
- 1Python-Numpy多维数组--数组操作_python中多维数组的操作方法
- 2什么是RMVB视频?如何把视频转成RMVB格式?视频格式转换的方法
- 3美团|华为|滴滴 测试开发 面试面经_社招测试开发面经
- 4机器人视觉软件实现目标检测通常借助深度学习技术和计算机视觉算法_机器人目标识别 csdn
- 5如何建立一套完整的人事管理制度?
- 6Hive(五) Hive参数与动态分区_hive动态分区初始化
- 7Codeforces 472D. Design Tutorial: Inverse the Problem(一种逆向判定树成立的办法,从Kruskal到dfs)
- 8思迈特软件入选2021爱分析·数据智能平台厂商全景报告 喜讯来袭_思迈特软件爱分析奖项
- 9Hadoop下载与安装_hadoop_libs_x86_download
- 10发布 Chrome/Edge浏览器extension扩展到应用商店_浏览器扩展程序
yolov5前期准备、创造并训练自己的数据集、下载别人的数据集及处理学习笔记_yolo数据集下载
赞
踩
前言
这篇文章主要是对本人在自学yolo时遇到的问题以及解决办法的总结。
有些地方还有语言表达可能不是很准确,欢迎提出指正。
一、安装anaconda、python、pycharm
在安装这三个软件的时候,都可以装最新版本,我们最后学习yolo是要在anaconda中创建一个虚拟环境,所以不影响。他们三个的配置在CSDN上搜就行,很简单,学yolo的基本都是会这个的,就跳过了。
二、CUDA、cudnn、pytorch
