有指向前一个节点的指针。
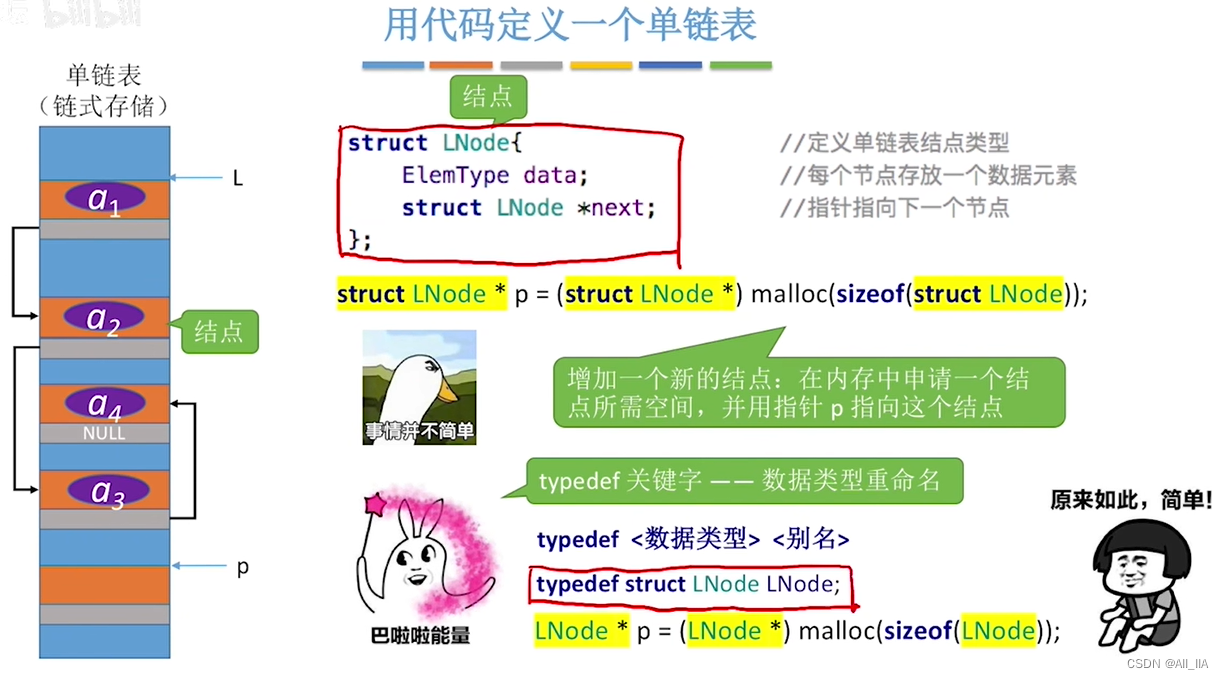

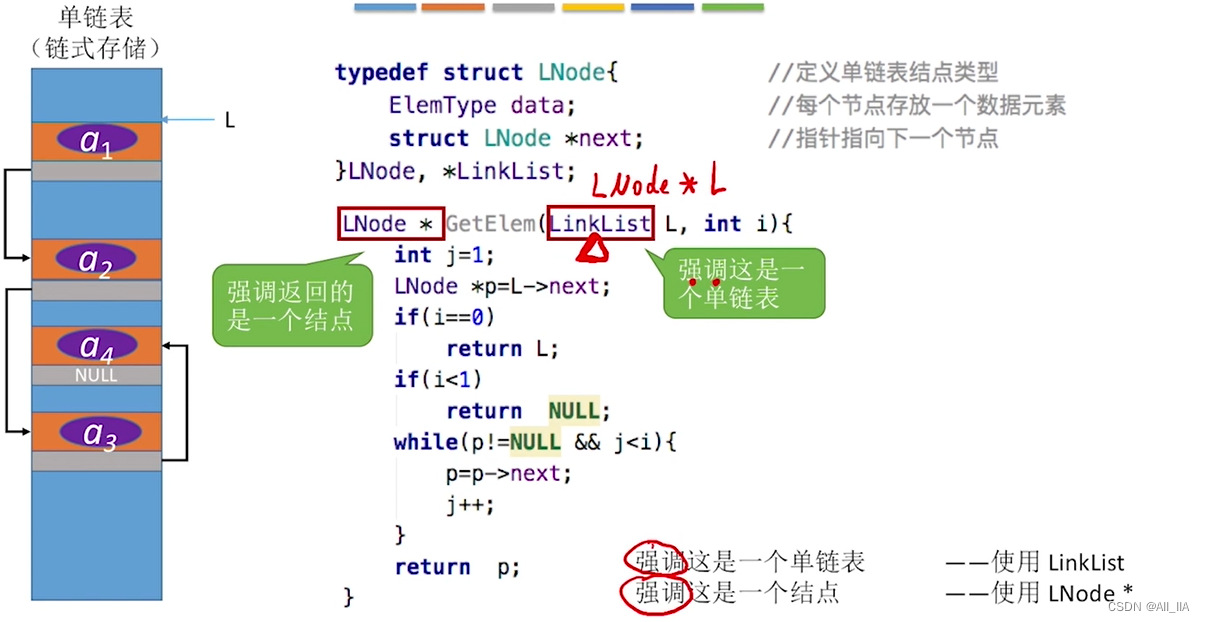

不带头结点的单链表
带头结点的单链表
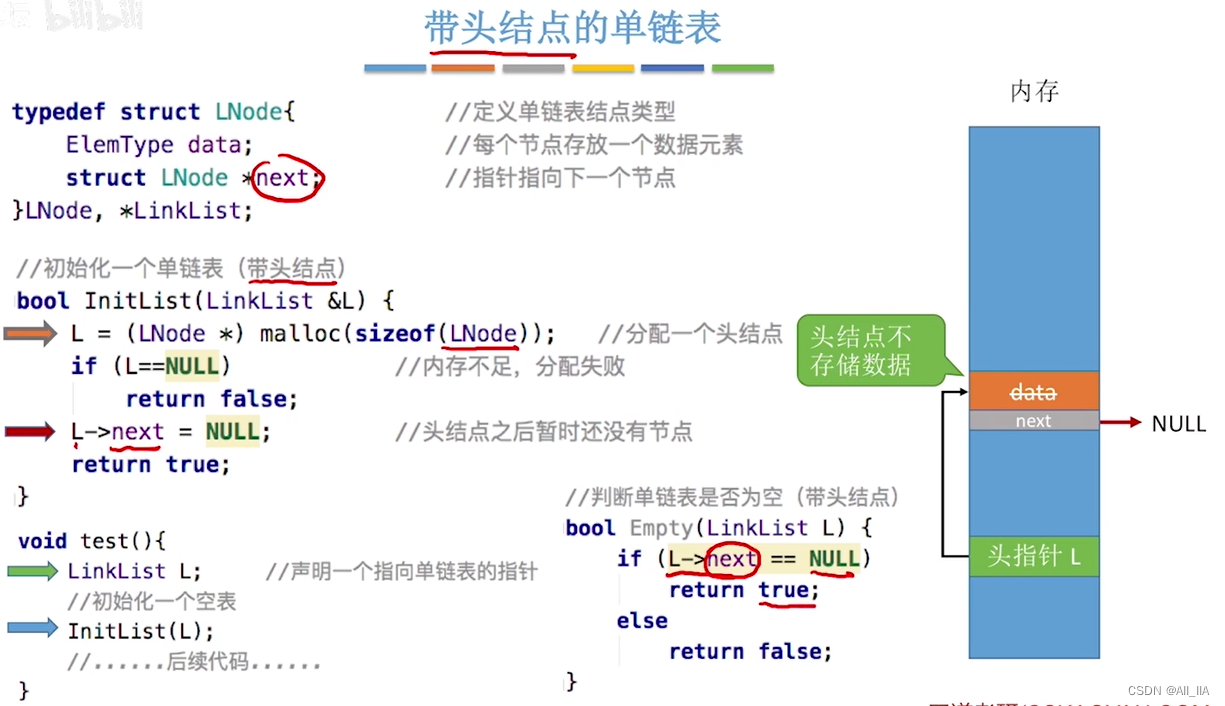
以下是一个完整的单链表的C++代码示例:
#include <iostream> // 定义链表节点结构体 struct Node { int data; // 存储节点的数据 Node* next; // 指向下一个节点的指针 }; // 定义链表类 class LinkedList { private: Node* head; // 头节点指针 public: // 构造函数,初始化链表为空 LinkedList() : head(nullptr) {} // 在链表末尾插入新节点 void insert(int value) { // 创建新节点 Node* newNode = new Node; newNode->data = value; newNode->next = nullptr; // 如果链表为空,将新节点作为头节点 if (head == nullptr) { head = newNode; } else { // 找到链表末尾的节点 Node* current = head; while (current->next != nullptr) { current = current->next; } // 将新节点插入到末尾 current->next = newNode; } } // 在指定位置插入新节点 void insertAt(int value, int position) { // 创建新节点 Node* newNode = new Node; newNode->data = value; newNode->next = nullptr; // 如果插入位置是头部 if (position == 0) { newNode->next = head; head = newNode; } // 