这里有个坑,csdn上有很多教程没问题,但是三个放在一起就有问题了,因为有版本匹配问题出现,待我娓娓道来。
1、先打开pytorch网站PyTorch
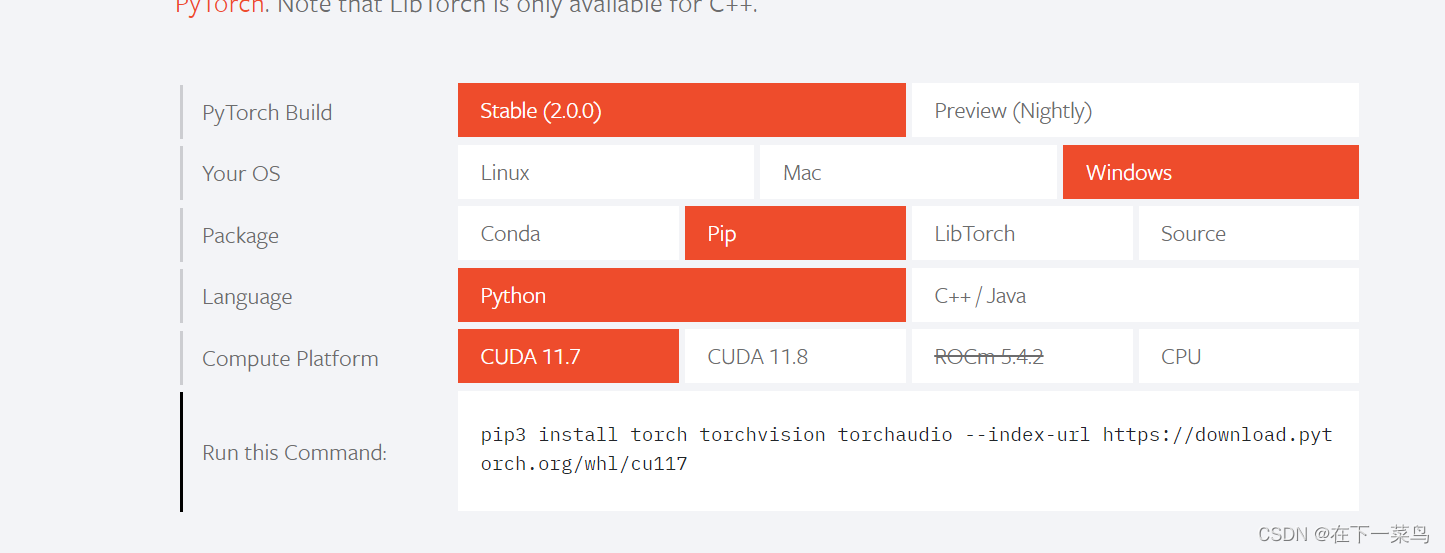
可以看到,cuda11.7和11.8两个版本的GPUpytorch,这个时候我们再去下载cuda。
2、下载cuda
先更新显卡驱动NVIDIA GeForce 驱动程序 - N 卡驱动 | NVIDIA
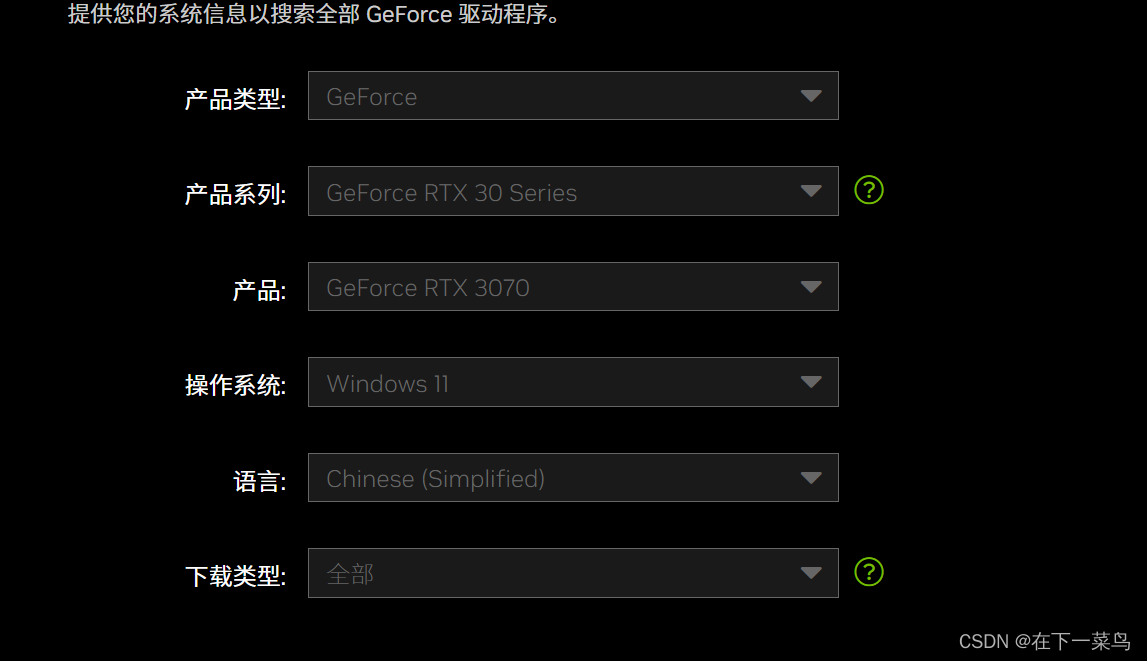
根据自己的硬件配置来填即可,然后下载,默认安装即可
安装完成后打开命令行输入nvidia-smi,如下图
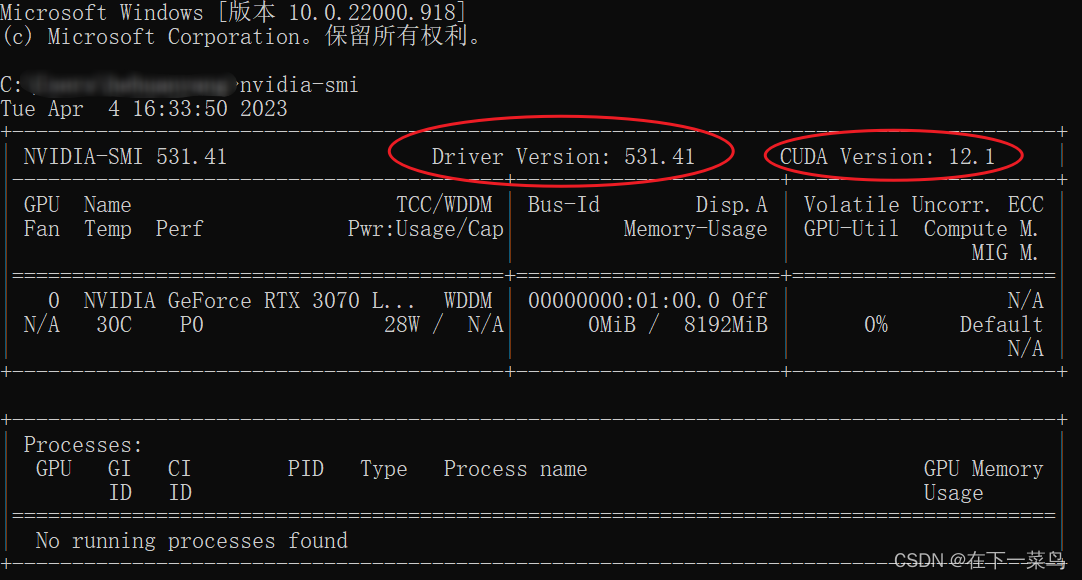
cuda version:12.1意思是该电脑最高下载12.1版本的cuda,但是,我们不能下最新的。
还记得我们上面查到的cuda版本吗?cuda11.7和11.8
下这两个其中一个才行。我下的11.8,如果你下载最新的,后面pytorch没有对应的,是不是得重新搞,我被这个差点搞吐。下面正式下载cuda11.8。嗯不想写了,你们CSDN搜吧,很多下载cuda和cudnn的教程。嗯,就这样吧~主要是步骤顺序
大家参考下面这位兄弟写的,很详细
然后检查cuda和cudnn是否安装成功
cmd中检查cuda及cudnn是否成功安装及其版本_查看cuda是否安装成功_信小海的博客-CSDN博客
三、下载pytorch
(更新:设置3.8,因为3.9后期无法安装pycocotools库,3.10会导致labelimg闪退,解决问题相当麻烦,哎!)
首先,搞个虚拟环境,我们在虚拟环境里弄深度学习,为啥要这样呢?因为我们深度学习用pytorch,可有时候搞别的不需要pytorch,可能需要别的,然后呢,万一他们冲突,是不是就不好办了,在创建虚拟环境的时候,你把虚拟环境的名字命名为pytorch,好记一点,然后,虚拟环境的python版本设置为3.8。原因是3.10的话后期yolo标注软件labelimg不支持3.10及以上,会闪退。说多了都是泪,当初没弄虚拟环境,装的又是3.10python,鬼知道我吐了多少天。
建议:先多看几个创建虚拟环境的文章,熟悉流程后再动手。
通过conda打开命令行
输入conda info查看conda创建虚拟环境的位置是否是你想要的,例如我的放D盘anaconda下的envs中
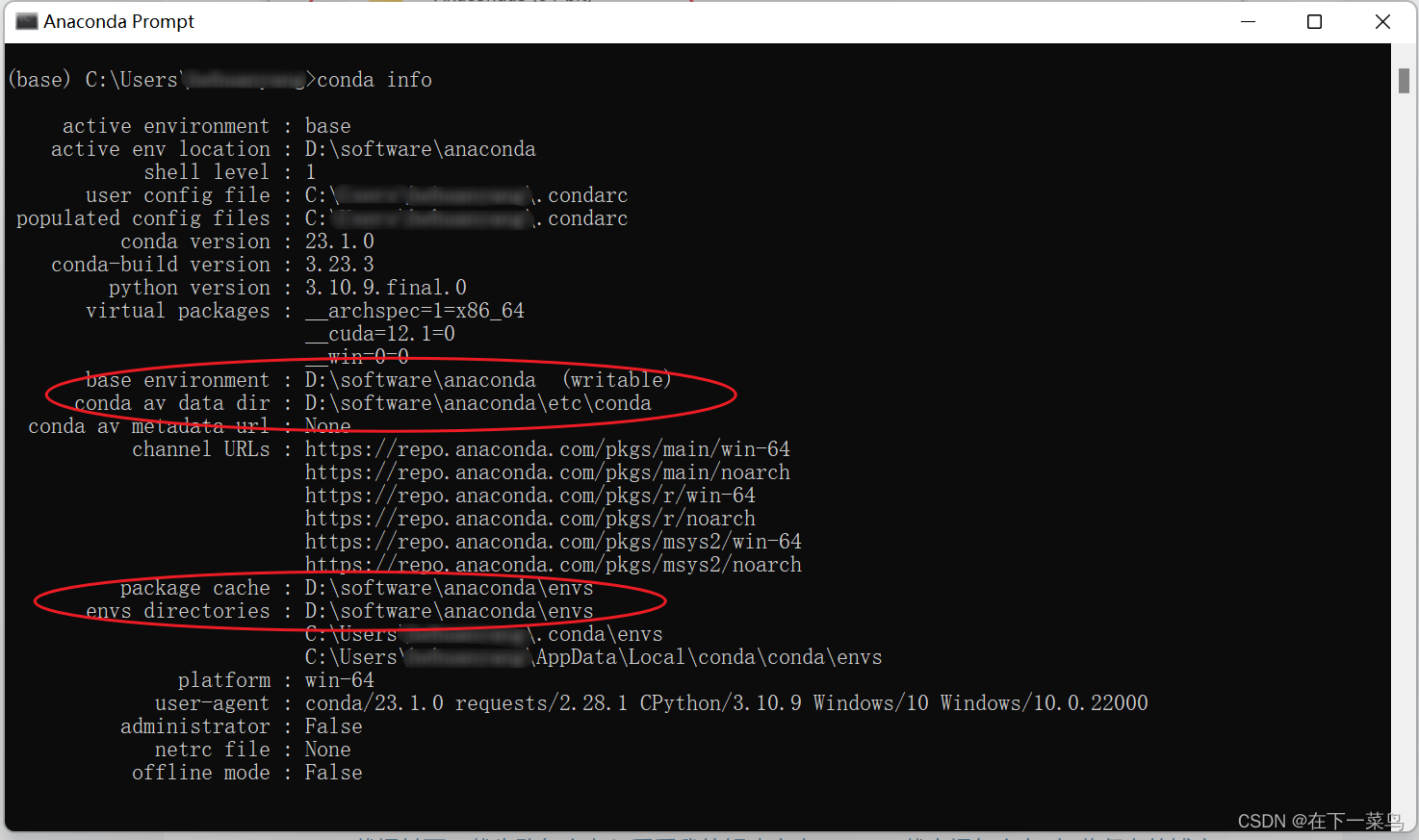
位置没问题的话开始创建虚拟环境,命令如下:
conda create -n pytorch python=3.8
pytorch是虚拟空间的名字,版本是3.8,建议不要弄太高,3.10及以上的话搞yolo的labelimg会出问题,听人劝吃饱饭,当然每个人的问题可能不一样,你自己看这弄,不行可以删除这个虚拟空间,这也是创建虚拟空间的好处之一。删除虚拟空间命令如下
conda remove -n pytorch --all
同样,pytorch是虚拟空间的名字,其它都是一样的。
查看自己有几个虚拟空间的命令:conda env list

进入pytorch虚拟空间的命令:activate pytorch

看,base环境变成了pytorch虚拟环境了。
下一步就是把虚拟环境和pycharm挂钩,这样在pycharm中更方便操作一些文件以及编代码。参考下面这位兄弟的文章,很简单,多弄两次就会了
Anaconda创建虚拟环境+Pycharm使用Anaconda创建的虚拟环境_pycharm创建conda虚拟环境_Icy Hunter的博客-CSDN博客