如果插入位置不是头部 else { int count = 0; Node* current = head; Node* prev = nullptr; // 找到插入位置的节点 while (current != nullptr && count < position) { prev = current; current = current->next; count++; } // 在插入位置插入新节点 prev->next = newNode; newNode->next = current; } } // 删除指定节点 void remove(int value) { // 如果链表为空,直接返回 if (head == nullptr) { return; } // 如果要删除的节点是头节点 if (head->data == value) { Node* temp = head; head = head->next; delete temp; return; } // 查找要删除节点的前驱节点 Node* current = head; Node* prev = nullptr; while (current != nullptr && current->data != value) { prev = current; current = current->next; } // 如果找到要删除的节点 if (current != nullptr) { prev->next = current->next; delete current; } } // 遍历链表并打印节点数据 void printList() { Node* current = head; while (current != nullptr) { std::cout << current->data << " "; current = current->next; } std::cout << std::endl; } }; int main() { // 创建链表对象 LinkedList list; // 在链表末尾插入节点 list.insert(1); list.insert(2); list.insert(3); // 打印链表 std::cout << "链表: "; list.printList(); // 在指定位置插入节点 list.insertAt(4, 2); // 打印链表 std::cout << "链表: "; list.printList(); // 删除节点 list.remove(2); // 打印链表 std::cout << "链表: "; list.printList(); return 0; }

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106
- 107
- 108
- 109
- 110
- 111
- 112
- 113
- 114
- 115
- 116
- 117
- 118
- 119
- 120
- 121
- 122
- 123
- 124
- 125
- 126
- 127
- 128
- 129
- 130
- 131
- 132
- 133
- 134
- 135
- 136
- 137
- 138
- 139
- 140
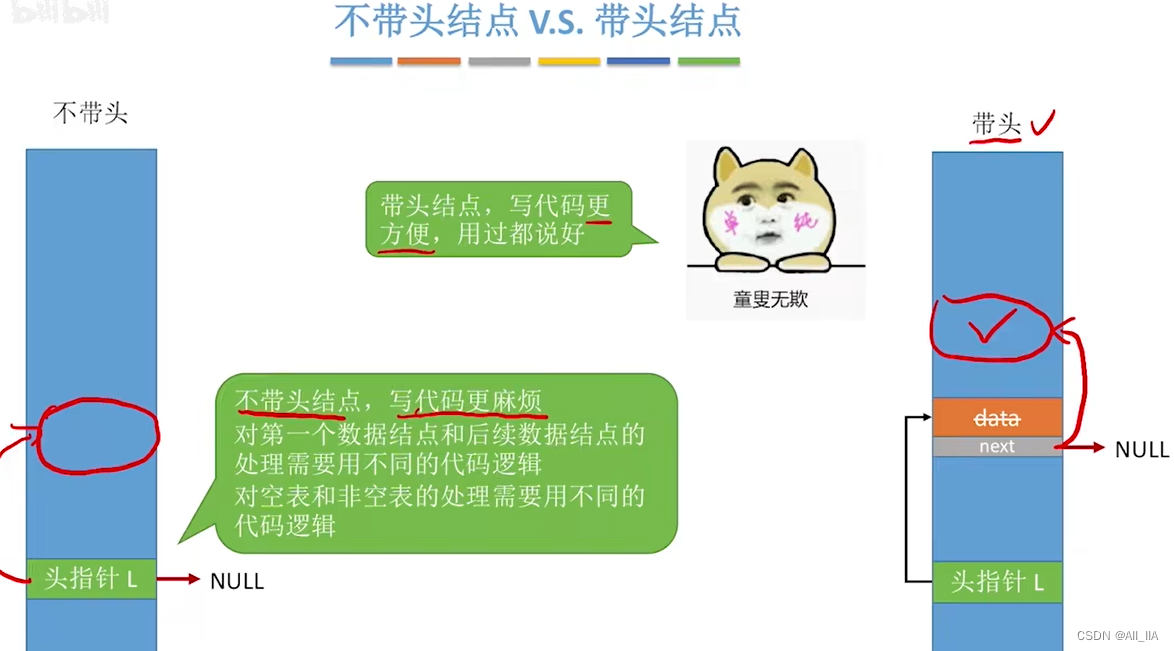
单链表的带头结点和不带头结点的区别在于是否在链表的开头添加一个额外的头结点。
- 不带头结点的单链表:
不带头结点的单链表直接将第一个节点作为链表的头节点。
特点是第一个节点存储数据,并且没有指向前一个节点的指针。
删除头节点时需要特殊处理,需要更新头指针。
- 带头结点的单链表:
带头结点的单链表在链表开头添加一个额外的头结点,头结点的数据域可以不存储实际数据。
头结点的作用是使得链表的第一个节点与其他节点的操作一致,简化链表操作。
头结点的指针域指向链表的第一个节点,方便遍历和插入。
删除头节点时可以直接将头指针指向下一个节点。
带头结点的单链表更常用,它使得链表的操作更加简单一致,避免了一些边界情况的特殊处理,更加方便处理链表的插入、删除等操作。同时,带头结点的单链表还可以避免链表为空的特殊情况的处理。
知识点回顾脉络