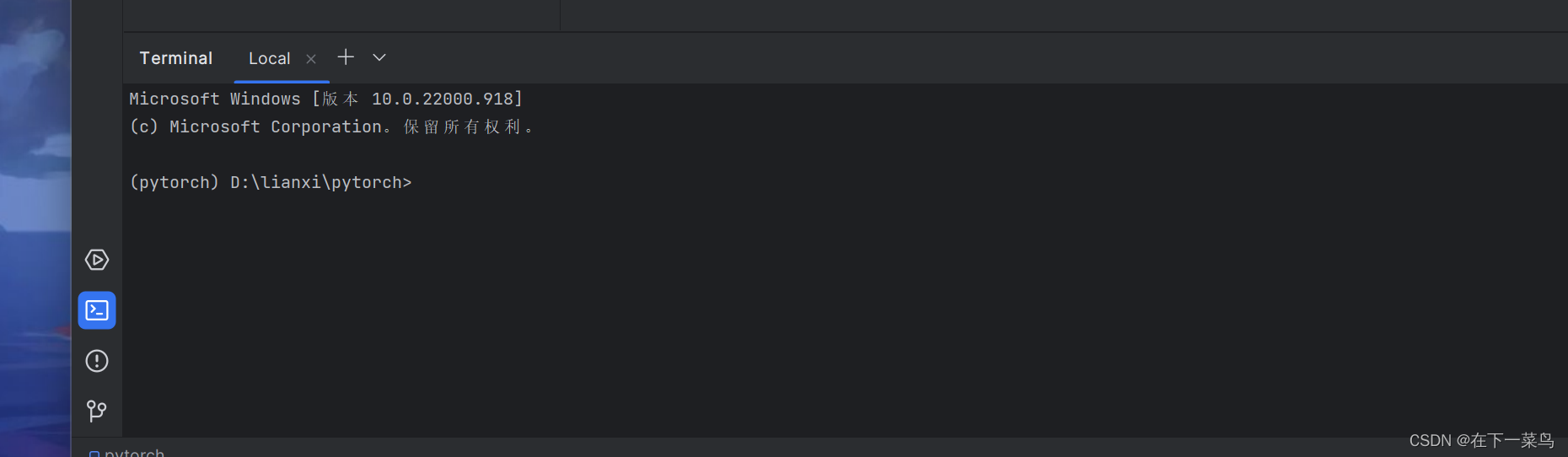
(pytorch)表示你的命令行环境也是pytorch

这个表明你的pycharm在你创建的pytorch环境中,python版本3.8
上面是先弄好虚拟环境,然后大家要注意,pytorch是装在这个虚拟环境中的,所以,你先进入pytorch虚拟环境,就是activate pytorch
装pytorch很费劲,我给你们试过了很多坑,下面这个方法稳
https://download.pytorch.org/whl/torch_stable.html
打开上面那个软件

找到这两个,其中cu代表GPU版本,cu11.8是对应cuda11.8版本,和我们之前装的版本要对应。然后是cp38代表python3.8,后面有windows版本和linux的,根据自己的下载,我的是win。
同样的方法,看清楚,一个是torch一个是torchvision,两个都要找到对应的版本下载下来。
不要用镜像,用这个方法,镜像太坑了。
然后,在你的pytorch虚拟环境中安装torch,命令如下:
pip install D:\software\torch\torch-2.0.0+cu118-cp38-cp38-win_amd64.whl
应该能看懂吧,就是pip install +文件路径,记得whl带上。
同样的思路,把第二个文件也给装上就可以了。
检验pytorch是否安装成功
在pytorch环境下输入python,进入python编辑器如下代码
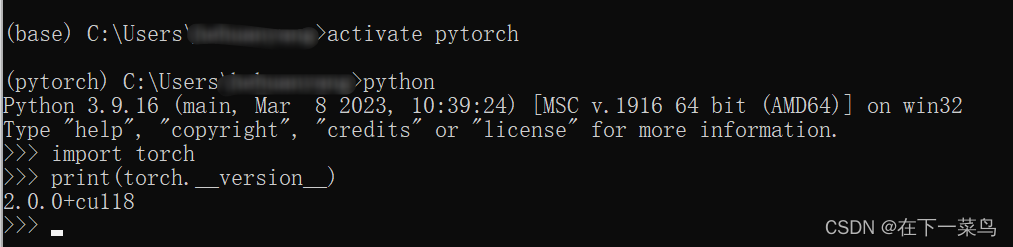
显示cu118表示安装成功。
四、整理自己的数据集
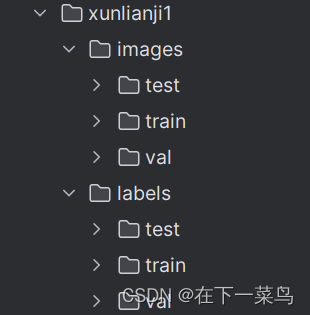
按照上面的层次创建一个文件夹。把图片放到xunlianji1/images/train中。然后下载labelimg,标注数据,标注的数据放到xunlianji1/labels/train中。
这样自己的数据集就做好了。关于labelimg和标注,这些比较简单,参考labelimg下载和使用标注数据集的文章就行,或者多参考几个,不想写了~~~
五、训练自己的数据集
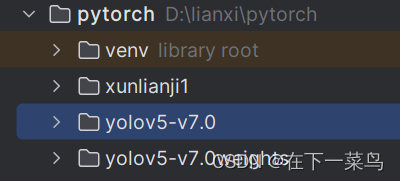
在pytorch虚拟环境中,放入yolov5-v7.0的文件(这个直接搜yolov5下载,放这里就行)。把我们刚才弄好的数据集也放进来,下面开始改参数
1、找到yolov5-v7.0/data/coco.yaml 复制这个文件,命名为xunlianji1,主要是如下几个参数要改
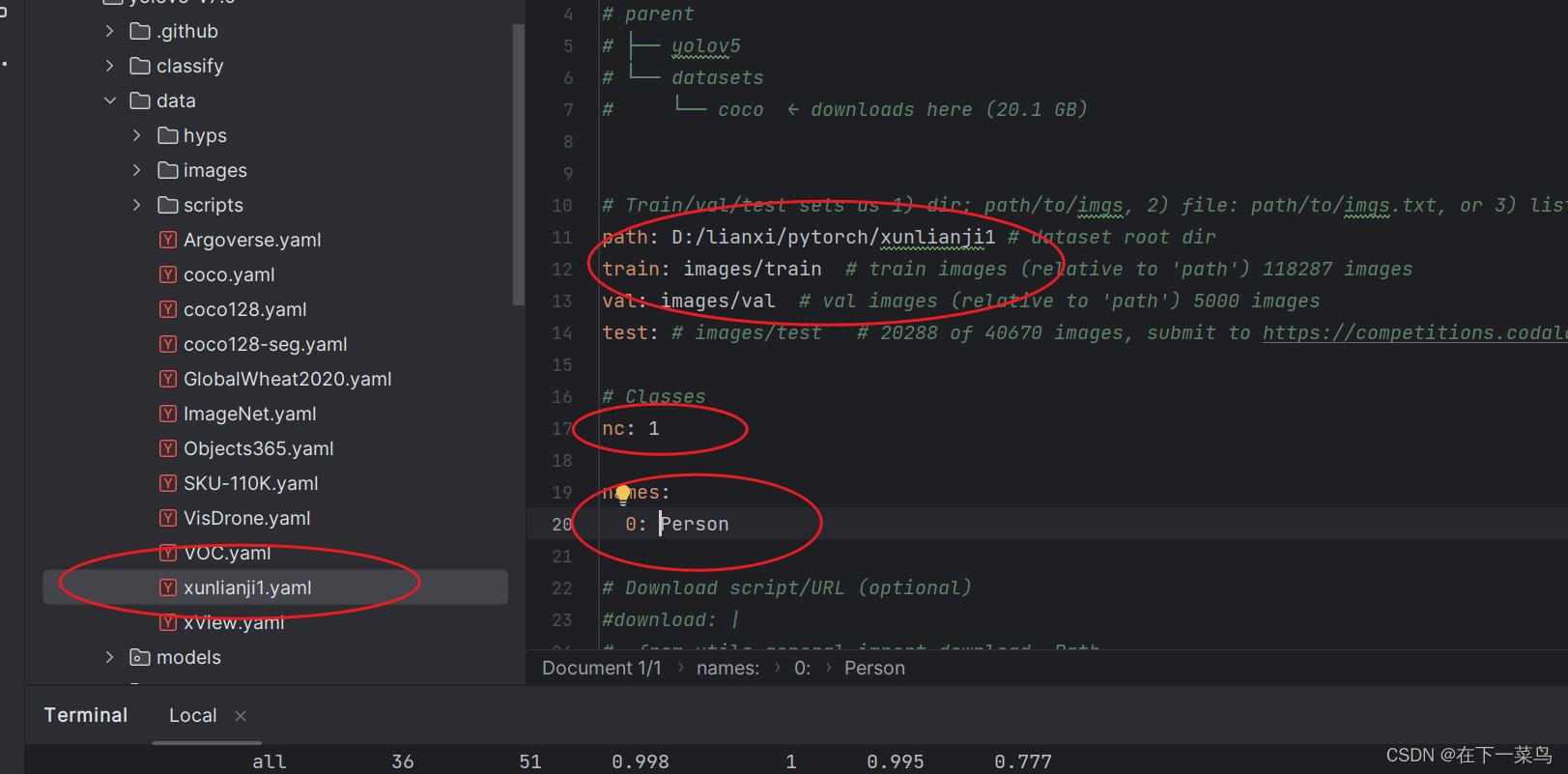
因为我主要检测Person,所以就一个人,nc也是1,其实你对照原coco.yaml就能看懂,然后还得把下面的download都给注释掉。
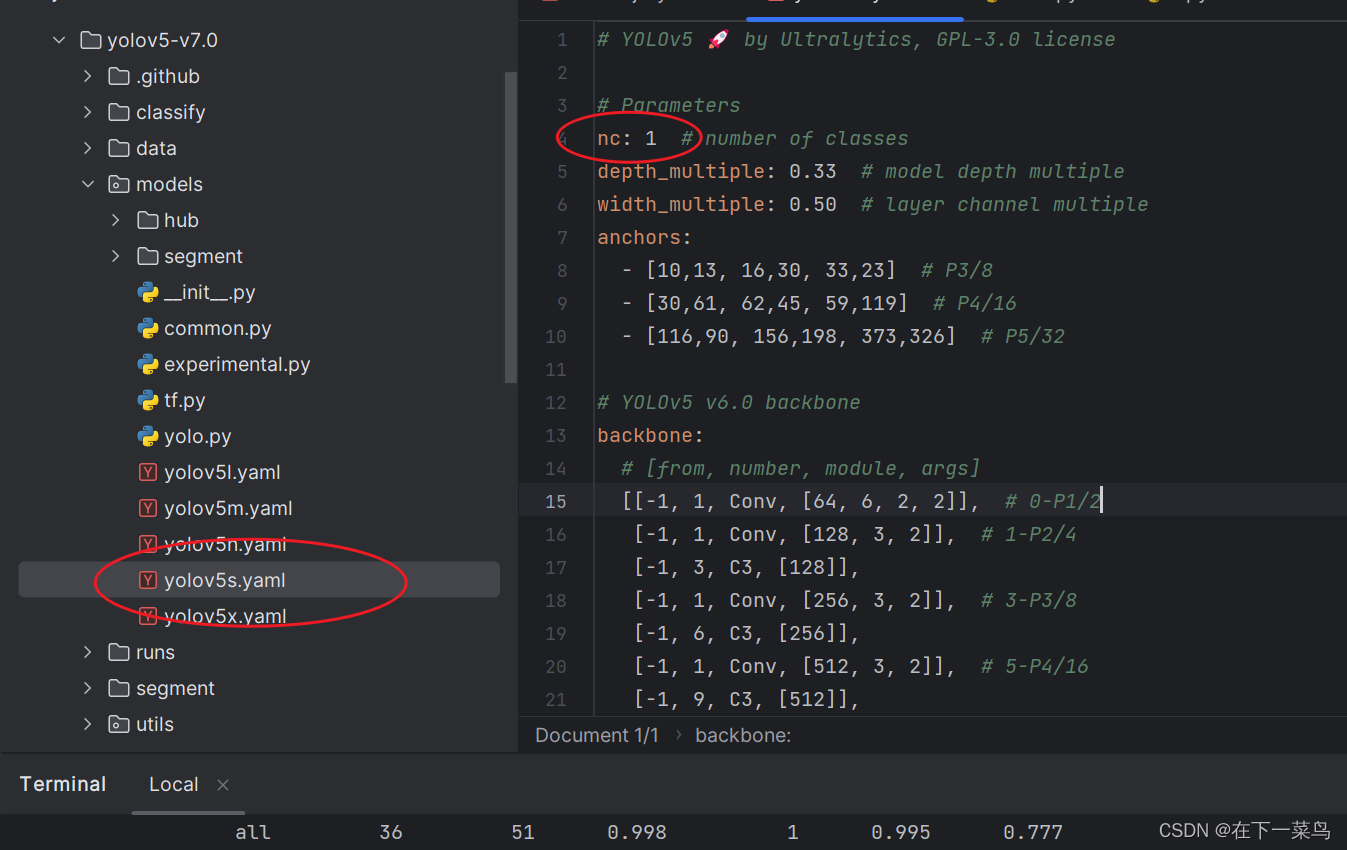
2、再改个文件,因为我用yolov5s模型,所以打开它把nc改一下即可
然后就是命令行执行训练命令了,下面代码很容易看懂,就是改改你的文件夹路径
yolov5-v7.0/train.py --weights yolov5-v7.0weights/yolov5s.pt --cfg yolov5-v7.0/models/yolov5s.yaml --data yolov5-v7.0/data/xunlianji1.yaml --batch-size 8 --img 640
训练结束后,会出现一些文件,下面这个博客是介绍这些文件啥意思的,大家参考一下:
六、模型测试
模型训练完成后,将runs/exp/weights下的模型(best.pt)复制在yolov5文件夹下。
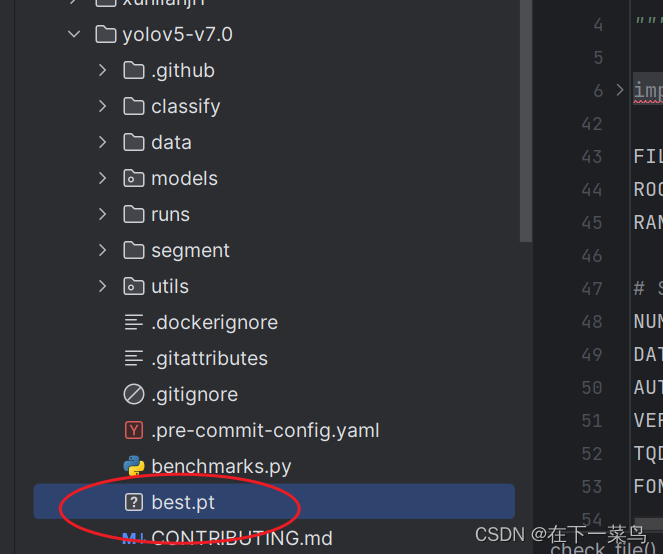
开始测试
yolov5-v7.0/detect.py --weights yolov5-v7.0/best.pt --source ../pytorch/xunlianji1/images/test
weights:是你训练好的模型的路径
--source:是你测试的数据路径
images/test里面放的是你要测试的数据图片,也可以用val文件作为测试,val文件夹是程序训练过程中用的,你测试的时候用val也行,这就是为什么有的人是train和val文件夹,没有test文件夹的原因
测试结果保存在runs/detect下
如果需要测试视频,很简单,在data文件夹下创建一个文件夹video,把视频放进去,改detect.py下的source,把路径换成视频的路径即可例如我的如下图

七、下载他人数据集
根据自己需要下载别人的数据集,一般下载下来的数据集别人会给分好文件夹,如果没有分好,那就自己调整,我们主要需要别人的图片和标签,只有有这俩就行。其中,images中分别放train、test、val文件夹,分别是训练集、测试集、验证集。同样的,labels文件夹下面三个文件夹分别一一对应标签文件。一般都是xml格式,很少有txt格式(也就是我们YOLO要用到的)。下面介绍一下如何xml转txt。
voc的xml格式转YOLO的txt格式代码:
- import os
- import xml.etree.ElementTree as ET
-
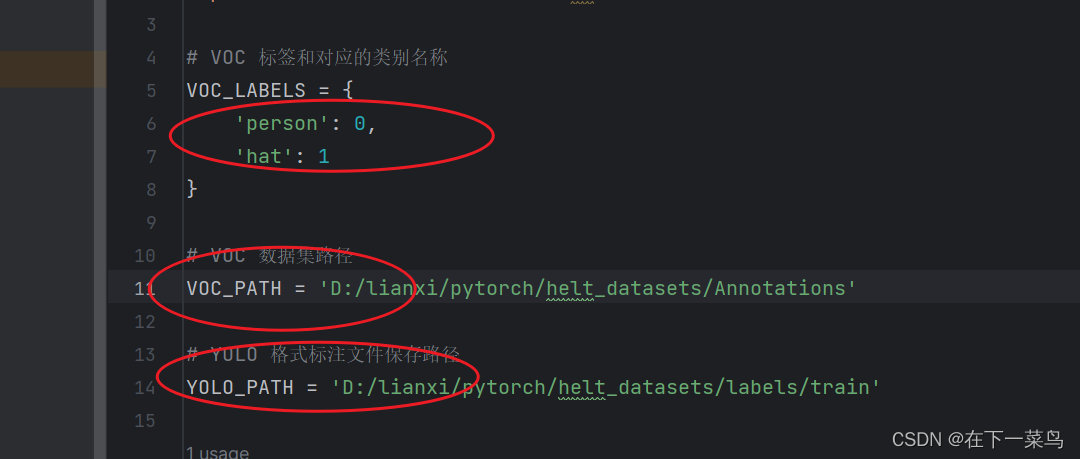
- # VOC 标签和对应的类别名称
- VOC_LABELS = {
- 'person': 0,
- 'bat': 1
- }
-
- # VOC 数据集路径
- VOC_PATH = '/path/to/VOC'
-
- # YOLO 格式标注文件保存路径
- YOLO_PATH = '/path/to/YOLO'
-
- def convert_voc_to_yolo(xml_file):
- # 解析 XML 文件
- tree = ET.parse(xml_file)
- root = tree.getroot()
-
- # 获取图像的宽度和高度
- size = root.find('size')
- width = int(size.find('width').text)
- height = int(size.find('height').text)
-
- # 遍历每一个物体
- for obj in root.findall('object'):
- # 获取物体的类别和位置信息
- label = obj.find('name').text
- xmin = int(obj.find('bndbox/xmin').text)
- ymin = int(obj.find('bndbox/ymin').text)
- xmax = int(obj.find('bndbox/xmax').text)
- ymax = int(obj.find('bndbox/ymax').text)
-
- # 将坐标信息转换为 YOLO 格式
- x_center = float(xmin + xmax) / 2 / width
- y_center = float(ymin + ymax) / 2 / height
- w = float(xmax - xmin) / width
- h = float(ymax - ymin) / height
-
- # 获取类别的 ID
- label_id = VOC_LABELS[label]
-
- # 将标注信息保存到 YOLO 格式的文件中
- yolo_file.write(f'{label_id} {x_center} {y_center} {w} {h}\n')
-
- # 遍历 VOC 数据集中的所有 XML 文件
- for root, dirs, files in os.walk(VOC_PATH):
- for file in files:
- if file.endswith('.xml'):
- # 打开 YOLO 格式的文件
- yolo_filename = os.path.splitext(file)[0] + '.txt'
- yolo_file = open(os.path.join(YOLO_PATH, yolo_filename), 'w')
-
- # 转换 XML 文件为 YOLO 格式
- xml_file = os.path.join(root, file)
- convert_voc_to_yolo(xml_file)
-
- # 关闭 YOLO 格式的文件
- yolo_file.close()
- #上述代码中,我们将 VOC_LABELS 字典中的键值对修改为 person: 0 和 bat: 1,然后在 #convert_voc_to_yolo 函数中根据标签名称获取类别 ID。需要注意的是,如果你的数据集中存在其他标签
- #或类别,也需要根据实际情况进行修改。

代码易懂,只需要改两个路径和你的类别,我这里是因为只有两个类person和bat,你们根据自己数据集的情况更改即可。
文件的位置放好,再根据前面学习的知识把train.py的内容改改(忘了可以看前面,改路径,改nc等,多试几次就熟悉了),就可以训练了。我这已经训练了

写的不好我知道,请不要介意,主要是记录一下学习过程,怕以后忘了。大家肯定要自己多动手的,中间肯定会有各种问题,一一解决就是了,加油各位~~~


